Learn more about Search Results Go - Page 376

- You may be interested
- 「Pythonにおける数理最適化入門」
- AI生成アート:倫理的な意義と議論
- マルコフとビネメ・シェビシェフの不等式
- リーンで、意味ありげなAI夢マシン:DejaV...
- 🤗変換器を使用した確率的な時系列予測
- 「テキストを科学的なベクトルグラフィッ...
- スタンフォード大学とFAIR Metaの研究者が...
- 「挑戦受けた:GeForce NOWが究極の挑戦と...
- GPUを活用した特徴量エンジニアリングにお...
- 「ODSC West 2023 の最初の50セッションが...
- 次世代の終わりのない学習者のベンチマーク化
- 「🦜🔗 LangChain は何をするのか?」
- 「推薦エンジンの再構築」
- スケールにおける言語モデリング:Gopher...
- 「モデルガバナンスを向上させるために、A...

マックス・プランク研究所の研究者たちは、MIME(3D人間モーションキャプチャを取得し、その動きに一致する可能性のある3Dシーンを生成する生成AIモデル)を提案しています
人間は常に周囲と相互作用しています。空間を移動したり、物に触れたり、椅子に座ったり、ベッドで寝たりします。これらの相互作用は、シーンの設定やオブジェクトの位置を詳細に示します。マイムは、そのような関係性の理解を利用して、身体の動きだけで豊かで想像力豊かな3D環境を作り出すパフォーマーです。彼らはコンピュータに人間の動作を模倣させて適切な3Dシーンを作ることができるでしょうか?建築、ゲーム、バーチャルリアリティ、合成データの合成など、多くの分野がこの技術に恩恵を受ける可能性があります。たとえば、AMASSなどの3D人間の動きの大規模なデータセットが存在しますが、これらのデータセットには収集された3D設定の詳細がほとんど含まれていません。 AMASSを使用して、すべての動きに対して信憑性の高い3Dシーンを作成できるでしょうか?そうであれば、AMASSを使用してリアルな人間-シーンの相互作用を考慮したトレーニングデータを作成できます。彼らは、MIME(Mining Interaction and Movement to infer 3D Environments)と呼ばれる新しい技術を開発しました。これは、3D人間の動きに基づいて信憑性の高い内部3Dシーンを作成して、このような問いに対応します。それを可能にするのは何でしょうか?基本的な仮定は次のとおりです。(1)空間を移動する人間の動きは、物の欠如を示し、実質的に家具のない画像領域を定義します。また、これにより、シーンに接触する場合の3Dオブジェクトの種類や場所が制限されます。たとえば、座っている人は椅子、ソファ、ベッドなどに座っている必要があります。 図1:人間の動きから3Dシーンを推定します。3D人間の動き(左)から推定された、動きが起こったリアルな3D設定を再現します。彼らの生成モデルは、人間-シーンの相互作用を考慮した、複数のリアリスティックなシナリオ(右)を生成できます。 ドイツのマックスプランク知能システム研究所とAdobeの研究者たちは、これらの直感を具体的な形で示すために、MIMEと呼ばれるトランスフォーマーベースの自己回帰3Dシーン生成技術を作成しました。空のフロアプランと人間の動きシーケンスが与えられると、MIMEは人間と接触する家具を予測します。さらに、人間と接触しないが他のオブジェクトにフィットし、人間の動作によって引き起こされる自由空間の制約に従う信憑性の高いアイテムを予測します。彼らは、人間の動きを接触と非接触のスニペットに分割して、3Dシーン作成を人間の動きに条件付けます。POSAを使用して接触可能なポーズを推定します。非接触姿勢は、足の頂点を地面に投影して、部屋の自由空間を確立し、2Dフロアマップとして記録します。 POSAによって予測された接触頂点は、接触ポーズと関連する3D人体モデルを反映した3D境界ボックスを作成します。接触と自由空間の基準を満たすオブジェクトは、トランスフォーマーへの入力として自己回帰的に期待されます。図1を参照してください。彼らは、3D-FRONTという大規模な合成シーンデータセットを拡張して、MIMEをトレーニングするための新しいデータセットである3D-FRONT HUMANを作成しました。彼らは、RenderPeopleスキャンからの静止接触ポーズと、AMASSからのモーションシーケンスを使用して、3Dシナリオに人を自動的に追加します(一連の歩行モーションと立っている人を含む非接触人と、座って、触れて、横たわっている人を含む接触人)。 MIMEは、3Dバウンディングボックスとして表される入力動作のリアルな3Dシーンレイアウトを推論時に作成します。彼らは、この配置に基づいて3D-FUTUREコレクションから3Dモデルを選択し、人間の位置とシーンの間の幾何学的制約に基づいて3D配置を微調整します。彼らの手法は、ATISSのような純粋な3Dシーン作成システムとは異なり、人間の接触と動きをサポートする3Dセットを作成し、自由空間に説得力のあるオブジェクトを配置することができます。Pose2Roomという最近のポーズ条件付け生成モデルとは異なり、個々のオブジェクトではなく完全なシーンを予測することができます。彼らは、PROX-Dのように記録された本物のモーションシーケンスに対して調整なしで彼らの手法が機能することを示しました。 まとめると、彼らが提供したものは以下の通りです: • 人と接触するものを自動的に生成し、運動定義された空きスペースを占有しないように自己回帰的に作成する、3Dルームシーンの全く新しい運動条件付き生成モデル。 • RenderPeopleの静止接触/立ち姿勢からの3Dモーションデータを用いて、人と自由空間にいる人々が相互作用する3Dシーンデータセットが、3D FRONTを埋めるように作成されました。 コードはGitHubで入手可能であり、ビデオデモとアプローチのビデオ解説も提供されています。
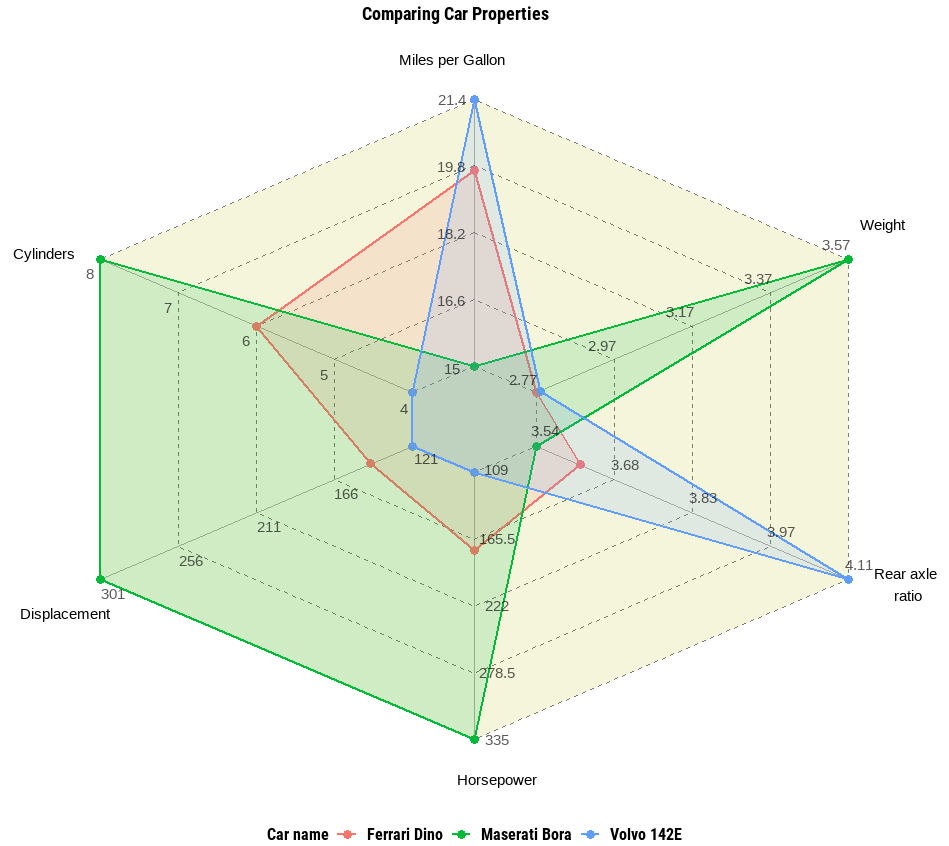
Rのggvancedパッケージを使用したスパイダーチャートと並列チャート
ggplot2パッケージの上に、スパイダーチャートや平行チャートなどの高度な多変数データ可視化を生成するためのパッケージ
スターバックスの報酬プログラムの成功を予測する
このプロジェクトは、スターバックスの現在の顧客を効果的に引きつけ、新しい顧客を獲得するための報酬プログラムオファーを特定することに焦点を当てていますスターバックスはデータに基づく会社であり、入手するために投資を行っています...

