Learn more about Search Results T5 - Page 36

- You may be interested
- 機械学習洞察のディレクター【パート4】
- 「オムニコントロール:拡張空間制御信号...
- 新しいAI研究がAttrPromptを紹介します:...
- 「OpenAI WhisperとHugging Chat APIを使...
- チャットアプリ開発の主要な柱
- 『Amazon SageMaker を使用して、Talent.c...
- 文のトランスフォーマーを使用してプレイ...
- UCバークレーとスタンフォードの研究者チ...
- 自己RAGが産業用LLMを革命化する方法
- 2024年に使用するためのトップ5の生成AIラ...
- 「生成モデルを活用して半教師あり学習を...
- 「AIとともに観測性の潜在能力を解き放つ」
- 『LEOと出会いましょう:先進的な3Dワール...
- 「巨大な望遠鏡が知能化されたメンテナン...
- 「分析的に成熟した組織(AMO)の構築」

テキストブック品質の合成データを使用して言語モデルをトレーニングする
マイクロソフトリサーチは、データの役割についての現在進行中の議論に新たな燃料を加える論文を発表しました具体的には、データの品質と合成データの役割に触れています
南アメリカにおける降水量と気候学的なラスターデータの活用
2023年にエルニーニョ現象が激化するにつれて、気候学的および降水データは、その気象パターンと地球全体または地域の気候ダイナミクスへの影響を解読するために基本的な要素となっています...

ProFusion における AI 非正則化フレームワーク テキストから画像合成における詳細保存に向けて
テキストから画像生成の領域は長年にわたって広範に研究され、最近では大きな進歩がなされています。研究者たちは、大規模なデータセットで大規模なモデルをトレーニングすることにより、任意のテキスト入力に対するゼロショットのテキストから画像生成を実現するという、驚異的な進展を達成しています。DALL-EやCogViewなどの画期的な作品は、研究者によって提案された多くの手法の道を開き、テキストの説明に合わせて高解像度の画像を生成し、非常に忠実度の高い性能を示す能力を持つものとなりました。これらの大規模なモデルは、テキストから画像生成だけでなく、画像の操作や動画生成など、さまざまな他のアプリケーションにも革命をもたらしました。 前述の大規模なテキストから画像生成モデルは、テキストに合わせた創造的な出力を生成する能力に優れていますが、ユーザーが指定した新しいユニークな概念を生成する際にはしばしば課題に直面します。その結果、研究者たちは、事前にトレーニングされたテキストから画像生成モデルをカスタマイズするさまざまな手法を探求してきました。 たとえば、いくつかの手法では、事前にトレーニングされた生成モデルを限られた数のサンプルを使用して微調整することが含まれます。過学習を防ぐために、異なる正則化技術が使用されます。他の手法では、ユーザーから提供される新しい概念をワード埋め込みにエンコードすることを目指しています。この埋め込みは、最適化プロセスまたはエンコーダネットワークから得ることができます。これらの手法により、ユーザーの入力テキストで指定された追加の要件を満たしながら、新しい概念のカスタマイズ生成が可能となります。 テキストから画像生成の進歩にもかかわらず、最近の研究では、正則化手法を使用する場合のカスタマイズの潜在的な制約に関する懸念が浮上しています。これらの正則化手法がカスタマイズされた生成の能力を意図せず制限する可能性があると疑われています。その結果、細かい詳細が失われる恐れがあります。 この課題を克服するために、ProFusionという新しいフレームワークが提案されました。そのアーキテクチャは以下に示されています。 ProFusionは、PromptNetと呼ばれる事前にトレーニングされたエンコーダと、Fusion Samplingと呼ばれる新しいサンプリング手法から構成されています。従来の手法とは異なり、ProFusionはトレーニングプロセス中に正則化の要件を排除します。代わりに、問題はFusion Sampling手法を使用して推論中に効果的に解決されます。 実際、著者たちは、正則化がテキストによって条件付けられた忠実なコンテンツ作成を可能にする一方で、詳細な情報の喪失をもたらし、劣ったパフォーマンスを引き起こすと主張しています。 Fusion Samplingは、各タイムステップで2つのステージから構成されています。