Learn more about Search Results T5 - Page 37

- You may be interested
- ヘッドショットプロのレビュー:2時間で12...
- 「データストラテジストになりますか?」
- AIを用いた遺伝子発現の予測
- データ体験の再発明:生成的AIと現代的な...
- 「データサイエンティストの履歴書を他と...
- 「インタリーブされた視覚と言語の生成に...
- データサイエンティストにとって使いやす...
- BigBirdのブロック疎な注意機構の理解
- 『プロンプトブリーダーの内部:Google De...
- ミニGPT-5:生成的なヴォケンによる交錯し...
- 作曲家:AIツールを使った投資の学び方
- 「AI自動化と性別格差:AIが女性労働者に...
- がん診断の革命:ディープラーニングが正...
- 「ニューロンの多様性を受け入れる:AIの...
- 「エローの有名なレーティングシステムに...
線形回帰の理論的な深堀り
多くのデータサイエンス志望のブロガーが行うことがあります 線形回帰に関する入門的な記事を書くことですこれは、この分野に入る際に最初に学ぶモデルの1つであるため、自然な選択肢です...

MetaのAIが参照メロディに基づいて音楽を生成する方法
2023年6月13日、Meta(以前のFacebook)は、生成音楽モデルであるMusicGenをリリースし、音楽とAIコミュニティに衝撃を与えましたこのモデルは、GoogleのMusicLMを超えるだけでなく...

レトロなデータサイエンス:YOLOの最初のバージョンのテスト
データサイエンスの世界は常に変化していますしばしば、変化がゆっくりと進んでいるため、私たちはそれらを見ることができないことがありますが、時間が経過すると、風景が見えやすくなります...

将来のPythonバージョン(3.12など)に一般のユーザーに先駆けてアクセスする方法
Python 3.12などの将来のバージョンを群衆より先にインストールしてテストする方法についてのチュートリアルで、新しい機能を体験して競争上の優位性を獲得する方法

マルチヘッドアテンションを使用した注意機構の理解
はじめに Transformerモデルについて詳しく学ぶ良い方法は、アテンションメカニズムについて学ぶことです。特に他のタイプのアテンションメカニズムを学ぶ前に、マルチヘッドアテンションについて学ぶことは良い選択です。なぜなら、この概念は少し理解しやすい傾向があるためです。 アテンションメカニズムは、通常の深層学習モデルに追加できるニューラルネットワークレイヤーと見なすことができます。これにより、重要な部分に割り当てられた重みを使用して、入力の特定の部分に焦点を当てるモデルを作成することができます。ここでは、マルチヘッドアテンションメカニズムを使用して、アテンションメカニズムについて詳しく見ていきます。 学習目標 アテンションメカニズムの概念 マルチヘッドアテンションについて Transformerのマルチヘッドアテンションのアーキテクチャ 他のタイプのアテンションメカニズムの概要 この記事は、データサイエンスブログマラソンの一環として公開されました。 アテンションメカニズムの理解 まず、この概念を人間の心理学から見てみましょう。心理学では、注意は他の刺激の影響を除外して、イベントに意識を集中することです。つまり、他の注意を引くものがある場合でも、私たちは選択したものに焦点を合わせます。注意は全体の一部に集中します。 これがTransformerで使用される概念です。彼らは入力のターゲット部分に焦点を当て、残りの部分を無視することができます。これにより、非常に効果的な方法で動作することができます。 マルチヘッドアテンションとは? マルチヘッドアテンションは、Transformerにおいて中心的なメカニズムであり、ResNet50アーキテクチャにおけるskip-joiningに相当します。場合によっては、アテンドするべきシーケンスの複数の他の点があります。全体の平均を見つける方法では、重みを分散させて多様な値を重みとして与えることができません。これにより、複数のアテンションメカニズムを個別に作成するアイデアが生まれ、複数のアテンションメカニズムが生じます。実装では、1つの機能に複数の異なるクエリキー値トリプレットが表示されます。 出典:Pngwing.com 計算は、アテンションモジュールが何度も反復し、アテンションヘッドとして知られる並列レイヤーに組織化される方法で実行されます。各別のヘッドは、入力シーケンスと関連する出力シーケンスの要素を独立して処理します。各ヘッドからの累積スコアは、すべての入力シーケンスの詳細を組み合わせた最終的なアテンションスコアを得るために組み合わされます。 数式表現 具体的には、キーマトリックスとバリューマトリックスがある場合、値をℎサブクエリ、サブキー、サブバリューに変換し、アテンションを独立して通過させることができます。連結すると、ヘッドが得られ、最終的な重み行列でそれらを組み合わせます。 学習可能なパラメータは、アテンションに割り当てられた値であり、各パラメータはマルチヘッドアテンションレイヤーと呼ばれます。以下の図はこのプロセスを示しています。 これらの変数を簡単に見てみましょう。Xの値は、単語埋め込みの行列の連結です。 行列の説明 クエリ:シーケンスのターゲットについての洞察を提供する特徴ベクトルです。クエリは、何がアテンションを必要としているかをシーケンスに要求します。 キー:要素に含まれるものを説明する特徴ベクトルです。クエリによってアテンションが与えられ、要素のアイデンティティを提供します。 値:…

