Learn more about Search Results Yi - Page 33

- You may be interested
- TSMixer グーグルによる最新の予測モデル
- LLM幻覚を軽減する方法
- VRヘッドセットはハッカーに対して脆弱です
- 「ResFieldsをご紹介します:長くて複雑な...
- DeepBrain AIレビュー:最高のAIアバター...
- RWKVとは、トランスフォーマーの利点を持...
- 「組織内で責任ある効果的なAI駆動文化を...
- Amazon SageMaker Data WranglerのSnowfla...
- 「機械エンジニアからデータサイエンティ...
- 「ジェーン・ザ・ディスカバラー:大規模...
- 「ChatGPT Canvaプラグインでグラフィック...
- 疾病の原因を特定するための遺伝子変異の...
- Optimum+ONNX Runtime – Hugging Fa...
- 「長期のCOVID検査への研究者の前進」
- 「統計学習入門、Pythonエディション:無...

大規模言語モデル:RoBERTa — ロバストに最適化されたBERTアプローチ
BERTモデルの登場は、自然言語処理(NLP)の大きな進歩をもたらしましたBERTはTransformerからアーキテクチャを派生させ、言語モデリングなどのさまざまな下流タスクで最先端の結果を達成しています
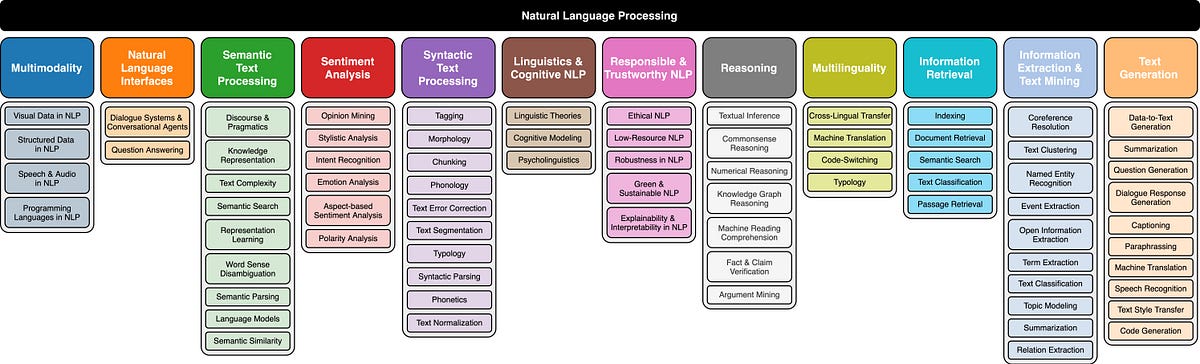
自然言語処理のタクソノミー
「異なる研究分野と最近の自然言語処理(NLP)の進展の概要」

スタンフォード大学の研究は、PointOdysseyを紹介します:長期ポイント追跡のための大規模な合成データセット
大規模な注釈付きデータセットは、さまざまなコンピュータビジョンタスクで正確なモデルを作成するためのハイウェイとして機能してきました。この研究では、細かい粒度の長距離トラッキングを達成するために、このようなハイウェイを提供することを目指しています。細かい粒度の長距離トラッキングは、映画の任意のフレームの任意のピクセルの位置を与えられた場合に、できるだけ長い時間、マッチングする世界の表面点を追跡することを目指しています。細かい粒度の短距離トラッキング(光流など)を目的としたデータセットの世代がいくつかあり、さまざまな種類の粗い粒度の長距離トラッキング(単一オブジェクトトラッキング、複数オブジェクトトラッキング、ビデオオブジェクトセグメンテーションなど)を目的とした定期的に更新されるデータセットがあります。しかし、これら2つの監視タイプのインターフェースに関する作品は限られています。 研究者たちはすでに実世界の映画で細かい粒度のトラッカーをスパースな人手による注釈(BADJAとTAPVid)を持つ映画でテストし、非現実的な合成データ(FlyingThings++とKubric-MOVi-E)でそれらをトレーニングしています。合成データは、ランダムなオブジェクトがランダムなバックドロップ上で予期せぬ方向に移動するものです。これらのモデルが実際のビデオに一般化できるという事実は興味深いですが、このような基本的なトレーニングを使用することで、長期的なコンテキストとシーンレベルの意味理解の開発が妨げられます。彼らは、長距離ポイントトラッキングは光流の拡張として考えてはならず、自然主義が犠牲になってもネガティブな結果が発生しないと主張しています。 ビデオのピクセルは多少ランダムに動くかもしれませんが、その経路にはカメラの振動、オブジェクトレベルの移動と変形、社会的および物理的相互作用を含む多くのモデリング可能な要素が反映されています。進歩は、問題の重要性を認識することに依存しています。これは、データと方法論の両方の観点からの問題の重要性を人々が認識することに依存しています。スタンフォード大学の研究者たちは、PointOdysseyという長期的な細かい粒度のトラッキングのトレーニングと評価のための大規模な合成データセットを提案しています。彼らのコレクションには、リアルワールドのビデオの複雑さ、多様性、リアリズムがすべて表現されており、ピクセルパーフェクトな注釈はシミュレーションを通じてのみ実現可能です。 