最初のステップでは、フュージョンステージが入力画像の埋め込みと条件付きテキストの情報を組み合わせてノイズのある部分的な結果をエンコードします。その後、リファインメントステージが続き、選択されたハイパーパラメータに基づいて予測を更新します。予測の更新により、Fusion Samplingは入力画像からの細かな情報を保持しながら、出力を入力のプロンプトに基づいて条件付けます。 この手法は、トレーニング時間を節約するだけでなく、正則化手法に関連するハイパーパラメータの調整の必要性もなくします。 以下に報告された結果が示されています。 ProFusionと最先端の手法との比較が示されています。提案された手法は、顔の特徴に関連する細かい詳細を保持し、他のすべての手法よりも優れた性能を発揮しています。 これがProFusionの概要であり、最先端の品質を持つテキストから画像生成のための新しい正則化フリーフレームワークでした。興味があれば、以下のリンクでこの技術について詳しく学ぶことができます。
トップ3のデータアーキテクチャのトレンド(およびLLMsがそれらに与える影響)
データアーキテクチャの次の時代への取り組み:トップ3のトレンドとLLMの影響力を明らかにする

TaatikNet(ターティクネット):ヘブライ語の翻字のためのシーケンス・トゥ・シーケンス学習
この記事では、TaatikNetとseq2seqモデルの簡単な実装方法について説明していますコードとドキュメントについては、TaatikNetのGitHubリポジトリを参照してくださいインタラクティブなデモについては、HF Spaces上のTaatikNetをご覧ください多くのタスク...

ChatArenaをご紹介します:複数の大規模言語モデル(LLMs)間のコミュニケーションとコラボレーションを容易にするために設計されたPythonライブラリです
ChatArenaは、様々な巨大言語モデルを支援するために作成されたPythonパッケージです。ChatArenaにはすでにマルチエージェント会話シミュレーション環境が含まれています。参加者は周囲によって支援され、役割によって決定された相互作用を持つことができます。 ChatArenaにはすでにマルチエージェント会話シミュレーション環境が含まれています。キャラクターは様々な役割を担うことができ、雰囲気は協力を促します。LLMを使用することで、ゲームが終了するタイミングや、状態間の進行方法を決定することができます。 ChatArenaが互換性のあるLLMバックエンドには、GPT-3.5-turbo、GPT-4、Huggingface Pipeline(モデルハブから1900以上のモデルを持つ)、Cohereなどがあります。これにより、競合するLLM間のオープンなコミュニケーションと協力が促進され、ゲームの強度と多様性が高まります。 ChatArenaの便利なWebUIとCLIインターフェースのおかげで、誰でも簡単にChatArenaで異なるシナリオを試すことができます。直感的なインターフェースにより、新しいゲームを作成し、素早くプレイヤーのリクエストを実装し、簡単に異なるゲーム作成アプローチを試すことができます。 自分自身の言語ゲームを作成したい場合は、このガイドを参照してください。https://tinyurl.com/2t5us7fv 協調的AIの可能性と課題に対する考慮と対応が必要となっています。マルチエージェント言語ゲームに関して、ChatArenaは安全性とアライメントを理解するためのツールと第一歩です。 キー コンセプト プレイヤー – ゲームをプレイするには、「プレイヤー」である他のプレイヤーと相互作用できるエージェントが必要です。名前、インフラストラクチャ、機能はすべて、特定の参加者を識別するために貢献します。人間と大規模言語モデルの両方が対象です(LLM)。 バックエンド – プレイヤーが他のプレイヤーと通信する方法を定義するために、Python開発者は「バックエンド」と呼ばれるクラスを作成します。バックエンドは、人間またはLLM、またはその両方のハイブリッドである場合があります。バックエンドの名前、タイプ、およびパラメータは、その定義的特徴です。 環境 – Pythonでは、ドメインはゲームルールを定義するクラスです。名前、タイプ、およびパラメータがすべて協力して環境を指定します。 モデレーター – Pythonクラスとして、モデレーターはゲームのルールを指定します。その定義的特徴は、モデレーターの名前、クラス、および設定です。 Arena – Pythonでは、アリーナはゲームを定義するクラスです。特定のアリーナのパラメータには、名前、タイプ、およびサイズが含まれます。…

