Learn more about Search Results ML - Page 381

- You may be interested
- 「ジェイソン・フラックスとともに会話型A...
- 既存のLLMプロジェクトをLangChainを使用...
- アムステルダム大学とクアルコムAIの研究...
- 「簡単な英語プロンプトでLLMをトレーニン...
- Macでの安定したDiffusion XLと高度なCore...
- Googleはカナダに「リンク税」を支払わな...
- 「生成AI」の「スーパーユーザー」に出会...
- トップAIアドベンチャー:OpenAIレジデンシー
- 「グリーンウォッシングとは何か、そして...
- ベルマン-フォードアルゴリズム:重み付き...
- 「データサイエンスとビジネスアナリティ...
- 「3D-VisTAに会いましょう:さまざまな下...
- 「機械学習モデルのバリデーション方法」
- クラウドインスタンスのスタートアップス...
- 「機械学習の解明:人気のあるMLライブラ...

「尤度」と「確率」の違いは何ですか?」
尤度(Likelihood)と確率(Probability)は、データサイエンスやビジネス分野でよく使われる相互関連する用語であり、定義や用法が異なり、しばしば混同されます。この記事は、それぞれの分野での理解と応用のために、確率の定義、用法、誤解を明確にすることを目的としています。 尤度とは何ですか? A. 尤度の定義と統計的推論における役割 尤度は、モデルや仮説が観測データに適合する度合いを示す量的評価または測定として定義することができます。また、特定のパラメータセットで所望の結果またはデータ収集を見つける確率として解釈することもできます。統計的推論において基本的な役割を果たし、尤度の究極の目的は、データの特性に関する結論を出すことです。同じことを達成するための役割は、パラメータ推定を通じて見ることができます。パラメータ推定には、最尤推定法(MLE)を利用してパラメータ推定を行います。 仮説検定では、尤度比を使用して帰無仮説を評価します。同様に、モデル選択とチェックには尤度が貢献します。研究者は、モデル選択の測定として、ベイズ情報量規準(BIC)と赤池情報量規準(AIC)を一般的に使用します。尤度ベースの方法は、パラメータを推定するための信頼区間の構築に重要な役割を果たします。 B. 尤度関数を用いた尤度の計算 尤度関数は、データ分布を特定するのに役立つ数式表現です。関数は、尤度(|x)と表記され、|は所望のモデルのパラメータを表し、Xは観測されたデータを表します。 例を挙げて説明しましょう。たとえば、色つきのビー玉の入った袋があるとします。赤いビー玉を取り出す確率を予測したいとします。ランダムに引くことから始め、色を記録し、次に上記の式を使用して尤度を計算します。赤いビー玉を引く確率を表すパラメータを計算または推定します。先に述べたように、尤度関数を表すことにします。尤度関数は、特定の値に対して観測されたデータxを観察する確率を示すものです。 独立かつ同一に分布すると仮定すると、尤度関数は次のようになります。 L(|x)=k(1-)(n-k)、ここでnは引き出す回数、kは観測されたデータ中の赤いビー玉の数です。5回引いた場合、赤、赤、青、赤、青の順であったと仮定します。 L(0.5|x)=0.53(1-0.5)(5-3) L(0.5|x)=0.530.52 L(0.5|x)=0.015625 したがって、= 0.5の場合、上記の玉を上記の順序で観察する尤度は0.015625です。 C. 尤度の特定の仮説やモデルに適合する度合いを示す測定としての解釈 上記の式で値を保持する場合、値の範囲は状況に応じて異なります。しかし、高い尤度値は、良好な結果と観測値と計算値の間の高い関連性を示します。 D. 尤度の概念を説明する例 コイントスの例を取り上げましょう。あなたは10回ほど公平なコインを投げます。今、コインの公平性または偏りを評価する必要があります。パラメータを設定する必要があります。8つの表と2つの裏は、コインが公平であることを示しています。高い尤度は、公平なコインを表し、公平性の仮説をさらに支持します。 ガウス分布の例を取ると、同じ分布に従う100個の測定データセットがあるとします。分布の平均値と標準偏差を知りたいとします。パラメータに基づいて異なる組み合わせが設定され、高い確率推定は、最良のガウス分布の最大尤度を示します。…

単一モダリティとの友情は終わりました – 今やマルチモダリティが私の親友です:CoDiは、合成可能な拡散による任意から任意への生成を実現できるAIモデルです
