Learn more about Search Results ML - Page 362

- You may be interested
- グラフニューラルネットワークによるロー...
- 創造性とAIに関するレフィク・アナドール...
- ChatGPT vs. BARD’の比較
- 「DatabricksがMosaicMLとその他の最近のA...
- エッジコンピューティングにおけるAI:リ...
- AIの力による医療の革命:患者ケアと診断...
- 「Google Brainの共同創設者は、テック企...
- 従業員のエンゲージメント向上にゲーミフ...
- 「AIに関する新しい公聴会を議会が開催する」
- 多変量ガウス分布による異常検知の基本
- 「OpenAIの研究者たちは、敵対的なトレー...
- 「MLを学ぶ勇気:F1、再現率、適合率、ROC...
- 「回答を見つける(最良の回答を見つける...
- メディアでの顔のぼかしの力を解き放つ:...
- 「非構造化データファンネル」

DeepMindの最新研究(NeurIPS 2022)
NeurIPSは人工知能(AI)と機械学習(ML)の世界最大のカンファレンスであり、私たちはダイヤモンドスポンサーとしてイベントをサポートし、AIとMLコミュニティでの研究進展の交流を促進することを誇りに思っていますDeepMindのチームは、仮想パネルやポスターセッションで、35の外部との共同研究を含む47の論文を発表しています

ディプロマシーというボードゲームのためのAI
歴史を通じて、成功したコミュニケーションと協力は社会の進歩に不可欠でしたボードゲームの閉ざされた環境は、相互作用やコミュニケーションのモデリングと調査のための砂場として機能し、私たちはそれらをプレイすることで多くのことを学ぶことができます私たちの最新の論文では、Nature Communicationsに今日発表されたもので、人工エージェントがコミュニケーションを利用してボードゲーム「Diplomacy」でより良い協力を行う方法を示していますDiplomacyは人工知能(AI)研究の中でも注目されている領域で、同盟構築に重点を置いています