新たな能力が明らかに:GPT-4のような成熟したAIのみが自己改善できるのか?言語モデルの自律的成長の影響を探る
研究者たちは、AlphaGo Zeroと同様に、明確に定義されたルールで競争的なゲームに反復的に参加することによってAIエージェントが自己発展する場合、多くの大規模言語モデル(LLM)が人間の関与がほとんどない交渉ゲームでお互いを高め合う可能性があるかどうかを調査しています。この研究の結果は、遠い影響を与えるでしょう。エージェントが独立に進歩できる場合、少数の人間の注釈で強力なエージェントを構築することができるため、今日のデータに飢えたLLMトレーニングに対して対照的です。それはまた、人間の監視がほとんどない強力なエージェントを示唆しており、問題があります。この研究では、エジンバラ大学とAIアレン研究所の研究者が、顧客と売り手の2つの言語モデルを招待して購入の交渉を行うようにしています。 図1:交渉ゲームの設定。彼らは2つのLLMエージェントを招待して、値切りのゲームで売り手と買い手をプレイさせます。彼らの目標は、より高い値段で製品を販売または購入することです。彼らは第三のLLMであるAI批評家に、ラウンド後に向上させたいプレイヤーを指定してもらいます。その後、批判に基づいて交渉戦術を調整するようにプレイヤーに促します。これを数ラウンド繰り返すことで、モデルがどんどん上達するかどうかを確認します。 顧客は製品の価格を下げたいと思っていますが、売り手はより高い価格で販売するように求められています(図1)。彼らは第三の言語モデルに批評家の役割を担ってもらい、取引が成立した後にプレイヤーにコメントを提供させます。次に、批評家LLMからのAI入力を利用して、再度ゲームをプレイし、プレイヤーにアプローチを改善するように促します。彼らは交渉ゲームを選んだ理由は、明確に定義されたルールと、戦術的な交渉のための特定の数量化目標(より低い/高い契約価格)があるためです。ゲームは最初は単純に見えますが、モデルは次の能力を持っている必要があります。 交渉ゲームのテキストルールを明確に理解し、厳密に遵守すること。 批評家LLMによって提供されるテキストフィードバックに対応し、反復的に改善すること。 長期的にストラテジーとフィードバックを反映し、複数のラウンドで改善すること。 彼らの実験では、モデルget-3.5-turbo、get-4、およびClaude-v1.3のみが交渉ルールと戦略を理解し、AIの指示に適切に合致している必要があるという要件を満たしています。その結果、彼らが考慮したモデルすべてがこれらの能力を示さなかったことが示されています(図2)。初めに、彼らはボードゲームやテキストベースのロールプレイングゲームなど、より複雑なテキストゲームもテストしましたが、エージェントがルールを理解して遵守することがより困難であることが判明しました。彼らの方法はICL-AIF(AIフィードバックからのコンテキスト学習)として知られています。 図2:私たちのゲームで必要な能力に基づいて、モデルは複数の階層に分けられます(C2-交渉、C3-AIフィードバック、C4-継続的な改善)。私たちの研究は、gpt-4やclaude-v1.3などの堅牢で適切に合致したモデルだけが反復的なAI入力から利益を得て、常に発展することができることを明らかにしています。 彼らは、AI批評家のコメントと前回の対話履歴ラウンドをコンテキストに応じたデモンストレーションとして利用しています。これにより、プレイヤーの前回の実際の開発と批評家の変更アイデアが、次のラウンドの交渉のためのフューショットキューに変換されます。2つの理由から、彼らはコンテキストでの学習を使用しています:(1)強化学習を用いた大規模な言語モデルの微調整は、高額であるため、(2)コンテキストでの学習は、勾配降下に密接に関連していることが最近示されたため、モデルの微調整を行う場合には、彼らが引き出す結論がかなり一般的になることが期待されます(資源が許される場合)。 人間からのフィードバックによる強化学習(RLHF)の報酬は通常スカラーですが、ICL-AIFでは、フィードバックが自然言語で提供されます。これは、2つのアプローチの注目すべき違いです。各ラウンド後に人間の相互作用に依存する代わりに、よりスケーラブルでモデルの進歩に役立つAIのフィードバックを検討しています。 異なる責任を負うときにフィードバックを与えられた場合、モデルは異なる反応を示します。バイヤー役のモデルを改善することは、ベンダー役のモデルよりも難しい場合があります。過去の知識とオンライン反復的なAIフィードバックを利用して、get-4のような強力なエージェントが常に意味のある開発を続けることができるとしても、何かをより高く売る(またはより少ないお金で何かを購入する)ことは、全く取引が成立しないリスクがあります。彼らはまた、モデルがより簡潔であるがより綿密(そして最終的にはより成功する)交渉に従事できることを証明しています。全体的に、彼らは自分たちの仕事がAIフィードバックのゲーム環境での言語モデルの交渉を向上させる重要な一歩になると期待しています。コードはGitHubで利用可能です。

