Learn more about Search Results CPU - Page 37

- You may be interested
- 『AIのおそらく知られていないトップ4の活...
- 「ハリウッドの自宅:DragNUWAは、制御可...
- 「AIの誤情報:なぜそれが機能するのか、...
- チャットボットの台頭
- 「Javaを使用した脳コンピュータインター...
- VoAGI 2023年3月のトップ投稿:AutoGPT:...
- Google AIがMedLMを導入:医療業界の利用...
- ユーザーフィードバック – MLモニタ...
- 「アマゾン、アントロピックへの40億ドル...
- ベストAI画像生成器(2023年7月)
- 中国が世界最速のインターネットを謳う
- 「新しいアプリが、生成AIを使用してサウ...
- UC BerkeleyとDeepmindの研究者は、Succes...
- CarperAIは、コードと自然言語の両方で進...
- 「スケールナットのレビュー:最高のAI SE...
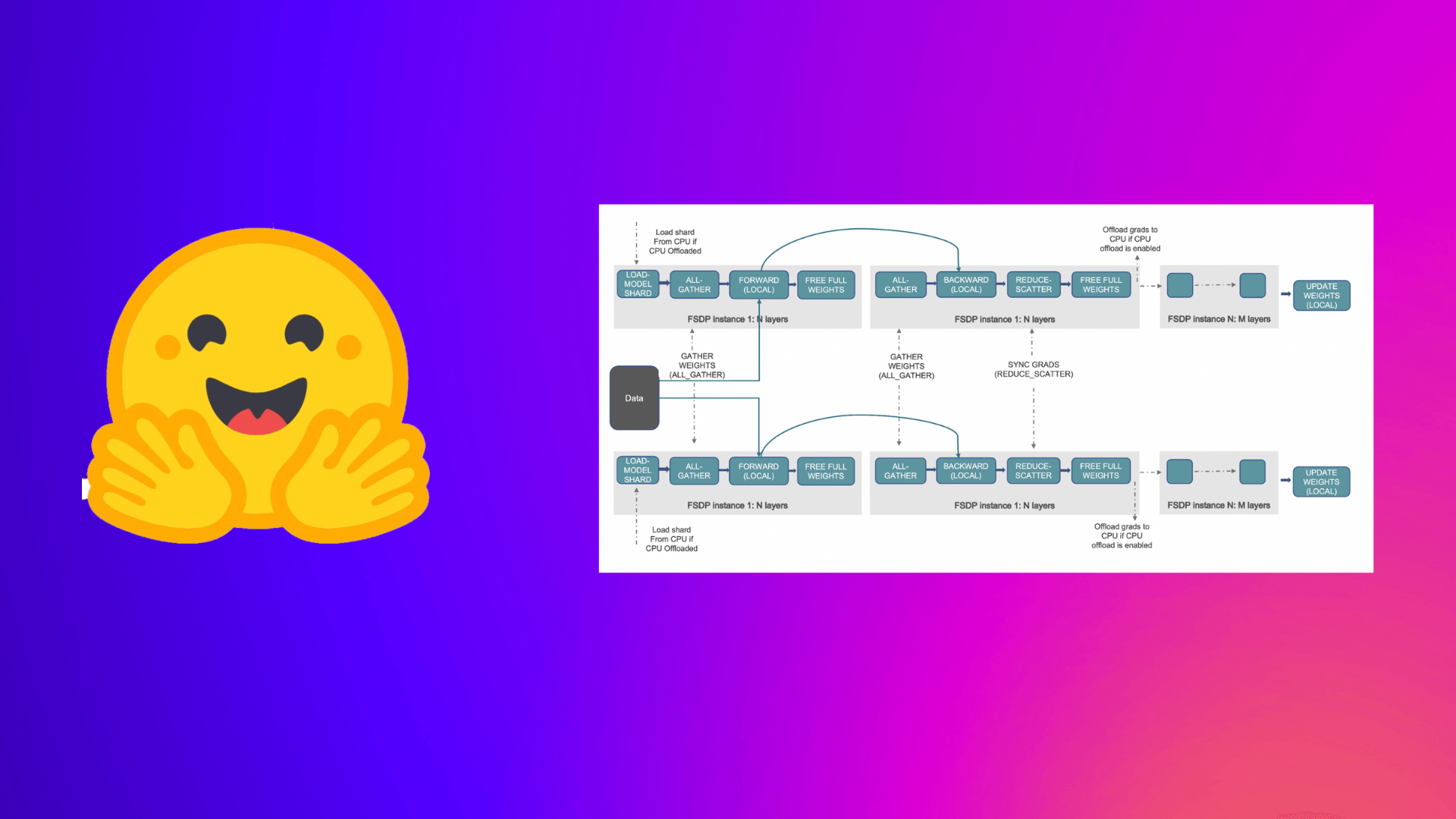
PyTorch完全にシャーディングされたデータパラレルを使用して、大規模モデルのトレーニングを加速する
この投稿では、Accelerate ライブラリを活用して大規模なモデルのトレーニングを行う方法について説明します。これにより、ユーザーは PyTorch FullyShardedDataParallel (FSDP) の最新機能を活用することができます。 機械学習 (ML) モデルのスケール、サイズ、およびパラメータがますます増加するにつれ、ML プラクティショナーは自身のハードウェア上でそのような大規模なモデルをトレーニングしたり、ロードしたりすることが困難になっています。 一方で、大規模なモデルは小さなモデルと比較して学習が速く(データと計算効率が高く)、パフォーマンスも著しく向上することがわかっています [1]。しかし、そのようなモデルをほとんどの利用可能なハードウェア上でトレーニングすることは困難です。 大規模なMLモデルをトレーニングするためには、分散トレーニングが重要です。 分散トレーニング の分野では、最近重要な進展がありました。最も注目すべき進展のいくつかは以下のとおりです: ZeROを用いたデータ並列化 – Zero Redundancy Optimizer [2] ステージ1:データ並列ワーカー/ GPU間でオプティマイザーの状態を分割 ステージ2:データ並列ワーカー/…

最適なパイプラインとトランスフォーマーパイプラインによる高速推論
推論は、Hugging Face TransformersパイプラインをサポートしてOptimumに追加されました。これには、ONNX Runtimeを使用したテキスト生成も含まれます。 BERTとTransformersの採用はますます拡大しています。Transformerベースのモデルは、自然言語処理だけでなく、コンピュータビジョン、音声、時間系列でも最先端の性能を発揮しています。💬 🖼 🎤 ⏳ 企業は、Transformerモデルを大規模なワークロードに使用するため、実験および研究フェーズから本番フェーズに移行しています。ただし、デフォルトでは、BERTおよびその関連製品は、従来の機械学習アルゴリズムと比較して、比較的遅くて大きくて複雑なモデルです。 この課題を解決するために、私たちはOptimumを作成しました。これは、BERTなどのTransformerモデルのトレーニングと推論を高速化するためのHugging Face Transformersの拡張機能です。 このブログ投稿では、次のことを学びます: 1. Optimumとは何ですか?ELI5 2. 新しいOptimum推論とパイプラインの機能 3. RoBERTaの質問応答を加速するためのエンドツーエンドチュートリアル、量子化、最適化を含む 4. 現在の制限事項 5. Optimum推論FAQ 6.…

