Learn more about Search Results TensorFlow - Page 36

- You may be interested
- Amazon SageMaker で大規模なモデル推論 D...
- 高度な言語モデルの世界における倫理とプ...
- コンテンツクリエイター向けの20のクロー...
- ETHチューリッヒとマイクロソフトの研究者...
- 「集中データ管理における感度の取り組み」
- 自動化された欺瞞検出:東京大学の研究者...
- DeepMind RoboCat:自己学習ロボットAIモデル
- 『臨床試験結果予測』
- ビデオゲームの世界でインタラクティブな...
- 「Amazon Bedrockへのプライベートアクセ...
- 「言語モデルにおける連鎖思考推論の力を...
- このフィンランド拠点のAIスタートアップ...
- 「Rustベースのベクトルデータベース、Qdr...
- 『見て学ぶ小さなロボット:このAIアプロ...
- 「A/Bテストのマスタリング:現実世界のビ...

PyTorchを使った効率的な画像セグメンテーション:Part 2
これは、PyTorchを使用してディープラーニング技術を使ってゼロから画像セグメンテーションをステップバイステップで実装する4部作シリーズの第2部ですこの部分では、ベースライン画像の実装に焦点を当てます...

Ludwig – より「フレンドリーな」ディープラーニングフレームワーク
産業用途の深層学習については、私は避ける傾向があります興味がないわけではなく、むしろ人気のある深層学習フレームワークが扱いづらいと感じています私はPyTorchとTensorFlowを高く評価しています
私の博士号入学への道 – 人工知能
大学の出願書類を取り組んで、日々をカウントダウンして過ごした6ヶ月間の後、2023年秋に人工知能の博士号を取得することになりました以下の内容をまとめてみました…

AutoML – 機械学習モデルを構築するための No Code ソリューション
はじめに AutoMLは自動機械学習としても知られています。2018年、GoogleはクラウドAutoMLを発表し、大きな関心を集め、機械学習と人工知能の分野で最も重要なツールの1つとなりました。この記事では、「Google Cloud AutoML」を使った機械学習モデルを構築するためのノーコードソリューションである「AutoML」について学びます。 AutoMLは、Google Cloud Platform上のVertex AIの一部です。Vertex AIは、クラウド上で機械学習パイプラインを構築および作成するためのエンドツーエンドソリューションです。ただし、Vertex AIの詳細については、別の記事で説明します。AutoMLは、主に転移学習とニューラルサーチアーキテクチャに依存しています。データを提供するだけで、AutoMLはユースケースに最適なカスタムモデルを構築します。 この記事では、Pythonコードを使ったGoogle Cloud Platform上でのAutoMLの利点、使用方法、実践的な実装について説明します。 学習目標 コードを使ったAutoMLの使用方法を読者に知らせること AutoMLの利点を理解すること クライアントライブラリを使用してMLパイプラインを作成する方法 この記事は、Data Science Blogathonの一部として公開されました。 問題の説明 機械学習モデルを構築することは時間がかかり、プログラミング言語の熟練度、数学と統計の良い知識、および機械学習アルゴリズムの理解などの専門知識が必要です。過去には、技術的なスキルを持つ人々だけがデータサイエンスで働き、モデルを構築できました。非技術的な人々にとっては、機械学習モデルを構築することは最も困難なタスクでした。ただし、モデルを構築した技術的な人々にとっても道のりは容易ではありませんでした。モデルを構築した後、メンテナンス、展開、および自動スケーリングには追加の努力、労働時間、およびわずかに異なるスキルセットが必要です。これらの課題を克服するために、グローバル検索大手のGoogleは、2014年にAutoMLを発表しましたが、後に一般に公開されました。 AutoMLの利点 AutoMLは手動の介入を減らし、少しの機械学習の専門知識が必要となります。…
PatchTST 時系列予測における画期的な技術革新
トランスフォーマーベースのモデルは、自然言語処理の分野(BERTやGPTモデルなど)やコンピュータビジョンなど、多くの分野で成功を収めていますしかし、時間の問題になると...

