Learn more about Search Results ISO - Page 34

- You may be interested
- 「生成AIにおけるバイアスの軽減」
- 「Amazon SageMakerを使用して、クラシカ...
- 「3Dプリントされた『生物性材料』が汚染...
- 「Rust言語を使う開発者が増えています」
- クラゲ、猫、ヘビ、宇宙飛行士は何を共有...
- 即座のハッキングとLLMの誤用
- GoogleのSymbol Tuningは、LLM(Language ...
- 「飛躍的進展:UCCの研究者が量子コンピュ...
- 「ハロー効果:AIがサンゴ礁保護に深く関...
- 「ここにあなたが見逃しているものがあり...
- 意思決定木の結果をより良くするための一...
- デジタル変革によって打撃を受ける可能性...
- 第四次産業革命:AIと自動化
- アマゾンのキャッシュレス「手のひらで支...
- 「自分自身の生成モデルを選択して実行す...

スターコーダーでコーディングアシスタントを作成する
ソフトウェア開発者であれば、おそらくGitHub CopilotやChatGPTを使用して、プログラミングのタスクを解決したことがあるでしょう。これらのタスクには、コードを別の言語に変換したり、自然言語のクエリ(「N番目のフィボナッチ数を見つけるPythonプログラムを書いてください」といったもの)から完全な実装を生成したりするものがあります。これらの独自のシステムは、その機能には感動的ですが、一般にはいくつかの欠点があります。これらには、トレーニングに使用される公開データの透明性の欠如や、ドメインやコードベースに適応することのできなさなどがあります。 幸いにも、今はいくつかの高品質なオープンソースの代替品があります!これには、SalesForceのPython用CodeGen Mono 16B、またはReplitの20のプログラミング言語でトレーニングされた3Bパラメータモデルなどがあります。 新しいオープンソースの選択肢としては、BigCodeのStarCoderがあります。80以上のプログラミング言語、GitHubの問題、Gitのコミット、Jupyterノートブックから1兆トークンを収集した16Bパラメータモデルで、これらはすべて許可されたライセンスです。エンタープライズ向けのライセンス、8,192トークンのコンテキスト長、およびマルチクエリアテンションによる高速な大規模バッチ推論を備えたStarCoderは、現在、コードベースのアプリケーションにおいて最も優れたオープンソースの選択肢です。 