注釈付き拡散モデル
このブログ記事では、Denoising Diffusion Probabilistic Models(DDPM、拡散モデル、スコアベースの生成モデル、または単にオートエンコーダーとも呼ばれる)について詳しく見ていきます。これらのモデルは、(非)条件付きの画像/音声/ビデオの生成において、驚くべき結果が得られています。具体的な例としては、OpenAIのGLIDEやDALL-E 2、University of HeidelbergのLatent Diffusion、Google BrainのImageGenなどがあります。 この記事では、(Hoら、2020)による元のDDPMの論文を取り上げ、Phil Wangの実装をベースにPyTorchでステップバイステップで実装します。なお、このアイデアは実際には(Sohl-Dicksteinら、2015)で既に導入されていました。ただし、改善が行われるまでには(Stanford大学のSongら、2019)を経て、Google BrainのHoら、2020)が独自にアプローチを改良しました。 拡散モデルにはいくつかの視点がありますので、ここでは離散時間(潜在変数モデル)の視点を採用していますが、他の視点もチェックしてください。 さあ、始めましょう! from IPython.display import Image Image(filename='assets/78_annotated-diffusion/ddpm_paper.png') まず必要なライブラリをインストールしてインポートします(PyTorchがインストールされていることを前提としています)。 !pip install -q -U…
IntelとHugging Faceがパートナーシップを結び、機械学習ハードウェアアクセラレーションを民主化する
Hugging Faceのミッションは、優れた機械学習を民主化し、産業や社会に対するそのポジティブな影響を最大化することです。私たちはTransformerモデルの進歩だけでなく、その採用を簡素化するためにも努力しています。 本日、Intelが正式に私たちのハードウェアパートナープログラムに参加したことをお知らせいたします。Optimumオープンソースライブラリのおかげで、IntelとHugging FaceはTransformerをトレーニング、微調整、予測するための最新のハードウェアアクセラレーションを共同で開発します。 Transformerモデルはますます大きく複雑になっており、検索やチャットボットなどのレイテンシーに敏感なアプリケーションにおいて、生産上の課題を引き起こすことがあります。残念ながら、レイテンシーの最適化は機械学習(ML)の専門家にとって長年の難問でした。基盤となるフレームワークやハードウェアプラットフォームの深い知識があっても、どのツマミや機能を活用するかを見極めるために多くの試行錯誤が必要です。 Intelは、Intel Xeon Scalable CPUプラットフォームと幅広いハードウェア最適化AIソフトウェアツール、フレームワーク、ライブラリを備えた、AIの加速化に完全な基盤を提供します。そのため、Hugging FaceとIntelが力を合わせて、Intelプラットフォーム上での最高のパフォーマンス、スケーラビリティ、生産性を実現するための強力なモデル最適化ツールの開発に取り組むことは理にかなっています。 「Intel XeonハードウェアとIntel AIソフトウェアの最新のイノベーションをTransformersコミュニティにもたらすため、オープンソースの統合と統合された開発者体験を通じてHugging Faceと協力することにワクワクしています。」