Learn more about Search Results ML - Page 380

- You may be interested
- デバイス上での条件付きテキストから画像...
- Amazon SageMakerのHugging Face推定器と...
- 「2023年に就職するために必要な10のビッ...
- オンラインで機械学習を学ぶ方法
- 「機械学習の公衆の認識に関する問題」
- 「起業家にとって最も優れたChatGPTプロン...
- 2023年のコード生成/コーディングにおける...
- AIは自己を食べるのか?このAI論文では、...
- メタAIのハンプバック!LLMの自己整列と指...
- ベストプロキシサーバー2023
- 「生成AIの布地を調整する:FABRICは反復...
- サムスンのAI研究者が、ニューラルヘアカ...
- Nvidiaは、エンジニア向けに生成AIを試験...
- 「データビジュアルの誤り:一般的なGPT-4...
- 「解釈力を高めたk-Meansクラスタリングの...
PythonからJuliaへ:基本的なデータ操作とEDA
統計計算の領域でエマージングなプログラミング言語として、Julia は近年ますます注目を集めています他の言語に優る2つの特徴があります...

LlamaIndex インデックスと検索のための究極のLLMフレームワーク
LlamaIndex(以前はGPT Indexとして知られていました)は、データ取り込みを容易にする必須ツールを提供することで、LLMを使用したアプリケーションの構築を支援する注目すべきデータフレームワークです
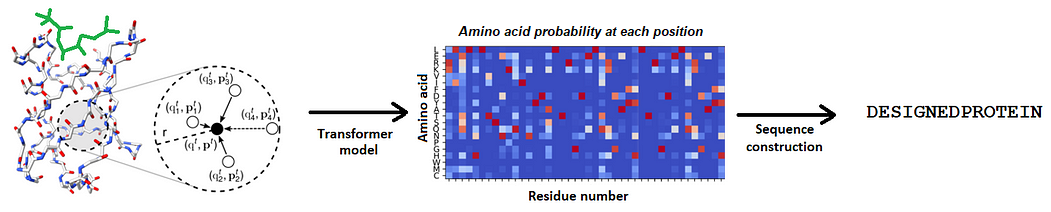
あらゆる種類の分子との相互作用を理解する新しいAIモデルによって、タンパク質デザインの領域での境界を打破する
DeepmindのAlphaFoldによって始まった構造生物学の革命の後、関連するタンパク質設計の分野は、深層学習の力によって最近新しい進展の時代に入りました...
超幾何分布の理解
二項分布は、データサイエンスの内外でよく知られた分布ですしかし、あなたはその人気のないいところのいとこである超幾何分布について聞いたことがありますか?もしそうでない場合、この投稿をご覧ください...

SparkとPlotly Dashを使用したインタラクティブで洞察力のあるダッシュボードの開発
クラウドデータレイクは、すべてのタイプ(構造化および非構造化)のデータのスケーラブルで低コストなリポジトリとして、エンタープライズ組織に広く採用されています分析には多くの課題があります...

予測の作成:Pythonにおける線形回帰の初心者ガイド
最も人気のある機械学習アルゴリズムである線形回帰について、その数学的直感とPythonによる実装をすべて学びましょう