ジェネレーティブAIは、今ではほぼ毎日聞く用語です。私はジェネレーティブAIに関する論文をどれだけ読んでまとめたか覚えていません。彼らは印象的で、彼らがすることは非現実的で魔法のようであり、多くのアプリケーションで使用できます。テキストプロンプトを使用するだけで、画像、動画、音声などを生成できます。 近年のジェネレーティブAIモデルの大幅な進歩により、以前は不可能と考えられていたユースケースが可能になりました。テキストから画像へのモデルで始まり、信じられないほど素晴らしい結果が得られたことがわかった後、複数のモダリティを扱うことができるAIモデルの需要が高まりました。 最近は、任意の入力の組み合わせ(例:テキスト+音声)を取り、様々な出力の組み合わせ(例:ビデオ+音声)を生成できるモデルの需要が急増しています。これを対処するためにいくつかのモデルが提案されていますが、これらのモデルは、共存し相互作用する複数のモダリティを含む現実世界のアプリケーションに関して制限があります。 モダリティ固有の生成モデルを多段的なプロセスでつなげることは可能ですが、各ステップの生成力は本質的に限定されるため、手間がかかり、遅いアプローチとなります。また、独立に生成された単一モダルストリームは、組み合わせるときに一貫性や整合性が欠けることがあり、後処理の同期が困難になる場合があります。 任意の入力モダリティの混合を処理し、任意の出力の組み合わせを柔軟に生成するためのモデルをトレーニングするには、膨大な計算およびデータ要件が必要です。可能な入力-出力の組み合わせの数は指数関数的に増加し、多数のモダリティグループに対して整列したトレーニングデータはまれまたは存在しないためです。 ここで、この課題に取り組むために提案されたCoDiというモデルを紹介しましょう。 CoDiは、任意のモダリティの任意の組み合わせを同時に処理および生成することを可能にする新しいニューラルアーキテクチャです。 CoDiの概要。出典:https://arxiv.org/pdf/2305.11846.pdf CoDi は、入力条件付けおよび生成拡散ステップの両方で複数のモダリティを整列させることを提案しています。さらに、対照的な学習のための「ブリッジングアライメント」戦略を導入し、線形数のトレーニング目標で指数関数的な入力-出力の組み合わせを効率的にモデル化できるようにしています。 CoDi の主要なイノベーションは、潜在的な拡散モデル(LDM)、多モダル条件付けメカニズム、およびクロスアテンションモジュールの組み合わせを利用して、任意の-to-任意の生成を処理することができる能力にあります。各モダリティ用に別々のLDMをトレーニングし、入力モダリティを共有特徴空間に射影することで、CoDi は、このような設定の直接的なトレーニングなしで、任意のモダリティまたはモダリティの組み合わせを生成できます。 CoDiの開発には、包括的なモデル設計と多様なデータリソースでのトレーニングが必要です。最初に、テキスト、画像、動画、音声などの各モダリティに対して潜在的な拡散モデル(LDM)をトレーニングします。これらのモデルは独立して並行してトレーニングでき、モダリティに固有のトレーニングデータを使用して、卓越した単一モダリティ生成品質を確保します。音声+言語のプロンプトを使用して画像を生成する場合の条件付きクロスモダリティ生成では、入力モダリティを共有の特徴空間に射影し、出力LDMは入力特徴の組み合わせに注意を払います。この多モダル条件付けメカニズムにより、拡散モデルは直接的なトレーニングなしで、任意のモダリティまたはモダリティの組み合わせを処理できるようになります。 CoDiモデルの概要。出典:https://arxiv.org/pdf/2305.11846.pdf トレーニングの第2ステージでは、CoDiは、任意の出力モダリティの任意の組み合わせを同時に生成する多対多の生成戦略を処理します。これは、各ディフューザーにクロスアテンションモジュールを追加し、環境エンコーダーを追加して、異なるLDMの潜在変数を共有潜在空間に投影することによって実現されます。このシームレスな生成能力により、CoDiは、すべての可能な生成組み合わせでトレーニングすることなく、任意のモダリティのグループを生成できるため、トレーニング目標の数を指数関数から線形関数に減らすことができます。 (※以下、原文のHTMLコードを保持します) In the second stage of training, CoDi…

AWSが開発した目的に特化したアクセラレータを使用することで、機械学習ワークロードのエネルギー消費を最大90%削減できます
従来、機械学習(ML)エンジニアは、モデルの学習と展開コストとパフォーマンスのバランスを取ることに焦点を当ててきました最近では、持続可能性(エネルギー効率)が顧客にとって追加の目標となっていますこれは重要なことであり、MLモデルのトレーニングを行い、トレーニングされたモデルを使用して予測(推論)を行うことは、非常にエネルギーを消費するタスクであるためです加えて、さらに...