と、Intel副社長兼AIおよび分析のゼネラルマネージャーであるWei Li氏は述べています。 最近の数ヶ月間、IntelとHugging FaceはTransformerワークロードのスケーリングに取り組んできました。推論(パート1、パート2)の詳細なチューニングガイドとベンチマークを公開し、最新のIntel Xeon Ice Lake CPU上でDistilBERTの単桁ミリ秒レイテンシーを実現しました。トレーニングの側では、GPUよりも40%優れた価格性能を提供するHabana Gaudiアクセラレータのサポートを追加しました。 次の自然なステップは、この作業を拡大してMLコミュニティと共有することでした。それがOptimum Intelオープンソースライブラリの登場です!それをより詳しく見てみましょう。…

埋め込みを使った始め方
ノートブックコンパニオンを使用したこのチュートリアルをチェックしてください: 埋め込みの理解 埋め込みは、テキスト、ドキュメント、画像、音声などの情報の数値表現です。この表現は、埋め込まれているものの意味を捉え、多くの産業アプリケーションに対して堅牢です。 テキスト「投票の主な利点は何ですか?」に対する埋め込みは、たとえば、384個の数値のリスト(例:[0.84、0.42、…、0.02])でベクトル空間で表現されることがあります。このリストは意味を捉えているため、異なる埋め込み間の距離を計算して、2つの文の意味がどれだけ一致するかを判断するなど、興味深いことができます。 埋め込みはテキストに限定されません!画像の埋め込み(たとえば、384個の数値のリスト)を作成し、テキストの埋め込みと比較して文が画像を説明しているかどうかを判断することもできます。この概念は、画像検索、分類、説明などの強力なシステムに適用されています! 埋め込みはどのように生成されるのでしょうか?オープンソースのライブラリであるSentence Transformersを使用すると、画像やテキストから最先端の埋め込みを無料で作成することができます。このブログでは、このライブラリを使用した例を紹介しています。 埋め込みの用途は何ですか? 「[…] このMLマルチツール(埋め込み)を理解すると、検索エンジンからレコメンデーションシステム、チャットボットなど、さまざまなものを構築できます。データサイエンティストやMLの専門家である必要はありませんし、大規模なラベル付けされたデータセットも必要ありません。」- デール・マルコウィッツ、Google Cloud。 情報(文、ドキュメント、画像)が埋め込まれると、創造性が発揮されます。いくつかの興味深い産業アプリケーションでは、埋め込みが使用されます。たとえば、Google検索ではテキストとテキスト、テキストと画像をマッチングさせるために埋め込みを使用しています。Snapchatでは、「ユーザーに適切な広告を適切なタイミングで提供する」ために埋め込みを使用しています。Meta(Facebook)では、ソーシャルサーチに埋め込みを使用しています。 埋め込みから知識を得る前に、これらの企業は情報を埋め込む必要がありました。埋め込まれたデータセットを使用することで、アルゴリズムは素早く検索、ソート、グループ化などを行うことができます。ただし、これは費用がかかり、技術的にも複雑な場合があります。この投稿では、シンプルなオープンソースのツールを使用して、データセットを埋め込み、分析する方法を紹介します。 埋め込みの始め方 小規模なよく寄せられる質問(FAQ)エンジンを作成します。ユーザーからのクエリを受け取り、最も類似したFAQを特定します。米国社会保障メディケアFAQを使用します。 しかし、まず、データセットを埋め込む必要があります(他のテキストでは、エンコードと埋め込みの用語を交換可能に使用します)。