CoDiに会おう:任意対任意合成のための新しいクロスモーダル拡散モデル
ここ数年、テキストからテキスト、画像、音声など、別の情報を生成する堅牢なクロスモーダルモデルが注目されています。注目すべき例としては、入力プロンプトによって期待される結果を説明することで、素晴らしい画像を生成できるStable Diffusionがあります。 実際にリアルな結果を出すにもかかわらず、これらのモデルは複数のモダリティが共存し相互作用する場合には実用上の制限があります。たとえば、「かわいい子犬が革製のソファで寝ている」というテキストの説明から画像を生成したいとしましょう。しかしそれだけでは不十分です。テキストから画像へのモデルから出力画像を受け取った後、子犬がソファで鼾をかいているという状況にどのような音がするかも聞きたいと思うでしょう。この場合、テキストまたは出力された画像を音に変換する別のモデルが必要になります。したがって、多数の特定の生成モデルをマルチステップの生成シナリオで接続することは可能ですが、このアプローチは手間がかかり遅くなる可能性があります。また、独立して生成された単一のストリームは、ビデオとオーディオを同期させるように、後処理的な方法で組み合わせた場合に一貫性とアラインメントが欠けることがあります。 包括的かつ多目的なany-to-anyモデルは、一貫したビデオ、オーディオ、およびテキストの説明を同時に生成し、全体的な体験を向上させ、必要な時間を減らすことができます。 この目標を達成するため、Composable Diffusion(CoDi)が開発され、任意のモダリティの組み合わせを同時に処理し生成することができるようになりました。 アーキテクチャの概要は以下に示されています。 https://arxiv.org/abs/2305.11846 任意のモダリティの混合物を処理し、さまざまな出力の組み合わせを柔軟に生成するモデルをトレーニングすることは、大きな計算量とデータ要件を必要とします。 これは、入力と出力のモダリティの可能性の指数関数的な成長に起因します。さらに、多数のモダリティグループの整列されたトレーニングデータを取得することは非常に限られており、存在しないため、すべての可能な入力-出力の組み合わせを使用してモデルをトレーニングすることは不可能です。この課題に対処するために、入力条件付けと生成散布ステップで複数のモダリティを整列させる戦略が提案されています。さらに、対照的な学習のための「ブリッジアライメント」戦略を導入することで、指数関数的な入力-出力の組み合わせを線形数のトレーニング目的で効率的にモデル化できます。 高品質な生成を維持し、任意の組み合わせを生成する能力を持ったモデルを実現するには、多様なデータリソースを活用した包括的なモデル設計とトレーニングアプローチが必要です。研究者たちは、CoDiを構築するために統合的なアプローチを採用しました。まず、テキスト、画像、ビデオ、音声など、各モダリティのために潜在的な散乱モデル(LDM)をトレーニングします。これらのLDMは、利用可能なモダリティ固有のトレーニングデータを使用して、各個別のモダリティの優れた生成品質を保証するために独立して並列にトレーニングできます。このデータには、1つ以上のモダリティを持つ入力と出力モダリティが含まれます。 音声や言語のプロンプトを使用して画像を生成するなど、モダリティの組み合わせが関わる条件付きクロスモダリティ生成の場合、入力モダリティは共有特徴空間に投影されます。このマルチモーダル調整メカニズムにより、特定の設定の直接トレーニングを必要とせずに、CoDiは任意のモダリティまたはモダリティの組み合わせに対して条件を付けることができます。出力LDMは、結合された入力特徴に注意を払い、クロスモダリティ生成を可能にします。このアプローチにより、CoDiはさまざまなモダリティの組み合わせを効果的に処理し、高品質な出力を生成することができます。 CoDiのトレーニングの第2段階は、多数の多対多生成戦略を処理できるモデルの能力を促進し、異なるLDMからの潜在変数を共有潜在空間に投影する環境エンコーダVと、各散布器にクロスアテンションモジュールを導入することで実現されます。現在の知識の範囲では、CoDiはこの能力を持つ最初のAIモデルとして立ち上がっています。 このステージでは、LDMのパラメーターは固定され、クロスアテンションパラメーターとVのみがトレーニングされます。