Learn more about Search Results T5 - Page 35

- You may be interested
- 「データ分析と可視化のための生成型AIの...
- ディープラーニングのマスタリング:分岐...
- 「アレクサ、学生たちは A.I. について何...
- このAI研究は、ロボット学習および具現化...
- 「指先で軽く触れるだけで仮想オブジェク...
- 「Googleのアルゴリズムによって、FIDO暗...
- 「2023年8月の10の最高のAIフェイススワッ...
- 「勾配降下法アルゴリズムとその直感的な...
- ChatGPTを使った効率的なデバッグ
- 大学でAIプログラム/コースを選ぶ方法
- Python Enumerate():カウンターを使用...
- データウェアハウスとデータレイクとデー...
- リフレックスを使って、純粋なPythonでCha...
- ネットワークの強化:異常検知におけるML...
- 「ベクターデータベースは、生成型AIソリ...
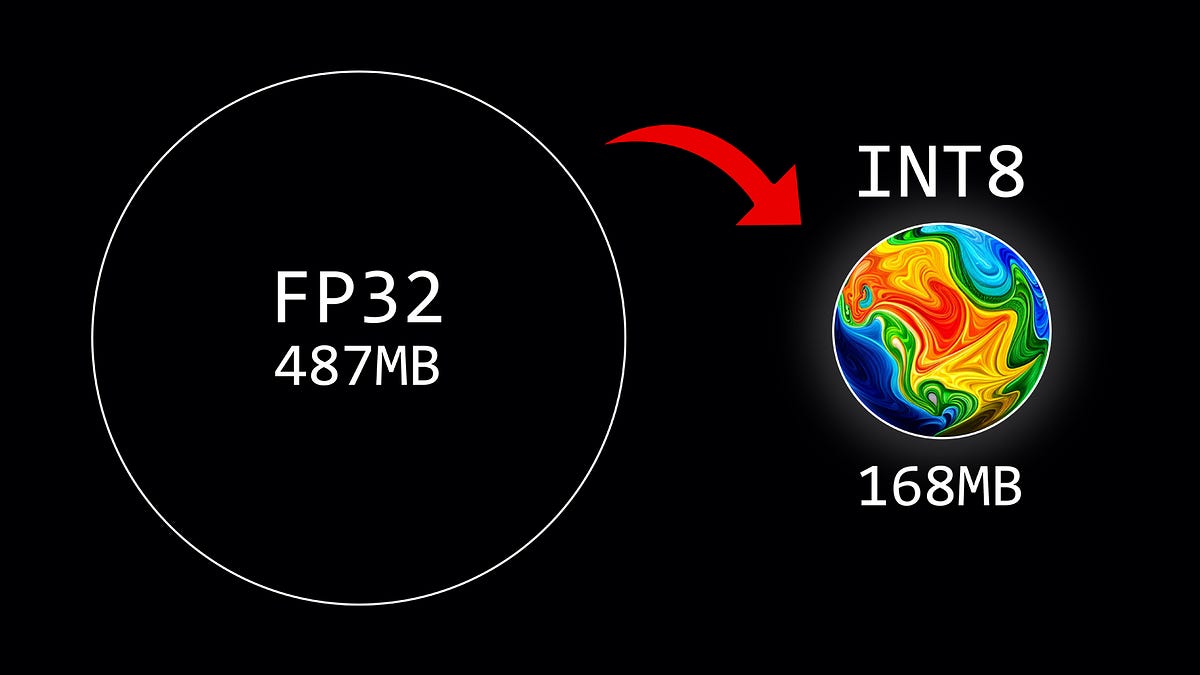
重み量子化の概要
この記事では、8ビットの量子化方式を使用して、大規模言語モデルのパラメータを量子化する方法について説明しています

新しいGoogle AI研究では、ペアワイズランキングプロンプティング(PRP)という新しい技術を使用して、LLMの負担を大幅に軽減することを提案しています
教師ありの対応モデルが数百万のラベル付き例で訓練されるのに対して、GPT-3やPaLMなどの大規模言語モデル(Large Language Models、LLMs)は、ゼロショット設定でもさまざまな自然言語のタスクで印象的な性能を示してきました。しかし、LLMsを使用して基本的なテキストランキング問題を解決することは、まちまちな結果となっています。既存の研究では、訓練済みのベースラインランカーと比較して明らかに性能が低いことが多いです。ただし、大規模でブラックボックスで商業的なGPT-4システムに依存する新しい戦略は、例外として扱われています。 彼らは、このようなブラックボックスのシステムに頼ることは、学術研究者にとっては重要な費用制約やアクセス制限のために理想的ではないと主張しています。ただし、ランキングメトリックスは入力ドキュメントの順序が変わると50%以上低下することも認識しています。この研究では、彼らはまず、現在のアプローチのポイントワイズとリストワイズの形式を使用した場合に、LLMsがランキング問題に苦労する理由を説明します。生成のみのLLM API(GPT-4など)ではこれができないため、ポイントワイズのランキングでは、ソートする前にLLMsがキャリブレーションされた予測確率を生成する必要があり、これは非常に困難とされています。 リストワイズのアプローチにおいては、人間には非常に明らかな指示でも、LLMsは一貫性のないまたは無意味な出力を提供することがよくあります。実証的には、以前の研究で用いられたリストワイズのランキングプロンプトは、VoAGIサイズのLLMsでは完全に無意味な結果を提供することがわかります。これらの結果から、現在広く使用されているLLMsは、ランキングタスクを理解する必要があることが示されており、これは事前トレーニングと微調整の技術がランキングの認識を欠いているためかもしれません。LLMsのタスクの複雑さを大幅に低減し、キャリブレーションの問題に対処するため、Google Researchの研究者はペアワイズランキングプロンプティング(PRP)パラダイムを提案しています。PRPは、クエリと一対のドキュメントをランキングタスクのプロンプトとして使用するシンプルなプロンプトアーキテクチャに基づいており、デフォルトで生成とスコアリングのLLM APIを提供します。 彼らは効率性に関する懸念に対応するためにいくつかのPRPのバリエーションについても議論しています。PRPの結果は、伝統的なベンチマークデータセット上で中程度の規模のオープンソースのLLMsを使用して、最先端のランキングパフォーマンスを達成するための初めての文献です。