ロボキャット:自己改善型ロボティックエージェント
ロボットは私たちの日常生活の一部として急速になっていますが、彼らはしばしば特定のタスクをうまく実行するためにのみプログラムされています最近のAIの進歩を活用することで、より多くの方法で助けることができるロボットが可能になるかもしれませんが、一般的な用途のロボットの構築には、現実世界のトレーニングデータを収集するために必要な時間の制約があり、進展が遅れています私たちの最新の論文では、自己改善型のAIエージェントであるロボキャットを紹介していますロボキャットは、異なるアームでさまざまなタスクを実行する方法を学び、その後、新しいトレーニングデータを自己生成して技術を向上させるのです
ロジスティック回帰における行列とベクトルの演算
任意の人工ニューラルネットワーク(ANN)アルゴリズムの基礎となる数学は理解するのが困難かもしれませんさらに、フィードフォワードや...
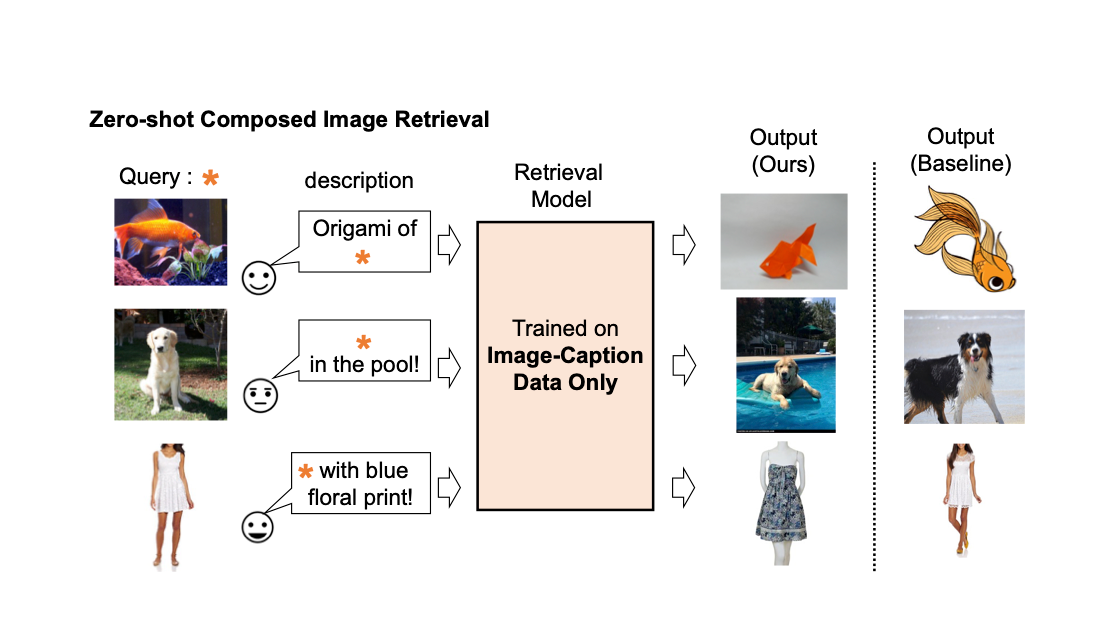
Pic2Word:ゼロショット構成画像検索のための写真から単語へのマッピング
Google Researchの学生研究者であるKuniaki SaitoとGoogle Researchの研究科学者であるKihyuk Sohnが投稿しました。 画像の検索エンジンでは、画像またはテキストをクエリとして使用して目的の画像を取得することが重要です。しかし、テキストに基づいた検索には限界があります。言葉で正確に目的の画像を説明することは難しいからです。たとえば、ファッションアイテムを検索する場合、ユーザーはウェブサイトで見つけたものとは異なる、ロゴの色やロゴ自体などの特定の属性を持つアイテムを求めるかもしれません。しかし、既存の検索エンジンでそのアイテムを検索することは容易ではありません。なぜなら、テキストでファッションアイテムを正確に説明することは難しいからです。この事実に対処するために、組み合わせ画像検索(CIR)は、画像とテキストの両方を組み合わせたクエリに基づいて画像を取得します。そのため、CIRは画像とテキストを組み合わせることで、目的の画像を正確に取得することができます。 しかし、CIRの方法には大量のラベル付きデータが必要です。つまり、1)クエリ画像、2)説明、および3)目標画像の3つ組を必要とします。このようなラベル付きデータを収集することはコストがかかり、このデータで訓練されたモデルはしばしば特定のユースケースに適応されており、異なるデータセットには一般化できる能力が制限されています。 これらの課題に対処するために、「Pic2Word:ゼロショット組み合わせ画像検索のための画像から単語へのマッピング」というタイトルの論文で、私たちはゼロショットCIR(ZS-CIR)というタスクを提案しています。ZS-CIRでは、ラベル付きの3つ組データを必要とせずに、オブジェクトの組み合わせ、属性の編集、またはドメインの変換など、さまざまなCIRのタスクを実行する単一のCIRモデルを構築することを目指しています。代わりに、大規模な画像キャプションのペアとラベルのない画像を使用して検索モデルを訓練することを提案しています。これらのデータは、大規模な教師ありCIRデータセットよりも容易に収集できます。再現性を促進し、この分野をさらに進展させるために、私たちはコードも公開しています。 既存の組み合わせ画像検索モデルの説明。 私たちは、画像キャプションのデータのみを使用して組み合わせ画像検索モデルを訓練します。私たちのモデルは、クエリ画像とテキストの組み合わせに合わせた画像を取得します。 手法の概要 私たちは、コントラスト言語-画像事前学習モデル(CLIP)の言語エンコーダの言語能力を活用することを提案しています。CLIPは、さまざまなテキストの概念と属性に対して意味のある言語埋め込みを生成することに優れています。そのため、CLIP内の軽量なマッピングサブモジュールを使用して、画像の埋め込み空間からテキスト入力空間の単語トークンにマッピングすることを目指します。全体のネットワークは、ビジョン-言語コントラスト損失を最適化して、画像とテキストの埋め込み空間が可能な限り近接するようにします。そして、クエリ画像を単語のように扱うことができます。これにより、言語エンコーダによるクエリ画像の特徴とテキストの説明の柔軟でシームレスな組み合わせが可能になります。私たちはこの手法をPic2Wordと呼び、その訓練プロセスの概要を以下の図で提供します。マップされたトークンsは、単語トークン形式で入力画像を表すようにしたいと考えています。その後、マッピングネットワークを訓練して、言語埋め込みp内で画像埋め込みを再構築します。具体的には、CLIPで提案されたコントラスト損失を最適化し、ビジュアル埋め込みvとテキスト埋め込みpの間のコントラスト損失を計算します。 未ラベルの画像のみを使用してマッピングネットワーク(fM)のトレーニングを行います。視覚とテキストのエンコーダーは固定されたまま、マッピングネットワークのみを最適化します。 トレーニングされたマッピングネットワークを考慮すると、以下の図に示すように、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成することができます。 トレーニングされたマッピングネットワークを使用して、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成します。 評価 さまざまな実験を行って、Pic2WordのCIRタスクでの性能を評価します。 ドメイン変換 まず、提案手法の合成能力をドメイン変換で評価します。画像と変換先の画像ドメイン(例:彫刻、折り紙、漫画、おもちゃ)を与えられた場合、システムの出力は同じ内容の画像を新しい望ましい画像ドメインまたはスタイルで出力する必要があります。以下の図で示されるように、画像とテキストのカテゴリ情報やドメイン説明を柔軟に組み合わせる能力を評価します。ImageNetとImageNet-Rを使用して、実際の画像から4つのドメインへの変換を評価します。 教師付きトレーニングデータを必要としないアプローチとの比較のために、次の3つのアプローチを選びます:(i)画像のみは視覚埋め込みのみで検索を実行します、(ii)テキストのみはテキスト埋め込みのみを使用します、(iii)画像+テキストは視覚とテキストの埋め込みを平均化してクエリを構成します。 (iii)との比較では、言語エンコーダーを使用して画像とテキストを組み合わせる重要性が示されます。また、Fashion-IQまたはCIRRでCIRモデルをトレーニングするCombinerとも比較します。 入力クエリ画像のドメインを、テキストで指定されたドメイン(例:折り紙)に変換することを目指します。 下の図に示されているように、提案された手法はベースラインを大きく上回る結果を示しています。 ドメイン変換のための合成画像検索における結果(リコール@10、つまり最初の10枚の画像で関連するインスタンスの割合)。…