将来のPythonバージョン(3.12など)に一般のユーザーに先駆けてアクセスする方法
Python 3.12などの将来のバージョンを群衆より先にインストールしてテストする方法についてのチュートリアルで、新しい機能を体験して競争上の優位性を獲得する方法

アテンションメカニズムを利用した時系列予測
はじめに 時系列予測は、金融、気象予測、株式市場分析、リソース計画など、さまざまな分野で重要な役割を果たしています。正確な予測は、企業が情報に基づいた決定を行い、プロセスを最適化し、競争上の優位性を得るのに役立ちます。近年、注意機構が、時系列予測モデルの性能を向上させるための強力なツールとして登場しています。本記事では、注意の概念と、時系列予測の精度を向上させるために注意を利用する方法について探求します。 この記事は、データサイエンスブログマラソンの一環として公開されました。 時系列予測の理解 注意機構について詳しく説明する前に、まず時系列予測の基礎を簡単に見直してみましょう。時系列は、日々の温度計測値、株価、月次の売上高など、時間の経過とともに収集されたデータポイントの系列から構成されます。時系列予測の目的は、過去の観測値に基づいて将来の値を予測することです。 従来の時系列予測手法、例えば自己回帰和分移動平均(ARIMA)や指数平滑法は、統計的手法や基礎となるデータに関する仮定に依存しています。研究者たちはこれらの手法を広く利用し、合理的な結果を得ていますが、データ内の複雑なパターンや依存関係を捉えることに課題を抱えることがあります。 注意機構とは何か? 人間の認知プロセスに着想を得た注意機構は、深層学習の分野で大きな注目を集めています。機械翻訳の文脈で初めて紹介された後、注意機構は自然言語処理、画像キャプション、そして最近では時系列予測など、様々な分野で広く採用されています。 注意機構の主要なアイデアは、モデルが予測を行うために最も関連性の高い入力シーケンスの特定の部分に焦点を合わせることを可能にすることです。注意は、すべての入力要素を同等に扱うのではなく、関連性に応じて異なる重みや重要度を割り当てることができるようにします。 注意の可視化 注意の仕組みをよりよく理解するために、例を可視化してみましょう。数年にわたって日々の株価を含む時系列データセットを考えます。次の日の株価を予測したいとします。注意機構を適用することで、モデルは、将来の価格に影響を与える可能性が高い、過去の価格の特定のパターンやトレンドに焦点を合わせることができます。 提供された可視化では、各時間ステップが小さな正方形として描かれ、その特定の時間ステップに割り当てられた注意重みが正方形のサイズで示されています。注意機構は、将来の価格を予測するために、関連性が高いと判断された最近の価格により高い重みを割り当てることができることがわかります。 注意に基づく時系列予測モデル 注意機構の理解ができたところで、時系列予測モデルにどのように統合できるかを探ってみましょう。人気のあるアプローチの1つは、注意を再帰型ニューラルネットワーク(RNN)と組み合わせることで、シーケンスモデリングに広く使用されている方法です。 エンコーダ・デコーダアーキテクチャ エンコーダ・デコーダアーキテクチャは、エンコーダとデコーダの2つの主要なコンポーネントから構成されています。過去の入力シーケンスをX = [X1、X2、…、XT]、Xiが時間ステップiの入力を表すようにします。 エンコーダ エンコーダは、入力シーケンスXを処理し、基礎となるパターンと依存関係を捉えます。このアーキテクチャでは、エンコーダは通常、LSTM(長短期記憶)レイヤを使用して実装されます。入力シーケンスXを取り、隠れ状態のシーケンスH = [H1、H2、…、HT]を生成します。各隠れ状態Hiは、時間ステップiの入力のエンコード表現を表します。 H、_= LSTM(X)…