TREC-DL2020では、20BパラメータのFLAN-UL2モデルに基づくPRPは、黒箱の商業的なGPT-4に比べて、NDCG@1で5%以上優れたメソッドを提供しています(推定)50倍のモデルサイズ。TREC-DL2019では、PRPは、175Bのパラメータを持つInstructGPTなどの現在の解決策を、ほぼすべてのランキング指標で10%以上上回すことができますが、NDCG@5とNDCG@10のメトリックではGPT-4の解決策に劣る結果となります。また、3Bおよび13Bのパラメータを持つFLAN-T5モデルを使用した競争力のある結果も示して、PRPの有効性と適用範囲を示しています。 彼らはまた、PRPの追加の利点、LLM APIのスコアリングと生成のサポート、および入力順序への感度の低さについてもレビューしています。結論として、この研究は以下の3つの貢献を行っています: • 彼らは、LLMsを使用したゼロショットランキングにおいてペアワイズランキングプロンプティングがうまく機能することを初めて示しています。彼らの結果は、既存のシステムがブラックボックスで商業的でかなり大きなモデルを使用するのに対し、中程度の規模のオープンソースのLLMsに基づいています。 • シンプルなプロンプティングとスコアリングメカニズムを使用して、最先端のランキングパフォーマンスを実現することができます。この発見により、この領域での将来の研究がよりアクセス可能になります。 • 線形の複雑さを実現しながら、いくつかの効率化の改善を検証し、良好な実証的なパフォーマンスを示しています。
自分のハードウェアでのコード理解
現在の大規模言語モデル(LLM)が実行できるさまざまなタスクの中で、ソースコードの理解は、ソフトウェア開発者やデータエンジニアとしてソースコードで作業している場合に特に興味深いものかもしれません

この人工知能ベースのタンパク質言語モデルは、汎用のシーケンスモデリングを解除します
人々が生命の言語を学ぶ方法は、自然言語の構文意味とタンパク質のシーケンス機能を比較することによって根本的に変わりました。この比較は、NLPのプロテインドメインへの応用を向上させた歴史的なマイルストーンとしての固有の価値を持っていますが(言語モデルなど)、NLPの領域の結果は完全にプロテインの言語に翻訳されているわけではありません。NLPモデルのサイズをスケーリングアップするだけでなく、プロテインの言語モデルのスケーリングアップは、NLPモデルのサイズをスケーリングアップするよりもはるかに大きな影響を与える可能性があります。 巨大なパラメータ数で訓練された言語モデルが多数のステップで訓練を受けても、まだ学習グラデーションが顕著であり、過適合と見なされる傾向があります。そのため、モデルのサイズと学習された表現の豊かさとの間に比例関係があるという誤解が生じます。その結果、より正確または関連性のあるプロテイン表現を選択することは、徐々により大きなモデルを選択することに変わってきています。これには、より多くの計算能力が必要であり、したがってアクセスしにくくなります。特に、PLMのサイズは最近106から109のパラメータに増加しました。彼らは、ProtTransのProtT5-XL-U50を利用して、UniRef50データベースで事前に訓練されたエンコーダーデコーダートランスフォーマを使用して、トレーニング用のパラメータが3B、推論用のパラメータが1.5Bであるサイズパフォーマンスのベンチマークを基にしています。これにより、プロテイン言語モデルの最新の最先端技術が明らかになりました。 プロテイン配列モデリングのスケーリング原則を開発するために、その方向性の第一歩であるRITAファミリーの言語モデルを使用して、モデルのパフォーマンスがサイズによってどのように変化するかを示しました。RITAは、85Mから300M、680M、1.2Bのパラメータに比例してサイズが増加する4つの代替モデルを提供します。同様のパターンが後にProGen2によって確認されました。これは、さまざまなシーケンシングデータセットでトレーニングされ、6.4Bのパラメータを含むプロテイン言語モデルのコレクションです。