このブログポストでは、StarCoderをチャット用にファインチューニングして、パーソナライズされたコーディングアシスタントを作成する方法を紹介します! StarChatと呼ばれるこのアシスタントには、次のようないくつかの技術的な詳細があります。 LLMを会話エージェントのように動作させる方法。 OpenAIのChat Markup Language(ChatMLとも呼ばれる)は、人間のユーザーとAIアシスタントの間の会話メッセージに対する構造化された形式を提供します。 🤗 TransformersとDeepSpeed ZeRO-3を使用して、多様な対話のコーパスで大きなモデルをファインチューニングする方法。 最終結果の一部を見るために、以下のデモでStarChatにいくつかのプログラミングの質問をしてみてください! デモで使用されたコード、データセット、およびモデルは、以下のリンクで見つけることができます。 コード: https://github.com/bigcode-project/starcoder データセット: https://huggingface.co/datasets/HuggingFaceH4/oasst1_en モデル: https://huggingface.co/HuggingFaceH4/starchat-alpha 始める準備ができたら、まずはファインチューニングなしで言語モデルを会話エージェントに変換する方法を見てみましょう。…

低リソースASRのためのMMSアダプターモデルの微調整
新しい(06/2023):このブログ記事は、「多言語ASRでのXLS-Rの微調整」に強く触発され、それの改良版として見なされるものです。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、およびAlex Conneauによって2020年9月にリリースされました。Wav2Vec2の強力なパフォーマンスが、ASRの最も人気のある英語データセットであるLibriSpeechで示された直後、Facebook AIはWav2Vec2の2つのマルチリンガルバージョンであるXLSRとXLM-Rを発表しました。これらのモデルは128の言語で音声を認識することができます。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習する能力を指します。 Meta AIの最新リリースであるMassive Multilingual Speech(MMS)(Vineel Pratap、Andros Tjandra、Bowen Shiなどによる)は、マルチリンガル音声表現を新たなレベルに引き上げています。1,100以上の話されている言語が識別、転写、生成され、さまざまな言語識別、音声認識、テキスト読み上げのチェックポイントがリリースされます。 