データアナリストは良いキャリアですか?
労働統計局(BLS)によると、データアナリストを含む研究アナリストの雇用は、2021年から2031年までに23%増加すると予想されています。データ分析のキャリアが著しく成長することは、有望な候補者にとっても重要な展望を示しています。それは一般に提供されるサービスや製品に深い影響を与えます。データアナリストとして、コンピュータサイエンス、統計学、数学の技術的な知識と問題解決能力および分析能力を持つ必要があります。この分野は、最先端のテクノロジーを使用する機会が豊富であり、個人的および職業的な成長のための機会を提供します。しかし、この興味深いキャリアパスには、どのような期待が置かれているのでしょうか。企業にデータ分析サービスを提供する理想的な候補者に課せられる期待について探ってみましょう。 データアナリストとは何ですか? データ分析とは、ビジネスの利益に活用するために、データから情報を得ることまたは分析することを指します。この仕事の役割と責任には、以下が含まれます。 分析のためのデータ収集。これには、さまざまな方法を通じてさまざまなタイプのデータを発見または収集することが含まれます。例としては、調査、投票、アンケート、およびウェブサイトの訪問者特性の追跡が挙げられます。必要に応じて、データセットを購入することもできます。 プログラミング言語を使用して、前のステップで生成されたデータ、つまり生データをクリーニングすることが必要です。名前は、処理が必要な外れ値、エラー、重複などの不要な情報の存在を示しています。クリーニングプロセスは、データの品質を向上させて利用可能にすることを目的としています。 データは、今後モデル化する必要があります。これには、データに構造と表現を与えて整理することが含まれます。また、データの分類およびその他の関連プロセスを行うことも必要です。 したがって、形成されたデータは複数の目的に役立ちます。使用法は問題文によって異なり、解釈方法も問題文によって異なります。データの解釈は主に、データ内のトレンドやパターンを見つけることに関係しています。 データのプレゼンテーションも同様に重要なタスクであり、情報が意図した通りに閲覧者や関係者に届くようにすることが最も重要な要件です。これには、プレゼンテーションおよびコミュニケーションスキルが必要です。データアナリストは、グラフやチャートを使用し、報告書の作成や情報のプレゼンテーションを行うことがあります。 データアナリストになる理由 データアナリストになるためには、複数の理由があります。以下は、最も重要な5つの理由です。 高い需要: データの生成が増加したことにより、未処理のデータが大量に存在しています。それには、企業が活用できる多くの秘密が含まれます。このタスクを実行できる個人の要件は急速に増加しており、標準的な要件は年間3000ポジションです。 ダイナミックなフィールド: データアナリストの仕事は、課題に対処し、問題を解決することに喜びを感じる場合、多くのものを提供します。毎日興味深く、新しい課題があり、分析思考とブレストストーミングが必要な場所です。また、旅の中で多くを学ぶこともでき、自己改善に貢献します。 高い報酬: データアナリストのポジションの報酬は高く、キャリアを追求する価値があります。給与の増加は、業界によって異なり、一部の分野ではボーナスを含む高い収入が約束されています。 普遍性: データアナリストの要件は、特定の分野に限定されるものではありません。すべての業界が多くのデータを生成し、情報に基づく論理的な意思決定が必要です。したがって、背景や興味に関係なく、すべての専門分野に開かれています。 キャリアの選択をリード: 熟練したデータアナリストは、ポジションと会社に価値をもたらすことができます。成長、昇進、追加の福利厚生の可能性はどこでも開かれています。グループをリードしたり、教えたり、競争したり、ワークフォースの文化を形成することができるように、キャリアの選択をリードすることができます。 需要と将来の仕事のトレンド 現在、データアナリストの需要は高く、良い報酬が期待できます。現在のデータ生成の速度に基づいて、将来的には需要がさらに高まると予想されています。新しいテクノロジーの生成とデータ収集の容易化により、将来的には才能に新しい機会が提供されるでしょう。将来のデータアナリストの予想される新しいジョブロールには、以下が含まれます。 AIの機能性と適合性を説明する。新しく開発された機能の品質分析。 ビジネスオペレーションとデータ処理のリアルタイム分析の組み合わせに取り組む。これにより、戦略に基づいた計画に向けて導かれます。…
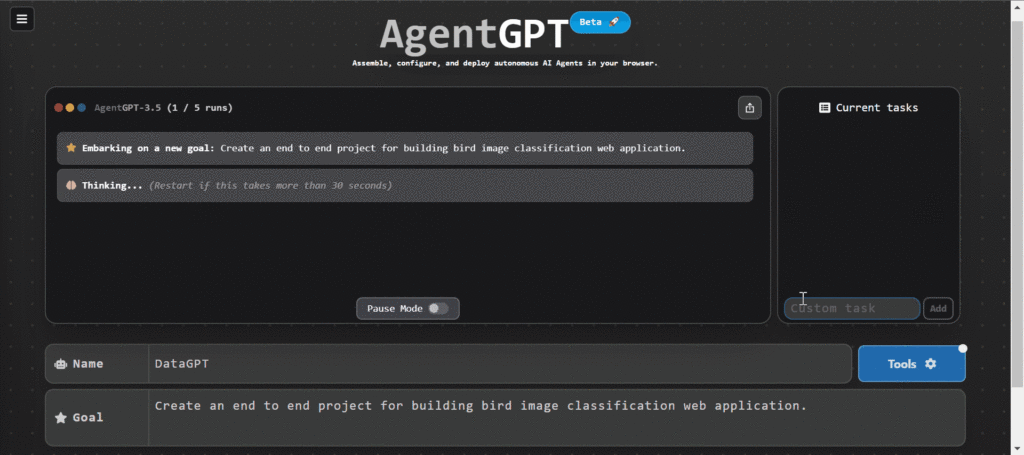
AgentGPT ブラウザ内の自律型AIエージェント
あなたのAIエージェントに名前と目標を与え、割り当てられた目的を達成するのを見てください

