Learn more about Search Results ML - Page 371

- You may be interested
- 「緑を守る:加速されたアナリティクスが...
- 「人工知能と気候変動」
- Skopsの紹介
- 生成AI:シームレスなデータ転送のための...
- 「取得した文書の圧縮は言語モデルのパフ...
- 「アドベクティブ拡散トランスフォーマー...
- 「なぜ私がAIの博士課程をやめたのか」
- オープンソースAIゲームジャムを発表しま...
- 「ChatGPTコードインタプリタは、すべての...
- 画像埋め込みのためのトップ10の事前訓練...
- 「ジャスティン・マクギル、Content at Sc...
- AudioCraft Metaの音声と音楽のための生成AI
- AIキャリアのトレンド:人工知能の世界で...
- 人工知能を規制するための競争
- 「すべてのビジネスが生成的AIを受け入れ...

マイクロソフトの研究者がKOSMOS-2を紹介:視覚世界に根付くことができるマルチモーダルな大規模言語モデル
マルチモーダル大規模言語モデル(MLLMs)は、言語、ビジョン、ビジョン言語のタスクを含むさまざまな活動で一般的なインターフェースとしての成功を示しています。ゼロショットおよびフューショットの条件下では、MLLMsはテキスト、画像、音声などの一般的なモダリティを知覚し、自由な形式のテキストを使用して回答を生成することができます。本研究では、マルチモーダルな大規模言語モデルに自己を基礎付ける能力を付与します。ビジョン言語の活動では、基礎付け能力はより実用的かつ効果的な人間-AIインターフェースを提供することができます。モデルは、地理座標と一緒にその画像領域を解釈することができ、ユーザーが長いテキストの説明を入力する代わりに、アイテムや領域を画像上で直接指すことができます。 図1:KOSMOS-2を使用して生成された選択されたサンプルが表示されます。ビジュアル基礎付け、基礎付け質問応答、バウンディングボックスを使用したマルチモーダル参照、基礎付け画像キャプション、ビジュアル基礎付けなどがあります。 モデルの基礎付け機能は、視覚的な応答(つまり、バウンディングボックス)の提供も可能にし、参照表現の理解などの他のビジョン言語のタスクを支援することができます。テキストベースの応答と比較して、視覚的な応答はより正確で、共参照の曖昧さを解消します。結果として得られる自由形式のテキスト応答の基礎付け能力は、名詞句や参照表現などを画像領域に関連付けて、より正確で情報量のある応答を生成します。Microsoft Researchの研究者は、基礎付け機能を備えたKOSMOS-1をベースにしたマルチモーダルな大規模言語モデルKOSMOS-2を紹介しています。次単語予測タスクを使用して、Transformerに基づく因果的言語モデルKOSMOS-2をトレーニングします。 彼らは、基礎付けの潜在能力を十分に活用するために、基礎付けられた画像テキストのペアデータセットをウェブスケールで構築し、KOSMOS-1のマルチモーダルコーパスに統合します。LAION-2BおよびCOYO-700Mからの画像テキストの一部のペアリングが、基礎付けられた画像テキストのペアの基盤となります。彼らは、キャプションから名詞句や参照表現などのテキストスパンを抽出し、それらのオブジェクトや領域のバウンディングボックスなどの空間的な位置に接続するためのパイプラインを提供します。バウンディングボックスの地理座標を位置トークンの文字列に変換し、それらを対応するテキストスパンの後に追加します。データ形式は、画像の要素をキャプションにリンクする「ハイパーリンク」として機能します。 実験の結果、KOSMOS-2は、基盤タスク(フレーズの基盤と参照表現の理解)および参照タスク(参照表現の生成)だけでなく、KOSMOS-1で評価された言語およびビジョン言語のタスクでも競争力を持っています。図1は、基礎付け機能を含めることで、KOSMOS-2を基盤とする画像キャプションとビジュアル質問応答をはじめとする追加のダウンストリームタスクに利用する方法を示しています。GitHubでオンラインデモが利用可能です。

初心者向けの生成AIの優しい紹介
ここ数ヶ月間、いわゆる「生成AI」の台頭が見られますその基礎を理解する時が来ました

データサイエンスの成功への道は、学習能力にかかっていますしかし、何を学ぶべきでしょうか?
過去10年間で、データサイエンスの多くの大きな進展がありましたが、これらの成果にもかかわらず、多くのプロジェクトは実現されることはありません私たちデータサイエンティストとしては、強力な成果を示すだけでなく、プロジェクトを実現させるためにも努力しなければなりません