Hugging FaceのInference APIを使用すると、簡単なPOSTコールを使用してデータセットを埋め込むことができます。 質問の意味を埋め込みが捉えるため、異なる埋め込みを比較してどれだけ異なるか、または類似しているかを確認することができます。これにより、クエリに最も類似した埋め込みを取得し、最も類似したFAQを見つけることができます。このメカニズムの詳細な説明については、セマンティックサーチのチュートリアルをご覧ください。 要するに、以下の手順を実行します: Inference APIを使用してメディケアのFAQを埋め込む。 埋め込まれた質問を無料ホスティングするためにHubにアップロードする。…

DeepSpeedを使用して大規模モデルトレーニングを高速化する
この投稿では、Accelerate ライブラリを活用して、ユーザーが DeeSpeed の ZeRO 機能を利用して大規模なモデルをトレーニングする方法について説明します。 大規模なモデルをトレーニングしようとする際にメモリ不足 (OOM) エラーに悩まされていますか?私たちがサポートします。大規模なモデルは非常に高性能ですが、利用可能なハードウェアでトレーニングするのは困難です。大規模なモデルのトレーニングに利用可能なハードウェアの最大限の性能を引き出すために、ZeRO – Zero Redundancy Optimizer [2] を使用したデータ並列処理を活用することができます。 以下は、このブログ記事からの図を使用した ZeRO を使用したデータ並列処理の短い説明です。 (出典: リンク) a. ステージ 1 :…

BLOOMトレーニングの技術背後
近年、ますます大規模な言語モデルの訓練が一般的になってきました。これらのモデルがさらなる研究のために公開されていない問題は頻繁に議論されますが、そのようなモデルを訓練するための技術やエンジニアリングについての隠された知識は滅多に注目されません。本記事では、1760億パラメータの言語モデルBLOOMを例に、そのようなモデルの訓練の裏側にあるハードウェアとソフトウェアの技術とエンジニアリングについて、いくつかの光を当てることを目指しています。 しかし、まず、この素晴らしい1760億パラメータモデルの訓練を可能にするために貢献してくれた企業や主要な人物やグループに感謝したいと思います。 その後、ハードウェアのセットアップと主要な技術的な構成要素について説明します。 以下はプロジェクトの要約です: 人々 このプロジェクトは、Hugging Faceの共同創設者でありCSOのThomas Wolf氏が考案しました。彼は巨大な企業と競争し、単なる夢だったものを実現し、最終的な結果をすべての人にアクセス可能にすることで、最も多くの人々にとっては夢であったものを実現しました。 この記事では、モデルの訓練のエンジニアリング側に特化しています。BLOOMの背後にある技術の最も重要な部分は、私たちにコーディングと訓練の助けを提供してくれた専門家の人々と企業です。 感謝すべき6つの主要なグループがあります: HuggingFaceのBigScienceチームは、数人の専任の従業員を捧げ、訓練を始めから終わりまで行うための方法を見つけるために、Jean Zayの計算機を超えるすべてのインフラストラクチャを提供しました。 MicrosoftのDeepSpeedチームは、DeepSpeedを開発し、後にMegatron-LMと統合しました。彼らの開発者たちはプロジェクトのニーズに多くの時間を費やし、訓練前後に素晴らしい実践的なアドバイスを提供しました。 NVIDIAのMegatron-LMチームは、Megatron-LMを開発し、私たちの多くの質問に親切に答えてくれ、一流の実践的なアドバイスを提供しました。 ジャン・ゼイのスーパーコンピュータを管理しているIDRIS / GENCIチームは、計算リソースをプロジェクトに寄付し、優れたシステム管理のサポートを提供しました。 