彼らは、ランダムまたは手動設計ではなく、リアルワールドのビデオとモーションキャプチャから採掘したモーション、シーンレイアウト、カメラの軌跡を使用しており、これは彼らの作業を以前の合成データセットと区別しています。また、環境マップ、照明、人間および動物の体、カメラの軌跡、材料など、さまざまなシーン属性でドメインのランダム化を使用しています。高品質なコンテンツとレンダリング技術のアクセス性の向上により、これまでに達成できなかったより写真的なリアリズムを提供することもできます。彼らのデータのモーションプロファイルは、大規模な人間および動物のモーションキャプチャデータセットから派生しています。これらのキャプチャを使用して、屋外環境でのヒューマノイドや他の動物のリアルな長距離軌跡を生成します。 屋外環境では、これらのアクターを地面にランダムに配置された3Dオブジェクトとペアにします。これらのオブジェクトは、キックされたり、足が接触すると蹴られたりするなど、物理的な反応を示します。次に、内部設定のモーションキャプチャを使用して、リアルな屋内シナリオを作成し、キャプチャ環境を手動で再現します。これにより、元のデータのシーン認識の性格を保ちながら、正確なモーションと相互作用を再現することができます。また、シチュエーションの複雑なマルチビューデータを提供するために、実際の映像から導かれたカメラの軌跡をインポートし、合成された存在の頭部に追加のカメラを接続します。KubricとFlyingThingsの主にランダムなモーションパターンとは対照的に、キャプチャ駆動アプローチを取っています。 彼らのデータは、従来のボトムアップの手がかり(特徴マッチングなど)だけに頼るのではなく、シーンレベルの手がかりを利用してトラックに強力なプライオリティを提供するトラッキング技術の開発を促進します。42種類のヒューマノイド形状、アーティストによって作成されたテクスチャ、7種類の動物、1K以上のオブジェクト/背景テクスチャ、1K以上のオブジェクト、20のオリジナル3Dシーン、50の環境マップなど、さまざまなシミュレートされたアセットの大規模なコレクションがデータに美的多様性を与えています。シーンの照明をランダム化して、さまざまな暗い場所と明るい場所を作成します。さらに、シーンにダイナミックな霧や煙の効果を追加し、FlyingThingsとKubricに完全に欠けている部分的な遮蔽のタイプを追加します。PointOdysseyが開く新しい問題の1つは、長距離の時間的コンテキストをどのように使用するかです。 たとえば、最先端のトラッキングアルゴリズムであるPersistent Independent Particles (PIPs)は、8フレームの時間ウィンドウを持っています。彼らは、任意の長さの時間的コンテキストを使用するための最初のステップとして、PIPにいくつかの変更を提案しています。これには、8フレームの時間範囲を大幅に拡張し、テンプレートの更新メカニズムを追加することが含まれます。実験結果によれば、彼らのソリューションは、PointOdysseyのテストセットおよび実世界のベンチマークにおいて、トラッキングの正確さにおいて他のすべての手法を上回るという結果です。結論として、本研究の主要な貢献である、リアルワールドの細かい粒度のモニタリングの難しさと機会を反映しようとする長期的なポイントトラッキングのための大規模な合成データセットであるPointOdysseyです。

「Excelでウォーターフォールチャートを作成する方法」
はじめに Excelは、データ分析や数学的な計算からビジネスレポートの管理やデータの整理まで、多くの機能を備えたグローバルなパワーハウスです。データの可視化に優れており、ピポットチャート、2D折れ線グラフ、ヒストグラム、円グラフなどのチャートやグラフを作成することができます。その中でも、Excelのウォーターフォールチャートは特に効果的なツールとして際立っています。Excelがどのように能力を高め、効率を向上させるかを探ってみましょう。 ウォーターフォールチャートとは何ですか? Excelのウォーターフォールチャートは、連続的に増加する正の(加算)または負の(減算)値を視覚的に示すために使用されます。