DeepMindのAIマスターゲーマー:2時間で26のゲームを学習
強化学習は、Google DeepMindの中核的な研究分野であり、AIを用いて実世界の問題を解決するための膨大な可能性を秘めています。しかし、そのトレーニングデータとコンピューティングパワーの非効率性は、重大な課題を引き起こしています。DeepMindは、MilaとUniversité de Montréalの研究者と協力して、これらの制限に対抗するAIエージェントを導入しました。このエージェントは、Bigger, Better, Faster(BBF)モデルとして知られており、わずか2時間で26のゲームを学習しながらAtariベンチマークで超人的なパフォーマンスを達成しました。この驚異的な成果は、効率的なAIトレーニング方法の新たな道を開き、RLアルゴリズムの将来的な進歩の可能性を解き放ちます。 詳細はこちらをご覧ください:DataHack Summit 2023のワークショップで、最新のAI技術を使用して強化学習の信じられないほどの可能性を解き放ち、実世界の課題に取り組んでください。 強化学習の効率課題 強化学習は、複雑なタスクに取り組むための有望なアプローチとして長年認識されてきました。しかし、従来のRLアルゴリズムは、実用的な実装を妨げる非効率性に苦しんでいます。これらのアルゴリズムは、大量のトレーニングデータと膨大なコンピューティングパワーを要求し、リソースを消費し、時間を要します。 また読む:強化学習の包括的なガイド Bigger, Better, Faster(BBF)モデル:人間を凌駕する DeepMindの最新のブレイクスルーは、Atariベンチマークでの卓越したパフォーマンスを発揮したBBFモデルから来ています。以前のRLエージェントはAtariゲームで人間を超えていましたが、BBFの特筆すべき点は、人間のテスターが利用可能な時間枠と同等の2時間のゲームプレイ内で、このような印象的な結果を達成したことです。 モデルフリー学習:新しいアプローチ BBFの成功は、ユニークなモデルフリー学習アプローチに帰することができます。ゲーム世界との相互作用を通じて受け取った報酬と罰に依存することにより、BBFは明示的なゲームモデルを構築する必要を回避します。この簡素化されたプロセスにより、エージェントは学習とパフォーマンスの最適化に集中し、より迅速かつ効率的なトレーニングが可能になります。 また読む:OpenAIとTensorFlowを使用した人間のフィードバックで強化学習を強化する トレーニング方法と計算効率の向上 BBFの急速な学習の成果は、いくつかの重要な要因によるものです。研究チームは、より大きなニューラルネットワークを採用し、自己モニタリングトレーニング方法を改良し、効率を向上させるための様々な技術を実装しました。特に、BBFは、以前のアプローチと比較して必要な計算リソースを減らすことができる、単一のNvidia A100 GPUでトレーニングすることができます。 進歩のベンチマーク:RLの進歩のための足がかり…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.