現代のデータエンジニアリングにおいてMAGE:効率的なデータ処理を可能にする
イントロダクション 今日のデータ駆動型の世界では、あらゆる業界の組織が膨大なデータ、複雑なパイプライン、そして効率的なデータ処理の必要性に直面しています。Apache Airflowなどの従来のデータエンジニアリングソリューションは、これらの困難に対処するためにデータ操作をオーケストレーションし、制御することで重要な役割を果たしてきました。しかし、技術の急速な進化により、データエンジニアリングの景観を再構築するMageという新しい競合者が登場しました。 学習目標 第3者のデータをシームレスに統合および同期化すること 変換のためのPython、SQL、およびRによるリアルタイムおよびバッチパイプラインの構築 データ検証で再利用可能かつテスト可能なモジュラーコード 寝ている間に複数のパイプラインを実行、監視、およびオーケストレーションすること クラウド上で協働し、Gitとバージョン管理を行い、利用可能な共有ステージング環境を待つことなくパイプラインをテストすること Terraformテンプレートを介してAWS、GCP、およびAzureなどのクラウドプロバイダーでの高速な展開 データウェアハウスで非常に大きなデータセットを直接変換するか、Sparkとのネイティブ統合を介して変換すること 直感的なUIを介して組み込みの監視、アラート、および観測性 まるで腕木式に簡単でしょうか?それならMageを絶対に試してみるべきです! この記事では、Mageの機能と機能性について説明し、これまでに学んだことやそれを使用して構築した最初のパイプラインを強調します。 この記事はData Science Blogathonの一部として公開されました。 Mageとは何ですか? Mageは、AIによって駆動され、機械学習モデル上に構築された現代的なデータオーケストレーションツールであり、かつてないほどのデータエンジニアリングプロセスを効率化し最適化することを目的としています。これは、データ変換と統合のための効果的でありながら簡単なオープンソースデータパイプラインツールであり、Airflowのような確立されたツールに対して強力な代替手段となる可能性があります。自動化と知能の力を組み合わせることで、Mageはデータ処理ワークフローを革新し、データの取り扱いと処理の方法を変革しています。Mageは、その無比の機能と使いやすいインターフェイスにより、これまでにないデータエンジニアリングプロセスの簡素化と最適化を目指しています。 ステップ1:クイックインストール Mageは、Docker、pip、およびcondaコマンドを使用してインストールでき、またはクラウドサービス上で仮想マシンとしてホストできます。 Dockerを使用する #Dockerを使用してMageをインストールするコマンドライン >docker…

アルゴリズム取引と金融におけるAIにおける知的財産権法の理解
金融業界は、特定の期間の要求に最も適したより効率的で効果的なアプローチを受け入れるために常に変化していますアルゴリズム取引とAIは、取引と金融に進出する最新の技術であり、効率性と正確性の面で金融の景観を変革することになっています... アルゴリズム取引とAIにおける知的財産法の理解(英語原文のタイトル)

ビジネスにおける機械学習オペレーションの構築
私のキャリアで気づいたことは、成功したAI戦略の鍵は機械学習モデルを本番環境に展開し、それによって商業的な可能性をスケールで解放する能力にあるということですしかし…
一度言えば十分です!単語の繰り返しはAIの向上に役立ちません
大規模言語モデル(LLM)はその能力を示し、世界中で話題になっています今や、すべての大手企業は洒落た名前を持つモデルを持っていますしかし、その裏にはすべてトランスフォーマーが動いています...