ウォーターフォールチャート、またはウォーターフォールダイアグラムまたはブリッジチャートとも呼ばれるこのチャートは、最初の値がチャート全体を通じて最終的な値にどのように移行するかを単純に示しています。 空中に浮かんでいる中央の列は、正の値と負の値を区別するために多少色分けされています。これらの中間値はタイムラインで増減します。したがって、ウォーターフォールチャートはフライングブリックスチャート、ブリッジチャートまたはマリオチャートとも呼ばれています。 さらに読む: ウォーターフォールチャートの始め方 Excelでウォーターフォールチャートを作成するには、Excelの使用においてマスターである必要はありません。誰でも個人用または専門用途にブリッジチャートを作成することができます。Excelのウォーターフォールチャートは、正確な結果と直線的なアプローチのため、金融および会計部門、ビジネス管理、製造部門などが望む結果を得るために使用します。Excelでウォーターフォールチャートを作成するには、次の手順があります。 必要なデータ形式 ウォーターフォールダイアグラムを作成するためには、まずチャートを作成するためのデータが必要です。希望するデータを取得した後、最初の値、最後の値、中間の正の値、負の値の形式でデータを整形する必要があります。これらのカテゴリーでデータをラベル付けすることで、混乱することなくデータを簡単に識別することができます。 ウォーターフォールチャートのためのデータの準備 Excelでウォーターフォールチャートのためのデータを準備することは、簡単ですが重要なステップであり、後の作業を容易にすることができます。データが事前に準備されていない場合、多くの異常が発生する可能性があります。たとえば、データの初期行と最終行がソートされているかもしれませんが、正確な結果を生成するためには、データをベース、加算/上昇または減算/下降の列に再配置して異なる値のブリッジを作成する必要があります。 Excelでウォーターフォールチャートを作成する方法 データを見る方法やそれとの対話方法は、洞察を得るためやデータ内の数字を理解するために最も重要な要素の一つです。注意深いカラーチョイスとメトリクスを持つ視覚的に魅力的なウォーターフォールチャートを作成することで、ユーザーとExcelの列との関係を作り出し、情報のより良い抽出を実現することができます。以下では、Microsoft Excelでウォーターフォールチャートを作成する手順を段階的に学んでいきます。 データの作成または読み込み Excelでウォーターフォールチャートを作成するためには、2つの新しい列を作成し、それらにラベルを付けて月と収入という詳細を追加します。ここでは、正の値は利益を示し、負の値は損失を示します。 ウォーターフォールチャートの作成 データが追加された後の次のステップは、Excelファイルでウォーターフォールチャートを作成することです。チャートには、収入の変化や収入の上下の変動が表示されます。 Ctrl + Shift + 矢印を押してすべての行を選択するか、マウスで行を手動で選択します。…

大規模言語モデルの応用の最先端テクニック
イントロダクション 大規模言語モデル(LLM)は、人工知能の絶えず進化する風景において、注目すべきイノベーションの柱です。GPT-3のようなこれらのモデルは、印象的な自然言語処理およびコンテンツ生成の能力を示しています。しかし、それらのフルポテンシャルを活かすには、その複雑な仕組みを理解し、ファインチューニングなどの効果的な技術を用いてパフォーマンスを最適化する必要があります。 私はLLMの研究の奥深さに踏み込むことが好きなデータサイエンティストとして、これらのモデルが輝くためのトリックや戦略を解明するための旅に出ました。この記事では、LLMのための高品質データの作成、効果的なモデルの構築、および現実世界のアプリケーションでの効果を最大化するためのいくつかの重要な側面を紹介します。 学習目標: 基礎モデルから専門エージェントまでのLLMの使用における段階的なアプローチを理解する。 安全性、強化学習、およびデータベースとのLLMの接続について学ぶ。 「LIMA」、「Distil」、および質問応答技術による一貫した応答の探求。 「phi-1」などのモデルを用いた高度なファインチューニングの理解とその利点。 スケーリング則、バイアス低減、およびモデルの傾向に対処する方法について学ぶ。 