Learn more about Search Results T5 - Page 33

- You may be interested
- メタAIは、「Code Llama」という最先端の...
- 「EUのAI法はAI規制のグローバルスタンダ...
- 仕事を加速するAIツール16選
- アップル M2 Max GPU vs Nvidia V100、P10...
- Amazon SageMaker JumpStartを使用した対...
- 「インテルCPU上での安定したディフューシ...
- 「機械学習の公衆の認識に関する問題」
- 「PythonとMatplotlibを使用して極座標ヒ...
- 「ChatGPT時代の会話支援の未来はどうなる...
- SDFStudio(エスディーエフスタジオ)は、...
- クレジットカードの取引データを使用した...
- QLoRAを使用して、Amazon SageMaker Studi...
- 「メーカーに会う ロボット学生がNVIDIA J...
- AIブームがシリコンバレーを再び変革の狂...
- 「AIが航空会社のコントレイルによる気候...

MTEB 大規模テキスト埋め込みベンチマーク
MTEBは、さまざまな埋め込みタスクでテキスト埋め込みモデルのパフォーマンスを測定するための大規模ベンチマークです。 🥇リーダーボードは、さまざまなタスクで最高のテキスト埋め込みモデルの包括的なビューを提供します。 📝論文は、MTEBのタスクとデータセットについての背景を説明し、リーダーボードの結果を分析しています! 💻Githubリポジトリには、ベンチマークのためのコードとリーダーボードへの任意のモデルの提出が含まれています。 テキスト埋め込みの重要性 テキスト埋め込みは、意味情報をエンコードするテキストのベクトル表現です。コンピュータは計算を行うために数値の入力を必要とするため、テキスト埋め込みは多くのNLPアプリケーションの重要な要素です。たとえば、Googleはテキスト埋め込みを検索エンジンの動力源として使用しています。テキスト埋め込みは、クラスタリングによる大量のテキストのパターン検出や、最近のSetFitのようなテキスト分類モデルへの入力としても使用できます。ただし、テキスト埋め込みの品質は、使用される埋め込みモデルに大きく依存します。MTEBは、さまざまなタスクに対して最適な埋め込みモデルを見つけるのに役立つように設計されています! MTEB 🐋 Massive:MTEBには8つのタスクにわたる56のデータセットが含まれ、現在リーダーボード上の>2000の結果を要約しています。 🌎 Multilingual:MTEBには最大112の異なる言語が含まれています!Bitext Mining、Classification、STSにおいていくつかの多言語モデルをベンチマークにかけました。 🦚 Extensible:新しいタスク、データセット、メトリクス、またはリーダーボードの追加に関しては、どんな貢献も大歓迎です。リーダーボードへの提出やオープンな課題の解決については、GitHubリポジトリをご覧ください。最高のテキスト埋め込みモデルの発見の旅にご参加いただければ幸いです。 MTEBのタスクとデータセットの概要。多言語データセットは紫の色で表示されます。 モデル MTEBの初期ベンチマークでは、最新の結果を謳うモデルやHubで人気のあるモデルに焦点を当てました。これにより、トランスフォーマーの代表的なモデルが多く含まれています。🤖 平均英語MTEBスコア(y)対速度(x)対埋め込みサイズ(円のサイズ)でモデルをグループ化しました。 次の3つの属性にモデルを分類して、タスクに最適なモデルを簡単に見つけることをお勧めします: 🏎 最大速度 Gloveのようなモデルは高速ですが、文脈の理解が不足しており、平均MTEBスコアが低くなります。 ⚖️ 速度とパフォーマンス…