このブログ記事では、MMSのアダプタートレーニングが、わずか10〜20分の微調整後でも驚くほど低い単語エラーレートを達成する方法を示します。 低リソース言語の場合、私たちは「多言語ASRでのXLS-Rの微調整」と同様にモデル全体を微調整するのではなく、MMSのアダプタートレーニングの使用を強くお勧めします。 私たちの実験では、MMSのアダプタートレーニングはメモリ効率がよく、より堅牢であり、低リソース言語に対してはより優れたパフォーマンスを発揮することがわかりました。ただし、VoAGIから高リソース言語への場合は、Adapterレイヤーの代わりにモデル全体のチェックポイントを微調整する方が依然として有利です。 世界の言語多様性の保存 https://www.ethnologue.com/によると、約3000の「生きている」言語のうち、40%、つまり約1200の言語が、話者が減少しているために危機に瀕しています。このトレンドはますますグローバル化する世界で続くでしょう。 MMSは、アリ語やカイビ語など、絶滅危惧種である多くの言語を転写することができます。将来的には、MMSは、残された話者が母国語での記録作成やコミュニケーションをサポートすることで、言語を生き続けるために重要な役割を果たすことができます。 1000以上の異なる語彙に適応するために、MMSはアダプターを使用します。アダプターレイヤーは言語間の知識を活用し、モデルが別の言語を解読する際に役立つ役割を果たします。 MMSの微調整 MMSの非監視チェックポイントは、1400以上の言語で300万〜10億のパラメータを持つ、50万時間以上のオーディオで事前学習されました。 事前学習のためのモデルサイズ(300Mおよび1B)の事前学習のみのチェックポイントは、🤗 Hubで見つけることができます:…

Pythonを使用した画像処理の紹介
当シリーズの第2エピソードの第3部へようこそ!前のパートでは、フーリエ変換とホワイトバランス技術について説明しましたが、今回は...

MPT-30B:モザイクMLは新しいLLMを使用して、NLPの限界を em>GPT-3を凌駕します
MosaicMLのLLMにおける画期的な進歩について、MPTシリーズで学びましょうMPT-30Bおよびその微調整された派生モデル、MPT-30B-InstructとMPT-30B-Chatが他のモデルを凌駕する方法を探索してください
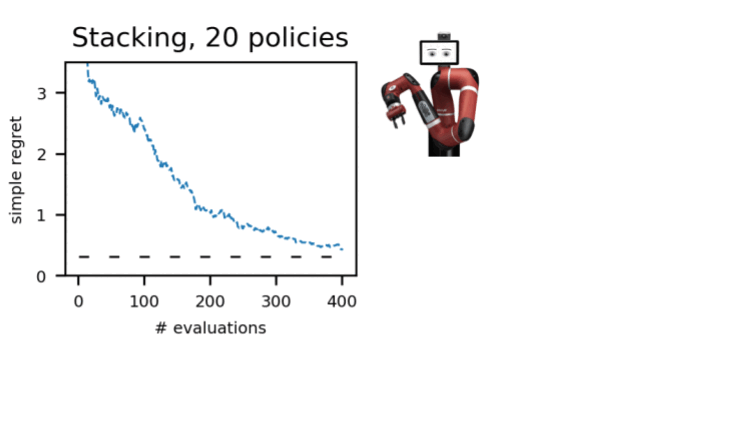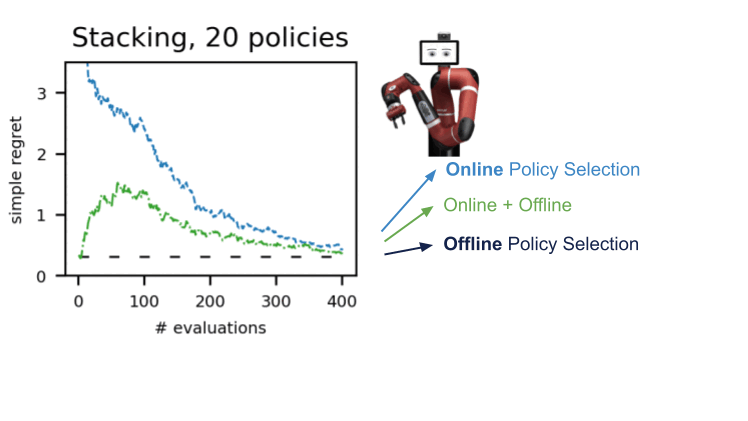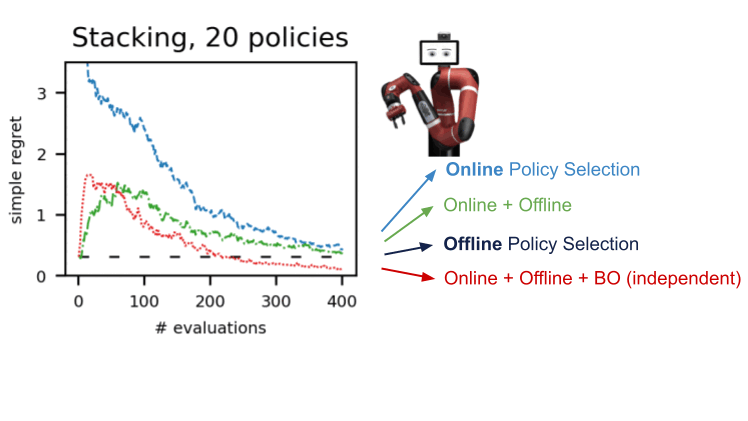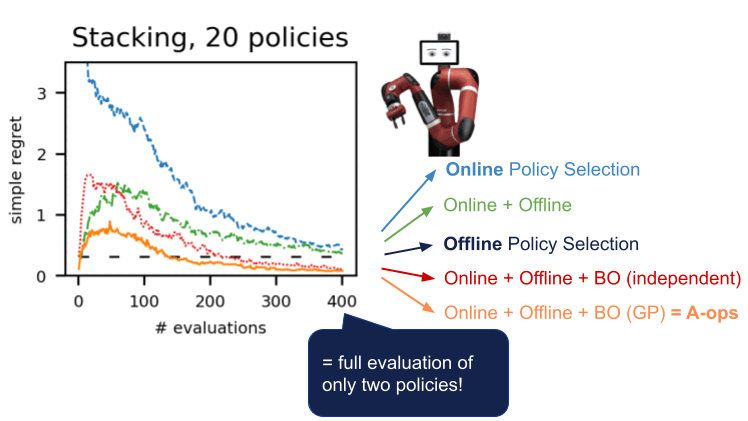