GPT-5から何を期待できるのか?
私たちが皆待ち望んでいた瞬間-GPT-5とその前身であるGPT-4の印象的な能力
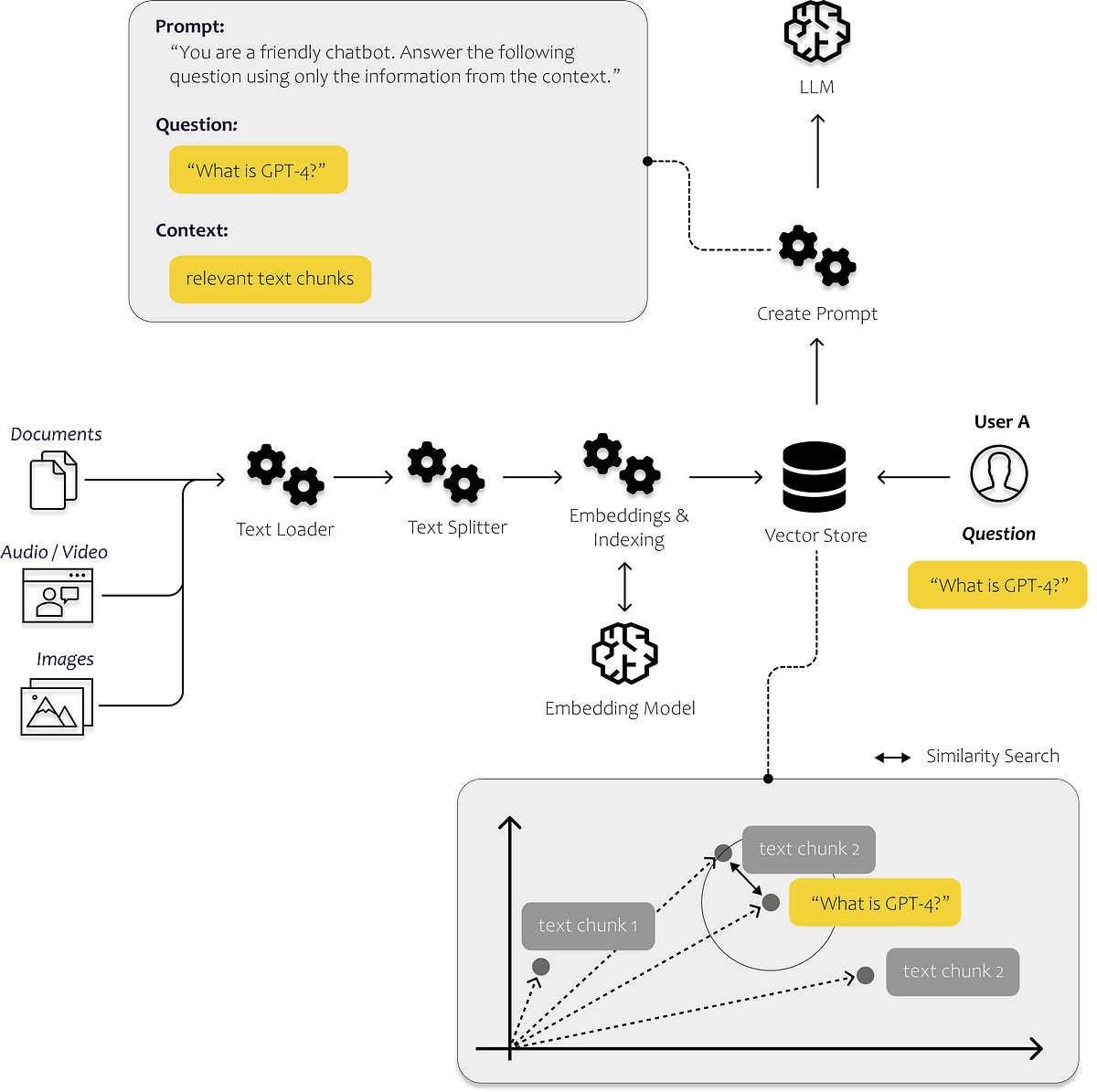
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...