環境エンコーダーが異なるモダリティの表現を整列させるため、LDMはVを使用して出力表現を補間することで、任意の共同生成モダリティのセットとクロスアテンドできます。このシームレスな統合により、CoDiは可能な生成組み合わせすべてでトレーニングする必要がなく、任意のモダリティの任意の組み合わせを生成できます。その結果、トレーニング目的の数は指数関数から線形関数に削減され、トレーニングプロセスの効率が大幅に向上します。 モデルによって生成されたいくつかの出力サンプルは、各生成タスクについて以下に報告されています。 https://arxiv.org/abs/2305.11846 これがCoDiの概要であり、最先端の品質を持つ任意の生成に対する効率的なクロスモーダル生成モデルです。興味がある場合は、以下のリンクでこの技術について詳しく学ぶことができます。

AIの汎化ギャップに対処:ロンドン大学の研究者たちは、Spawriousという画像分類ベンチマークスイートを提案しましたこのスイートには、クラスと背景の間に偽の相関が含まれます
人工知能の人気が高まるにつれ、新しいモデルがほぼ毎日リリースされています。これらのモデルには新しい機能や問題解決能力があります。近年、研究者たちは、AIモデルの抵抗力を強化し、スパリアスフィーチャーへの依存度を減らすアプローチを考えることに重点を置いています。自動運転車や自律型キッチンロボットの例を考えると、彼らは彼らが訓練データから学習したものと大きく異なるシナリオで動作する際に生じる課題のためにまだ広く展開されていません。 多くの研究がスパリアス相関の問題を調査し、モデルのパフォーマンスに対するその負の影響を軽減する方法を提案しています。ImageNetなどのよく知られたデータセットで訓練された分類器は、クラスラベルと相関があるが、それらを予測するわけではない背景データに依存していることが示されています。SCの問題に対処する方法の開発に進展はあったものの、既存のベンチマークの制限に対処する必要があります。現在のWaterbirdsやCelebA hair color benchmarksなどのベンチマークには制限があり、そのうちの1つは、現実では多対多(M2M)のスパリアス相関がより一般的であり、クラスと背景のグループを含む単純な1対1(O2O)スパリアス相関に焦点を当てていることです。 最近、ロンドン大学カレッジの研究チームが、クラスと背景の間にスパリアス相関が含まれる画像分類ベンチマークスイートであるSpawriousデータセットを導入しました。それは1対1(O2O)および多対多(M2M)のスパリアス相関の両方を含み、3つの難易度レベル(Easy、VoAGI、Hard)に分類されています。データセットは、テキストから画像を生成するモデルを使用して生成された約152,000の高品質の写真リアルな画像で構成されており、画像キャプションモデルを使用して不適切な画像をフィルタリングし、データセットの品質と関連性を確保しています。 Spawriousデータセットの評価により、現在の最先端のグループ頑健性アプローチに対してHard-splitsなどの課題が課せられ、ImageNetで事前学習されたResNet50モデルを使用してもテストされた方法のいずれも70%以上の正確性を達成できなかったことが示されました。チームは、分類器が間違った分類を行った際に背景に依存していることを見て、モデルのパフォーマンスの短所が引き起こされたと説明しています。これは、スパリアスデータの弱点を成功裏にテストし、分類器の弱点を明らかにすることができたことを示しています。 O2OとM2Mベンチマークの違いを説明するために、チームは、夏に訓練データを収集する例を使用しました。それは、2つの異なる場所から2つの動物種のグループで構成され、各動物グループが特定の背景グループに関連付けられているものです。しかし、季節が変わり、動物が移動すると、グループは場所を交換し、動物グループと背景の間のスパリアス相関が1対1で一致することはできなくなります。これは、M2Mスパリアス相関の複雑な関係と相互依存関係を捉える必要性を強調しています。 Spawriousは、OOD、ドメイン汎化アルゴリズムにおける有望なベンチマークスイートであり、スパリアスフィーチャーの存在下でモデルの評価と改善を行うためにも使用できます。
ベイジアンマーケティングミックスモデルの理解:事前仕様に深く入り込む
ベイジアン・マーケティング・ミックス・モデリングは、特にLightweightMMM(Google)やPyMC Marketing(PyMC Labs)などのオープンソースツールの最近のリリースにより、ますます注目を集めています...