StorybirdはAIの力を借りて、誰でもわずか数秒でビジュアルストーリーを作成することができます
StoryBird.AIはAIの力を活用して、誰でも数秒でビジュアルストーリーを作成できます。彼らのStoriesプラグインは、ChatGPTプラグインストアで最も人気のあるプラグインの一つです。プラグインまたはウェブサイトを使用して、誰でも人工知能の助けを借りて魅力的なストーリーや本を作成できます。このプラットフォームは非常に使いやすく、OpenAIのChatGPTストアで最も求められるプラグインの1つであるStoriesプラグインを使用してすぐに始めることができます。ワクワクしませんか? ストーリーは見事なものであり、Storybird.aiでさまざまな例を探索することができます。以下のようなものがあります。 StoryBird.aiを使用すると、本を書き、編集し、公開し、売上を上げることさえできます。そのシンプルさと効果において、これに匹敵するAIソリューションは他にありません。 Storybirdのチームは、LLMsとGANsを活用してシームレスにする方法を見つけました。 主な特徴: 生成的編集:これにより、生成的な手法を使用してストーリーを編集できます。 速度:プロセスは非常に高速で、数秒で完了します。 個別化とカスタマイズ:プラットフォームでは、各ページの生成されたコンテンツを編集することでストーリーをカスタマイズできます。さらに、編集に基づいて関連する画像やイラストを再生成することもできます。まるで魔法のようであり、ストーリーはあなた自身だけのものになります。 印象的な結果:ストーリーやイラストは本当に印象的です。 Stories ChatGPTプラグイン 追加するのは簡単で、単に「stories」を検索して追加できます。 Storybird.aiは、魅力的なストーリーを作成するための便利なヒントを提供しています: ストーリーの短い説明で始める(20〜1000文字)。 該当する場合、キャラクターの名前を含める。 最適な結果を得るために、キャラクター(例:茶色の髪の女の子)や設定についての詳細を提供する。 ChatGPTでは、次のように簡単にプロセスを開始できます: そして、次のような迅速な結果を受け取ることができます: 以下は、次の初期プロンプトを使用した別の例です: 「12歳の少女であるオリビアという名前の少女についての物語を書いてください。彼女は毎朝早起きしてサッカーの練習をし、いつかプロの選手になることを夢見ています。」 バックパックを「Red」に変更したいのですが、それは簡単にできます。その後、イラストを再生成しました。 誰のためのものですか? StoryBird AIは、親、教育者、著者向けにパーソナライズされた物語を作成するためのツールです。…
モデルの解釈のマスタリング:パーシャル依存プロットの包括的な解説
モデルの解釈方法を知っていることは、それが奇妙なことをしていないかを理解するために不可欠ですモデルをよりよく知っているほど、予測時の振る舞いに驚かされる可能性は低くなります
学習トランスフォーマーコード入門:パート1 – セットアップ
あなたについてはわかりませんが、コードを見ることの方が論文を読むよりも簡単なことがありますAdventureGPTに取り組んでいた時、まずはReActの実装であるBabyAGIのソースコードを読むことから始めました

Falcon-7Bの本番環境への展開
これまでに、ChatGPTの能力と提供するものを見てきましたしかし、企業利用においては、ChatGPTのようなクローズドソースモデルは、企業がデータを制御できないというリスクがあるかもしれません...
極小データセットを用いたテキスト分類チャレンジ:ファインチューニング対ChatGPT
Toloka MLチームは、さまざまな条件下でのテキスト分類の異なるアプローチを継続的に研究し比較していますここでは、NLPのパフォーマンスに関する私たちの別の実験をご紹介します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.