Learn more about Search Results T5 - Page 34

- You may be interested
- 最適な会議スケジューリング
- 「アリババが新しいAIツールを導入し、テ...
- 2023 AIインデックスレポート:将来に期待...
- AIにおいて大胆であることは、最初から責...
- 「ヒドラで実験を追跡し続けましょう」
- 「目と耳を持つChatGPT:BuboGPTは、マル...
- UCLAとCMUの研究者が、優れた中程度範囲の...
- 百度のAI研究者がVideoGenを紹介:高フレ...
- ヴィンセント・ファン・ゴッホの復活
- 「AIの擬人化:人間が共感を求める場所を...
- ChatGPTの大きなサプライズ:OpenAIがAIマ...
- 機械学習におけるバイアスについて話しま...
- サイバーエキスパートたちは、2024年の米...
- 「グラフ理論における重要な概念、グラフ...
- 『2つの方が1つより優れている:AIと自動...

Amazon SageMakerのHugging Face LLM推論コンテナをご紹介します
これは、オープンソースのLLM(Large Language Model)であるBLOOMをAmazon SageMakerに展開し、新しいHugging Face LLM Inference Containerを使用して推論を行う方法の例です。Open Assistantデータセットで訓練されたオープンソースのチャットLLMである12B Pythia Open Assistant Modelを展開します。 この例では以下の内容をカバーしています: 開発環境のセットアップ 新しいHugging Face LLM DLCの取得 Open Assistant 12BのAmazon SageMakerへの展開 モデルを使用して推論およびチャットを行う…

Hugging FaceとAMDは、CPUおよびGPUプラットフォーム向けの最先端モデルの高速化に関するパートナーシップを結んでいます
言語モデル、大規模な言語モデル、または基盤モデル、トランスフォーマーは、事前学習、微調整、および推論において大量の計算を必要とします。Hugging Faceは、開発者や組織が最大のパフォーマンスを得るために、ハードウェア企業と協力して、各チップのアクセラレーション機能を活用してきました。 本日、私たちはAMDが正式に私たちのハードウェアパートナープログラムに参加したことをお知らせいたします。私たちのCEOであるClement Delangueが、サンフランシスコで行われたAMDのデータセンターおよびAIテクノロジープレミアで基調講演を行い、このエキサイティングな新しい協力関係を発表しました。 AMDとHugging Faceは、AMDのCPUおよびGPU上で最先端のトランスフォーマーパフォーマンスを提供するために協力しています。このパートナーシップは、Hugging Faceコミュニティ全体にとって非常に良いニュースであり、近々、最新のAMDプラットフォームをトレーニングおよび推論に活用することができるようになります。 長年にわたり、ディープラーニングハードウェアの選択肢は限られており、価格と供給は懸念事項となっています。