Learn more about Search Results ML - Page 353

- You may be interested
- 「AIコントロールを手にして、サイバーセ...
- 究極のGFNサーズデー:41の新しいゲームに...
- GoogleのAIがPaLI-3を紹介:10倍も大きい...
- 「LLMsとRAGを組み合わせることによる拡張」
- 大型言語モデルへの優しい導入
- 「RNNにおける誤差逆伝播法と勾配消失問題...
- 「マルチモーダルAIの最新の進歩:(ChatG...
- 発達心理学に触発された深層学習モデルに...
- 海洋ナビゲーションのためのロボットプラ...
- AIシステムは、構造設計のターゲットを満...
- パートナーシップ:Amazon SageMakerとHug...
- 「ChatGPTの高度な設定ガイド – Top...
- 「2023年の振り返り:Post-ChatGPT時代の...
- AutoGPTQをご紹介します:GPTQアルゴリズ...
- 新しいZeroscope v2モデルに会ってくださ...

🤗 Optimum IntelとOpenVINOでモデルを高速化しましょう
昨年7月、インテルとHugging Faceは、Transformerモデルのための最新かつシンプルなハードウェアアクセラレーションツールの開発で協力することを発表しました。本日、私たちはOptimum IntelにIntel OpenVINOを追加したことをお知らせできて非常に嬉しく思います。これにより、Hugging FaceハブまたはローカルにホストされるTransformerモデルを使用して、様々なIntelプロセッサ上でOpenVINOランタイムによる推論を簡単に実行できます(サポートされているデバイスの完全なリストを参照)。OpenVINOニューラルネットワーク圧縮フレームワーク(NNCF)を使用してモデルを量子化し、サイズと予測レイテンシをわずか数分で削減することもできます。 この最初のリリースはOpenVINO 2022.2をベースにしており、私たちのOVModelsを使用して、多くのPyTorchモデルに対する推論を実現しています。事後トレーニング静的量子化と量子化感知トレーニングは、多くのエンコーダモデル(BERT、DistilBERTなど)に適用することができます。今後のOpenVINOリリースでさらに多くのエンコーダモデルがサポートされる予定です。現在、エンコーダデコーダモデルの量子化は有効化されていませんが、次のOpenVINOリリースの統合により、この制限は解除されるはずです。 では、数分で始める方法をご紹介します! Optimum IntelとOpenVINOを使用してVision Transformerを量子化する この例では、食品101データセットでイメージ分類のためにファインチューニングされたVision Transformer(ViT)モデルに対して事後トレーニング静的量子化を実行します。 量子化は、モデルパラメータのビット幅を減らすことによってメモリと計算要件を低下させるプロセスです。ビット数を減らすことで、推論時に必要なメモリが少なくなり、行列乗算などの演算が整数演算によって高速に実行できるようになります。 まず、仮想環境を作成し、すべての依存関係をインストールしましょう。 virtualenv openvino source openvino/bin/activate pip install pip --upgrade pip…

マルチリンガルASRのためのWhisperの調整を行います with 🤗 Transformers
このブログでは、ハギングフェイス🤗トランスフォーマーを使用して、Whisperを任意の多言語ASRデータセットに対して細かく調整する手順を段階的に説明します。このブログでは、Whisperモデル、Common Voiceデータセット、および細かな調整の背後にある理論について詳しく説明し、データの準備と細かい調整の手順を実行するためのコードセルと共に提供しています。説明は少ないですが、すべてのコードがあるより簡略化されたバージョンのノートブックは、関連するGoogle Colabを参照してください。 目次 はじめに Google ColabでのWhisperの細かい調整 環境の準備 データセットの読み込み 特徴抽出器、トークナイザー、およびデータの準備 トレーニングと評価 デモの作成 締めくくり はじめに Whisperは、OpenAIのAlec Radfordらによって2022年9月に発表された自動音声認識(ASR)のための事前学習モデルです。Whisperは、Wav2Vec 2.0などの先行研究とは異なり、ラベル付きの音声トランスクリプションデータで事前学習されています。具体的には、680,000時間のデータが使用されています。