あなたのLLMアプリケーションは公開に準備ができていますか?
大規模言語モデル(LLM)は、現代の自然言語処理アプリケーションにおいてパンとバターとなり、固有表現認識モデルなどのより専門的なツールの多様性を多くの面で置き換えています

データサイエンティストのための必須ガイド:探索的データ分析
データを完全に理解するためのベストプラクティス、技術、ツール
AIフロンティアシリーズ:人材
私が初めて参加した「多業種のブレストセッション」から約3年が経ち、かつて野心的だと考えられていた機械学習の概念が、今では人事部門でも実現可能になっていることに驚かされています...

中国における大量生産自動運転の課題
自律走行は、世界でも最も困難な運転の一つが既に存在する中国では、特に難しい課題です主に3つの要因が関係しています:動的...

AIの導入障壁:主要な課題と克服方法
人工知能(AI)がビジネスを革新し、効率を高め、生産性を向上させる方法を発見してくださいAI導入の障壁について議論します

フロントエンド開発のトレンド
最先端の進歩や最高水準のイノベーションが、現在ウェブ開発の世界を形作っている様子について、私たちと一緒に深く掘り下げてみませんか

量子AI:量子コンピューティングの潜在能力を機械学習で解き明かす
この記事では、量子機械学習について、現在の課題、機会、評価、成熟度、およびタイムリーさについて、読者がより詳しく学ぶことができます
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.