この新しいパートナーシップは、競争に対抗するだけでなく、市場の動向を緩和するのに役立ちます。さらに、新しいコストパフォーマンスの基準を設定することも期待されます。 サポートされるハードウェアプラットフォーム GPU側では、AMDとHugging Faceはまず、エンタープライズグレードのInstinct MI2xxおよびMI3xxファミリー、次に、カスタマーグレードのRadeon Navi3xファミリーで協力します。AMDの最近のテストでは、MI250が直接競合他社よりもBERT-Largeを1.2倍、GPT2-Largeを1.4倍高速にトレーニングすることを報告しています。 CPU側では、両社はクライアントRyzenおよびサーバーEPYC CPUの推論の最適化に取り組みます。いくつかの以前の投稿で議論したように、CPUはトランスフォーマーの推論において優れたオプションになり得ます。特に、量子化などのモデル圧縮技術と組み合わせた場合です。 最後に、この協力関係には、低い電力要件で驚異的なパフォーマンスを発揮するAlveo V70 AIアクセラレータも含まれます。 サポートされるモデルアーキテクチャとフレームワーク 私たちは、自然言語処理、コンピュータビジョン、音声などの最先端のトランスフォーマーアーキテクチャ(BERT、DistilBERT、ROBERTA、Vision Transformer、CLIP、Wav2Vec2など)をサポートする予定です。もちろん、生成型AIモデル(GPT2、GPT-NeoX、T5、OPT、LLaMAなど)、私たち自身のBLOOMおよびStarCoderモデルも利用可能です。最後に、ResNetやResNextのようなより伝統的なコンピュータビジョンモデル、そして深層学習の推薦モデルにも初めて対応します。 これらのモデルをPyTorch、TensorFlow、およびONNX Runtime向けに上記のプラットフォームでテストおよび検証するために最善を尽くします。すべてのモデルが、すべてのフレームワークまたはすべてのハードウェアプラットフォームでトレーニングおよび推論に利用可能であるわけではないことを覚えておいてください。 今後の展望…
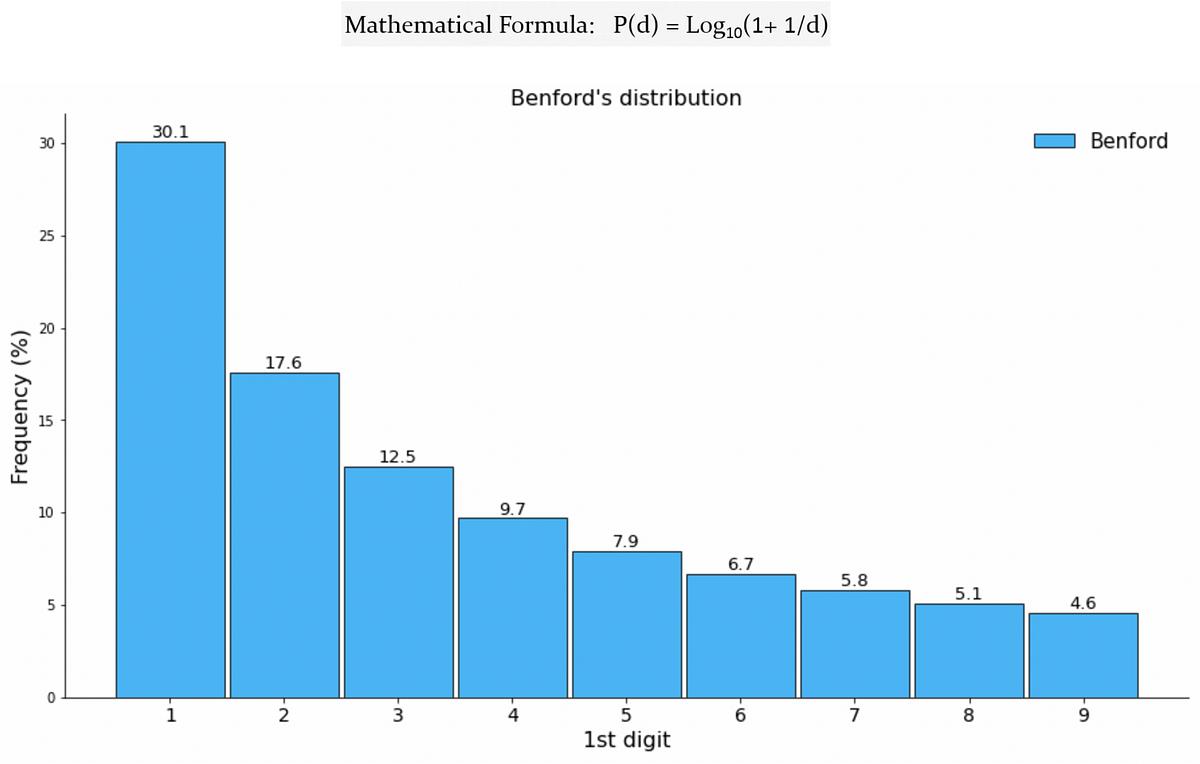
Benfordの法則が機械学習と出会って、偽のTwitterフォロワーを検出する
ソーシャルメディアの広大なデジタル領域において、ユーザーの真正性は最も重要な懸念事項ですTwitterなどのプラットフォームが成長するにつれ、フェイクアカウントの増加も増えていますこれらのアカウントは本物のアカウントを模倣します

MuZero ルールなしでGo、チェス、将棋、アタリをマスターする
2016年、我々はAlphaGoという初めて人間を囲碁で打ち負かすことのできる人工知能(AI)プログラムを紹介しました2年後、その後継者であるAlphaZeroは、ゼロから囲碁、チェス、将棋をマスターするために学習しましたそして今、学術誌Natureに掲載された論文で、我々はMuZeroを紹介していますこれは汎用アルゴリズムの追求において重要な進展ですMuZeroは、未知の環境で勝利戦略を計画する能力により、ルールを教えられることなく囲碁、チェス、将棋、アタリをマスターします
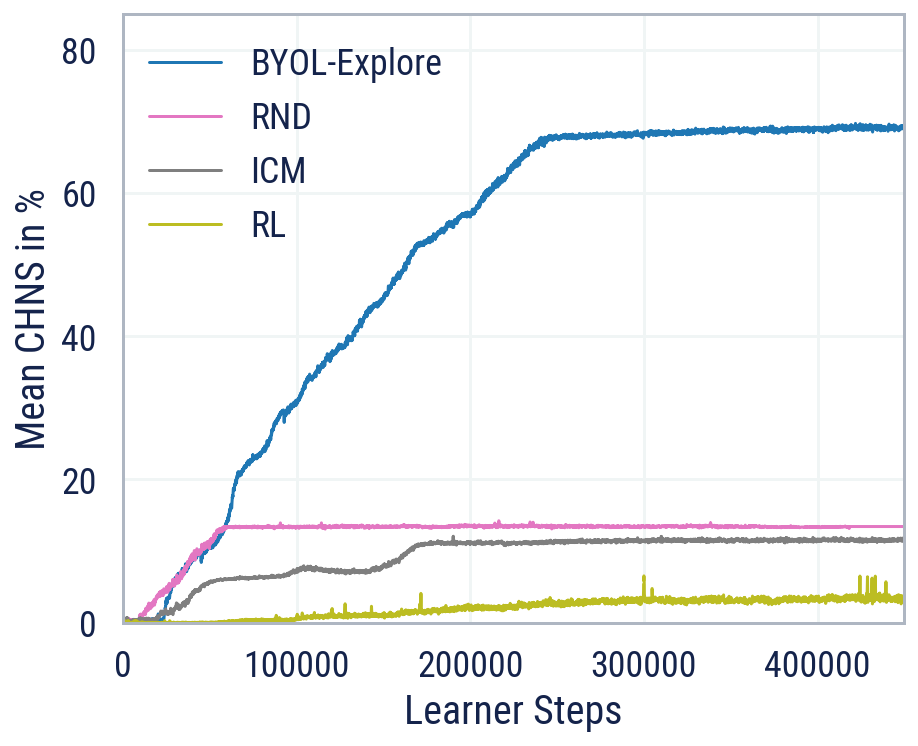