オフラインでのアクティブなポリシー選択
実際のロボット工学などの現実世界のアプリケーションに強化学習をより適用可能にするために、私たちは展開に適した方針を選択するための知的な評価手法、アクティブオフラインポリシー選択(A-OPS)を提案しますA-OPSでは、事前に録画されたデータセットを活用し、限定的な実環境との相互作用を許可することで、選択の品質を向上させます
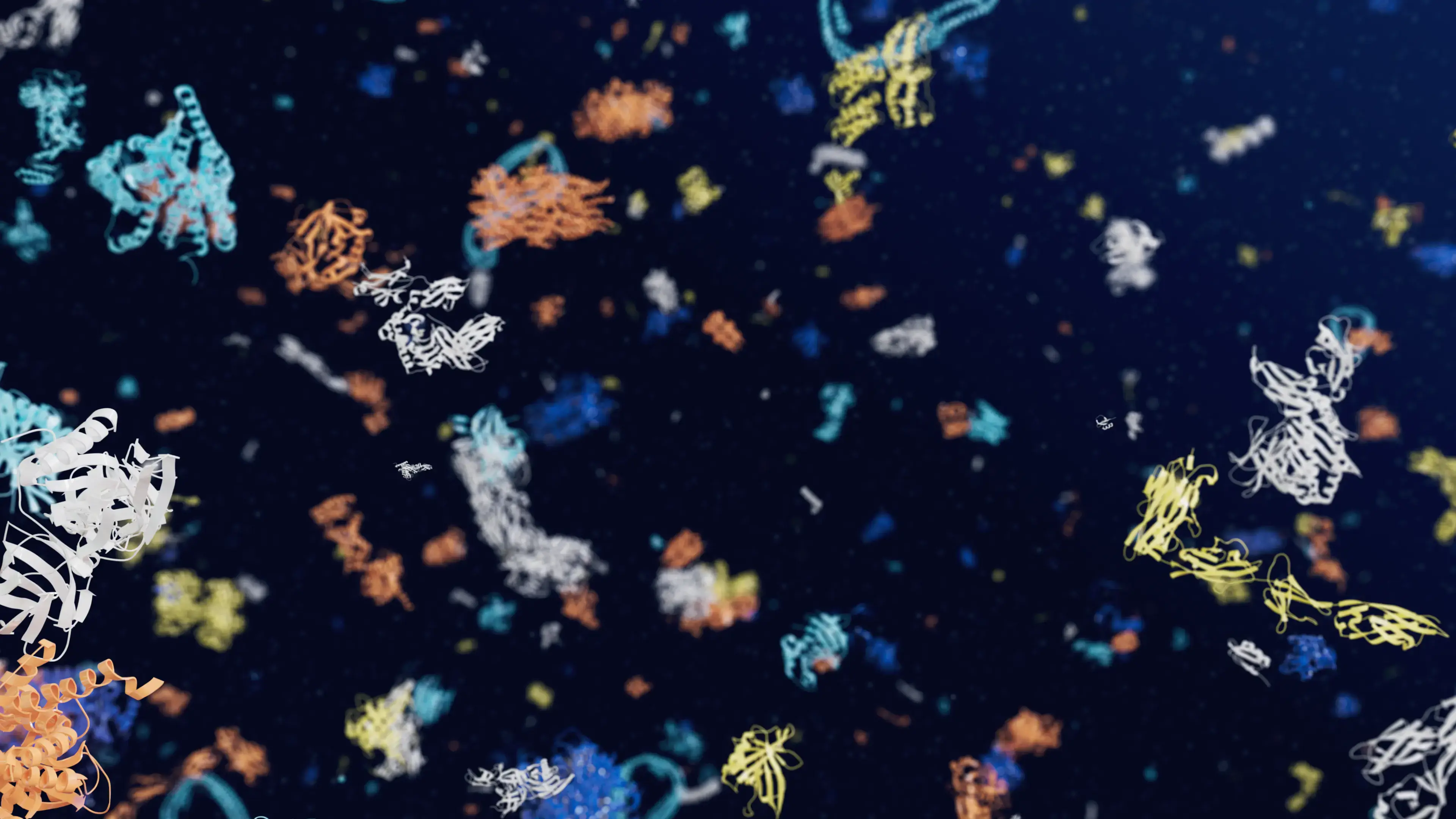
AlphaFoldは、タンパク質の宇宙の構造を明らかにする
今日、EMBLのヨーロッパバイオインフォマティクス研究所(EMBL-EBI)とのパートナーシップを結び、科学界に知られるほぼすべてのカタログ化されたタンパク質の予測構造を公開しますこれにより、AlphaFold DBの構造数は約1,000,000から約2億構造に拡大し、生物学の理解を劇的に高める可能性があります

Pixis AIとは、コードを書かずにAIソリューションを提供する新興のスタートアップです
AIモデルのトレーニングには膨大な情報が必要です。しかし、すべての情報が同じではありません。モデルをトレーニングするためのデータは、エラーがなく、適切にフォーマットされ、ラベルが付けられ、問題を反映している必要があります。これは難しく、時間のかかるプロセスです。計画どおりに機能しない場合、AIモデルのデバッグが困難になることもあります。これは、モデルが通常複雑であり、さまざまな要因が故障の原因となる可能性があるためです。また、モデルの作成に使用されるトレーニングデータも、ミスの原因となる可能性があります。人工知能の領域では常に新しい進歩があります。そのため、新しい動向についていくことは困難です。さらに、AIシステムのハードウェア要件は常に増え続けており、古いまたは性能の低いマシンでAIモデルを実行することは困難です。AIコンポーネントを使用してプログラムを作成する際には、さまざまな困難が生じる場合があります。 現在、AI構造のコーディングに関連する困難を解消するためのさまざまなソリューション/製品が市場に存在しています。たとえば: ノーコードまたは低コード環境。これらのシステムのユーザーは、コードを一切触れずにAIモデルを構築することができます。一般的に、モデル作成やトレーニングプロセスを簡略化するためのグラフィカルユーザーインターフェースが付属しています。 機械学習およびAIホスティングサービス。これらのプラットフォームを通じてクラウドベースのAIモデルやサービスが提供されます。人員や資金がない企業は、自社のAIモデルを作成および維持するためにこれらを活用することができます。 