Learn more about Search Results ML - Page 349

- You may be interested
- 「Amazon SageMaker Feature Store Featur...
- クラスの不均衡:アンダーサンプリング技...
- 「GenAI-Infused ChatGPT 有効なプロンプ...
- 疾病の原因を特定するための遺伝子変異の...
- マルコフとビネメ・シェビシェフの不等式
- 『LLM360をご紹介します:最初の完全オー...
- 「ChatGPT 3.5 Turboの微調整方法」
- Google Cloudによるデジタルトランスフォ...
- このAI論文は、MITが化学研究のために深層...
- モバイルネットワーク上でのIoTの増加する...
- 「RoboPianistに会いましょう:シミュレー...
- AnomalyGPT:LVLMを使用して産業の異常を...
- LLMの巨人たちの戦い:Google PaLM 2 vs O...
- 最終フロンティアの記録:30日間の#30DayM...
- チャットボットに関する不正行為の懸念は...
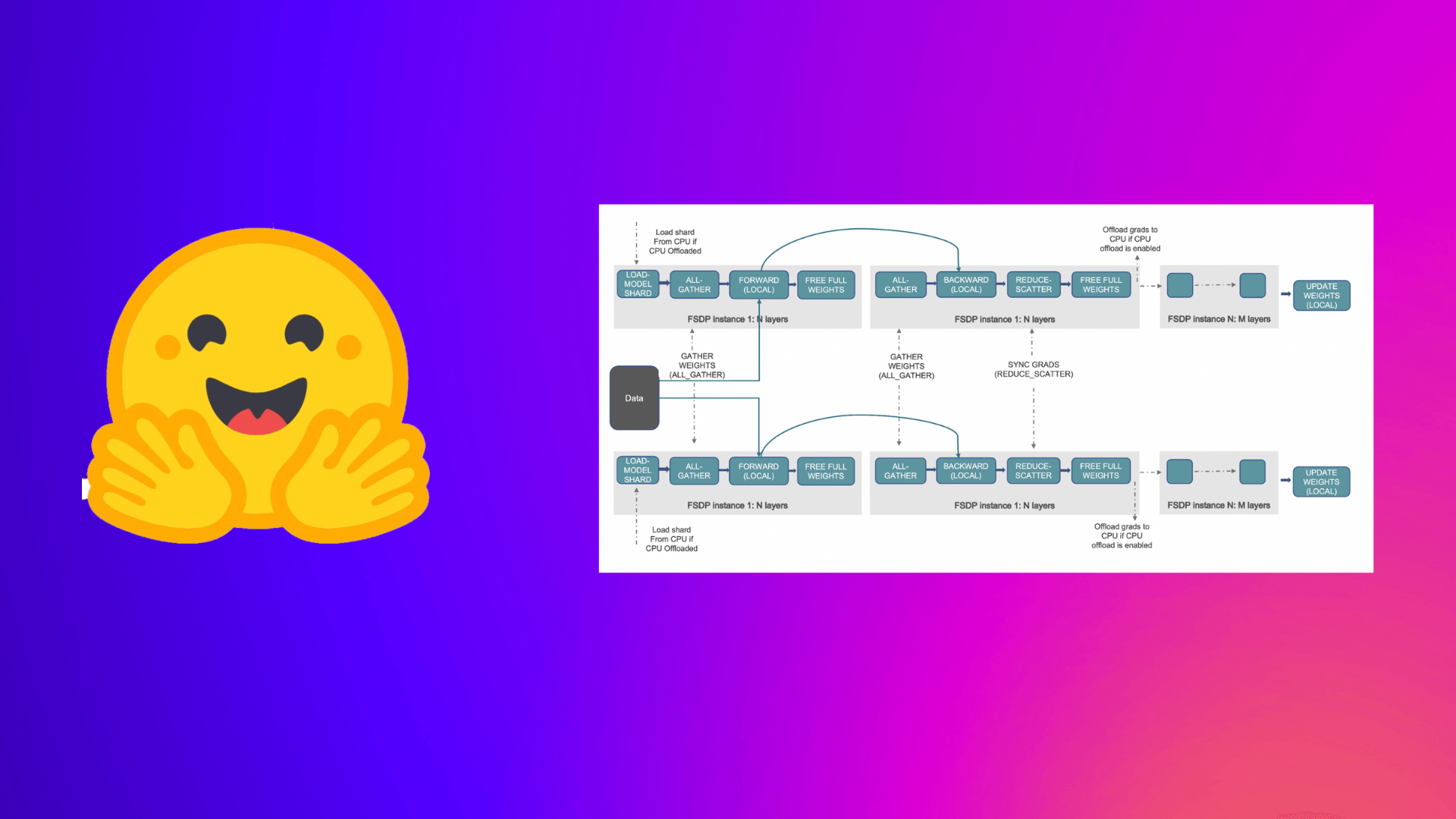
PyTorch完全にシャーディングされたデータパラレルを使用して、大規模モデルのトレーニングを加速する
この投稿では、Accelerate ライブラリを活用して大規模なモデルのトレーニングを行う方法について説明します。これにより、ユーザーは PyTorch FullyShardedDataParallel (FSDP) の最新機能を活用することができます。 機械学習 (ML) モデルのスケール、サイズ、およびパラメータがますます増加するにつれ、ML プラクティショナーは自身のハードウェア上でそのような大規模なモデルをトレーニングしたり、ロードしたりすることが困難になっています。 一方で、大規模なモデルは小さなモデルと比較して学習が速く(データと計算効率が高く)、パフォーマンスも著しく向上することがわかっています [1]。しかし、そのようなモデルをほとんどの利用可能なハードウェア上でトレーニングすることは困難です。 大規模なMLモデルをトレーニングするためには、分散トレーニングが重要です。 分散トレーニング の分野では、最近重要な進展がありました。最も注目すべき進展のいくつかは以下のとおりです: ZeROを用いたデータ並列化 – Zero Redundancy Optimizer [2] ステージ1:データ並列ワーカー/ GPU間でオプティマイザーの状態を分割 ステージ2:データ並列ワーカー/…