PyTorchチームは、このプロジェクトのために基礎となる非常に強力なフレームワークを作成し、訓練の準備中に私たちをサポートし、複数のバグを修正し、PyTorchコンポーネントの使いやすさを向上させました。 BigScience Engineeringワーキンググループのボランティア プロジェクトのエンジニアリング側に貢献してくれたすべての素晴らしい人々を全て挙げることは非常に困難なので、Hugging Face以外のいくつかの主要な人物を挙げます。彼らはこのプロジェクトのエンジニアリングの基盤となりました。 Olatunji Ruwase、Deepak…
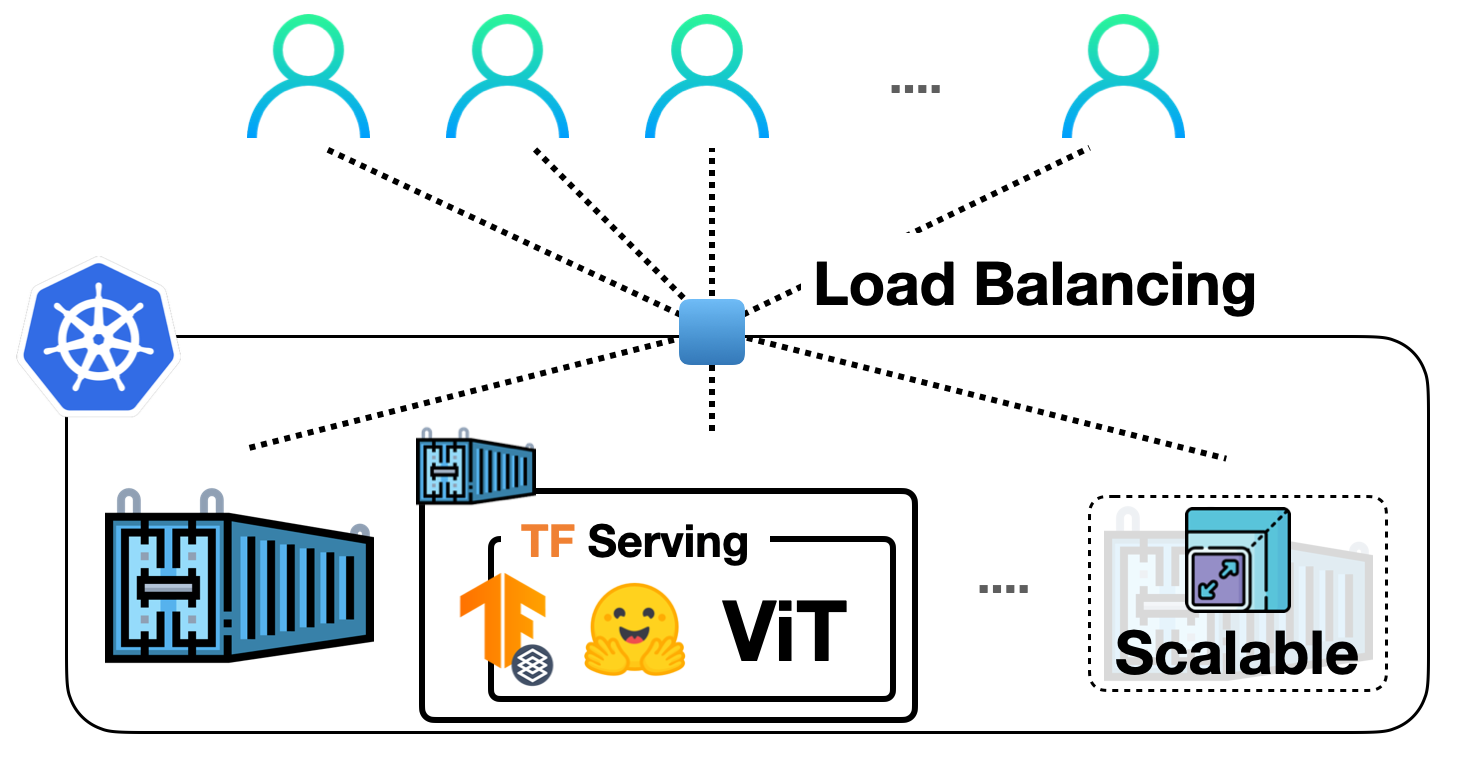
TF Servingを使用してKubernetes上に🤗 ViTをデプロイする
前の投稿では、TensorFlow Servingを使用して🤗 TransformersからVision Transformer(ViT)モデルをローカルに展開する方法を示しました。ビジョントランスフォーマーモデル内での埋め込み前処理および後処理操作、gRPCリクエストの処理など、さまざまなトピックをカバーしました! ローカル展開は、有用なものを構築するための優れたスタート地点ですが、実際のプロジェクトで多くのユーザーに対応できる展開を実行する必要があります。この投稿では、前の投稿のローカル展開をDockerとKubernetesでスケーリングする方法を学びます。したがって、DockerとKubernetesに関する基本的な知識が必要です。 この投稿は前の投稿に基づいていますので、まずそれをお読みいただくことを強くお勧めします。この投稿で説明されているコードは、このリポジトリで確認することができます。 私たちの展開をスケールアップする基本的なワークフローは、次のステップを含みます: アプリケーションロジックのコンテナ化:アプリケーションロジックには、リクエストを処理して予測を返すサービスモデルが含まれます。コンテナ化するために、Dockerが業界標準です。 Dockerコンテナの展開:ここにはさまざまなオプションがあります。最も一般的に使用されるオプションは、DockerコンテナをKubernetesクラスターに展開することです。Kubernetesは、展開に便利な機能(例:自動スケーリングとセキュリティ)を提供します。ローカルでKubernetesクラスターを管理するためのMinikubeのようなソリューションや、Elastic Kubernetes Service(EKS)のようなサーバーレスソリューションを使用することもできます。 SagemakerやVertex AIのような、MLデプロイメント固有の機能をすぐに利用できる時代に、なぜこのような明示的なセットアップを使用するのか疑問に思うかもしれません。それは考えるのは当然です。 上記のワークフローは、業界で広く採用され、多くの組織がその恩恵を受けています。長年にわたってすでに実戦投入されています。また、複雑な部分を抽象化しながら、展開に対してより細かな制御を持つことができます。 この投稿では、Google Kubernetes Engine(GKE)を使用してKubernetesクラスターをプロビジョニングおよび管理することを前提としています。GKEを使用する場合、請求を有効にしたGCPプロジェクトが既にあることを想定しています。また、GKEで展開を行うためにgcloudユーティリティを構成する必要があります。ただし、Minikubeを使用する場合でも、この投稿で説明されているコンセプトは同様に適用されます。 注意:この投稿で表示されるコードスニペットは、gcloudユーティリティとDocker、kubectlが構成されている限り、Unixターミナルで実行できます。