人工知能の専門家。多くのAI専門家がAIに関連する問題に対処するために企業を支援しています。基礎を学ぶことから実践に移すことまで、AIのニーズに応じてサポートできます。 PixisのAIソリューションは、クロスプラットフォームのパフォーマンスと成長マーケティングにAIを活用した意思決定を可能にします。顧客は、目標を満たし超えるために、目的に特化した自己進化型ニューラルネットワークを使用したコードレスのAIインフラストラクチャを活用しています。この若い企業は、堅牢なコードレスのAIインフラストラクチャを実現するために、2022年に1億ドルのシリーズCの資金調達を成功裏に終えました。これにより、ブランドはマーケティングのあらゆる側面の拡大および意思決定の効率的な補完を実現することを目指しています。最後の資金調達以来、Pixisはインフラストラクチャに約120以上の新しいAIモデルを導入し、200の独自のAIモデルのベンチマーク達成に一歩近づいています。これらのAIモデルは、マーケターに対してコードを1行も書かずに堅牢なプラグアンドプレイのAI製品を提供します。また、Pixisの300人以上の分散チームは、顧客のマーケティングおよび需要創出の取り組みを最大限に活用するための非常に変革的なAI製品の開発に注力しています。 100を超えるPixisのグローバル顧客がそのAIサービスを利用しています。Pixis AIインフラストラクチャのユーザーは、少なくとも300時間の手作業の月間節約と、少なくとも10-15%の顧客獲得コストの削減を報告しています。このブランドは、1行のコードを書く必要なしに即座にAIを活性化することを顧客に約束しています。 PixisのパフォーマンスマーケティングのためのコードレスAIインフラストラクチャ:概要 ターゲットAI PixisのターゲティングAIは、数十億のデータポイントでトレーニングされた最先端のニューラルネットワークを使用して、ブランドに最も関連性のあるコホートを提供し、時間の経過とともにさらに向上させます。 ブランドは、コンバージョンのトレンド、行動パターン、エンゲージメントレベル、およびその他のコンテキストの洞察に基づいて導き出されたユーザーペルソナを活用して、ターゲティングパラメータと技法を微調整することができます。インフラストラクチャは、顧客関係管理(CRM)プラットフォーム、アトリビューションプラットフォーム、デザインツール、およびウェブ分析を簡単にサポートします。 ターゲティングAIは、ユニークなクラスタリングアルゴリズムを使用して、非常に関連性の高いクロスプラットフォームのオーディエンスコホートを構築し、ターゲットオーディエンスの知識を活用して、マーケティング活動を創造性と最適化の両面で導きます。 