深層強化学習の概要
Hugging FaceとのDeep Reinforcement Learningクラスの第1章 ⚠️ この記事の新しい更新版はこちらでご覧いただけます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learningクラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらでご覧いただけます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learningクラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 人工知能の最も魅力的なトピックへようこそ: Deep Reinforcement Learning(深層強化学習) Deep RLは、エージェントが行動を実行し、結果を観察することで、環境内でどのように振る舞うかを学習する機械学習の一種です。…

Hugging Faceハブへ、fastaiさんを歓迎します
ニューラルネットを再びクールじゃなくする…そして共有する Deep Learningのアクセシビリティを高めるために、fast.aiエコシステムは他に類を見ない成果を上げてきました。Hugging Faceの使命は、優れた機械学習を民主化することです。機械学習へのアクセスの排他性、事前学習済みモデルを過去のものとし、この素晴らしい領域をさらに推進しましょう。 fastaiは、PyTorchとPythonを活用して、テキスト、画像、表形式のデータに対して最新の出力を備えた高速かつ正確なニューラルネットワークをトレーニングするためのハイレベルなコンポーネントを提供するオープンソースのDeep Learningライブラリです。ただし、fast.aiは単なるライブラリ以上のものです。それはオープンソースの貢献者とニューラルネットワークの学習に取り組む人々の繁栄するエコシステムに成長しました。いくつかの例として、彼らの書籍やコースをチェックしてみてください。fast.aiのDiscordやフォーラムに参加してください。彼らのコミュニティに参加することで、確実に学びが得られます! これら全ての理由から(この記事の執筆者はfast.aiのコースのおかげで自分の旅をスタートさせました)、私たちは誇りを持ってお知らせします。fastaiのプラクティショナーは、Pythonの一行でモデルをHugging Face Hubに共有・アップロードすることができるようになりました。 👉 この記事では、fastaiとHubの統合について紹介します。さらに、このチュートリアルをColabノートブックとして開くこともできます。 fast.aiコミュニティ、特にJeremy Howard、Wayde Gilliam、Zach Muellerにフィードバックをいただいたことに感謝します 🤗。このブログは、fastaiドキュメントのHugging Face Hubセクションに強く触発されています。 Hubに共有する理由 Hubは、モデル、データセット、MLデモを共有・探索できる中央プラットフォームです。最も広範なオープンソースのモデル、データセット、デモのコレクションを提供しています。 Hubで共有することで、あなたのfastaiモデルの影響力を広げ、他の人がダウンロードして探索できるようにします。また、fastaiモデルを転移学習に利用することもできます。他の誰かのモデルをタスクの基礎として読み込むことができます。 誰でも、hf.co/modelsのウェブページでfastaiライブラリをフィルタリングすることで、Hubの全てのfastaiモデルにアクセスできます。以下の画像を参照してください。 広範なコミュニティへの無料モデルホスティングと露出に加えて、Hubにはgitに基づいたバージョン管理(大容量ファイルの場合はgit-lfs)や、発見性と再現性のためのモデルカードも組み込まれています。Hubのナビゲーションについての詳細は、この紹介を参照してください。 Hugging…