詳しい手順は、付属のリポジトリで入手できます。 サービングモデルは、生のイメージ入力をバイトとして処理し、前処理および後処理を行うことができます。 このセクションでは、ベースのTensorFlow Servingイメージを使用してそのモデルをコンテナ化する方法を示します。TensorFlow Servingは、モデルをSavedModel形式で消費します。前の投稿でSavedModelを取得した方法を思い出してください。ここでは、SavedModelがtar.gz形式で圧縮されていることを前提としています。万が一必要な場合は、ここから入手できます。その後、SavedModelは<MODEL_NAME>/<VERSION>/<SavedModel>という特別なディレクトリ構造に配置する必要があります。これにより、TensorFlow Servingは異なるバージョンのモデルの複数の展開を同時に管理できます。 Dockerイメージの準備…

Hugging FaceのTensorFlowの哲学
はじめに PyTorchやJAXからの競争が増えても、TensorFlowは最も使用されるディープラーニングフレームワークのままです。また、それらの他の2つのライブラリとはいくつか非常に重要な点で異なります。特に、高レベルのAPIであるKerasと、データの読み込みライブラリであるtf.dataとの統合が非常に密接です。 PyTorchのエンジニアの中には(ここでオープンプランオフィスを暗く見つめながら私を想像してください)、これを克服すべき問題だと見なす傾向があります。彼らの目標は、TensorFlowが彼らのやり方に従って低レベルのトレーニングとデータの読み込みコードを使用できるようにする方法を見つけることです。これはTensorFlowに取り組む間違った方法です! Kerasは素晴らしい高レベルのAPIです。プロジェクトが数モジュールよりも大きい場合、それを押しのけると、必要になると気付いたときに、その機能のほとんどを自分で再現することになります。 洗練された、尊敬され、非常に魅力的なTensorFlowエンジニアとして、私たちは最先端のモデルの驚異的なパワーと柔軟性を使用したいと思っていますが、私たちが使い慣れたツールとAPIでそれらを扱いたいのです。このブログポストでは、Hugging Faceでそれを実現するために行う選択と、TensorFlowプログラマーとしてフレームワークから期待できることについて説明します。 インタールード:30秒で🤗 経験豊富なユーザーは、このセクションをざっと読んだりスキップしたりして構いませんが、Hugging Faceとtransformersに初めて出会う方には、ライブラリのコアアイデアについて概要を説明する必要があります。モデルを事前学習済みモデルとして名前でリクエストするだけで、1行のコードで取得できます。最も簡単な方法は、TFAutoModelクラスを使用するだけです。 from transformers import TFAutoModel model = TFAutoModel.from_pretrained("bert-base-cased") この1行でモデルのアーキテクチャがインスタンス化され、重みが読み込まれます。これにより、元の有名なBERTモデルの正確なレプリカが得られます。ただし、このモデル自体ではあまり役に立ちません – 出力ヘッドや損失関数がありません。実際には、これは最後の隠れ層の直後で終了するニューラルネットワークの「ステム」です。では、どのようにして出力ヘッドを追加するのでしょうか?簡単です、異なるAutoModelクラスを使用するだけです。ここでは、Vision Transformer(ViT)モデルを読み込み、画像分類ヘッドを追加しています。 from transformers import TFAutoModelForImageClassification…