SparkとTableau Desktopを使用して洞察に富んだダッシュボードを作成する
データの視覚的表現として、データの可視化はデータ分析において広く採用されている手法であり、有益なビジネスの洞察(トレンド、パターン、外れ値、相関関係など)を得るための手段です

API管理を使用してAIパワードJavaアプリを管理する
OpenAIのChatGPT APIをSpring Bootアプリケーションに統合し、オープンソースのAPIゲートウェイであるApache APISIXを使用してAPIを管理する方法を探索してください

ProFusion における AI 非正則化フレームワーク テキストから画像合成における詳細保存に向けて
テキストから画像生成の領域は長年にわたって広範に研究され、最近では大きな進歩がなされています。研究者たちは、大規模なデータセットで大規模なモデルをトレーニングすることにより、任意のテキスト入力に対するゼロショットのテキストから画像生成を実現するという、驚異的な進展を達成しています。DALL-EやCogViewなどの画期的な作品は、研究者によって提案された多くの手法の道を開き、テキストの説明に合わせて高解像度の画像を生成し、非常に忠実度の高い性能を示す能力を持つものとなりました。これらの大規模なモデルは、テキストから画像生成だけでなく、画像の操作や動画生成など、さまざまな他のアプリケーションにも革命をもたらしました。 前述の大規模なテキストから画像生成モデルは、テキストに合わせた創造的な出力を生成する能力に優れていますが、ユーザーが指定した新しいユニークな概念を生成する際にはしばしば課題に直面します。その結果、研究者たちは、事前にトレーニングされたテキストから画像生成モデルをカスタマイズするさまざまな手法を探求してきました。 たとえば、いくつかの手法では、事前にトレーニングされた生成モデルを限られた数のサンプルを使用して微調整することが含まれます。過学習を防ぐために、異なる正則化技術が使用されます。他の手法では、ユーザーから提供される新しい概念をワード埋め込みにエンコードすることを目指しています。この埋め込みは、最適化プロセスまたはエンコーダネットワークから得ることができます。これらの手法により、ユーザーの入力テキストで指定された追加の要件を満たしながら、新しい概念のカスタマイズ生成が可能となります。 テキストから画像生成の進歩にもかかわらず、最近の研究では、正則化手法を使用する場合のカスタマイズの潜在的な制約に関する懸念が浮上しています。これらの正則化手法がカスタマイズされた生成の能力を意図せず制限する可能性があると疑われています。その結果、細かい詳細が失われる恐れがあります。 この課題を克服するために、ProFusionという新しいフレームワークが提案されました。そのアーキテクチャは以下に示されています。 ProFusionは、PromptNetと呼ばれる事前にトレーニングされたエンコーダと、Fusion Samplingと呼ばれる新しいサンプリング手法から構成されています。従来の手法とは異なり、ProFusionはトレーニングプロセス中に正則化の要件を排除します。代わりに、問題はFusion Sampling手法を使用して推論中に効果的に解決されます。 実際、著者たちは、正則化がテキストによって条件付けられた忠実なコンテンツ作成を可能にする一方で、詳細な情報の喪失をもたらし、劣ったパフォーマンスを引き起こすと主張しています。 Fusion Samplingは、各タイムステップで2つのステージから構成されています。最初のステップでは、フュージョンステージが入力画像の埋め込みと条件付きテキストの情報を組み合わせてノイズのある部分的な結果をエンコードします。その後、リファインメントステージが続き、選択されたハイパーパラメータに基づいて予測を更新します。予測の更新により、Fusion Samplingは入力画像からの細かな情報を保持しながら、出力を入力のプロンプトに基づいて条件付けます。 この手法は、トレーニング時間を節約するだけでなく、正則化手法に関連するハイパーパラメータの調整の必要性もなくします。 以下に報告された結果が示されています。 ProFusionと最先端の手法との比較が示されています。提案された手法は、顔の特徴に関連する細かい詳細を保持し、他のすべての手法よりも優れた性能を発揮しています。 これがProFusionの概要であり、最先端の品質を持つテキストから画像生成のための新しい正則化フリーフレームワークでした。興味があれば、以下のリンクでこの技術について詳しく学ぶことができます。