データアナリストは良いキャリアですか?
労働統計局(BLS)によると、データアナリストを含む研究アナリストの雇用は、2021年から2031年までに23%増加すると予想されています。データ分析のキャリアが著しく成長することは、有望な候補者にとっても重要な展望を示しています。それは一般に提供されるサービスや製品に深い影響を与えます。データアナリストとして、コンピュータサイエンス、統計学、数学の技術的な知識と問題解決能力および分析能力を持つ必要があります。この分野は、最先端のテクノロジーを使用する機会が豊富であり、個人的および職業的な成長のための機会を提供します。しかし、この興味深いキャリアパスには、どのような期待が置かれているのでしょうか。企業にデータ分析サービスを提供する理想的な候補者に課せられる期待について探ってみましょう。 データアナリストとは何ですか? データ分析とは、ビジネスの利益に活用するために、データから情報を得ることまたは分析することを指します。この仕事の役割と責任には、以下が含まれます。 分析のためのデータ収集。これには、さまざまな方法を通じてさまざまなタイプのデータを発見または収集することが含まれます。例としては、調査、投票、アンケート、およびウェブサイトの訪問者特性の追跡が挙げられます。必要に応じて、データセットを購入することもできます。 プログラミング言語を使用して、前のステップで生成されたデータ、つまり生データをクリーニングすることが必要です。名前は、処理が必要な外れ値、エラー、重複などの不要な情報の存在を示しています。クリーニングプロセスは、データの品質を向上させて利用可能にすることを目的としています。 データは、今後モデル化する必要があります。これには、データに構造と表現を与えて整理することが含まれます。また、データの分類およびその他の関連プロセスを行うことも必要です。 したがって、形成されたデータは複数の目的に役立ちます。使用法は問題文によって異なり、解釈方法も問題文によって異なります。データの解釈は主に、データ内のトレンドやパターンを見つけることに関係しています。 データのプレゼンテーションも同様に重要なタスクであり、情報が意図した通りに閲覧者や関係者に届くようにすることが最も重要な要件です。これには、プレゼンテーションおよびコミュニケーションスキルが必要です。データアナリストは、グラフやチャートを使用し、報告書の作成や情報のプレゼンテーションを行うことがあります。 データアナリストになる理由 データアナリストになるためには、複数の理由があります。以下は、最も重要な5つの理由です。 高い需要: データの生成が増加したことにより、未処理のデータが大量に存在しています。それには、企業が活用できる多くの秘密が含まれます。このタスクを実行できる個人の要件は急速に増加しており、標準的な要件は年間3000ポジションです。 ダイナミックなフィールド: データアナリストの仕事は、課題に対処し、問題を解決することに喜びを感じる場合、多くのものを提供します。毎日興味深く、新しい課題があり、分析思考とブレストストーミングが必要な場所です。また、旅の中で多くを学ぶこともでき、自己改善に貢献します。 高い報酬: データアナリストのポジションの報酬は高く、キャリアを追求する価値があります。給与の増加は、業界によって異なり、一部の分野ではボーナスを含む高い収入が約束されています。 普遍性: データアナリストの要件は、特定の分野に限定されるものではありません。すべての業界が多くのデータを生成し、情報に基づく論理的な意思決定が必要です。したがって、背景や興味に関係なく、すべての専門分野に開かれています。 キャリアの選択をリード: 熟練したデータアナリストは、ポジションと会社に価値をもたらすことができます。成長、昇進、追加の福利厚生の可能性はどこでも開かれています。グループをリードしたり、教えたり、競争したり、ワークフォースの文化を形成することができるように、キャリアの選択をリードすることができます。 需要と将来の仕事のトレンド 現在、データアナリストの需要は高く、良い報酬が期待できます。現在のデータ生成の速度に基づいて、将来的には需要がさらに高まると予想されています。新しいテクノロジーの生成とデータ収集の容易化により、将来的には才能に新しい機会が提供されるでしょう。将来のデータアナリストの予想される新しいジョブロールには、以下が含まれます。 AIの機能性と適合性を説明する。新しく開発された機能の品質分析。 ビジネスオペレーションとデータ処理のリアルタイム分析の組み合わせに取り組む。これにより、戦略に基づいた計画に向けて導かれます。…