高速なトレーニングと推論 Habana Gaudi®2 vs Nvidia A100 80GB
この記事では、Habana® Gaudi®2を使用してモデルのトレーニングと推論を高速化し、🤗 Optimum Habanaを使用してより大きなモデルをトレーニングする方法について説明します。さらに、BERTの事前トレーニング、Stable Diffusion推論、およびT5-3Bファインチューニングなど、第一世代のGaudi、Gaudi2、およびNvidia A100 80GBのパフォーマンスの違いを評価するためのいくつかのベンチマークを紹介します。ネタバレ注意 – Gaudi2はトレーニングと推論の両方でNvidia A100 80GBよりも約2倍高速です! Gaudi2は、Habana Labsが設計した第2世代のAIハードウェアアクセラレータです。単一のサーバには、各々96GBのメモリを持つ8つのアクセラレータデバイスが搭載されています(第一世代のGaudiでは32GB、A100 80GBでは80GB)。Habana SDKであるSynapseAIは、第一世代のGaudiとGaudi2の両方に共通しています。つまり、🤗 Optimus Habanaは、🤗 Transformersと🤗 DiffusersライブラリとSynapseAIの間の非常に使いやすいインターフェースを提供し、第一世代のGaudiと同じようにGaudi2でも動作します!ですので、既に第一世代のGaudi用の使用準備が整ったトレーニングや推論のワークフローがある場合は、何も変更することなくGaudi2で試してみることをお勧めします。 Gaudi2へのアクセス方法 IntelとHabanaがGaudi2を利用可能にするための簡単で費用効果の高い方法の1つは、Intel Developer Cloudで利用できるようになっています。そこでGaudi2を使用するためには、以下の手順に従う必要があります: Intel…

ストーリーの生成:ゲーム開発のためのAI #5
AIゲーム開発へようこそ!このシリーズでは、AIツールを使用してわずか5日で完全な機能を備えた農業ゲームを作成します。このシリーズの終わりまでに、さまざまなAIツールをゲーム開発のワークフローに取り入れる方法を学ぶことができます。以下のような目的でAIツールを使用する方法をお見せします: アートスタイル ゲームデザイン 3Dアセット 2Dアセット ストーリー クイックビデオバージョンが欲しいですか? こちらでご覧いただけます。それ以外の場合は、技術的な詳細を読み続けてください! 注:この投稿では、ゲームデザインにChatGPTを使用したPart 2への参照がいくつかあります。ChatGPTの動作方法、言語モデルの概要、およびその制限についての追加のコンテキストについては、Part 2をお読みください。 Day 5: ストーリー このチュートリアルシリーズのPart 4では、Stable DiffusionとImage2Imageを2Dアセットのワークフローに使用する方法について説明しました。 この最終パートでは、ストーリーにAIを使用します。まず、農業ゲームのプロセスを説明し、注意すべき⚠️ 制限事項について説明します。次に、ゲーム開発の文脈での関連技術と今後の方向性について話します。最後に、最終的なゲームについてまとめます。 プロセス 要件:このプロセス全体でChatGPTを使用しています。ChatGPTと言語モデリングについての詳細については、シリーズのPart 2をお読みいただくことをおすすめします。ChatGPTは唯一の解決策ではありません。オープンソースの対話エージェントなど、数多くの新興競合他社が存在します。対話エージェントの新興市場についてさらに詳しく学ぶために、先を読んでください。 ChatGPTにストーリーの執筆を依頼します。ゲームに関する多くのコンテキストを提供した後、ChatGPTにストーリーの要約を書いてもらいます。 ChatGPTは、ゲームStardew…