PDFの変換:PythonにおけるTransformerを用いた情報の要約化
はじめに トランスフォーマーは、単語の関係を捉えることにより正確なテキスト表現を提供し、自然言語処理を革新しています。PDFから重要な情報を抽出することは今日不可欠であり、トランスフォーマーはPDF要約の自動化に効率的な解決策を提供します。トランスフォーマーの適応性により、これらのモデルは法律、金融、学術などのさまざまなドキュメント形式を扱うのに貴重なものになっています。この記事では、トランスフォーマーを使用したPDF要約を紹介するPythonプロジェクトを紹介します。このガイドに従うことで、読者はこれらのモデルの変革的な可能性を活かし、広範なPDFから洞察を得ることができます。自動化されたドキュメント分析のためにトランスフォーマーの力を活用し、効率的な旅に乗り出しましょう。 学習目標 このプロジェクトでは、読者は以下の学習目標に沿った重要なスキルを身につけることができます。 トランスフォーマーの複雑な操作を深く理解し、テキスト要約などの自然言語処理タスクの取り組み方を革新する。 PyPDF2などの高度なPythonライブラリを使用してPDFのパースとテキスト抽出を行う方法を学び、さまざまなフォーマットとレイアウトの扱いに関する複雑さに対処する。 トークン化、ストップワードの削除、ユニークな文字やフォーマットの複雑さに対処するなど、テキスト要約の品質を向上させるための必須の前処理技術に精通する。 T5などの事前学習済みトランスフォーマーモデルを使用して、高度なテキスト要約技術を適用することで、トランスフォーマーの力を引き出す。PDFドキュメントの抽出的要約に対応する実践的な経験を得る。 この記事はData Science Blogathonの一部として公開されました。 プロジェクトの説明 このプロジェクトでは、Pythonトランスフォーマーの可能性を活かして、PDFファイルの自動要約を実現することを目的としています。PDFから重要な詳細を抽出し、手動分析の手間を軽減することを目指しています。トランスフォーマーを使用してテキスト要約を行うことで、文書分析を迅速化し、効率性と生産性を高めることを目指しています。事前学習済みのトランスフォーマーモデルを実装することで、PDFドキュメント内の重要な情報を簡潔な要約にまとめることを目指しています。トランスフォーマーを使用して、プロジェクトでPDF要約を合理化するための専門知識を提供することがプロジェクトの目的です。 問題の説明 PDFドキュメントから重要な情報を抽出するために必要な時間と人的労力を最小限に抑えることは、大きな障壁です。長いPDFを手動で要約することは、手間のかかる作業であり、人的ミスによる限界と、膨大なテキストデータを扱う能力の限界があります。これらの障壁は、PDFが多数存在する場合には効率性と生産性を著しく阻害します。 トランスフォーマーを使用してこのプロセスを自動化する重要性は過小評価できません。トランスフォーマーの変革的な能力を活用することで、PDFドキュメントから重要な洞察、注目すべき発見、重要な議論を包括する重要な詳細を自律的に抽出することができます。トランスフォーマーの展開により、要約ワークフローが最適化され、人的介入が軽減され、重要な情報の取得が迅速化されます。この自動化により、異なるドメインの専門家が迅速かつ適切な意思決定を行い、最新の研究に精通し、PDFドキュメントの膨大な情報を効果的にナビゲートできるようになります。 アプローチ このプロジェクトにおける私たちの革新的なアプローチは、トランスフォーマーを使用してPDFドキュメントを要約することです。私たちは、完全に新しい文を生成するのではなく、元のテキストから重要な情報を抽出する抽出的テキスト要約に重点を置くことにします。これは、PDFから抽出された重要な詳細を簡潔かつ分かりやすくまとめることがプロジェクトの目的に合致しています。 このアプローチを実現するために、以下のように進めます。 PDFのパースとテキスト抽出: PyPDF2ライブラリを使用してPDFファイルをナビゲートし、各ページからテキストコンテンツを抽出します。抽出されたテキストは、後続の処理のために細心の注意を払ってコンパイルされます。 テキストエンコードと要約: transformersライブラリを使用して、T5ForConditionalGenerationモデルの力を利用します。事前に学習された能力を持つこのモデルは、テキスト生成タスクにとって重要な役割を果たします。モデルとトークナイザを初期化し、T5トークナイザを使用して抽出されたテキストをエンコードし、後続のステップで適切な表現を確保します。 要約の生成:…
PyTorchを使った転移学習の実践ガイド
この記事では、転移学習と呼ばれる技術を使用して、カスタム分類タスクに事前学習済みモデルを適応する方法を学びますPyTorchを使用した画像分類タスクで、Vgg16、ResNet50、およびResNet152の3つの事前学習済みモデルで転移学習を比較します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.