これは、Wav2Vec 2.0の訓練に使用されるラベルなしの音声データ(60,000時間)よりも桁違いに多いデータです。さらに、この事前学習データのうち117,000時間が多言語ASRデータです。これにより、96以上の言語に適用できるチェックポイントが生成され、その多くは低リソース言語とされています。 このような大量のラベル付きデータにより、Whisperは事前学習データから音声認識の教師ありタスクを直接学習し、音声トランスクリプションデータからテキストへのマッピングを学習します。そのため、Whisperはパフォーマンスの高いASRモデルを得るためにほとんど追加の細かい調整を必要としません。これに対して、Wav2Vec 2.0は非教師付きタスクのマスク予測で事前学習されており、音声から隠れた状態への中間的なマッピングを学習します。非教師付きの事前学習は音声の高品質な表現を生み出しますが、音声からテキストへのマッピングは学習されません。このマッピングは細かい調整中にのみ学習されるため、競争力のあるパフォーマンスを得るにはより多くの細かい調整が必要です。 680,000時間のラベル付き事前学習データにスケールされると、Whisperモデルは多くのデータセットとドメインに対して高い汎化能力を示します。事前学習されたチェックポイントは、LibriSpeech ASRのtest-cleanサブセットで約3%の単語エラーレート(WER)を達成し、TED-LIUMでは4.7%のWERで新たな最先端の結果を実現します(Whisper論文の表8を参照)。Whisperが事前学習中に獲得した多言語ASRの知識は、他の低リソース言語に活用することができます。細かい調整により、事前学習済みのチェックポイントを特定のデータセットと言語に適応させることで、これらの結果をさらに改善することができます。 Whisperは、Transformerベースのエンコーダーデコーダーモデルであり、シーケンスからシーケンスへのモデルとも呼ばれています。Whisperは、オーディオのスペクトログラム特徴のシーケンスをテキストトークンのシーケンスにマッピングします。まず、生のオーディオ入力は特徴抽出器によってログメルスペクトログラムに変換されます。次に、Transformerエンコーダーはスペクトログラムをエンコードしてエンコーダーの隠れ状態のシーケンスを形成します。最後に、デコーダーはエンコーダーの隠れ状態と以前に予測されたトークンの両方に依存して、テキストトークンを自己回帰的に予測します。図1はWhisperモデルを要約しています。 <img…

Diffusersを使用したDreamboothによる安定した拡散のトレーニング
ドリームブースは、特殊なファインチューニングの形式を使用して、安定拡散に新しい概念を教えるための技術です。一部の人々は、素晴らしい状況に自分自身を配置するために、いくつかの写真を使用してそれを利用しています。一方、他の人々は新しいスタイルを取り入れるためにそれを使用しています。🧨 Diffusersは、Dreamboothトレーニングスクリプトを提供しています。トレーニングには時間はかかりませんが、適切なハイパーパラメータのセットを選択するのは難しく、過学習しやすいです。 私たちは、Dreamboothのさまざまな設定の効果を分析するために多くの実験を行いました。この投稿では、Stable DiffusionをDreamboothでファインチューニングする際に結果を改善するための見つけたポイントといくつかのヒントを紹介します。 始める前に、この方法は決して悪意のある目的、何らかの害を引き起こすため、または人々を知らずになりすますために使用してはなりません。それでトレーニングされたモデルは、Stable Diffusionモデルの配布を規制するCreativeML Open RAIL-Mライセンスによって依然として拘束されます。 注意:この投稿の以前のバージョンはW&Bレポートとして公開されました。 要約:推奨設定 ドリームブースはすぐに過学習します。良質な画像を得るためには、トレーニングステップ数と学習率の間の「適切なスイートスポット」を見つける必要があります。低い学習率を使用し、結果が満足できるまでステップ数を徐々に増やすことを推奨します。 ドリームブースでは、顔に対してはより多くのトレーニングステップが必要です。私たちの実験では、バッチサイズ2とLR 1e-6を使用した場合に、800〜1200ステップがうまく機能しました。 事前保存は、顔のトレーニング時に過学習を避けるために重要です。他の対象に対しては、それほど大きな違いはないようです。 生成された画像がノイズが多いか品質が低下している場合、それはおそらく過学習を意味します。まず、上記の手順を試して避けてみてください。生成された画像がまだノイズが多い場合は、DDIMスケジューラを使用するか、より多くの推論ステップ(私たちの実験では約100ステップがうまく機能しました)を実行してみてください。 