BYOL-Explore ブートストラップ予測による探索
BYOL-Exploreを紹介しますこれは、視覚的に複雑な環境での好奇心に基づいた探索のための概念的にシンプルでありながら一般的なアプローチですBYOL-Exploreは、追加の補助的な目的ではなく、潜在空間での単一の予測損失を最適化することによって、世界表現、世界の動態、および探索方針をすべて一緒に学習します我々は、BYOL-Exploreが視覚的に豊かな3D環境を持つ難解な部分観測可能な連続アクションの困難な探索ベンチマークであるDM-HARD-8で効果的であることを示します

私のDeepMindインターンからメンターへの道のり
元インターンであり、現在はインターンマネージャーとして活躍するリチャード・エベレット氏は、DeepMindへの道のりを語り、DeepMindを志す人々に対してのアドバイスやヒントを共有しています2023年のインターンシップ応募は9月16日に開始されますので、詳細についてはhttps//dpmd.ai/internshipsatdeepmindをご覧ください

ロボキャット:自己改善型ロボティックエージェント
ロボットは私たちの日常生活の一部として急速になっていますが、彼らはしばしば特定のタスクをうまく実行するためにのみプログラムされています最近のAIの進歩を活用することで、より多くの方法で助けることができるロボットが可能になるかもしれませんが、一般的な用途のロボットの構築には、現実世界のトレーニングデータを収集するために必要な時間の制約があり、進展が遅れています私たちの最新の論文では、自己改善型のAIエージェントであるロボキャットを紹介していますロボキャットは、異なるアームでさまざまなタスクを実行する方法を学び、その後、新しいトレーニングデータを自己生成して技術を向上させるのです
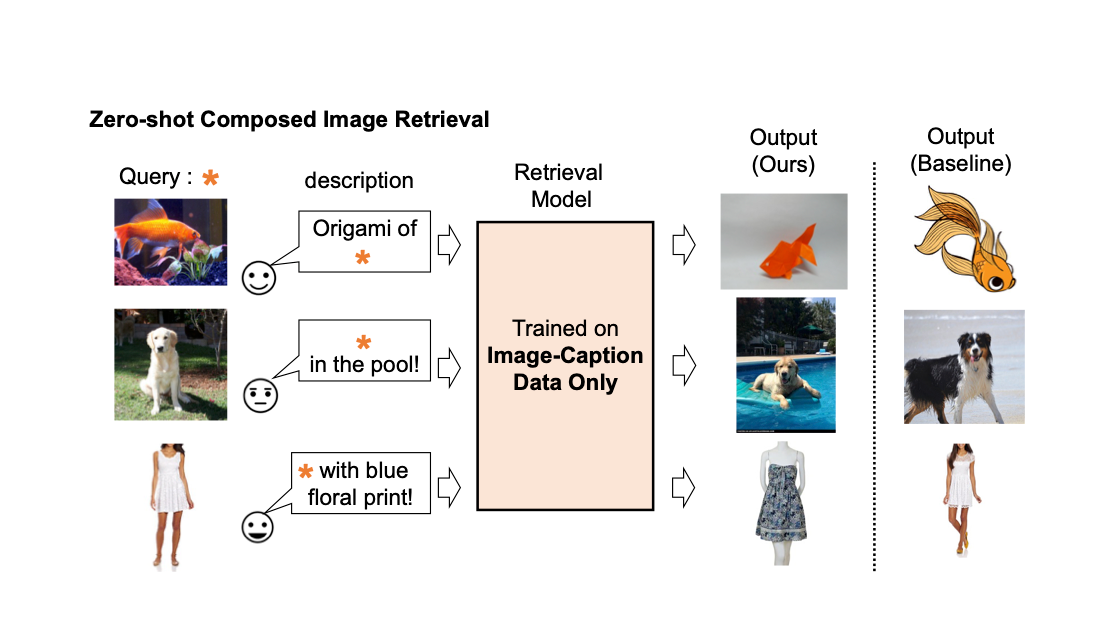
Pic2Word:ゼロショット構成画像検索のための写真から単語へのマッピング
Google Researchの学生研究者であるKuniaki SaitoとGoogle Researchの研究科学者であるKihyuk Sohnが投稿しました。 画像の検索エンジンでは、画像またはテキストをクエリとして使用して目的の画像を取得することが重要です。しかし、テキストに基づいた検索には限界があります。言葉で正確に目的の画像を説明することは難しいからです。たとえば、ファッションアイテムを検索する場合、ユーザーはウェブサイトで見つけたものとは異なる、ロゴの色やロゴ自体などの特定の属性を持つアイテムを求めるかもしれません。しかし、既存の検索エンジンでそのアイテムを検索することは容易ではありません。なぜなら、テキストでファッションアイテムを正確に説明することは難しいからです。この事実に対処するために、組み合わせ画像検索(CIR)は、画像とテキストの両方を組み合わせたクエリに基づいて画像を取得します。そのため、CIRは画像とテキストを組み合わせることで、目的の画像を正確に取得することができます。 しかし、CIRの方法には大量のラベル付きデータが必要です。つまり、1)クエリ画像、2)説明、および3)目標画像の3つ組を必要とします。