Learn more about Search Results ML - Page 352

- You may be interested
- 「データ資産のポートフォリオを構築およ...
- マッキンゼー・レポート:B2Bセールスにと...
- 「データサイエンスの観点からFCバルセロ...
- ユーザーのコンテキストに基づいてアイテ...
- 「HaystackにおけるRAGパイプラインの拡張...
- 「H3とPlotlyを使用してヘキサゴンマップ...
- 「ジェネレーティブAIがビジネス、健康医...
- 「NLPエンジニアになるには?キャリアロー...
- 我々はまもなく独自のパーソナルAIムービ...
- 「EU AI Actについて今日関心を持つべき理...
- ETHチューリッヒの研究者が、大規模な言語...
- 音から視覚へ:音声から画像を合成するAud...
- 真菌アーキテクチャと論理バクテリア
- 「夢を先に見て、後で学ぶ:DECKARDは強化...
- データサイエンティストやアナリストのた...
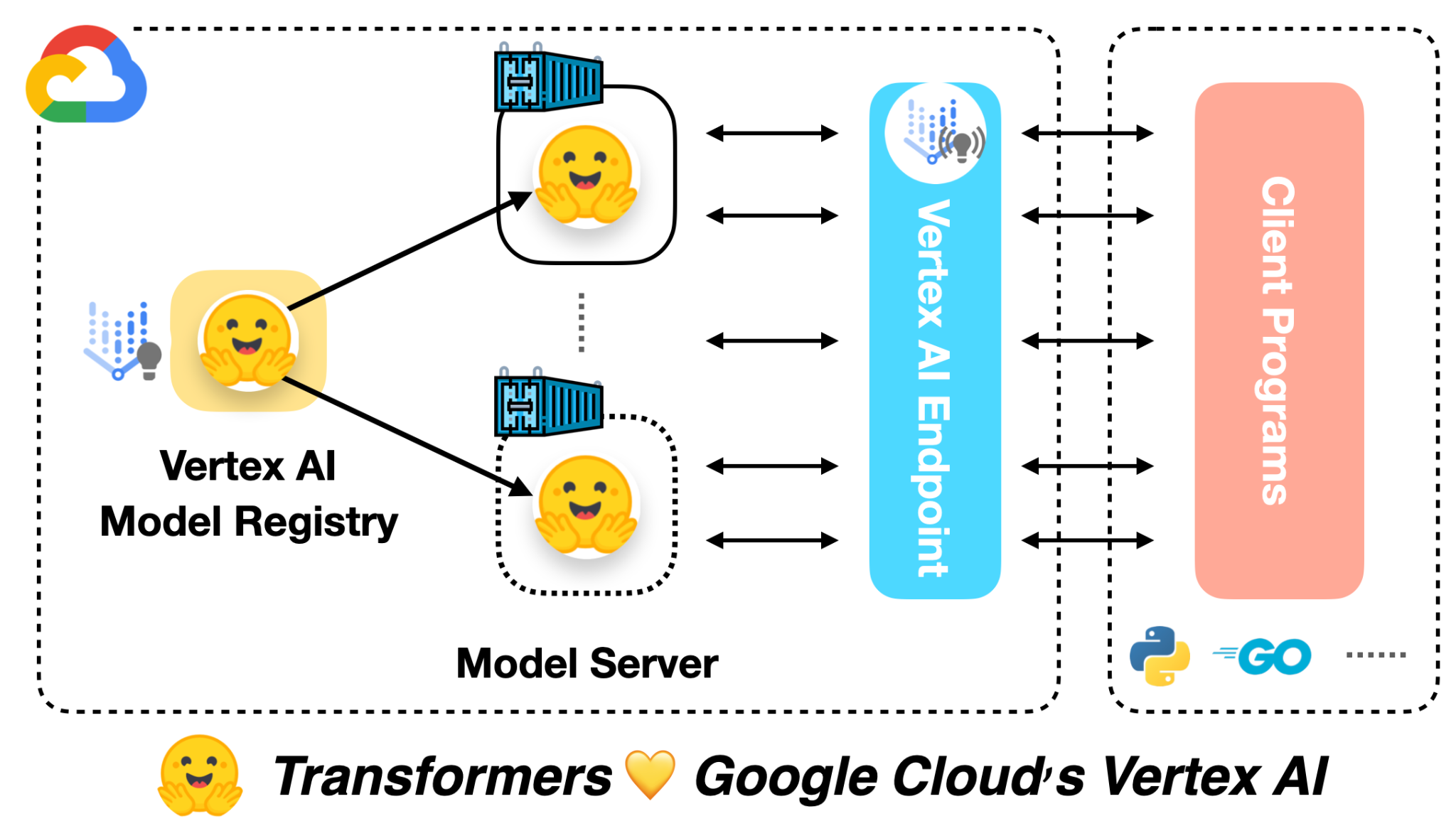
🤗 ViTをVertex AIに展開する
前の投稿では、Vision Transformers(ViT)モデルを🤗 Transformersを使用してローカルおよびKubernetesクラスター上に展開する方法を紹介しました。この投稿では、同じモデルをVertex AIプラットフォームに展開する方法を示します。Kubernetesベースの展開と同じスケーラビリティレベルを実現できますが、コードは大幅に簡略化されます。 この投稿は、上記にリンクされた前の2つの投稿を基に構築されています。まだチェックしていない場合は、それらを確認することをお勧めします。 この投稿の冒頭にリンクされたColab Notebookには、完全に作成された例があります。 Google Cloudによると: Vertex AIは、さまざまなモデルタイプと異なるレベルのMLの専門知識をサポートするツールを提供します。 モデルの展開に関しては、Vertex AIは次の重要な機能を統一されたAPIデザインで提供しています: 認証 トラフィックに基づく自動スケーリング モデルのバージョニング 異なるバージョンのモデル間のトラフィックの分割 レート制限 モデルの監視とログ記録 オンラインおよびバッチ予測のサポート TensorFlowモデルに対しては、この投稿で紹介されるいくつかの既製のユーティリティが提供されます。ただし、PyTorchやscikit-learnなどの他のフレームワークにも同様のサポートがあります。 Vertex AIを使用するには、請求が有効なGoogle Cloud…

Hugging Face TransformersとHabana Gaudiを使用して、BERTを事前に学習する
このチュートリアルでは、Habana GaudiベースのDL1インスタンスを使用してBERT-baseをゼロから事前トレーニングする方法を学びます。Gaudiのコストパフォーマンスの利点を活用するためにAWSで使用します。Hugging Face Transformers、Optimum Habana、およびDatasetsライブラリを使用して、マスクされた言語モデリングを使用してBERT-baseモデルを事前トレーニングします。これは、最初のBERT事前トレーニングタスクの一つです。始める前に、ディープラーニング環境をセットアップする必要があります。 コードを表示する 以下のことを学びます: データセットの準備 トークナイザのトレーニング データセットの前処理 Habana Gaudi上でBERTを事前トレーニングする 注意:ステップ1から3は、CPUを多く使用するタスクのため、異なるインスタンスサイズで実行することができます/すべきです。 要件 始める前に、以下の要件を満たしていることを確認してください DL1インスタンスタイプのクオータを持つAWSアカウント AWS CLIがインストールされていること AWS IAMユーザーがCLIで構成され、ec2インスタンスの作成と管理の権限を持っていること 役立つリソース Hugging Face TransformersとHabana…