UNetに加えてテキストエンコーダをファインチューニングすることは、品質に大きな影響を与えます。私たちの最良の結果は、テキストエンコーダのファインチューニング、低いLR、適切なステップ数の組み合わせを使用して得られました。ただし、テキストエンコーダのファインチューニングにはより多くのメモリが必要ですので、少なくとも24 GBのRAMを持つGPUが理想です。Google ColabやKaggleが提供する16 GBのGPUのようなものでは、8ビットAdam、fp16トレーニング、勾配蓄積などの技術を使用してトレーニングすることが可能です。 EMAを使用してファインチューニングするかどうかに関係なく、類似の結果が得られました。 ドリームブースをトレーニングするためにsksという単語を使用する必要はありません。最初の実装の一部は、それが語彙の中で稀なトークンであったためにそれを使用しましたが、実際にはライフルの一種です。私たちの実験および@nitrosockeなどの実験は、ターゲットを説明するために自然に使用する用語を選択しても問題ないことを示しています。 学習率の影響 ドリームブースは非常に速く過学習します。良い結果を得るためには、データセットに合理的な学習率とトレーニングステップ数を調整します。私たちの実験(以下で詳細に説明)では、高い学習率と低い学習率で4つの異なるデータセットでファインチューニングを行いました。すべての場合で、低い学習率でより良い結果が得られました。 実験設定…

新しい価格設定をご紹介します
ご注意いただいたかもしれませんが、最近、当社の料金ページは大幅に変更されています。 まず、Inference APIサービスの有料ティアを廃止します。Inference APIは引き続き誰でも無料で利用できます。ただし、高速でエンタープライズグレードの推論サービスをお探しの場合は、新しいソリューションである「Inference Endpoints」をご覧ください。 Inference Endpointsに加えて、Spaces向けのハードウェアアップグレードを最近導入しました。これにより、お好きなハードウェアでMLデモを実行することができます。これらのサービスの利用にはサブスクリプションは必要ありませんが、請求設定からアカウントにクレジットカードを追加する必要があります。また、組織に対して支払い方法を関連付けることもできます。 請求設定では、有料サービスに関するすべてを一元管理できます。そこから、個人のPROサブスクリプションを管理したり、支払い方法を更新したり、過去3ヶ月間の利用状況を可視化したりすることができます。有料サービスとサブスクリプションの利用料金は毎月の開始時に請求され、記録用の統合請求書が利用可能です。 要約: HFでは、AIのための計算への簡単なアクセスを提供することで収益化しています。AutoTrain、Spaces、Inference Endpointsなどのサービスは、Hubから直接アクセスできます。料金体系について詳しくは、当社の価格と請求システムについてのページをご覧ください。 ご質問があれば、お気軽にお問い合わせください。フィードバックを歓迎します🔥

ホモモーフィック暗号化による暗号化データの感情分析
感情分析モデルは、テキストがポジティブ、ネガティブ、または中立であるかを判断することが広く知られています。しかし、このプロセスには通常、暗号化されていないテキストへのアクセスが必要であり、プライバシー上の懸念が生じる可能性があります。 ホモモーフィック暗号化は、復号化することなく暗号化されたデータ上で計算を行うことができる暗号化の一種です。これにより、ユーザーの個人情報や潜在的に機密性の高いデータがリスクにさらされるアプリケーションに適しています(例:プライベートメッセージの感情分析)。 このブログ投稿では、Concrete-MLライブラリを使用して、データサイエンティストが暗号化されたデータ上で機械学習モデルを使用することができるようにしています。事前の暗号学の知識は必要ありません。暗号化されたデータ上で感情分析モデルを構築するための実践的なチュートリアルを提供しています。 この投稿では以下の内容をカバーしています: トランスフォーマー トランスフォーマーをXGBoostと組み合わせて感情分析を実行する方法 トレーニング方法 Concrete-MLを使用して予測を暗号化されたデータ上の予測に変換する方法 クライアント/サーバープロトコルを使用してクラウドにデプロイする方法 最後に、この機能を実際に使用するためのHugging Face Spaces上の完全なデモで締めくくります。 環境のセットアップ まず、次のコマンドを実行してpipとsetuptoolsが最新であることを確認します: pip install -U pip setuptools 次に、次のコマンドでこのブログに必要なすべてのライブラリをインストールします。 pip install concrete-ml transformers…