効果的なLLMの構築:アプローチと技術 LLMの領域に没入する際には、その適用の段階を認識することが重要です。これらの段階は、私にとって知識のピラミッドを形成し、各層が前の層に基づいて構築されています。基礎モデルは基盤です。それは次の単語を予測することに優れたモデルであり、スマートフォンの予測キーボードと同様です。 魔法は、その基礎モデルをタスクに関連するデータを用いてファインチューニングすることで起こります。ここでチャットモデルが登場します。チャットの会話や教示的な例でモデルをトレーニングすることで、チャットボットのような振る舞いを示すように誘導することができます。これは、さまざまなアプリケーションにおける強力なツールです。 インターネットはかなり乱暴な場所であるため、安全性は非常に重要です。次のステップは、人間のフィードバックからの強化学習(RLHF)です。この段階では、モデルの振る舞いを人間の価値観に合わせ、不適切な応答や不正確な応答を防止します。 ピラミッドをさらに上に進むと、アプリケーション層に達します。ここでは、LLMがデータベースと接続して、有益な情報を提供し、質問に答えたり、コード生成やテキスト要約などのタスクを実行したりすることができます。 最後に、ピラミッドの頂点は、独自にタスクを実行できるエージェントの作成に関わります。これらのエージェントは、ファイナンスや医学などの特定のドメインで優れた性能を発揮する特殊なLLMと考えることができます。 データ品質の向上とファインチューニング データ品質はLLMの効果において重要な役割を果たします。データを持つことだけでなく、正しいデータを持つことが重要です。たとえば、「LIMA」のアプローチでは、注意深く選ばれた小さなセットの例が大きなモデルよりも優れることが示されています。したがって、焦点は量から品質へと移ります。 「Distil」テクニックは、別の興味深いアプローチを提供しています。ファインチューニング中に回答に根拠を加えることで、モデルに「何」を教えるかと「なぜ」を教えることができます。これにより、より堅牢で一貫性のある応答が得られることがしばしばあります。 Metaの創造的なアプローチである回答から質問のペアを作成する手法も注目に値します。既存のソリューションに基づいて質問を形成するためにLLMを活用することで、より多様で効果的なトレーニングデータセットが作成できます。 LLMを使用したPDFからの質問ペアの作成 特に魅力的な手法の1つは、回答から質問を生成することです。これは一見矛盾する概念ですが、知識の逆破壊とも言える手法です。テキストがあり、それから質問を抽出したいと想像してみてください。これがLLMの得意分野です。 たとえば、LLM Data Studioのようなツールを使用すると、PDFをアップロードすると、ツールが内容に基づいて関連する質問を出力します。このような手法を用いることで、特定のタスクを実行するために必要な知識を持ったLLMを効率的に作成することができます。…

「ヌガットモデルを使用した研究論文の生成AI」
最近の大規模言語モデル(LLM)の進展(例:GPT-4)は、一貫したテキストの生成能力において印象的な成果を示していますしかし、研究論文の解析と理解は依然として…

「限られたトレーニングデータでも、機械学習モデルは信頼性のある結果を生み出すことができる」
研究者は、機械学習モデルが限られた訓練データでも信頼性のある結果を生成できることを示しました

「大規模なラスター人口データの探索」
オンラインで美しい人口地図がよく出回っているのを見かけますが、通常、チュートリアルに表示されている以外の地図セグメントを可視化する、または...というような技術的な部分で詰まってしまいます

「LLaMaをポケットに収めるトリック:LLMの効率とパフォーマンスを結ぶAIメソッド、OmniQuantに出会おう」