🧨ディフューザーを使用した安定した拡散
…🧨 ディフューザーを使用して Stable Diffusionは、CompVis、Stability AI、およびLAIONの研究者とエンジニアによって作成されたテキストから画像への潜在的な拡散モデルです。これは、LAION-5Bデータベースのサブセットから512×512の画像でトレーニングされています。LAION-5Bは現在存在する最大の、自由にアクセス可能な多様性のあるデータセットです。 この記事では、Stable Diffusionと🧨 ディフューザーのライブラリを使用する方法、モデルの動作の説明、およびディフューザーを使用して画像生成パイプラインをカスタマイズする方法について説明します。 注意:ディフュージョンモデルの動作原理を基本的に理解することを強くお勧めします。ディフュージョンモデルが完全に新しいものである場合、次のブログ記事のいずれかを読むことをお勧めします: 注釈付きディフュージョンモデル 🧨 ディフューザーの始め方 それでは、いくつかの画像を生成しましょう 🎨。 Stable Diffusionの実行 ライセンス モデルを使用する前に、モデルのライセンスを受け入れて重みをダウンロードして使用する必要があります。 注意:ライセンスはもはやUIを介して明示的に受け入れる必要はありません。 このライセンスは、このような強力な機械学習システムの潜在的な有害な影響を緩和するために設計されています。ユーザーには、ライセンスを完全かつ注意深く読むことをお願いします。以下に要約を提供します: モデルを意図的に違法または有害な出力やコンテンツの生成や共有に使用することはできません。 生成した出力に対する権利は主張しません。使用は自由であり、使用に関してはライセンスで設定された規定に違反してはならず、その使用については責任があります。 重みを再配布し、モデルを商業的および/またはサービスとして使用することができます。ただし、その場合、ライセンスで設定された使用制限とCreativeML OpenRAIL-Mのコピーをすべてのユーザーに提供する必要があります。…

Hugging Face Spacesでタンパク質を可視化する
この投稿では、Hugging Face Spacesでタンパク質を可視化する方法について見ていきます。 動機 🤗 タンパク質は、医薬品から洗剤まで私たちの生活に大きな影響を与えています。タンパク質の機械学習は、新しい興味深いタンパク質の設計を支援するための急速に成長している分野です。タンパク質は、主にアミノ酸と呼ばれる一連の構成要素を3D空間に配列して、タンパク質の機能を与える複雑な3Dオブジェクトです。機械学習の目的で、タンパク質は、例えば座標、グラフ、またはタンパク質言語モデルで使用するための1次元の文字列として表現することができます。 タンパク質の有名な機械学習モデルの一つにAlphaFold2があります。AlphaFold2は、類似のタンパク質の多重配列と構造モジュールを使用してタンパク質配列の構造を予測します。 AlphaFold2が登場して以来、OmegaFold、OpenFoldなど、さまざまなモデルが登場しました(詳細はこのリストやこのリストを参照)。 見ることは信じること タンパク質の構造は、タンパク質の機能を理解する上で重要な要素です。現在、mol*や3dmol.jsなどのブラウザで直接タンパク質を可視化するためのツールがいくつか利用可能です。この投稿では、3Dmol.jsとHTMLブロックを使用して、Hugging Face Spaceに構造可視化を統合する方法を学びます。 必要条件 すでにgradio Pythonパッケージがインストールされていること、およびJavascript / JQueryの基本的な知識を持っていることを確認してください。 コードの概要 3Dmol.jsのセットアップ方法に入る前に、インターフェースの最小機能デモを作成する方法を見てみましょう。 以下のコードは、4桁のPDBコードまたはPDBファイルを受け入れる簡単なデモアプリを作成します。アプリは、RCSB Protein Databankからpdbファイルを取得して表示するか、アップロードされたファイルを使用して表示します。 import gradio…