このようなラベル付きデータを収集することはコストがかかり、このデータで訓練されたモデルはしばしば特定のユースケースに適応されており、異なるデータセットには一般化できる能力が制限されています。 これらの課題に対処するために、「Pic2Word:ゼロショット組み合わせ画像検索のための画像から単語へのマッピング」というタイトルの論文で、私たちはゼロショットCIR(ZS-CIR)というタスクを提案しています。ZS-CIRでは、ラベル付きの3つ組データを必要とせずに、オブジェクトの組み合わせ、属性の編集、またはドメインの変換など、さまざまなCIRのタスクを実行する単一のCIRモデルを構築することを目指しています。代わりに、大規模な画像キャプションのペアとラベルのない画像を使用して検索モデルを訓練することを提案しています。これらのデータは、大規模な教師ありCIRデータセットよりも容易に収集できます。再現性を促進し、この分野をさらに進展させるために、私たちはコードも公開しています。 既存の組み合わせ画像検索モデルの説明。 私たちは、画像キャプションのデータのみを使用して組み合わせ画像検索モデルを訓練します。私たちのモデルは、クエリ画像とテキストの組み合わせに合わせた画像を取得します。 手法の概要 私たちは、コントラスト言語-画像事前学習モデル(CLIP)の言語エンコーダの言語能力を活用することを提案しています。CLIPは、さまざまなテキストの概念と属性に対して意味のある言語埋め込みを生成することに優れています。そのため、CLIP内の軽量なマッピングサブモジュールを使用して、画像の埋め込み空間からテキスト入力空間の単語トークンにマッピングすることを目指します。全体のネットワークは、ビジョン-言語コントラスト損失を最適化して、画像とテキストの埋め込み空間が可能な限り近接するようにします。そして、クエリ画像を単語のように扱うことができます。これにより、言語エンコーダによるクエリ画像の特徴とテキストの説明の柔軟でシームレスな組み合わせが可能になります。私たちはこの手法をPic2Wordと呼び、その訓練プロセスの概要を以下の図で提供します。マップされたトークンsは、単語トークン形式で入力画像を表すようにしたいと考えています。その後、マッピングネットワークを訓練して、言語埋め込みp内で画像埋め込みを再構築します。具体的には、CLIPで提案されたコントラスト損失を最適化し、ビジュアル埋め込みvとテキスト埋め込みpの間のコントラスト損失を計算します。 未ラベルの画像のみを使用してマッピングネットワーク(fM)のトレーニングを行います。視覚とテキストのエンコーダーは固定されたまま、マッピングネットワークのみを最適化します。 トレーニングされたマッピングネットワークを考慮すると、以下の図に示すように、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成することができます。 トレーニングされたマッピングネットワークを使用して、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成します。 評価 さまざまな実験を行って、Pic2WordのCIRタスクでの性能を評価します。 ドメイン変換 まず、提案手法の合成能力をドメイン変換で評価します。