transformers、accelerate、bitsandbytesを使用した大規模トランスフォーマーの8ビット行列乗算へのやさしい入門
導入 言語モデルはますます大きくなっています。この執筆時点では、PaLMは540Bのパラメータを持ち、OPT、GPT-3、およびBLOOMは約176Bのパラメータを持ち、さらに大きなモデルに向かっています。以下は、いくつかの最近の言語モデルのサイズを示した図です。 したがって、これらのモデルは簡単にアクセス可能なデバイス上で実行するのが難しいです。例えば、BLOOM-176Bで推論を行うためには、8つの80GBのA100 GPU(各約15,000ドル)が必要です。BLOOM-176Bを微調整するには、これらのGPUが72台必要です!PaLMのようなさらに大きなモデルでは、さらに多くのリソースが必要です。 これらの巨大なモデルは多くのGPUで実行する必要があるため、モデルの性能を維持しながらこれらの要件を削減する方法を見つける必要があります。モデルサイズを縮小するためのさまざまな技術が開発されており、量子化や蒸留などの技術があります。 BLOOM-176Bのトレーニングを完了した後、HuggingFaceとBigScienceでは、この大きなモデルをより少ないGPUで簡単に実行できるようにする方法を探していました。BigScienceコミュニティを通じて、大規模モデルの予測パフォーマンスを低下させずに大規模モデルのメモリフットプリントを2倍に減らすInt8推論の研究について知らされました。すぐにこの研究に協力し始め、Hugging Faceのtransformersに完全に統合することで終了しました。このブログ記事では、Hugging FaceモデルのLLM.int8()統合を提供し、詳細を以下で説明します。研究についてもっと読みたい場合は、論文「LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale」を読んでください。 この記事では、この量子化技術の高レベルの概要を提供し、transformersライブラリへの統合の難しさを概説し、このパートナーシップの長期的な目標を立てます。 ここでは、なぜ大きなモデルが多くのメモリを使用するのか、BLOOMが350GBになる理由について、少しずつ基本的な前提を説明します。 機械学習で使用される一般的なデータ型 まず、機械学習の文脈では「精度」とも呼ばれる異なる浮動小数点データ型の基本的な理解から始めます。 モデルのサイズは、そのパラメータの数とその精度によって決まります。一般的には、float32、float16、またはbfloat16のいずれかのデータ型が使用されます(以下の画像は、https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/から引用されています)。 Float32(FP32)は、標準化されたIEEE 32ビット浮動小数点表現を表します。このデータ型では、幅広い浮動小数点数を表現することが可能です。FP32では、8ビットが「指数」に、23ビットが「仮数」に、1ビットが数値の符号に予約されています。さらに、ほとんどのハードウェアはFP32の操作と命令をサポートしています。 浮動小数点16ビット(FP16)のデータ型では、5ビットが指数に、10ビットが仮数に予約されています。これにより、FP16数の表現可能な範囲はFP32よりもはるかに低くなります。これにより、FP16数はオーバーフロー(非常に大きな数を表現しようとする)やアンダーフロー(非常に小さな数を表現する)のリスクにさらされます。 例えば、10k…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.