マックス・プランク研究所の研究者たちは、MIME(3D人間モーションキャプチャを取得し、その動きに一致する可能性のある3Dシーンを生成する生成AIモデル)を提案しています
人間は常に周囲と相互作用しています。空間を移動したり、物に触れたり、椅子に座ったり、ベッドで寝たりします。これらの相互作用は、シーンの設定やオブジェクトの位置を詳細に示します。マイムは、そのような関係性の理解を利用して、身体の動きだけで豊かで想像力豊かな3D環境を作り出すパフォーマーです。彼らはコンピュータに人間の動作を模倣させて適切な3Dシーンを作ることができるでしょうか?建築、ゲーム、バーチャルリアリティ、合成データの合成など、多くの分野がこの技術に恩恵を受ける可能性があります。たとえば、AMASSなどの3D人間の動きの大規模なデータセットが存在しますが、これらのデータセットには収集された3D設定の詳細がほとんど含まれていません。 AMASSを使用して、すべての動きに対して信憑性の高い3Dシーンを作成できるでしょうか?そうであれば、AMASSを使用してリアルな人間-シーンの相互作用を考慮したトレーニングデータを作成できます。彼らは、MIME(Mining Interaction and Movement to infer 3D Environments)と呼ばれる新しい技術を開発しました。これは、3D人間の動きに基づいて信憑性の高い内部3Dシーンを作成して、このような問いに対応します。それを可能にするのは何でしょうか?基本的な仮定は次のとおりです。(1)空間を移動する人間の動きは、物の欠如を示し、実質的に家具のない画像領域を定義します。また、これにより、シーンに接触する場合の3Dオブジェクトの種類や場所が制限されます。たとえば、座っている人は椅子、ソファ、ベッドなどに座っている必要があります。 図1:人間の動きから3Dシーンを推定します。3D人間の動き(左)から推定された、動きが起こったリアルな3D設定を再現します。彼らの生成モデルは、人間-シーンの相互作用を考慮した、複数のリアリスティックなシナリオ(右)を生成できます。 ドイツのマックスプランク知能システム研究所とAdobeの研究者たちは、これらの直感を具体的な形で示すために、MIMEと呼ばれるトランスフォーマーベースの自己回帰3Dシーン生成技術を作成しました。空のフロアプランと人間の動きシーケンスが与えられると、MIMEは人間と接触する家具を予測します。さらに、人間と接触しないが他のオブジェクトにフィットし、人間の動作によって引き起こされる自由空間の制約に従う信憑性の高いアイテムを予測します。彼らは、人間の動きを接触と非接触のスニペットに分割して、3Dシーン作成を人間の動きに条件付けます。POSAを使用して接触可能なポーズを推定します。非接触姿勢は、足の頂点を地面に投影して、部屋の自由空間を確立し、2Dフロアマップとして記録します。 