学生アンバサダープログラムの応募受付が開始されました!
オープンソースの企業であり、機械学習の民主化を目指すHugging Faceは、世界中のさまざまなバックグラウンドを持つ人々にオープンソースの機械学習を教えることが不可欠だと考えています。 2023年までに500万人に機械学習を教えることを目指しています。 あなたは機械学習を勉強していますか、または既にコミュニティで機械学習を普及させていますか? Hugging Faceと一緒に機械学習の民主化の取り組みに参加し、キャンパスコミュニティにHugging Faceを使用したMLモデルの構築方法を紹介したいですか? もしもそうであれば、私たちはあなたの取り組みをサポートするために、初の学生アンバサダープログラムを立ち上げます 🤗 🥳 以下のことをしたい場合は、学生アンバサダープログラムは素晴らしい機会です。 仲間をサポートして彼らの機械学習の道を手助けする 無料でオープンソースの技術を学び使う 繁栄するエコシステムに貢献する コミュニティの価値観を共有しながらコミュニティを育てることに熱心である 学生アンバサダープログラムはあなたにとって絶好の機会です。応募期限は2022年6月13日までです! プログラムへの参加のメリットは何ですか? 🤩 選ばれたアンバサダーは以下のリソースとサポートを受けることができます: 🎎 コラボレーションできる仲間のネットワーク。 🧑🏻💻 Hugging Faceチームからのワークショップとサポート!…

機械学習インサイトのディレクター[Part 2 SaaSエディション]
もしもあなたやあなたのチームがMLソリューションの構築に興味があるなら、今すぐhf.co/supportを訪れてください! 👋 マシンラーニングインサイトの第2弾へようこそ。第1弾はこちらをご覧ください。 マシンラーニングディレクターは、さまざまな役割と責任の視点を持つAIテーブルで特別な立場にあります。彼らのMLフレームワーク、エンジニアリング、アーキテクチャ、実世界の応用および問題解決に関する豊富な知識は、MLの現状に深い洞察を提供します。例えば、あるディレクターは、新しいトランスフォーマースピーチテクノロジーの使用により、チームのエラーレートを30%減少させ、単純な思考が多くの計算能力を節約するのに役立つことに気付くでしょう。 SalesforceやZoomInfoのディレクターが現在のマシンラーニングの状況についてどう考えているのか、彼らの最大の課題は何か、そして彼らが最も興奮していることは何か、気になりませんか?それでは、すぐに知ることができます! この第2弾のSaaSに焦点を当てたインストールでは、ヘルスケアの教科書の著者であり、MLの才能を育成する非営利団体を設立した深層学習の専門家、チェス愛好家のサイバーセキュリティ専門家、リードリコール後のバービーのブランド評判の監視の必要性からビジネスを起こした起業家、そして自身の4人の子供がMLモデルと同じ間違いをするのを見るのが楽しいと感じる特許および学術論文の著者が登場します。 🚀 SaaSのトップマシンラーニングディレクターに会って、彼らがマシンラーニングについてどう考えているか聞いてみましょう: Omar Rahman – Salesforceでのマシンラーニングディレクター 経歴:オマーは、サイバーセキュリティチームの一環として、MLとデータエンジニアのチームをリードし、MLを防御的なセキュリティ目的で活用しています。以前、オマーはAdobeやSAPでデータサイエンスとMLエンジニアリングのチームをリードし、マーケティングクラウドや調達アプリケーションにインテリジェントな機能をもたらしていました。オマーはアリゾナ州立大学で電気工学の修士号を取得しています。 おもしろい事実:オマーはチェスをすることが大好きで、自由な時間にAIの卒業生を指導しています。 Salesforce:世界トップの顧客関係管理ソフトウェア。 1. MLはSaaSにどのようにポジティブな影響を与えていますか? MLはSaaSの提供に多くの利点をもたらしています。 a. アプリケーション内の自動化の改善:たとえば、サービスリクエストの文脈を理解し、組織内の適切なチームにルーティングするためにNLP(自然言語処理)を使用するサービスチケットルーター。 b. コードの複雑さの削減:ルールベースのシステムは、新しいルールが追加されると使いにくくなり、メンテナンスコストが増加します。例えば、以前のルールベースのシステムと比較して、MLベースの言語翻訳システムは、より正確で堅牢でありながら、はるかに少ない行数のコードで構築されています。 c. コスト削減につながるより良い予測結果。より正確に予測できることは、供給チェーンのバックオーダーの削減やストレージコストの削減など、コスト削減に役立ちます。…