大型言語モデル(LLM)は、機械翻訳、テキスト要約、質問応答など、さまざまな自然言語処理タスクで印象的なパフォーマンスを発揮しています。彼らは私たちがコンピュータとコミュニケーションを取る方法やタスクを行う方法を変えてきました。 LLMは、自然言語の理解と生成の限界を押し広げる変革的な存在として現れています。その中でもChatGPTは、会話の文脈でユーザーと対話するために設計されたLLMのクラスを代表する注目すべき例です。これらのモデルは、非常に大きなテキストデータセットでの集中的なトレーニングの結果、人間のようなテキストを理解し生成する能力を持っています。 しかし、これらのモデルは計算とメモリの消費量が多く、実用的な展開を制限しています。その名前が示すように、これらのモデルは大きいです。最新のオープンソースLLMであるMetaのLLaMa2は、約700億のパラメータを含んでいます。 これらの要件を削減することは、より実用的にするための重要なステップです。量子化は、LLMの計算とメモリのオーバーヘッドを削減する有望な技術です。量子化には、トレーニング後の量子化(PTQ)と量子化に対応したトレーニング(QAT)の2つの主要な方法があります。QATは競争力のある精度を提供しますが、計算と時間の両方の面で非常に高価です。そのため、PTQは多くの量子化の試みで主要な方法となっています。 重みのみの量子化や重み活性化の量子化など、既存のPTQ技術は、メモリ消費量と計算オーバーヘッドの大幅な削減を達成しています。ただし、効率的な展開には重要な低ビット量子化で苦労する傾向があります。低ビット量子化におけるこの性能の低下は、手作業での量子化パラメータに依存しているため、最適な結果が得られないことが主な原因です。 それでは、OmniQuantに会いましょう。これはLLM用の画期的な量子化技術であり、特に低ビット設定でさまざまな量子化シナリオで最先端のパフォーマンスを実現し、PTQの時間とデータの効率性を保ちます。 OmniQuantのLLaMaファミリーにおける特徴。出典: https://arxiv.org/pdf/2308.13137.pdf OmniQuantは、元の完全精度の重みを凍結し、一部の学習可能な量子化パラメータを組み込むというユニークなアプローチを取ります。QATとは異なり、煩雑な重みの最適化を必要とせず、OmniQuantは個々のレイヤーに焦点を当てた順次量子化プロセスに焦点を当てています。これにより、単純なアルゴリズムを使用した効率的な最適化が可能になります。 OmniQuantは、学習可能な重みクリッピング(LWC)と学習可能な等価変換(LET)という2つの重要なコンポーネントで構成されています。LWCはクリッピング閾値を最適化し、極端な重み値を調整します。一方、LETはトランスフォーマーエンコーダ内で等価変換を学習することで、アクティベーションの外れ値に対処します。これらのコンポーネントにより、完全精度の重みとアクティベーションを量子化しやすくします。 OmniQuantの柔軟性は、重みのみの量子化や重み活性化の量子化の両方に対応しており、量子化されたモデルには追加の計算負荷やパラメータが必要ありません。なぜなら、量子化パラメータは量子化された重みに融合されるからです。 OmniQuantの概要。出典: https://arxiv.org/pdf/2308.13137.pdf LLM全体のすべてのパラメータを共同で最適化する代わりに、「OmniQuant」は次のレイヤーに移る前に1つのレイヤーのパラメータを順次量子化します。これにより、OmniQuantは単純な確率的勾配降下法(SGD)アルゴリズムを使用して効率的に最適化することができます。 これは実用的なモデルであり、単一のGPU上でも簡単に実装できます。自分自身のLLMを16時間で訓練することができるため、さまざまな実世界のアプリケーションで本当にアクセスしやすくなります。また、OmniQuantは以前のPTQベースの方法よりも優れたパフォーマンスを発揮するため、パフォーマンスを犠牲にすることはありません。 ただし、これはまだ比較的新しい手法であり、パフォーマンスにはいくつかの制約があります。たとえば、フルプレシジョンモデルよりもわずかに悪い結果を生み出すことがある場合があります。しかし、これはOmniQuantの小さな不便さであり、LLMの効率的な展開のための有望な技術です。

コーディングなしで独自のLLMをトレーニングする