OpenRAIL オープンで責任あるAIライセンスフレームワークに向けて
オープン&レスポンシブAIライセンス(「OpenRAIL」)は、後者の責任ある使用を求めながら、AIアーティファクトのオープンアクセス、使用、配布を可能にするAI特有のライセンスです。 OpenRAILライセンスは、現在のオープンソフトウェアライセンスがコードに対して、およびクリエイティブコモンズが一般コンテンツに対して行っていることと同様に、オープンで責任あるMLに対する広範なコミュニティライセンスツールです。 機械学習と他のAI関連分野の進歩は、情報通信技術(ICT)セクターにおけるオープンソース文化の普及の一部によって、過去数年間で著しく発展してきました。これは、MLの研究開発ダイナミクスに浸透しています。イノベーションのための核としてのオープンさの利点にもかかわらず、(まだそうではない)最近の機械学習モデルの開発と使用に関する倫理的および社会経済的懸念に関連する出来事は明確なメッセージを広めています。オープンさだけでは十分ではありません。しかし、問題は、企業のプライベートAI開発プロセスの不透明性の下で問題が持続しているため、閉じたシステムも答えではありません。 オープンソースライセンスはすべてに適合しません MLモデルのアクセス、開発、使用は、オープンソースライセンスのスキームに非常に影響を受けています。たとえば、ML開発者は、公式のオープンソースライセンスやその他のオープンソースソフトウェアまたはコンテンツライセンス(Creative Commonsなど)を添付して重みを利用可能にすると、非公式に「モデルのオープンソース化」と呼ぶことがあります。これは次の疑問を投げかけます:なぜ彼らはそれをやるのですか?MLアーティファクトとソースコードは本当に似ているのでしょうか?技術的な観点から十分に共有できるほど共有していますか(たとえば、Apache 2.0など)。 ほとんどの現在のモデル開発者はそう考えているようですが、公開されたモデルの大部分はオープンソースライセンスを持っています(例:Apache 2.0)。たとえば、Hugging Face Model HubやMuñoz Ferrandis & Duque Lizarralde(2022)を参照してください。 しかし、経験的な証拠は、オープンソース化と/またはフリーソフトウェアダイナミクスへの厳格なアプローチと、MLアーティファクトのリリースにおけるFreedom 0への公理的な信念が、MLモデルの使用における社会倫理的な歪みを生み出していることを示しています(Widder et al. (2022)参照)。より簡単に言えば、オープンソースライセンスは、モデルがソフトウェア/ソースコードとは異なるアーティファクトであることを考慮に入れず、MLモデルの責任ある使用を可能にするには適応されていないため、適応されていません。 モデルのドキュメンテーション、透明性、倫理的な使用に専念した特定の特別なプラクティスが既に存在し、日々改善されています(例:モデルカード、評価ベンチマーク)。なぜ、MLモデルに関するオープンライセンスのプラクティスも、MLモデルから生じる特定の能力と課題に適応されていないのでしょうか? 同様の懸念は、商業および政府のMLライセンスプラクティスでも浮上しています。Bowe & Martin(2022)の言葉によれば、「Anduril…

DeepSpeedとAccelerateを使用した非常に高速なBLOOM推論