Hugging Faceの機械学習デモ(arXiv上)
私たちは、Hugging FaceがarXivと協力して論文をよりアクセスしやすく、見つけやすく、楽しくすることを発表できることを非常に嬉しく思っています!今日から、Hugging Face SpacesはarXivLabsとの統合を通じて、コミュニティまたは著者自身によって作成されたデモへのリンクを含むDemoタブとして提供されます。お気に入りの論文のデモタブに移動することで、オープンソースのデモへのリンクを見つけ、すぐに試すことができます🔥 Hugging Face Spacesは2021年10月のローンチ以来、コミュニティによって作成された12,000以上のオープンソースの機械学習デモを構築し共有するために使用されています。Spacesを使用すると、Hugging Faceユーザーはブラウザを使用してコードを実行することなく、モデルを共有、探索、議論し、対話型アプリケーションを構築することができます。これらのデモは、GradioやStreamlitなどのオープンソースのツールを使用し、Hugging Face Hubで利用可能なモデルとデータセットを活用して構築されています。 最新のarXivの統合により、ユーザーは論文のarXivの要約ページで最も人気のあるデモを見つけることができます。たとえば、BERT言語モデルのデモを試したい場合は、BERT論文のarXivページに移動し、デモタブに移動します。そこには、オープンソースコミュニティによって作成された200以上のデモが表示されます。一部のデモは単にBERTモデルを紹介しているだけであり、他のデモはBERTをより大きなパイプラインの一部として変更または使用する関連アプリケーションを紹介しています。上記のデモのようなものです。 デモにより、機械学習だけでなく、生物学、化学、天文学、経済学など、計算モデルが構築される他の分野を広範な視聴者が探索できるようになります。デモはモデルの動作原理の認識と理解を高め、研究者の仕事の可視性を高め、より多様な視聴者がバイアスやその他の問題を特定およびデバッグできるようにします。これらのデモにより、コードを一行も書くことなく、他の人が論文の結果を探索することができるため、研究の再現性が向上します!arXivとのこの統合に興奮しており、研究コミュニティがコミュニケーション、発信、解釈性を向上させるためにどのように活用するかを楽しみにしています。

機械学習洞察のディレクター【パート4】
MLソリューションをより速く構築したい場合は、今すぐ hf.co/support をご覧ください! 👋 ML Insightsシリーズのディレクターへお帰りなさい!以前のエディションを見逃した場合は、こちらで見つけることができます: ディレクター・オブ・マシン・ラーニング・インサイト[パート1] ディレクター・オブ・マシン・ラーニング・インサイト[パート2:SaaSエディション] ディレクター・オブ・マシン・ラーニング・インサイト[パート3:金融エディション] 🚀 この第4弾では、次のトップマシン・ラーニング・ディレクターがそれぞれの業界へのマシン・ラーニングの影響について語ります:ハビエル・マンシージャ、ショーン・ギットンズ、サミュエル・フランクリン、エヴァン・キャッスル。全員が現在、豊富なフィールドの洞察を持つマシン・ラーニングのディレクターです。 免責事項:すべての意見は個人の意見であり、過去または現在の雇用者の意見ではありません。 ハビエル・マンシージャ – マーケティングサイエンス部門のマシン・ラーニングディレクター、メルカドリブレ 経歴:経験豊富な起業家でありリーダーであるハビエルは、2010年以来マシン・ラーニングを構築する高級企業であるMachinalisの共同設立者兼CTOでした(そう、ニューラルネットの突破前の時代です)。 MachinalisがMercado Libreに買収されたとき、その小さなチームは10,000人以上の開発者を持つテックジャイアントにマシン・ラーニングを可能にする能力として進化し、ほぼ1億人の直接ユーザーの生活に影響を与えました。ハビエルは、彼らのマシン・ラーニングプラットフォーム(NASDAQ MELI)の技術と製品のロードマップだけでなく、ユーザーのトラッキングシステム、ABテストフレームワーク、オープンソースオフィスもリードしています。ハビエルはPython-Argentinaの非営利団体PyArの積極的なメンバーおよび貢献者であり、家族や友人、Python、サイクリング、サッカー、大工仕事、そしてゆっくりとした自然の休暇が大好きです! おもしろい事実:私はSF小説を読むのが大好きで、引退後は短編小説を書くという10代の夢を再開する予定です。📚 メルカドリブレ:ラテンアメリカ最大の企業であり、コンチネンタルのeコマース&フィンテックの普遍的なソリューションです 1. eコマースにおいてMLがポジティブな影響を与えたのはどのような場合ですか? 詐欺防止や最適化されたプロセスやフローなど、特定のケースにおいてMLは不可能を可能にしたと言えます。他のほとんどの分野では想像もできなかった方法で、MLがUXの次のレベルを実現しました。…