パラメータ効率の高いファインチューニングを使用する 🤗 PEFT
動機 トランスフォーマーアーキテクチャに基づく大規模言語モデル(LLM)であるGPT、T5、BERTなどは、さまざまな自然言語処理(NLP)タスクで最先端の結果を達成しています。これらのモデルは、コンピュータビジョン(CV)(VIT、Stable Diffusion、LayoutLM)やオーディオ(Whisper、XLS-R)などの他の領域にも進出しています。従来のパラダイムは、一般的なWebスケールのデータでの大規模な事前学習に続いて、ダウンストリームのタスクに対する微調整です。ダウンストリームのデータセットでこれらの事前学習済みLLMを微調整することで、事前学習済みLLMをそのまま使用する場合(ゼロショット推論など)と比較して、大幅な性能向上が得られます。 しかし、モデルが大きくなるにつれて、完全な微調整は一般的なハードウェアで訓練することが不可能になります。また、各ダウンストリームタスクごとに微調整済みモデルを独立して保存および展開することは非常に高コストです。なぜなら、微調整済みモデルのサイズは元の事前学習済みモデルと同じサイズだからです。パラメータ効率の良い微調整(PEFT)アプローチは、これらの問題に対処するために開発されました! PEFTアプローチは、事前学習済みLLMのほとんどのパラメータを凍結しながら、わずかな(追加の)モデルパラメータのみを微調整するため、計算およびストレージコストを大幅に削減します。これにより、LLMの完全な微調整中に観察される「壊滅的な忘却」という問題も克服されます。PEFTアプローチは、低データレジメでの微調整よりも優れた性能を示し、ドメイン外のシナリオにもより適応します。これは、画像分類や安定拡散ドリームブースなどのさまざまなモダリティに適用することができます。 また、PEFTアプローチは移植性にも役立ちます。ユーザーはPEFTメソッドを使用してモデルを微調整し、完全な微調整の大きなチェックポイントと比較して数MBの小さなチェックポイントを取得することができます。たとえば、「bigscience/mt0-xxl」は40GBのストレージを使用し、完全な微調整では各ダウンストリームデータセットに40GBのチェックポイントが生成されますが、PEFTメソッドを使用すると、各ダウンストリームデータセットにはわずか数MBのチェックポイントでありながら、完全な微調整と同等の性能が得られます。PEFTアプローチからの小さなトレーニング済み重みは、事前学習済みLLMの上に追加されます。そのため、モデル全体を置き換えることなく、小さな重みを追加することで同じLLMを複数のタスクに使用することができます。 つまり、PEFTアプローチは、わずかなトレーニング可能なパラメータの数だけで完全な微調整と同等のパフォーマンスを実現できるようにします。 本日は、🤗 PEFTライブラリをご紹介いたします。このライブラリは、最新のパラメータ効率の良い微調整技術を🤗 Transformersと🤗 Accelerateにシームレスに統合しています。これにより、Transformersの最も人気のあるモデルを使用し、Accelerateのシンプルさとスケーラビリティを活用することができます。