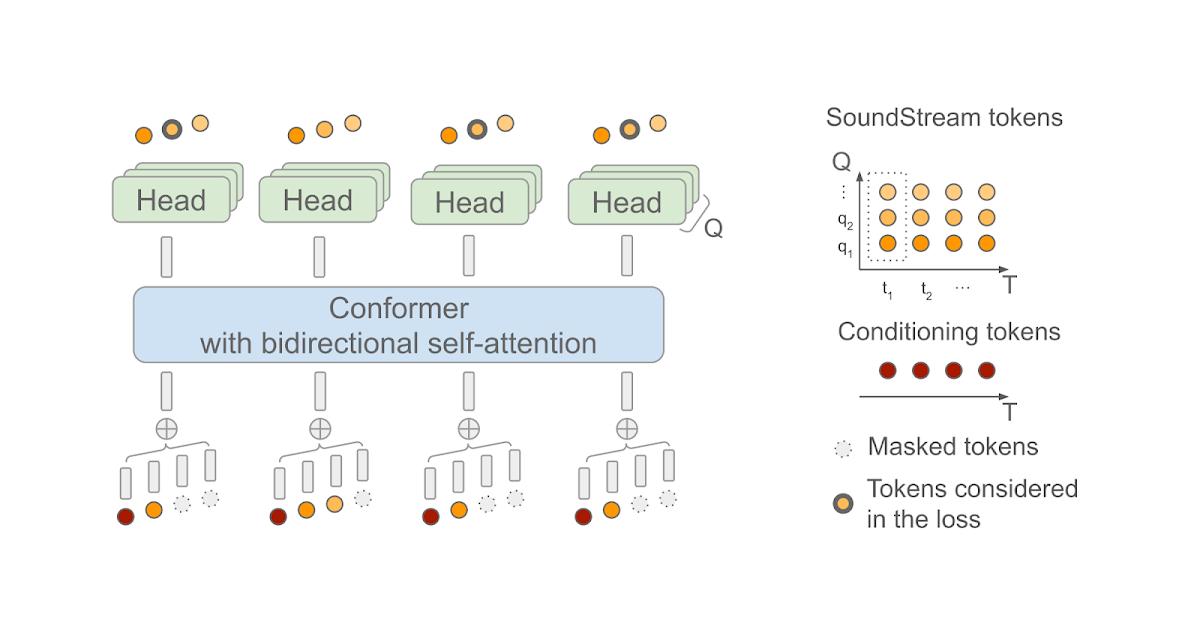
SoundStorm:効率的な並列音声生成
Zalán Borsos氏(リサーチソフトウェアエンジニア)とMarco Tagliasacchi氏(シニアスタッフリサーチサイエンティスト)がGoogle Researchで発表した記事です。 最近の生成AIの進歩により、テキスト、ビジョン、オーディオなど、さまざまな領域で新しいコンテンツを作成する可能性が開かれました。これらのモデルは、生データが最初にトークンのシーケンスとして圧縮されることに依存しています。オーディオの場合、ニューラルオーディオコーデック(例えば、SoundStreamまたはEnCodec)を使用して、波形をコンパクトな表現に効率的に圧縮することができます。これにより、元のオーディオ信号の近似値を再構成できます。この表現は、音の局所的な特性(たとえば、音素)および時間的構造(たとえば、韻律)を捉えた離散的な音声トークンのシーケンスで構成されています。オーディオを離散的なトークンのシーケンスとして表現することで、Transformerベースのシーケンスツーシーケンスモデルを使用してオーディオ生成を実行できるようになりました。これにより、音声継続性(AudioLMを使用した)、テキストから音声への変換(SPEAR-TTSを使用した)、一般的なオーディオや音楽の生成(AudioGenおよびMusicLMを使用した)において急速な進歩が可能になりました。多くの生成オーディオモデル、AudioLMを含む、自己回帰デコーディングに依存しています。この方法は高い音響品質を実現しますが、特に長いシーケンスをデコードする場合、推論(出力の計算)が遅くなることがあります。 この問題に対処するため、「SoundStorm: Efficient Parallel Audio Generation」という記事で、効率的かつ高品質なオーディオ生成の新しい方法を提案しています。SoundStormは、SoundStreamニューラルコーデックによって生成されるオーディオトークンの特性に適合するアーキテクチャと、MaskGITと呼ばれる最近提案された画像生成の方法に着想を得たデコードスキームの2つの新しい要素に依存して、長いオーディオトークンシーケンスの生成の問題に対処します。これにより、AudioLMの自己回帰デコーディングアプローチと比較して、SoundStormはトークンを並列に生成できるため、長いシーケンスの推論時間を100倍短縮することができ、同じ品質で、声質や音響条件の一貫性が高いオーディオを生成できます。