最後に、この研究が公開された時点では、ESM-2は、650Mから3B、15Bのパラメータに比例してサイズが増加する一般的なプロテイン言語モデルの調査であり、モデルのスケーリングアップを推奨する最新の追加です。 より大きくて明らかに優れたPLMの間にある単純な関係は、コンピューティングコストやタスクに依存しないモデルの設計と展開など、いくつかの要素を無視しています。これにより、革新的な研究への参入のハードルが高くなり、スケールする能力が制限されます。モデルのサイズは確かに上記の目標の達成に影響を与えることは疑いようがありませんが、それが唯一の要素ではありません。同じ方向に向けた事前訓練データセットのスケーリングは条件付きであり、つまり、より大きなデータセットが常により品質の高い小さなデータセットよりも好ましいわけではありません。彼らは、言語モデルのスケーリングアップは条件付きであり、最適化のためのプロテインの知識によってガイドされた手段の小さなモデルよりも大きなモデルが必ずしも優れているわけではないと主張しています。 この研究の主な目標は、知識による最適化を反復的な経験的フレームワークに組み込み、実用的なリソースを通じて研究のイノベーションへのアクセスを促進することです。彼らのモデルは、その「文字」であるアミノ酸のより良い表現を学ぶことによって、生命の言語を「解放」するためのものであり、そのために彼らのプロジェクトを「アンク」と名付けました(生命の鍵を示す古代エジプトの記号に言及しています)。これは、アンクの一般性と最適化を評価するための2つの証拠としてさらに開発されています。 High-N(ファミリーベース)およびOne-N(シングルシーケンスベース)のアプリケーションにおけるプロテインエンジニアリングのための世代研究は、入力シーケンスの数であるNの範囲の構造と機能のベンチマークのパフォーマンスを上回るための第一歩です。第二のステップは、モデルのアーキテクチャだけでなく、モデルの作成、トレーニング、展開に使用されるソフトウェアやハードウェアなど、最適な属性の調査によってこのパフォーマンスを達成することです。アプリケーションのニーズに応じて、Ankh bigとAnkh baseという2つの事前訓練モデルを提供しています。それぞれ2つの計算方法を提供しています。彼らは、AnkhのフラッグシップモデルであるAnkh bigを便宜上Ankhと呼んでいます。事前訓練済みのモデルは、彼らのGitHubページで入手可能です。コードベースの実行方法も詳細に説明されています。
Pythonプロジェクトのセットアップ:パートV
経験豊富な開発者であろうと、🐍 Pythonを始めたばかりであろうと、堅牢で保守性の高いプロジェクトの構築方法を知ることは重要ですこのチュートリアルでは、...のプロセスを案内します
ドメイン適応:事前に学習済みのNLPモデルの微調整
ドメイン適応のために事前学習済みNLPモデルの微調整方法を学びましょう特定の文脈でのパフォーマンスと精度を向上させますステップバイステップのガイドと実践的な例を提供します
Matplotlibを使用してインフォグラフィックを作成する
データを扱い、データサイエンティストとして仕事をするためには、魅力的で興味深いデータの可視化を作成することが重要ですこれにより、読者に情報を簡潔な形式で提供することができ、理解を助けることができます

CMUの研究者がFROMAGeを紹介:凍結された大規模言語モデル(LLM)を効率的に起動し、画像と交錯した自由形式のテキストを生成するAIモデル