クリエイティブAI PixisのクリエイティブAIは、特許取得済みの生成AIモデルを使用して、関連性の高い視覚的および静的なアセットを作成することで、プラットフォーム全体でのエンゲージメントとコンバージョン率を向上させます。 クリエイティブ努力の効果をフィードバックしやすくすることで、将来のキャンペーンの改善に向けて微調整することが容易になります。すべてのチャネルでのペルソナベースのクリエイティブアドバイスにより、エンゲージメントと売上を増加させます。フィードバックに基づいたクリエイティブの最適化を通じて、クリエイティブAIはコミュニケーションのコンテキストを常に向上させます。 パフォーマンスAI 過去のキャンペーンデータ、季節パターン、アトリビューション、分析、およびリアルタイムのパフォーマンスデータからのコンテキスト学習を統合し、すべてのチャネルにわたるスマートな意思決定を実現するAIパワードマーケティングインフラストラクチャを構築します。 ブランドは、入札とリソースを自動的に割り当てなおすことができ、また、すべてのチャネルでのマイクロトレンドを検出する多目的収束型AIモデルも含まれているインフラストラクチャを使用して、広告支出のリターンを最大化することを目指しています。 ピーク時のトラフィックでAIトラックを実行し、広告費の支出と収益(ROAS)を分析し、将来のキャンペーンに最適な予算配分技術を予測します。予算編成と主要パフォーマンス指標の最適化の間のベストなバランスを見つけるために、ハイパーコンテクストUAL AIモデルを使用します。 Pixis AIの特長機能 ●…

強化学習:コンピューターに最適な決定をさせる方法の教え方
足を濡らすための強化学習の基本を学びましょうエージェントや報酬から価値関数、方策など、強化学習フレームワークの要素とキーコンセプトを学びます
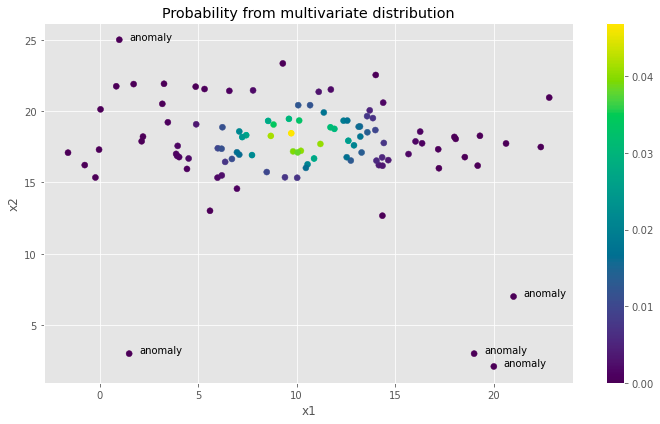
多変量ガウス分布による異常検知の基本
私たちの生まれつきのパターン認識能力によって、私たちはこのスキルを使って抜け落ちた部分を埋めたり、次に何が起こるかを予測したりすることができますしかし時折、私たちの予測に合わないことが起こります...
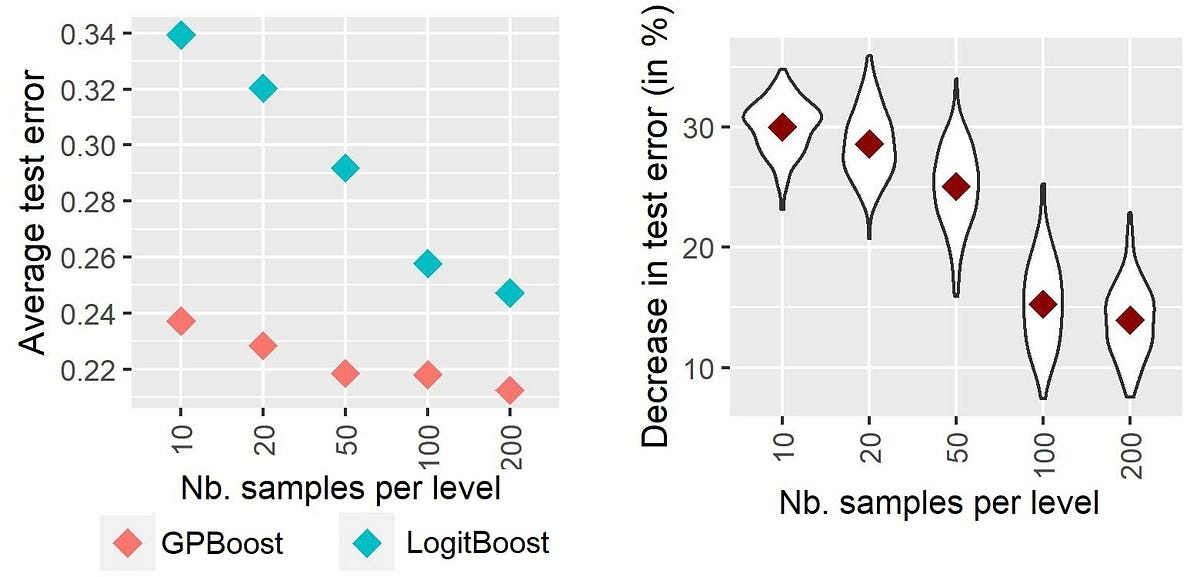
ハイカーディナリティのカテゴリカル変数に対する混合効果機械学習-第I部:異なる手法の実証的比較
高次元のカテゴリー変数のモデリングを向上させるための機械学習におけるランダム効果:アプローチの紹介と比較
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.