この記事では、176BパラメータのBLOOMモデルを使用してトークンごとのスループットを非常に高速に取得する方法を紹介します。 モデルは352GBのbf16(bfloat16)ウェイト(176*2)を必要とするため、最も効率的なセットアップは8x80GBのA100 GPUです。また、2x8x40GBのA100または2x8x48GBのA6000も使用できます。これらのGPUを使用する主な理由は、この執筆時点ではこれらのGPUが最大のGPUメモリを提供しているためですが、他のGPUも使用できます。たとえば、24x32GBのV100を使用することもできます。 単一のノードを使用すると、通常、最速のスループットが得られます。なぜなら、ほとんどの場合、ノード内のGPUリンクハードウェアの方がノード間のものよりも速いためですが、常にそうとは限りません。 もしハードウェアがそれほど多くない場合でも、CPUやNVMeのオフロードを使用してBLOOM推論を実行することは可能ですが、もちろん、生成時間は遅くなります。 また、GPUメモリの半分の容量を必要とする8ビット量子化ソリューションについても説明します。これにはBitsAndBytesとDeepspeed-Inferenceライブラリが必要です。 ベンチマーク さらなる遅延なしでいくつかの数値を示しましょう。 一貫性を保つために、この記事のベンチマークはすべて同じ8x80GBのA100ノードで実行され、512GBのCPUメモリを持つJean Zay HPCで行われました。JeanZay HPCのユーザーは、約3GB/sの読み取り速度(GPFS)で非常に高速なIOを利用しています。これはチェックポイントの読み込み時間に重要です。遅いディスクは読み込み時間が遅くなります。特に複数のプロセスでIOを同時に行っている場合はさらに重要です。 すべてのベンチマークは、100トークンの出力を貪欲に生成しています: Generate args {'max_length': 100, 'do_sample': False} 入力プロンプトはわずかなトークンで構成されています。以前のトークンのキャッシュもオンになっています。常にそれらを再計算すると非常に遅くなるためです。 まず、生成の準備が完了するまでにかかった時間(つまり、モデルの読み込みと準備にかかった時間)を見てみましょう: Deepspeed-Inferenceには、事前にシャードされたウェイトリポジトリが付属しており、読み込みに約1分かかります。Accelerateの読み込み時間も優れており、わずか2分です。他のソリューションはここでははるかに遅いです。 読み込み時間は重要であるかどうかは、一度読み込んだら追加の読み込みオーバーヘッドなしに繰り返しトークンを生成できるため、場合によります。 次に、トークン生成の最も重要なベンチマークです。ここでのスループット指標は単純であり、100個の新しいトークンを生成するのにかかった時間を100で割り、バッチサイズで割ったものです。…

倫理と社会のニュースレター#1
Hello, world! オープンソース企業として創業したHugging Faceは、技術におけるいくつかの重要な倫理的価値、すなわち協力、責任、透明性に基づいて設立されました。オープンな環境でコードを記述することは、自分のコードとその選択肢が世界に公開され、他の人が批判や追加を行うために利用可能であることを意味します。Hugging Face Hubをホストとしてモデルやデータを提供するようになると、リサーチコミュニティは再現性を直接統合し、それを会社の基本的な価値としました。そして、Hugging Faceに存在するデータセットやモデルの数が増えるにつれ、Hugging Faceのメンバーは、リサーチコミュニティによって定義された新たな価値に対応するために、ドキュメントの要件や無料の指導コースを導入しました。これにより、技術の進歩につながる数学、コード、プロセス、人々の理解を含む、監査可能性の価値が追加されました。 AIにおける倫理をどのように実施するかは、オープンな研究領域です。応用倫理と人工知能に関する学問や理論は数十年前から存在していましたが、AI開発における倫理の実践とテストされた手法は、過去10年間にわずかに現れ始めたに過ぎません。