イントロダクション 生成AIは、私たちがテクノロジーとコンテンツの生成方法を革新するという魅力的な分野で、世界中で大きな注目を浴びています。この記事では、大規模言語モデル(LLM)の魅力的な領域、その構成要素、クローズドソースLLMがもたらす課題、そしてオープンソースモデルの出現について探求します。さらに、h2oGPTやLLM DataStudioなどのツールやフレームワークを含むH2OのLLMエコシステムについても詳しく説明します。これらのツールとフレームワークにより、コーディングスキルをほとんど必要とせずにLLMをトレーニングすることができます。 学習目標: 大規模言語モデル(LLM)を使用した生成AIの概念と応用を理解する。 クローズドソースLLMの課題とオープンソースモデルの利点を認識する。 コーディングスキルをほとんど必要とせずにAIのトレーニングを行うためのH2OのLLMエコシステムを探索する。 LLMの構成要素:基礎モデルと微調整 LLMの詳細を掘り下げる前に、生成AIの概念を把握しましょう。予測AIが主流であり、過去のデータパターンに基づいて予測に焦点を当てる一方で、生成AIはその逆です。既存のデータセットから新しい情報を生成する能力を機械に与えます。 単一のモデルからテキストを予測・生成し、コンテンツを要約し、情報を分類するなど、さまざまなことができる機械学習モデルを想像してみてください。それが大規模言語モデル(LLM)の役割です。 LLMは、まず基礎モデルから始まる多段階のプロセスに従います。このモデルは、しばしばテラバイトまたはペタバイト単位のデータセット上でトレーニングするため、膨大なデータが必要です。この基礎モデルは、次の単語をシーケンスで予測することにより学習し、データ内のパターンを理解することを目指します。 基礎モデルが確立されたら、次のステップは微調整です。このフェーズでは、キュレートされたデータセットでの教師付き微調整を行い、モデルを所望の動作に適合させます。これには、モデルを特定のタスク(例:多肢選択、分類など)を実行できるようにトレーニングすることが含まれます。 第三のステップである人間のフィードバックに基づく強化学習により、モデルのパフォーマンスをさらに向上させます。人間のフィードバックに基づいた報酬モデルを使用することで、モデルは予測をより人間の好みに合わせて微調整します。これによりノイズが減少し、応答の品質が向上します。 このプロセスの各ステップがモデルのパフォーマンスを向上させ、不確実性を減らすのに寄与しています。なお、基礎モデル、データセット、および微調整戦略の選択は、具体的なユースケースに依存することに注意してください。 クローズドソースLLMの課題とオープンソースモデルの台頭 ChatGPT、Google BardなどのクローズドソースLLMは、効果を示していますが、いくつかの課題も抱えています。これには、データプライバシーへの懸念、カスタマイズと制御の制約、高い運用コスト、時々の利用不可などが含まれます。 組織や研究者は、よりアクセス可能でカスタマイズ可能なLLMの必要性を認識しています。そのため、彼らはオープンソースモデルの開発を始めています。これらのモデルは、コスト効果があり、特定の要件に合わせてカスタマイズすることができます。また、機密データを外部サーバーに送信することへの懸念も解消されます。 オープンソースLLMは、ユーザーにモデルのトレーニングとアルゴリズムの内部動作へのアクセス権を与えます。このオープンなエコシステムは、さまざまなアプリケーションにとって有望なソリューションとなるため、より多くの制御と透明性を提供します。 H2OのLLMエコシステム:コーディング不要のLLMトレーニング用ツールとフレームワーク 機械学習の世界で著名なH2Oは、LLM用の堅牢なエコシステムを開発しました。彼らのツールとフレームワークは、広範なコーディングの専門知識を必要とせずにLLMのトレーニングを容易にします。以下に、これらのコンポーネントのいくつかを紹介します。 h2oGPT h2oGPTは、独自のデータでトレーニングできる微調整済みのLLMです。最高の部分は何でしょうか?完全に無料で使用できます。h2oGPTを使用すると、LLMの実験を行い、商業的にも適用することができます。このオープンソースモデルを使用することで、財務上の障壁なしにLLMの機能を探索できます。 展開ツール…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.