Gradio 3.0 がリリースされました!
機械学習デモ 機械学習デモは、モデルのリリースにおいてますます重要な役割を果たしています。デモを使用することで、MLエンジニアに限らず誰でもブラウザ上でモデルを試し、予測にフィードバックを提供し、モデルがうまく機能する場合にはモデルへの信頼を築くことができます。 2019年の初版以来、Gradioライブラリを使用して600,000以上のMLデモが作成されています。そして今日、私たちはうれしいことに、Gradio 3.0の発表をお知らせできます!Gradioライブラリの完全な再設計です🥳 Gradio 3.0の新機能 🔥 Gradioユーザーからのフィードバックに基づいた、フロントエンドの完全な再設計: Gradioフロントエンドの構築には、Svelteなどの最新技術を使用しています。その結果、ペイロードが非常に小さく、ページの読み込みも非常に高速になりました! また、よりクリーンなデザインにも取り組んでおり、Gradioデモが視覚的により多くの設定に適合するようになりました(ブログ記事に埋め込まれるなど)。 CSVファイルをドラッグアンドドロップしてDataframeに入力するなど、既存のコンポーネントであるDataframeをよりユーザーフレンドリーに改良し、Galleryなどの新しいコンポーネントを追加して、モデルに適したUIを構築できるようにしました。 新たにTabbedInterfaceクラスを追加しました。これにより、関連するデモを1つのWebアプリケーション内の複数のタブとしてグループ化することができます。 すべての使用可能なコンポーネントについては、(再設計された)ドキュメントをご覧ください🤗! 🔥 Pythonで複雑なカスタムWebアプリを構築できる新しい低レベル言語Gradio Blocksを作成しました: なぜBlocksを作成したのでしょうか?Gradioデモは非常に簡単に構築できますが、デモのレイアウトやデータのフローに対してより細かい制御をしたい場合はどうでしょうか?たとえば、以下のようなことができるようになります: 入力を左側にまとめ、出力を右側にまとめるデモのレイアウトを変更する 1つのモデルの出力を次のモデルの入力とするような、マルチステップのインターフェースを持つか、一般的にはより柔軟なデータフローを持つ ユーザーの入力に基づいてコンポーネントのプロパティ(例:ドロップダウンの選択肢)や表示状態を変更する 低レベルのBlocks APIを使用すると、すべての操作をPythonで実行できます。 次に、2つのシンプルなデモを作成し、タブを使用してそれらをグループ化するBlocksデモの例を示します: import…

ハギングフェイスフェローシッププログラムの発表
フェローシップは、さまざまなバックグラウンドを持つ優れた人々のネットワークであり、機械学習のオープンソースエコシステムに貢献しています🚀。このプログラムの目標は、主要な貢献者に力を与え、彼らの影響力をスケールさせると同時に、他の人々にも貢献を促すことです。 フェローシップの仕組み 🙌🏻 これはHugging Faceが貢献者の素晴らしい仕事をサポートしています!フェローであることは、すべての人にとって異なる方法で機能します。重要な質問は次のとおりです: ❓ 貢献者がより大きな影響を持つためには何が必要ですか? Hugging Faceは彼らが常にやりたかったプロジェクトを実現できるようにどのようにサポートできますか? あらゆるバックグラウンドのフェローを歓迎します!機械学習の進歩は草の根の貢献に依存しています。それぞれの人には、さまざまな方法でこの分野を民主化するために使用できる独自のスキルと知識があります。それぞれのフェローは異なる方法で影響を与え、それは完璧です🌈。 Hugging Faceは彼らが最も必要とする方法で創造し、共有し続けることをサポートします。 フェローシップに参加することの利点は何ですか? 🤩 利点は個々の興味に基づきます。Hugging Faceがフェローをサポートする例をいくつか紹介します: 💾 コンピューティングとリソース 🎁 マーチャンダイズと資産。 ✨ Hugging Faceからの公式な認知。 フェローになるには…