画像と変換先の画像ドメイン(例:彫刻、折り紙、漫画、おもちゃ)を与えられた場合、システムの出力は同じ内容の画像を新しい望ましい画像ドメインまたはスタイルで出力する必要があります。以下の図で示されるように、画像とテキストのカテゴリ情報やドメイン説明を柔軟に組み合わせる能力を評価します。ImageNetとImageNet-Rを使用して、実際の画像から4つのドメインへの変換を評価します。 教師付きトレーニングデータを必要としないアプローチとの比較のために、次の3つのアプローチを選びます:(i)画像のみは視覚埋め込みのみで検索を実行します、(ii)テキストのみはテキスト埋め込みのみを使用します、(iii)画像+テキストは視覚とテキストの埋め込みを平均化してクエリを構成します。 (iii)との比較では、言語エンコーダーを使用して画像とテキストを組み合わせる重要性が示されます。また、Fashion-IQまたはCIRRでCIRモデルをトレーニングするCombinerとも比較します。 入力クエリ画像のドメインを、テキストで指定されたドメイン(例:折り紙)に変換することを目指します。 下の図に示されているように、提案された手法はベースラインを大きく上回る結果を示しています。 ドメイン変換のための合成画像検索における結果(リコール@10、つまり最初の10枚の画像で関連するインスタンスの割合)。…

StorybirdはAIの力を借りて、誰でもわずか数秒でビジュアルストーリーを作成することができます
StoryBird.AIはAIの力を活用して、誰でも数秒でビジュアルストーリーを作成できます。彼らのStoriesプラグインは、ChatGPTプラグインストアで最も人気のあるプラグインの一つです。プラグインまたはウェブサイトを使用して、誰でも人工知能の助けを借りて魅力的なストーリーや本を作成できます。このプラットフォームは非常に使いやすく、OpenAIのChatGPTストアで最も求められるプラグインの1つであるStoriesプラグインを使用してすぐに始めることができます。ワクワクしませんか? ストーリーは見事なものであり、Storybird.aiでさまざまな例を探索することができます。以下のようなものがあります。 StoryBird.aiを使用すると、本を書き、編集し、公開し、売上を上げることさえできます。そのシンプルさと効果において、これに匹敵するAIソリューションは他にありません。 Storybirdのチームは、LLMsとGANsを活用してシームレスにする方法を見つけました。 主な特徴: 生成的編集:これにより、生成的な手法を使用してストーリーを編集できます。 速度:プロセスは非常に高速で、数秒で完了します。 個別化とカスタマイズ:プラットフォームでは、各ページの生成されたコンテンツを編集することでストーリーをカスタマイズできます。さらに、編集に基づいて関連する画像やイラストを再生成することもできます。まるで魔法のようであり、ストーリーはあなた自身だけのものになります。 印象的な結果:ストーリーやイラストは本当に印象的です。 Stories ChatGPTプラグイン 追加するのは簡単で、単に「stories」を検索して追加できます。 Storybird.aiは、魅力的なストーリーを作成するための便利なヒントを提供しています: ストーリーの短い説明で始める(20〜1000文字)。 該当する場合、キャラクターの名前を含める。 