巨大な言語モデル(LLM)は、大規模なテキストコーパスでスケールに基づいて訓練されているため、人間のような話し言葉を生成したり、複雑な問いに応答したりするなど魅力的なスキルを発揮することができます。これらのモデルは非常に素晴らしいものですが、ほとんどの先端的なLLMはインターネットからダウンロードしたテキストデータのみで訓練されています。そのため、豊富な視覚的手がかりに触れる必要があるため、実世界に基づく概念を吸収することができません。その結果、現在使用されているほとんどの言語モデルは、視覚的な推論や基盤を必要とするタスクに制約があり、また視覚的な要素を生成することができません。本記事では、凍結されたLLMの能力をマルチモーダル(画像とテキスト)の入力と出力に効果的に使用する方法を示しています。 彼らは、言語モデルを訓練して、画像の代わりになる[RET]トークンを学習させ、コントラスティブラーニングを使用して[RET]の埋め込みを、それに関連する画像の視覚的な埋め込みに近づける線形マッピングも行っています。訓練中には、線形層と[RET]トークンの埋め込みの重みのみが更新され、モデルの大部分は凍結されたままです。そのため、彼らの提案手法はメモリと計算効率が非常に高いです。訓練が完了すると、モデルはいくつかのスキルを示します。元のテキストのみのLLMがテキストを生成する能力に加えて、新たなマルチモーダルの会話と推論のスキルを持っています。彼らの提案手法はモデルに依存せず、より強力なまたは大きなLLMの将来のリリースの基盤として使用することができます。 言語モデルは、画像を表す新しい[RET]トークンを学習し、コントラスティブラーニングを使用して、キャプションの[RET]の埋め込みを対応する画像の視覚的な埋め込みに近づける線形マッピングを行います。訓練中には、線形層と[RET]トークンの埋め込みの重みのみが更新され、モデルの大部分は固定されたままです。その結果、彼らの提案手法はメモリと計算効率が非常に高いです。訓練が完了すると、彼らのモデルはいくつかのスキルを示します。元のテキストのみのLLMがテキストを生成する能力に加えて、新たなマルチモーダルの会話と推論のスキルを持っています。彼らの提案手法はモデルに依存せず、より強力なまたは大きなLLMの将来のリリースの基盤として使用することができます。 オートリグレッシブLLMによるテキストから画像への検索の感度の向上を示しています。彼らの主な貢献の一つは、凍結された検索を使用したマルチモーダルデータに対するオートリグレッシブジェネレーション(FROMAGe)モデルであり、画像キャプションとコントラスティブラーニングを通じてLLMを視覚的に固定することが効果的に訓練されています。以前のアルゴリズムはウェブスケールの画像テキストデータが必要でしたが、FROMAGeは画像キャプションのペアだけから強力なフューショットのマルチモーダル能力を開発しています。彼らの手法は、以前のモデルよりも長く複雑な自由形式のテキストに対してより正確です。視覚的な入力を必要とするタスクにおいて、事前に訓練されたテキストのみのLLMの現在のスキル、コンテキストでの学習、入力の感度、会話の作成などを活用する方法を示しています。 彼らは以下を示しています:(1) 画像とテキストが交互に並ぶシーケンスからの文脈に基づいた画像の検索、(2) ビジュアルな会話におけるゼロショットの優れたパフォーマンス、および(3) 画像の検索における強化された対話文脈の感度。彼らの結果は、マルチモーダルなシーケンスの学習と生成を可能にするモデルの可能性を示しています。また、視覚に基づくタスクでの事前に訓練されたテキストのみのLLMの能力も強調しています。より多くの研究開発を促進するために、彼らのコードと事前訓練モデルは近々一般に公開される予定です。 このアプローチを使用することで、言語モデルは視覚領域に基づいて固定され、任意の画像テキスト入力を処理し、一貫した画像テキスト出力を生成することができます。緑の吹き出しはモデルによって作成され、グレーの吹き出しは入力プロンプトを表します。

Contextual AIは、VQAv2においてFlamingoを9%上回る(56->65%)ビジョン補完言語モデルのためのAIフレームワークLENSを導入しました