これは、AIシステムの構築ブロックである機械学習モデルが、それらの進歩を測定するために使用されてきた基準を超えたため、機械学習システムが日常生活に影響を与える実用的なアプリケーションの範囲で広範に採用されたためです。倫理に基づくAIの進歩に興味を持つ私たちのうちの何人かは、倫理的な原則に基づいて設立された機械学習企業に参加することは、成長が始まり、世界中の人々が倫理的なAIの問題に取り組み始めるときに、将来のAIがどのようになるかを根本的に形作る機会です。これは、倫理を念頭に置いて最初から設立されたテクノロジー企業がどのように見えるのかという、新しい形の現代のAIの実験です。機械学習に倫理の視点を当てるとは、良い機械学習を民主化するとはどういうことでしょうか。 このため、私たちは新しいHugging Face Ethics and Societyニュースレターで最近の考え方と取り組みを共有しています。このニュースレターは、春分点と夏至点に毎シーズン発行されます。これは、私たちHugging Faceの「倫理と社会の専門家」というオープンなグループが一緒になって機械学習の広範な社会的文脈やHugging Faceの役割に取り組むために作成されました。私たちは、会社全体が価値に基づいた意思決定を行うためには、専門チームではなく、共有の責任とコミットメントが必要であると考えています。私たちの仕事の倫理的なリスクを認識し、学ぶために、すべての関係者が責任を共有することが重要です。 私たちは、現在のところ「良い」機械学習の意味について継続的に研究しており、それを定義するための基準を提供しようとしています。これは進行中のプロセスであり、現在の日常生活に影響を与える機械学習コミュニティの異なる価値観と調和する点に到達するために、現在の日常生活で可能な限り何ができるかを見据えています。私たちは、Hugging Faceの創業の原則に基づいてこのアプローチを展開しています。 私たちはオープンソースコミュニティと協力することを目指しています。これには、ドキュメンテーションと評価のための現代化されたツール、コミュニティディスカッション、Discord、さらには異なる価値観に基づいて自分の作業を共有するための貢献者への個別サポートが含まれます。 私たちは、自分たちの考え方やプロセスを透明にすることを目指しています。プロジェクトの開始時に特定のプロジェクト価値についての執筆を共有し、AIポリシーについての考え方も共有しています。また、この作業に対するコミュニティからのフィードバックも学ぶためのリソースとして得ています。 私たちは、現在と将来の影響に対する責任を負いながら、これらのツールとアーティファクトの作成を基盤としています。この優先順位付けにより、機械学習システムをより監査可能で理解可能にするプロジェクト設計が実現しました。これには、ML以外の専門知識を持つ人々にも適した教育プロジェクトやコーディング不要のMLデータ分析ツールなどが含まれます。 これらの基本から出発し、私たちは、プロジェクトごとの特定の文脈と予測される影響に重点を置いた価値観の実施方法を取っています。したがって、ここではグローバルな価値観や原則の一覧を提供することはありません。その代わり、このニュースレターなど、プロジェクトごとの考え方を引き続き共有し、理解が進むにつれてさらに共有する予定です。異なる価値観と影響を受ける人々を特定するために、コミュニティのディスカッションが重要であると考えているため、Hugging Face Hubにオンラインで接続できる人は誰でも直接モデル、データ、およびスペースに関するフィードバックを提供できる機会を最近提供しました。オープンなディスカッションのツールと並行して、包括的なコミュニティスペースのための行動規範とコンテンツガイドラインを作成しました。セキュアなML開発のためのプライベートHub、モデルを厳密に評価するための評価ライブラリ、スキューとバイアスを分析するためのデータ解析のためのコード、モデルのトレーニング時の炭素排出量を追跡するためのツールを開発しています。また、倫理的および法的な問題について報告するためにモデルとスペースのリポジトリを「フラグ」とすることも可能にしました。…