以下は現在サポートされているPEFTメソッドですが、今後も追加される予定です: LoRA:LORA:大規模言語モデルの低ランク適応 Prefix Tuning:P-Tuning v2:プロンプトチューニングは、スケールとタスクにわたって完全な微調整と同等の性能を発揮することができます Prompt Tuning:パラメータ効率の良いプロンプトチューニングの力 P-Tuning:GPTも理解しています ユースケース ここでは多くの興味深いユースケースを探求しています。以下はいくつかの興味深い例です: Google Colabで、Nvidia GeForce RTX…
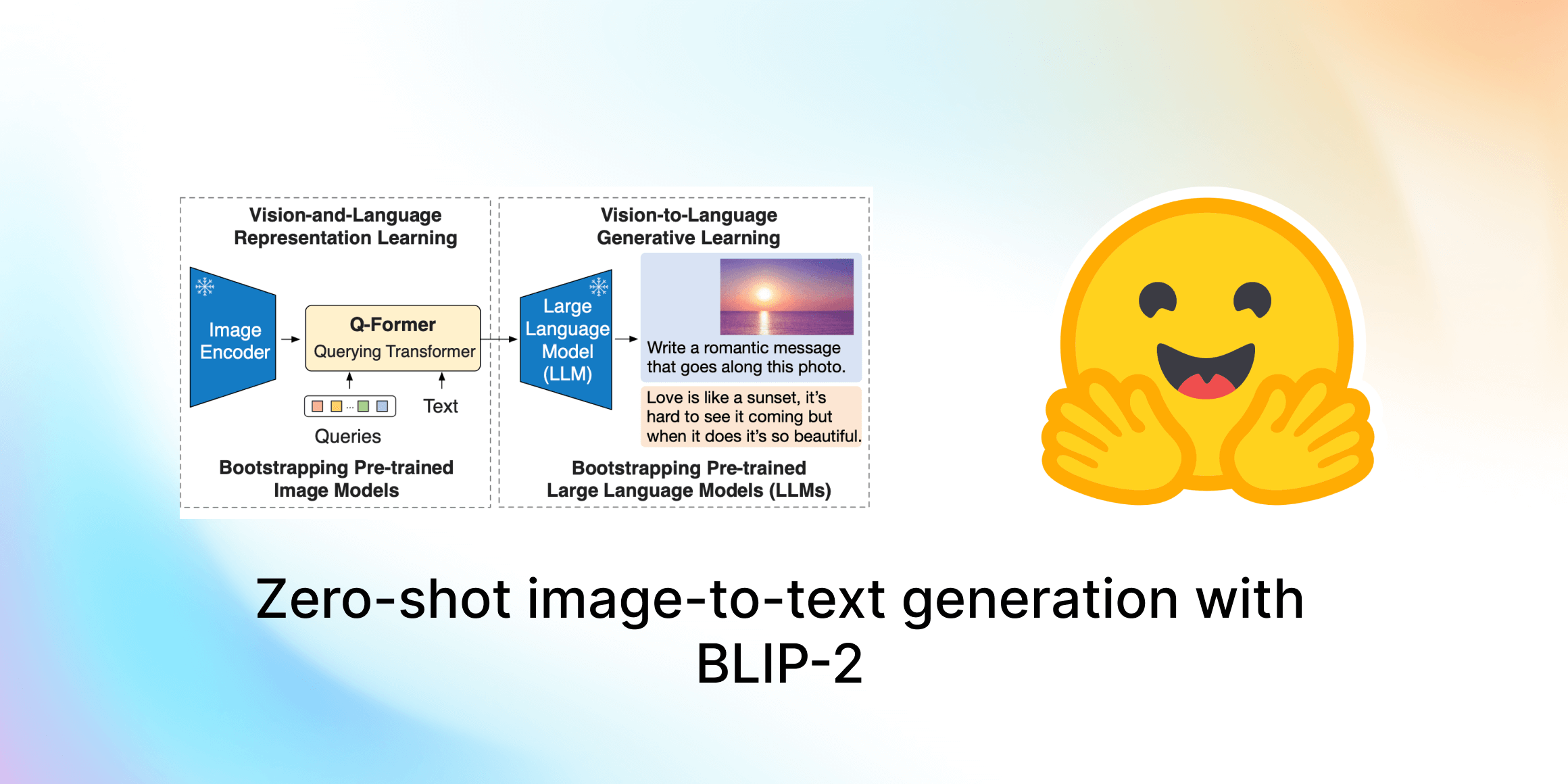
ゼロショット画像からテキスト生成 BLIP-2
このガイドでは、Salesforce ResearchのBLIP-2を紹介します。これは最先端のビジュアル言語モデルのスイートで、現在は🤗 Transformersで利用可能です。画像キャプショニング、プロンプト付き画像キャプショニング、ビジュアルな質問応答、チャットベースのプロンプトに使用する方法を紹介します。 目次 はじめに BLIP-2の内部構造は? Hugging Face TransformersでのBLIP-2の使用 画像キャプショニング プロンプト付き画像キャプショニング ビジュアルな質問応答 チャットベースのプロンプト 結論 謝辞 はじめに 近年、コンピュータビジョンと自然言語処理の分野で急速な進歩がありました。しかし、多くの現実世界の問題は本質的にマルチモーダルです。つまり、画像やテキストなど、複数の異なる形式のデータを含みます。ビジュアル言語モデルは、異なるモダリティを組み合わせることで、さまざまなアプリケーションの可能性を広げるという課題に直面しています。ビジュアル言語モデルが取り組むことができる画像からテキストへのタスクには、画像キャプショニング、画像テキスト検索、ビジュアルな質問応答などがあります。画像キャプショニングは視覚障害者の支援、有用な商品説明の作成、テキスト以外の不適切なコンテンツの特定などに役立ちます。画像テキスト検索はマルチモーダルな検索や自動運転などのアプリケーションに適用することができます。ビジュアルな質問応答は教育に役立ち、マルチモーダルなチャットボットを可能にし、さまざまなドメイン固有の情報検索アプリケーションを支援します。 現代のコンピュータビジョンと自然言語モデルは、より優れた性能を持つ一方で、以前のモデルと比べて大幅にサイズが増えています。単一のモダリティモデルの事前学習はリソースを消費し、高コストですが、ビジョンと言語のエンドツーエンドの事前学習のコストはますます高くなっています。BLIP-2は、事前学習済みのビジョンエンコーダとLLMの組み合わせを活用し、アーキテクチャ全体をエンドツーエンドで事前学習する必要なく、新しいビジュアル言語の事前学習パラダイムを導入することで、この課題に取り組んでいます。これにより、複数のビジュアル言語タスクで最先端の結果を実現しながら、訓練可能なパラメータの数と事前学習コストを大幅に削減することができます。さらに、この手法はマルチモーダルなChatGPTのモデルへの道を切り拓きます。 BLIP-2の内部構造は? BLIP-2は、既製の凍結された事前学習済み画像エンコーダと凍結された大規模言語モデルの間に、軽量なクエリングトランスフォーマ(Q-Former)を追加することで、ビジョンと言語モデルのモダリティのギャップを埋めます。Q-FormerはBLIP-2の唯一の訓練可能な部分であり、画像エンコーダと言語モデルは凍結されたままです。 