最適な結果を得るために、キャラクター(例:茶色の髪の女の子)や設定についての詳細を提供する。 ChatGPTでは、次のように簡単にプロセスを開始できます: そして、次のような迅速な結果を受け取ることができます: 以下は、次の初期プロンプトを使用した別の例です: 「12歳の少女であるオリビアという名前の少女についての物語を書いてください。彼女は毎朝早起きしてサッカーの練習をし、いつかプロの選手になることを夢見ています。」 バックパックを「Red」に変更したいのですが、それは簡単にできます。その後、イラストを再生成しました。 誰のためのものですか? StoryBird AIは、親、教育者、著者向けにパーソナライズされた物語を作成するためのツールです。…
トランスフォーマーエンコーダー | 自然言語処理の核心の問題
イントロダクション 非常に簡単な方法でトランスフォーマーエンコーダーを説明します。トランスフォーマーの学習に苦労している人は、このブログ投稿を最後まで読んでください。自然言語処理(NLP)の分野で働く興味がある方は、トランスフォーマーについて少なくとも基本的な知識を持っておくべきです。ほとんどの産業はこの最新のモデルをさまざまな仕事に使用しています。トランスフォーマーは、「Attention Is All You Need」という論文で紹介された最新のNLPモデルであり、従来のRNNやLSTMを上回っています。トランスフォーマーは再帰ではなくセルフアテンションに頼ることで、長期的な依存関係の捉える課題を克服しています。トランスフォーマーはNLPを革新し、BERT、GPT-3、T5などのアーキテクチャの道を開いています。 学習目標 この記事では、以下を学びます: トランスフォーマーがなぜ人気になったのか? NLPの分野でのセルフアテンションメカニズムの役割。 自分自身の入力データからキー、クエリ、バリューの行列を作成する方法。 キー、クエリ、バリューの行列を使用してアテンション行列を計算する方法。 メカニズムにおけるソフトマックス関数の適用の重要性。 この記事は、データサイエンスブログマラソンの一部として公開されました。 トランスフォーマーがRNNやLSTMモデルを上回る要因は何か? RNNやLSTMでは、長期的な依存関係を理解することができず、複雑なデータを扱う際に計算量が増えるという問題に直面しました。「Attention Is All You Need」という論文では、トランスフォーマーという新しいデザインが従来の順次ネットワークの制約を克服するために開発され、NLPアプリケーションの最先端モデルとなりました。 RNNやLSTMでは、入力とトークンは一度に1つずつ与えられ、トランスフォーマーではデータを並列に処理します。 トランスフォーマーモデルは再帰プロセスを完全に排除し、アテンションメカニズムに完全に依存しています。セルフアテンションという独特のアテンションメカニズムを使用します。 トランスフォーマーの構成と動作 多くのNLPタスクでは、トランスフォーマーモデルが現在の最先端モデルです。トランスフォーマーの導入により、NLPの分野での大きな進歩があり、BERT、GPT-3、T5などの先端システムの道を開きました。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.