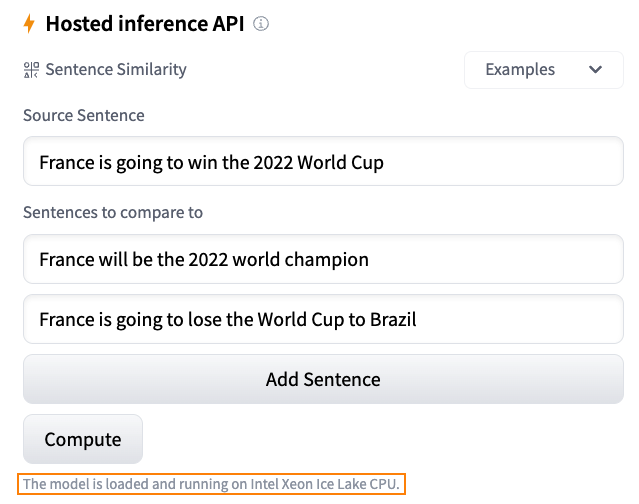
Hugging Faceにおける推論ソリューションの概要
毎日、開発者や組織はHugging Faceでホストされたモデルを採用し、アイデアを概念実証デモに、デモを本格的なアプリケーションに変えています。例えば、Transformerモデルは、自然言語処理、コンピュータビジョン、音声など、さまざまな機械学習(ML)アプリケーションの人気のあるアーキテクチャとなりました。最近では、ディフューザーがテキストから画像または画像から画像を生成するための人気のあるアーキテクチャとなりました。他のアーキテクチャも他のタスクで人気があり、私たちはそれらをすべてHF Hubでホストしています! Hugging Faceでは、最新のモデルを最小限の摩擦でテストおよび展開できる能力は、MLプロジェクトのライフサイクル全体で重要です。コストとパフォーマンスの比率を最適化することも同様に重要であり、無料のCPUベースの推論ソリューションを提供していただいたインテルの友人に感謝申し上げます。これは私たちのパートナーシップにおけるさらなる大きな一歩です。また、Intel Xeon Ice Lakeアーキテクチャによる高速化を無料でお楽しみいただけるため、ユーザーコミュニティの皆様にとっても素晴らしいニュースです。 さあ、Hugging Faceでの推論オプションを見てみましょう。 無料推論ウィジェット Hugging Faceハブでの私のお気に入りの機能の1つは、推論ウィジェットです。モデルページにある推論ウィジェットを使用すると、サンプルデータをアップロードして1クリックで予測することができます。 以下は、sentence-transformers/all-MiniLM-L6-v2モデルを使用した文の類似性の例です: モデルの動作、出力、およびデータセットのいくつかのサンプルでのパフォーマンスを素早く把握する最良の方法です。モデルはサーバー上でオンデマンドでロードされ、必要なくなるとアンロードされます。コードを書く必要はありませんし、この機能は無料です。どこが好きではないですか? 無料推論API 推論APIは、推論ウィジェットの内部で動作しています。単純なHTTPリクエストで、ハブの任意のモデルをロードし、数秒でデータを予測することができます。モデルのURLと有効なハブトークンが必要です。 以下は、xlm-roberta-baseモデルを1行でロードして予測する方法です: curl https://api-inference.huggingface.co/models/xlm-roberta-base \ -X POST \…

インターンを募集しています!
AIの中でも、–と自負してもいいくらい–最もクールな場所の一つで未来を一緒に築きたいですか?2023年のインターンシッププログラムを発表します。ハギングフェイスのメンターと協力して、AIと機械学習の最先端の問題に取り組みます。 バックグラウンドを問わず、応募者を歓迎します!理想的には、いくつかの関連する経験があり、責任ある機械学習の民主化の使命に興奮しています。私たちの分野の進歩は、既存の格差を不均衡に悪化させる可能性があります。それが、社会の最も弱者である人々、特に有色人種、労働階級の出身者、女性、LGBTQ+の人々に不利な影響を与えることがあります。これらのコミュニティは、私たちの研究コミュニティが行う仕事の中心に置かれなければなりません。したがって、これらのアイデンティティを反映した個人の経験を持つ人々からの提案を強く推奨します! ポジション 次のインターンシップのポジションがオープンソースチームで利用可能です。それぞれのライブラリのメンテナと一緒に働きます: Accelerate Internship,ライブラリに新しく影響力のある機能を統合するためのリーダーシップポジション。 Text to Speech Internship,テキストから音声再生に取り組むポジション。 次の科学チームのポジションが利用可能です: Embodied AI Internship,シミュレータでの強化学習に取り組むEmbodied AIチームとの協力ポジション。 Fast Distributed Training Framework Internship,大規模言語モデルの柔軟な分散トレーニングのためのフレームワークを作成するポジション。 Datasets for LLMs Internship,次世代の大規模言語モデルと関連ツールのトレーニングデータセットを作成するポジション。…