大規模言語モデル(LLM)は、最近の数年間で自然言語理解を変革し、ゼロショットおよびフューショットの環境での特に意味理解、クエリ解決、およびテキスト生成の能力を示しています。図1(a)に示すように、ビジョンに関わるタスクでLLMを使用するためのいくつかの手法が提案されています。光学エンコーダを使用して各画像を連続埋め込みの系列として表現し、LLMが理解できるようにする方法もあります。別の手法では、コントラスト学習でトレーニングされた固定ビジョンエンコーダを使用し、凍結されたLLMに追加の層を追加してゼロから学習します。 別の手法では、凍結された視覚エンコーダ(コントラスト学習で事前トレーニングされたもの)と凍結されたLLMを整列させるために、軽量トランスフォーマをトレーニングすることを推奨しています。上記の研究では進歩していますが、追加の事前トレーニング段階の計算コストを正当化するのは依然として困難です。また、既存のLLMと視覚および言語のモダリティを同期させるために、テキスト、写真、動画などの大規模なデータベースが必要です。Flamingoでは、視覚特徴を追加するために、事前トレーニングされたLLMに新しいクロスアテンション層を追加します。 図1:視覚と言語のモダリティを調整するための手法の比較 マルチモーダルプリトレーニングには2つのオプションがあります:(a)対応またはWebデータセットを利用する方法;および(b)LENSは、追加のマルチモーダルデータセットの要件がない、市販のLLMと組み合わせて使用できるプリトレーニングフリーの手法です。LENSと異なり、従来の手法では視覚タスクを達成するために大規模なマルチモーダルデータセットでの共同アライメントプリトレーニングが必要です。 マルチモーダルプリトレーニング段階では、驚くべき20億の画像テキストペアと4300万のウェブサイトが必要であり、事前にトレーニングされた画像エンコーダと凍結されたLLMを使用しても最大15日かかることがあります。代わりに、さまざまな「ビジョンモジュール」を使用して、彼らはビジュアル入力から情報を抽出し、詳細なテキスト表現(タグ、属性、アクション、関係など)を生成し、それをLLMに直接フィードして追加のマルチモーダルプリトレーニングの必要性を回避することができます(図1(b)参照)。Contextual AIとスタンフォード大学の研究者は、LENS(Large Language Models ENnhanced to See)というモジュラーな戦略を紹介し、LLMを「推論モジュール」として使用し、個別の「ビジョンモジュール」で機能する方法を提案しています。 彼らはまず、コントラストモデルや画像キャプションモデルなどの事前トレーニング済みビジョンモジュールを使用してLENS手法で豊富なテキスト情報を抽出します。そのテキストは次にLLMに送られ、オブジェクト認識、ビジョン、言語(V&L)を含むタスクを実行することができます。LENSは、追加のマルチモーダルプリトレーニングステージやデータの必要性をなくすことで、モダリティ間のギャップを無償で埋めることができます。また、この統合により、コンピュータビジョンと自然言語処理の最新の進歩を即座に活用することができ、両分野の利点を最大限に引き出すことができます。 彼らは以下の貢献を提供しています: • LENSは、言語モデルのfew-shot、インコンテキスト学習能力を使用して、コンピュータビジョンの課題を処理するモジュラーな方法を提供します。 • LENSにより、追加のトレーニングやデータなしで、どの市販のLLMでも視覚情報を認識することができます。 • 凍結されたLLMを使用してオブジェクト認識およびビジュアル推論タスクを処理するために、ビジョンと言語のアライメントやマルチモーダルデータの追加は必要ありません。実験結果は、彼らの手法が、KosmosやFlamingoなどのエンドツーエンド共同プリトレーニングモデルと競合または優れたゼロショットパフォーマンスを達成することを示しています。彼らの論文の一部の実装はGitHubで利用できます。
既存のLLMプロジェクトをLangChainを使用するように適応する
おめでとうございます!素晴らしいLLMの概念証明が完成しましたね自信を持って世界に披露できます!もしかしたら、OpenAIライブラリを直接利用したかもしれませんし、他のライブラリを使用しているかもしれませんが、どのようにしても、この素晴らしい成果を誇示できます!
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.