AutoTrainによる画像分類
機械学習の世界で起こっているすごいことをすべて聞いたことがありますね。そして、参加したいと思っています。ただ1つ問題があります – コーディングの方法がわかりません! 😱 または、MLをサイドプロジェクトに追加したい経験豊富なソフトウェアエンジニアでありながら、新しいテックスタックを習得する時間がありません!多くの人々にとって、機械学習の技術的な壁は乗り越えられないと感じるものです。そこで、Hugging FaceはAutoTrainを作成しました。そして、私たちが追加した最新の機能により、「ノーコード」の機械学習がこれまで以上に優れたものになりました。何よりも、最初のプロジェクトを✨無料で✨作成できます! Hugging Face AutoTrainは、設定が不要なモデルをトレーニングすることができます。タスクを選択します(翻訳ですか?質問応答はいかがですか?)、データをアップロードし、Hugging Faceが残りの作業を行います! AutoTrainによってさまざまなモデルの実験を行わせることで、エンジニアによって手動でトレーニングされたモデルよりも性能が向上する可能性さえあります 🤯 サポートするタスクの数を増やしていますが、嬉しいお知らせがあります。AutoTrainはコンピュータビジョンにも使用できるようになりました!最新のタスクである画像分類を追加しましたが、これからもさらに追加予定です。しかし、これがあなたにとってどういう意味を持つのでしょうか? 画像分類モデルは画像をカテゴリに分類する方法を学びますので、これらのモデルの1つをトレーニングして任意の画像にラベルを付けることができます。署名を認識できるモデルが欲しいですか?鳥の種類を区別できるモデルが欲しいですか?植物の病気を特定できるモデルが欲しいですか?適切なデータセットを見つけることができる限り、画像分類モデルが対応してくれます。 自分自身の画像分類器をトレーニングする方法は? Hugging Faceのアカウントをまだ作成していない場合は、今がチャンスです!その後、AutoTrainのホームページに移動し、「新しいプロジェクトを作成」をクリックして始めましょう。プロジェクトに関する基本情報を入力するように求められます。以下のスクリーンショットでは、私はbutterflies-classificationという名前のプロジェクトを作成し、”Image Classification”タスクを選択しました。また、自分のプロジェクトで最適なモデルアーキテクチャを見つけるために、”Automatic”モデルオプションも選択しました。 AutoTrainがプロジェクトを作成したら、あとはデータを接続するだけです。データがローカルにある場合は、フォルダをウィンドウにドラッグアンドドロップすることができます。また、Hugging Face Hubで提供されている画像分類のデータセットを使用することもできます。この例では、NimaBoscarino/butterfliesデータセットを使用することにしました。利用可能な場合は、別々のトレーニングデータセットと検証データセットを選択することもできますし、データの分割をAutoTrainに依頼することもできます。 データが追加されたら、AutoModelが試すモデル候補の数を選択し、予想されるトレーニングコスト(5つの候補モデルと500枚未満の画像でのトレーニングは無料です 🤩)を確認して、トレーニングを開始します。 上のスクリーンショットでは、私のプロジェクトが5つの異なるモデルを開始し、それぞれが異なる精度のスコアを達成しました。そのうちの1つはあまりうまく機能していなかったため、AutoTrainはリソースを無駄にしないように停止しました。最も優れたモデルは84%の精度を達成しましたが、私の努力はほぼゼロでした…

データセットとモデルにおけるDOI(デジタルオブジェクト識別子)の紹介