Q-Formerは、2つのサブモジュールからなるトランスフォーマモデルであり、同じセルフアテンションレイヤを共有しています: 画像トランスフォーマは、入力画像の解像度に関係なく、固定数の出力特徴を画像エンコーダから抽出し、学習可能なクエリ埋め込みを入力として受け取ります。クエリは同じセルフアテンションレイヤを介してテキストとも相互作用できます。 テキストトランスフォーマは、テキストエンコーダおよびテキストデコーダとして機能することができます。 画像トランスフォーマは、入力画像の解像度に関係なく、固定数の出力特徴を画像エンコーダから抽出し、学習可能なクエリ埋め込みを入力として受け取ります。クエリは同じセルフアテンションレイヤを介してテキストとも相互作用できます。…

24GBのコンシューマーGPUでRLHFを使用して20B LLMを微調整する
私たちは、trlとpeftの統合を正式にリリースし、Reinforcement Learningを用いたLarge Language Model (LLM)のファインチューニングを誰でも簡単に利用できるようにしました!この投稿では、既存のファインチューニング手法と競合する代替手法である理由を説明します。 peftは一般的なツールであり、多くのMLユースケースに適用できますが、特にメモリを多く必要とするRLHFにとって興味深いです! コードに直接深く入りたい場合は、TRLのドキュメンテーションページで直接例のスクリプトをチェックしてください。 イントロダクション LLMとRLHF 言語モデルとRLHF(Reinforcement Learning with Human Feedback)を組み合わせることは、ChatGPTなどの非常に強力なAIシステムを構築するための次の手段として注目されています。 RLHFを用いた言語モデルのトレーニングは、通常以下の3つのステップを含みます: 1- 特定のドメインまたは命令のコーパスで事前学習されたLLMをファインチューニングする 2- 人間によって注釈付けされたデータセットを収集し、報酬モデルをトレーニングする 3- ステップ1で得られたLLMを報酬モデルとデータセットを用いてRL(例:PPO)でさらにファインチューニングする ここで、ベースとなるLLMの選択は非常に重要です。現時点では、多くのタスクに直接使用できる「最も優れた」オープンソースのLLMは、命令にファインチューニングされたLLMです。有名なモデルとしては、BLOOMZ、Flan-T5、Flan-UL2、OPT-IMLなどがあります。これらのモデルの欠点は、そのサイズです。まともなモデルを得るには、少なくとも10B+スケールのモデルを使用する必要がありますが、モデルを単一のGPUデバイスに合わせるだけでも40GBのGPUメモリが必要です。 TRLとは何ですか? trlライブラリは、カスタムデータセットとトレーニングセットアップを使用して、誰でも簡単に自分のLMをRLでファインチューニングできるようにすることを目指しています。他の多くのアプリケーションの中で、このアルゴリズムを使用して、ポジティブな映画のレビューを生成するモデルをファインチューニングしたり、制御された生成を行ったり、モデルをより毒性のないものにしたりすることができます。…
AWS Inferentia2を使用してHugging Face Transformersを高速化する