タンパク質を用いたディープラーニング
この記事を書く際には、2つの対象読者を想定しています。1つ目は機械学習に入門しようとしている生物学者であり、もう1つは生物学に入門しようとしている機械学習者です。もし生物学または機械学習のいずれにも詳しくない場合でも、どうぞご参加ください。ただし、時折混乱するかもしれません。そして、両方に詳しい場合は、この記事は必要ないかもしれません – これらのモデルが実際にどのように機能するかを確認するために、直接例のノートブックに移動できます: タンパク質言語モデルのファインチューニング(PyTorch、TensorFlow) ESMFoldを使用したタンパク質の折りたたみ(現時点ではopenfoldの依存関係のため、PyTorchのみ) 生物学者向けの紹介:言語モデルとは一体何なのか? タンパク質を扱うモデルは、BERTやGPTのような大規模な言語モデルに強く影響を受けています。したがって、これらのモデルがどのように機能するかを理解するために、2016年ごろに遡ってみましょう。ドナルド・トランプはまだ選出されておらず、Brexitも起こっておらず、ディープラーニング(DL)は毎日新記録を打ち立てている最新の技術です。DLの成功の鍵は、人工ニューラルネットワークを使用してデータの複雑なパターンを学習することです。ただし、DLには1つの重大な問題があります – 実際には、良い結果を得るためには非常に多くのデータが必要であり、多くのタスクではそのデータが利用できませんでした。 例えば、英語の文を入力として受け取り、それが文法的に正しいかどうかを判断するためのDLモデルを訓練したいとしましょう。そのためにトレーニングデータを集めると、以下のようなものになるでしょう: 理論的には、当時このタスクは完全に可能でした – このようなトレーニングデータをDLモデルに与えれば、新しい文が文法的に正しいかどうかを予測することができるようになるはずです。しかし、実際にはうまくいかなかったのです。なぜなら、2016年当時、ほとんどの人々が各タスクごとに新しいモデルをランダムに初期化していたからです。これはつまり、モデルがトレーニングデータの例だけから必要なすべての知識を学ぶ必要があったということです! それがどれほど困難であるかを理解するために、機械学習モデルであり、私があなたに学習してほしいタスクのトレーニングデータを与えるとします。以下に示します: ここで、あなたが見たことのない言語を選んだため、おそらく自信を持ってこのタスクを学習できるとは思えません。おそらく何百回も何千回もの例を見るまで、入力の中で再発する単語やパターンをいくつか見つけ出すことができるかもしれません。その場合でも、新しい単語や一般的でない表現が登場すると、あなたは間違った予測をする可能性があります。偶然ではありませんが、当時のDLモデルの性能もほぼ同じでした! では、同じタスクを英語で試してみましょう: 今回は簡単です – タスクは単に映画のレビューがポジティブ(1)かネガティブ(0)かを予測することです。2つのポジティブな例と2つのネガティブな例だけで、おそらくほぼ100%の正確さでこのタスクを達成できるでしょう。なぜなら、英語の語彙や文法、映画や感情表現に関する文化的な文脈について、すでに豊富な前提知識を持っているからです。その知識がなければ、最初のタスクのような状況になります – 入力の中にさえ表面的なパターンを見つけるには、膨大な数の例を読む必要があります。そして、何十万もの例を研究する時間をかけても、英語のタスクにおいてたった4つの例だけで得られるよりもはるかに正確な予測はできません。 重要なブレークスルー:転移学習 機械学習では、このような既知の知識を新しいタスクに転移する概念を「転移学習」と呼びます。このような転移学習をDLにうまく適用することは、2016年ごろのこの分野の主要な目標でした。2016年までには、事前学習された単語ベクトル(非常に興味深いものですが、このブログ記事の範囲外です!)などが存在し、一部の知識が新しいモデルに転移できるようになっていましたが、この知識の転移はまだ比較的表面的であり、モデルはまだ大量のトレーニングデータが必要でした。 この状況は2018年まで続きました。その年、ULMFiTと後にBERTという2つの重要な論文が発表されました。これらは、自然言語の転移学習を本当にうまく機能させた最初の論文であり、特にBERTは事前学習された大規模な言語モデルの時代の始まりを示しました。両論文で共有されているトリックは、ディープラーニングの人工ニューラルネットワークの内部構造を利用したものです…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.