POSAによって予測された接触頂点は、接触ポーズと関連する3D人体モデルを反映した3D境界ボックスを作成します。接触と自由空間の基準を満たすオブジェクトは、トランスフォーマーへの入力として自己回帰的に期待されます。図1を参照してください。彼らは、3D-FRONTという大規模な合成シーンデータセットを拡張して、MIMEをトレーニングするための新しいデータセットである3D-FRONT HUMANを作成しました。彼らは、RenderPeopleスキャンからの静止接触ポーズと、AMASSからのモーションシーケンスを使用して、3Dシナリオに人を自動的に追加します(一連の歩行モーションと立っている人を含む非接触人と、座って、触れて、横たわっている人を含む接触人)。 MIMEは、3Dバウンディングボックスとして表される入力動作のリアルな3Dシーンレイアウトを推論時に作成します。彼らは、この配置に基づいて3D-FUTUREコレクションから3Dモデルを選択し、人間の位置とシーンの間の幾何学的制約に基づいて3D配置を微調整します。彼らの手法は、ATISSのような純粋な3Dシーン作成システムとは異なり、人間の接触と動きをサポートする3Dセットを作成し、自由空間に説得力のあるオブジェクトを配置することができます。Pose2Roomという最近のポーズ条件付け生成モデルとは異なり、個々のオブジェクトではなく完全なシーンを予測することができます。彼らは、PROX-Dのように記録された本物のモーションシーケンスに対して調整なしで彼らの手法が機能することを示しました。 まとめると、彼らが提供したものは以下の通りです: • 人と接触するものを自動的に生成し、運動定義された空きスペースを占有しないように自己回帰的に作成する、3Dルームシーンの全く新しい運動条件付き生成モデル。 • RenderPeopleの静止接触/立ち姿勢からの3Dモーションデータを用いて、人と自由空間にいる人々が相互作用する3Dシーンデータセットが、3D FRONTを埋めるように作成されました。 コードはGitHubで入手可能であり、ビデオデモとアプローチのビデオ解説も提供されています。
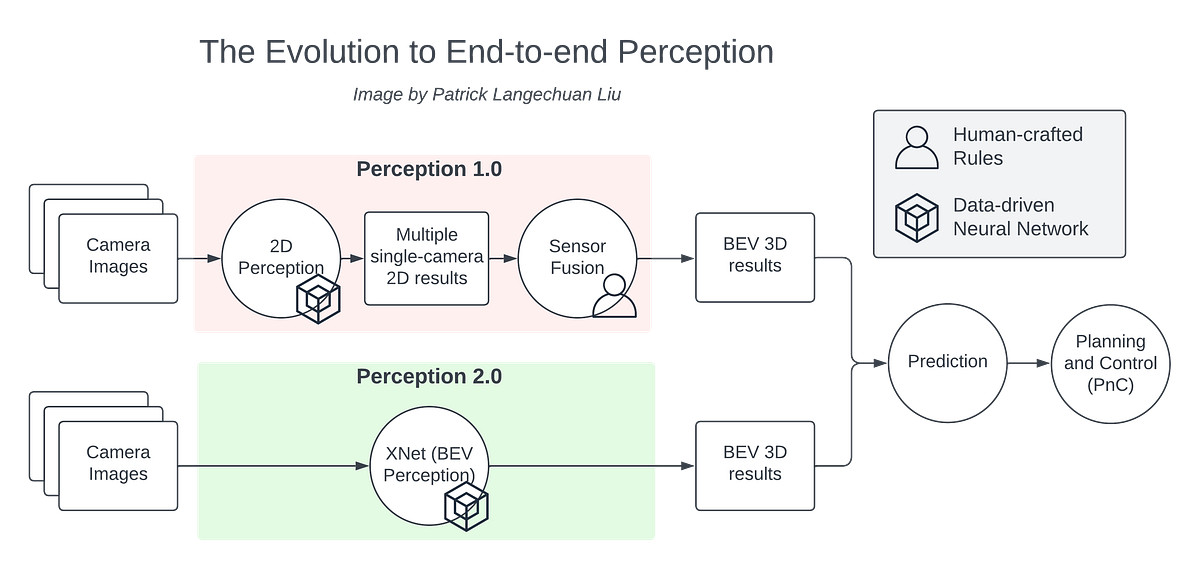
量産自動運転におけるBEVパーセプション
BEVの認識技術は、ここ数年で非常に進歩しました自動運転車の周りの環境を直接認識することができますBEVの認識技術はエンド・トゥ・エンドと考えることができます
PyTorchモデルのパフォーマンス分析と最適化—Part2
これは、GPU上で実行されるPyTorchモデルの分析と最適化に関する一連の投稿の第二部です最初の投稿では、プロセスとその重要な可能性を示しました...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.