Amazon AIコンテンツモデレーションサービスを使用した安全な画像生成と拡散モデル
生成AI技術は急速に進化しており、テキスト入力に基づいてテキストや画像を生成することが可能になっていますStable Diffusionは、写真のようなリアルなアプリケーションを作成するためのテキストから画像へのモデルですAmazon SageMaker JumpStartを通じて、Stable Diffusionモデルを使用してテキストから簡単に画像を生成することができます以下は、テキスト入力とそれに対応する画像の例です

Amazon SageMaker Canvasを使用して、ノーコードの機械学習を活用して、公衆衛生の洞察をより迅速にキャプチャーしましょう
公衆衛生機関は、さまざまな種類の疾病、健康のトレンド、危険因子に関する豊富なデータを保有しています彼らのスタッフは、長年にわたり統計モデルや回帰分析を使用して、治療薬を用いた疾病の最も高いリスク要因を持つ人口を対象にするなど、重要な決定を行ってきましたまた、懸念される感染症の進行を予測するためのモデルも使われています
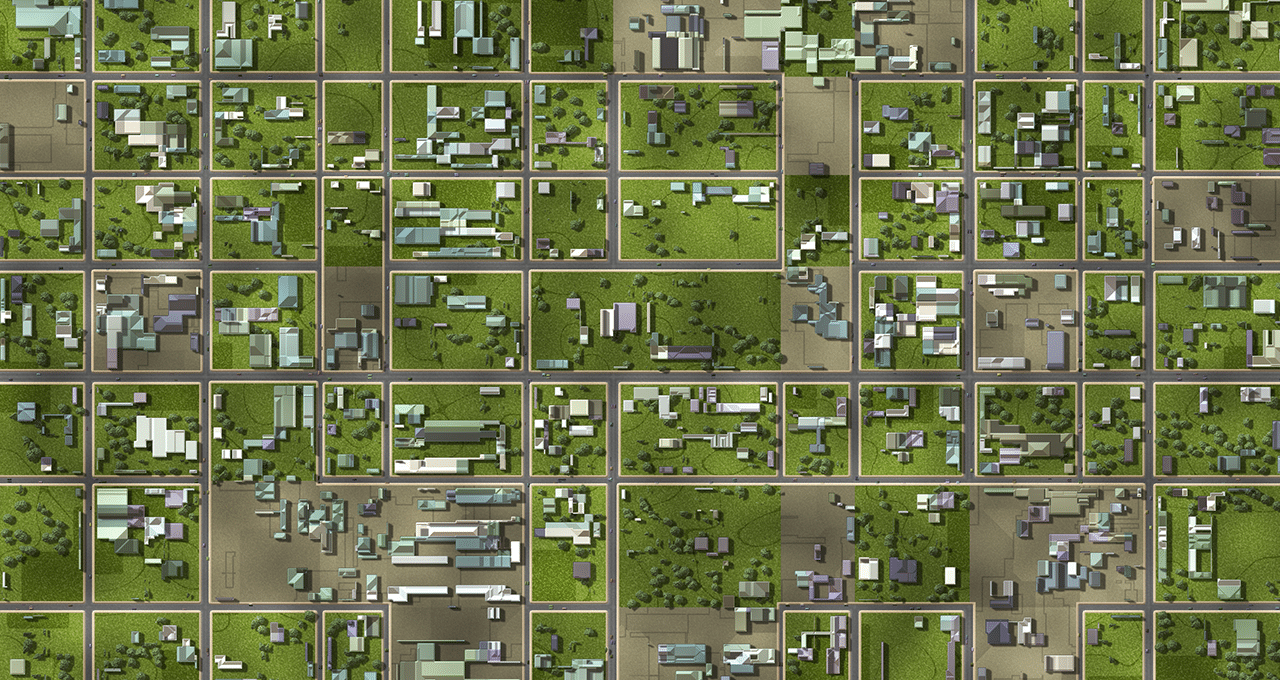
このスペースを見る:AIを使用してリスクを推定し、資産を監視し、クレームを分析する新しい空間金融の分野
金融の意思決定をする際には、ドローン、衛星、またはAIパワードセンサーから取得した大局的な情報を見ることが重要です。 空間金融という新興分野では、銀行、保険会社、投資会社、および事業者がリスクと機会を分析し、新しいサービスや製品を提供し、保有資産の環境への影響を測定し、危機後の被害を評価するために、リモートセンサーや空中画像からのAIの洞察を活用しています。 空間金融の応用には、資産のモニタリング、エネルギー効率のモデリング、排出物や汚染物の追跡、違法な鉱業や森林伐採の検出、自然災害のリスクの分析などがあります。NVIDIAのAIソフトウェアとハードウェアは、これらの応用を加速するために、ビジネスデータを地理空間データと組み合わせるための支援を提供できます。 投資に関連する環境と社会のリスクをよりよく理解することで、金融部門は持続可能な開発をサポートする可能性の高い投資を優先することができます。これは環境、社会、ガバナンス(ESG)として知られる枠組みです。 持続可能な投資への関心は高まっており、Bloomberg Intelligenceの分析によれば、ESG資産は2025年までに世界の総管理資産の3分の1以上を占めると推定されています。また、欧州連合宇宙プログラム機関の報告書によると、保険業や金融業は次の10年間で地球観測データとサービスの最大の消費者となり、2031年までに総売上高が10億ドルを超える見込みです。 NVIDIA Inceptionのメンバーの中には、工場周辺の水質汚染を追跡したり、野火の金融リスクを評価したり、嵐後の被害を評価したりすることができるGPUアクセラレートAIアプリケーションを開発しているスタートアップがあります。 