私たちの使命は、良い機械学習を民主化することです。それには、MLモデルやデータセットの再現性を高め、より良くドキュメント化し、使いやすく共有できるようなベストプラクティスが含まれます。 この課題を解決するために、喜んでお知らせしますが、ハブからモデルまたはデータセットのDOIを直接生成できるようになりました! DOIはリポジトリの設定から直接生成することができ、誰でもモデルまたはデータセットのページで「このモデル/データセットを引用する」とクリックすることであなたの作品を引用することができます🔥。 DOIとは何か、なぜ重要なのか? DOI(Digital Object Identifier)は、記事から図表、データセットやモデルなど、デジタルオブジェクトを一意に識別する文字列です。DOIはオブジェクトのメタデータに関連しており、オブジェクトのURL、バージョン、作成日、説明などが含まれます。DOIは研究や学術コミュニティでデジタルリソースを参照するための一般的に受け入れられた手段であり、書籍のISBNに相当します。 DOIを持つことで、モデルやデータセットに関する情報を見つけやすくし、世界と共有するための永続的なリンクを提供します。そのため、DOIを持つデータセットやモデルは永続的に存在し、サポートへの要求を行わない限り削除されることはありません。 Hugging FaceでDOIが割り当てられる方法は? 私たちはDataCiteと提携しており、登録されたハブのユーザーは自分のモデルやデータセットのDOIをリクエストすることができます。必要なメタデータを入力すると、新しい輝かしいDOIがもらえます🌟! モデルやデータセットの新しいバージョンがある場合、DOIは簡単に更新でき、以前のDOIのバージョンは古くなります。これにより、オブジェクトの特定のバージョンを参照するのが簡単になります。 私たちがさらに改善できるアイデアはありますか?このような多くの機能は、コミュニティのフィードバックから直接提供されています。ご意見やご要望があれば、お知らせください。または、huggingface/hub-docsの問題を開いてください🤗 このパートナーシップにはDataCiteチームに感謝します!また、このhub-docsのGitHubの問題に関する議論を開始し、育ててくれたAlix Leroyさん、Bram Vanroyさん、Daniel van Strienさん、Yoshitomo Matsubaraさんにも感謝します。

🧨 JAX / Flax での安定した拡散!
🤗 Hugging Face Diffusersはバージョン0.5.1からFlaxをサポートしています!これにより、Colab、Kaggle、またはGoogle Cloud PlatformなどのGoogle TPU上での超高速な推論が可能になります。 この投稿では、JAX / Flaxを使用して推論を実行する方法を示します。Stable Diffusionの動作詳細やGPUでの実行方法について詳細を知りたい場合は、このColabノートブックを参照してください。 一緒に進める場合は、上のボタンをクリックしてこの投稿をColabノートブックとして開きます。 まず、TPUバックエンドを使用していることを確認してください。このノートブックをColabで実行している場合は、上のメニューでランタイムを選択し、「ランタイムのタイプを変更」オプションを選択し、ハードウェアアクセラレータの設定でTPUを選択します。 JAXはTPUに限定されているわけではありませんが、TPUサーバーごとに8つのTPUアクセラレータが並列に動作するため、そのハードウェア上で輝きます。 セットアップ import jax num_devices = jax.device_count() device_type = jax.devices()[0].device_kind print(f"Found…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.