さらに、SPEAR-TTSのテキストから意味論的モデリング段階と組み合わせたSoundStormは、例えば以下の例で示されるように、高品質で自然な対話を合成することができ、話される内容(トランスクリプトを介して)、話者の声(短い音声プロンプトを介して)、話者のターン(トランスクリプト注釈を介して)を制御できます。 入力:テキスト(オーディオ生成を駆動するトランスクリプトは太字) 今朝、私にとてもおかしなことが起こりました。| え、本当に?|普段通りに起きて、朝食を食べに下に降りたんです。|なるほど。| 食べ始めてから10分後に、今夜中だと気づいたんです。| あ、それはおもしろい。| 昨晩よく眠れなかったんだ。|え、どうしたの?|よくわからないんだ。どうしても寝付けなくて、一晩中寝返りを打ち続けたんだ。|そうなんだ。今晩は早く寝た方がいいかもしれないし、本でも読んでみるのはどうかな。|ああ、ありがとう。そうだといいんだけど。|どういたしまして。よく眠れるといいね。 入力:オーディオプロンプト 出力:オーディオプロンプト+生成されたオーディオ SoundStormの設計 以前のAudioLMの研究で、オーディオ生成を2つのステップに分解できることを示しました。1つ目は、意味的なトークンを生成する意味モデリングであり、前の意味トークンまたは条件信号(SPEAR-TTSのトランスクリプトやMusicLMのようなテキストプロンプトなど)から意味トークンを生成します。2つ目は、意味トークンから音声トークンを生成する音響モデリングです。SoundStormでは、より高速な並列デコードによって、より遅い自己回帰デコーディングを置き換え、音響モデリングに特に対処しています。 SoundStormは、トランスフォーマーと畳み込みを組み合わせたモデルアーキテクチャであるConformerに双方向アテンションを依存しており、トークンのシーケンスのローカルおよびグローバルな構造を捕捉します。具体的には、AudioLMが生成した意味トークンのシーケンスを入力として与えられた場合、SoundStreamによって生成されたオーディオトークンを予測するようにモデルが訓練されます。この際、各時間ステップtにおいて、SoundStreamは、右側に示すように、残差ベクトル量子化(RVQ)として知られる方法を使用して、最大Qトークンまでオーディオを表現します。主要な考え方は、各ステップで生成されるトークンの数が1からQに増えるにつれて、再構築されたオーディオの品質が徐々に向上するということです。 推論時には、入力として意味トークンを与えた場合、SoundStormは、すべてのオーディオトークンをマスクアウトし、RVQレベルq = 1の粗いトークンから始めて、より細かいトークンまでレベル別に進み、レベルq…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.