大規模データのための強力な計算 GPUアクセラレートAIとデータサイエンスは、複雑で構造化されていないデータから迅速に洞察を抽出することができます。これにより、銀行や事業者は衛星、ドローン、アンテナ、エッジセンサーからキャプチャされたデータのリアルタイムストリーミングと分析を設定することができます。 航空写真を監視することにより、公共の宇宙機関から無料で入手できるもの、または民間企業からより詳細なものを使用して、解析者は貯水池からの水の使用量の推移、建設プロジェクトのために伐採された木の数、竜巻によって損傷を受けた家の数などを明確に把握することができます。 この機能により、政府の義務付けられた開示書類、環境影響報告書、さらには保険請求などの正確性を検証することで、投資を監査するのに役立ちます。 たとえば、投資家は、製品ラインでネットゼロを達成したと報告している会社のサプライチェーンを追跡し、衛星画像で確認できる石炭灰を発する海外の工場に依存していることを発見するかもしれません。また、ビルからの熱放射を分析するセンサーは、税金控除対象となる低排出ビジネスを特定するのに役立ちます。 NVIDIAのエッジコンピューティングソリューションは、自律型マシンやその他の組み込みアプリケーション向けのNVIDIA Jetsonプラットフォームを含め、空間金融のさまざまなAIイニシアチブを支えています。 アプリケーションの高速化のためにNVIDIAハードウェアを使用するだけでなく、開発者は、ビジョンAIのためのNVIDIA Metropolisプラットフォームの一部であるストリーミング分析のためのNVIDIA DeepStreamソフトウェア開発キット、およびジオスペーシャルデータの詳細な3DビジュアライゼーションのためのNVIDIA Omniverseプラットフォームを使用しています。 保険業務-リスク評価から請求の加速まで NVIDIA Inceptionのメンバーは、ジオスペーシャルデータを保険会社に洞察を提供するGPUアクセラレートアプリケーションを開発しており、保険対象物の状態を監視するために必要な高価な現地訪問の回数を減らすことができます。 ルクセンブルクに拠点を置くRSS-Hydroは、衛星画像から洪水の影響をマッピングするためにGPUコンピューティングをクラウドとオンプレミスで使用しています。同社はまた、洪水のリスクを効果的に伝え、緊急時のリソース配分計画を通知するために、FloodSENSを3Dでアニメーション化するためにNVIDIA Omniverseを使用しています。…

TaatikNet(ターティクネット):ヘブライ語の翻字のためのシーケンス・トゥ・シーケンス学習
この記事では、TaatikNetとseq2seqモデルの簡単な実装方法について説明していますコードとドキュメントについては、TaatikNetのGitHubリポジトリを参照してくださいインタラクティブなデモについては、HF Spaces上のTaatikNetをご覧ください多くのタスク...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.