機械学習の専門家 – Sasha Luccioni
🤗 マシンラーニングエキスパートへようこそ – サーシャ・ルッチョーニ 🚀 サーシャのようなMLエキスパートがあなたのMLロードマップを加速する方法に興味がある場合は、hf.co/supportを訪れてください。 こんにちは、友達たち!マシンラーニングエキスパートへようこそ。私は司会者のブリトニー・ミュラーで、今日のゲストはサーシャ・ルッチョーニです。サーシャは、Hugging Faceで研究科学者として、機械学習モデルとデータセットの倫理的・社会的影響に取り組んでいます。 サーシャはまた、Big Science WorkshopのCarbon Footprint WGの共同議長、WiMLの理事、そして気候危機に機械学習を適用する意義のある活動を促進するClimate Change AI(CCAI)組織の創設メンバーでもあります。 サーシャがメールの炭素フットプリントを計測する方法、地元のスープキッチンが機械学習の力を活用するのをどのように手助けしたか、そして意味と創造性が彼女の仕事を支える方法についてお話しいただきます。 この素晴らしいエピソードを紹介するのをとても楽しみにしています!以下がサーシャ・ルッチョーニとの私の対話です: 注:転記はわかりやすい読み物を提供するためにわずかに修正/書式設定されています。 今日参加していただき、本当にありがとうございます。私たちはあなたが来てくれたことを非常に嬉しく思っています! サーシャ: 私もここにいることを本当に嬉しく思っています。 直接本題に入りますが、あなたのバックグラウンドとHugging Faceへの道を教えていただけますか? サーシャ:…

Q-学習入門 第1部への紹介
ハギングフェイスと一緒に行うディープ強化学習クラスのユニット2、パート1 🤗 ⚠️ この記事の新しいバージョンがこちらで利用可能です 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 ⚠️ この記事の新しいバージョンがこちらで利用可能です 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 このクラスの第1章では、強化学習(RL)、RLプロセス、およびRL問題を解決するための異なる手法について学びました。また、最初のランダーエージェントをトレーニングして、月面に正しく着陸させ、Hugging Face Hubにアップロードしました。 今日は、強化学習のメソッドの一つである価値ベースの手法について詳しく掘り下げて、最初のRLアルゴリズムであるQ-Learningを学びます。 また、スクラッチから最初のRLエージェントを実装し、2つの環境でトレーニングします: Frozen-Lake-v1(滑りにくいバージョン):エージェントは凍ったタイル(F)の上を歩き、穴(H)を避けて、開始状態(S)からゴール状態(G)へ移動する必要があります。 自動タクシーは、都市をナビゲートすることを学び、乗客をポイントAからポイントBまで輸送する必要があります。 このユニットは2つのパートに分かれています: 第1部では、価値ベースの手法とモンテカルロ法と時間差学習の違いについて学びます。 そして、第2部では、最初のRLアルゴリズムであるQ-Learningを学び、最初のRLエージェントを実装します。 このユニットは、Deep Q-Learning(ユニット3)で作業できるようになるためには基礎となるものです。これは最初のDeep…
Q-Learningの紹介 パート2/2
ディープ強化学習クラスのユニット2、パート2(Hugging Faceと共に) ⚠️ この記事の新しい更新版はこちらで入手できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらで入手できます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 このユニットの第1部では、価値ベースの手法とモンテカルロ法と時差学習の違いについて学びました。 したがって、第2部では、Q-Learningを学び、スクラッチから最初のRLエージェントであるQ-Learningエージェントを実装し、2つの環境でトレーニングします: 凍った湖 v1 ❄️:エージェントは凍ったタイル(F)の上を歩き、穴(H)を避けて、開始状態(S)からゴール状態(G)に移動する必要があります。 自律運転タクシー 🚕:エージェントは都市をナビゲートし、乗客を地点Aから地点Bに輸送する必要があります。 このユニットは、ディープQ-Learning(ユニット3)で作業を行うためには基礎となるものです。 では、始めましょう! 🚀 Q-Learningの紹介 Q-Learningとは?…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.