PDFの変換:PythonにおけるTransformerを用いた情報の要約化
はじめに トランスフォーマーは、単語の関係を捉えることにより正確なテキスト表現を提供し、自然言語処理を革新しています。PDFから重要な情報を抽出することは今日不可欠であり、トランスフォーマーはPDF要約の自動化に効率的な解決策を提供します。トランスフォーマーの適応性により、これらのモデルは法律、金融、学術などのさまざまなドキュメント形式を扱うのに貴重なものになっています。この記事では、トランスフォーマーを使用したPDF要約を紹介するPythonプロジェクトを紹介します。このガイドに従うことで、読者はこれらのモデルの変革的な可能性を活かし、広範なPDFから洞察を得ることができます。自動化されたドキュメント分析のためにトランスフォーマーの力を活用し、効率的な旅に乗り出しましょう。 学習目標 このプロジェクトでは、読者は以下の学習目標に沿った重要なスキルを身につけることができます。 トランスフォーマーの複雑な操作を深く理解し、テキスト要約などの自然言語処理タスクの取り組み方を革新する。 PyPDF2などの高度なPythonライブラリを使用してPDFのパースとテキスト抽出を行う方法を学び、さまざまなフォーマットとレイアウトの扱いに関する複雑さに対処する。 トークン化、ストップワードの削除、ユニークな文字やフォーマットの複雑さに対処するなど、テキスト要約の品質を向上させるための必須の前処理技術に精通する。 T5などの事前学習済みトランスフォーマーモデルを使用して、高度なテキスト要約技術を適用することで、トランスフォーマーの力を引き出す。PDFドキュメントの抽出的要約に対応する実践的な経験を得る。 この記事はData Science Blogathonの一部として公開されました。 プロジェクトの説明 このプロジェクトでは、Pythonトランスフォーマーの可能性を活かして、PDFファイルの自動要約を実現することを目的としています。PDFから重要な詳細を抽出し、手動分析の手間を軽減することを目指しています。トランスフォーマーを使用してテキスト要約を行うことで、文書分析を迅速化し、効率性と生産性を高めることを目指しています。事前学習済みのトランスフォーマーモデルを実装することで、PDFドキュメント内の重要な情報を簡潔な要約にまとめることを目指しています。トランスフォーマーを使用して、プロジェクトでPDF要約を合理化するための専門知識を提供することがプロジェクトの目的です。 問題の説明 PDFドキュメントから重要な情報を抽出するために必要な時間と人的労力を最小限に抑えることは、大きな障壁です。長いPDFを手動で要約することは、手間のかかる作業であり、人的ミスによる限界と、膨大なテキストデータを扱う能力の限界があります。これらの障壁は、PDFが多数存在する場合には効率性と生産性を著しく阻害します。 トランスフォーマーを使用してこのプロセスを自動化する重要性は過小評価できません。トランスフォーマーの変革的な能力を活用することで、PDFドキュメントから重要な洞察、注目すべき発見、重要な議論を包括する重要な詳細を自律的に抽出することができます。トランスフォーマーの展開により、要約ワークフローが最適化され、人的介入が軽減され、重要な情報の取得が迅速化されます。この自動化により、異なるドメインの専門家が迅速かつ適切な意思決定を行い、最新の研究に精通し、PDFドキュメントの膨大な情報を効果的にナビゲートできるようになります。 アプローチ このプロジェクトにおける私たちの革新的なアプローチは、トランスフォーマーを使用してPDFドキュメントを要約することです。私たちは、完全に新しい文を生成するのではなく、元のテキストから重要な情報を抽出する抽出的テキスト要約に重点を置くことにします。これは、PDFから抽出された重要な詳細を簡潔かつ分かりやすくまとめることがプロジェクトの目的に合致しています。 このアプローチを実現するために、以下のように進めます。 PDFのパースとテキスト抽出: PyPDF2ライブラリを使用してPDFファイルをナビゲートし、各ページからテキストコンテンツを抽出します。抽出されたテキストは、後続の処理のために細心の注意を払ってコンパイルされます。 テキストエンコードと要約: transformersライブラリを使用して、T5ForConditionalGenerationモデルの力を利用します。事前に学習された能力を持つこのモデルは、テキスト生成タスクにとって重要な役割を果たします。モデルとトークナイザを初期化し、T5トークナイザを使用して抽出されたテキストをエンコードし、後続のステップで適切な表現を確保します。 要約の生成:…
PyTorchを使った転移学習の実践ガイド
この記事では、転移学習と呼ばれる技術を使用して、カスタム分類タスクに事前学習済みモデルを適応する方法を学びますPyTorchを使用した画像分類タスクで、Vgg16、ResNet50、およびResNet152の3つの事前学習済みモデルで転移学習を比較します
OpenAIのWhisper APIによる転写と翻訳
この記事では、OpenAIのWhisper APIを使用してオーディオをテキストに変換する方法を紹介しますまた、自分自身のプロジェクトでの使用方法やデータサイエンスプロジェクトへの統合方法も説明します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.