過去5年間、Transformerモデル[1]は、自然言語処理(NLP)、コンピュータビジョン(CV)、音声など、多くの機械学習(ML)タスクのデファクトスタンダードとなりました。今日、多くのデータサイエンティストやMLエンジニアは、BERT[2]、RoBERTa[3]、Vision Transformer[4]などの人気のあるTransformerアーキテクチャ、またはHugging Faceハブで利用可能な130,000以上の事前学習済みモデルを使用して、最先端の精度で複雑なビジネス問題を解決するために頼っています。 しかし、その優れた性能にもかかわらず、Transformerは本番環境での展開には困難を伴うことがあります。モデル展開に通常関連するインフラストラクチャの設定に加えて、我々はInference Endpointsサービスで大部分の問題を解決しましたが、Transformerは通常、数ギガバイトを超える大きなモデルです。GPT-J-6B、Flan-T5、Opt-30Bなどの大規模言語モデル(LLM)は数十ギガバイトであり、BLOOMなどの巨大なモデルは350ギガバイトもあります。 これらのモデルを単一のアクセラレータに適合させることは非常に困難ですし、会話型アプリケーションや検索のようなアプリケーションが必要とする高スループットと低推論レイテンシを実現することはさらに難しいです。MLの専門家たちは、大規模モデルをスライスし、アクセラレータクラスタに分散させ、レイテンシを最適化するために複雑な手法を設計してきました。残念ながら、この作業は非常に困難で時間がかかり、多くのMLプラクティショナーには到底手の届かないものです。 Hugging Faceでは、MLの民主化を進めるとともに、すべての開発者と組織が最先端のモデルを利用できるようにすることを目指しています。そのため、今回はAmazon Web Servicesと提携し、Hugging Face TransformersをAWS Inferentia 2に最適化することに興奮しています!これは、前例のないスループット、レイテンシ、パフォーマンス、スケーラビリティを提供する新しい特別な推論アクセラレータです。 AWS Inferentia2の紹介 AWS Inferentia2は、2019年に発売されたInferentia1の次世代です。Inferentia1のパワーにより、Amazon EC2 Inf1インスタンスは、NVIDIA A10G GPUをベースとしたG5インスタンスと比較して、スループットが25%向上し、コストが70%削減されました。そして、Inferentia2により、AWSは再び限界を em>押し広げています。 新しいInferentia2チップは、Inferentiaと比較してスループットが4倍向上し、レイテンシが10倍低下します。同様に、新しいAmazon…

フリーティアのGoogle Colabで🧨ディフューザーを使用してIFを実行中
要約:Google Colabの無料ティア上で最も強力なオープンソースのテキストから画像への変換モデルIFを実行する方法を紹介します。 また、Hugging Face Spaceでモデルの機能を直接探索することもできます。 公式のIF GitHubリポジトリから圧縮された画像。 はじめに IFは、ピクセルベースのテキストから画像への生成モデルで、DeepFloydによって2023年4月下旬にリリースされました。モデルのアーキテクチャは、GoogleのクローズドソースのImagenに強く影響を受けています。 IFは、Stable Diffusionなどの既存のテキストから画像へのモデルと比較して、次の2つの利点があります: モデルは、レイテントスペースではなく「ピクセルスペース」(つまり、非圧縮画像上で)で直接動作し、Stable Diffusionのようなノイズ除去プロセスを実行しません。 モデルは、Stable Diffusionでテキストエンコーダとして使用されるCLIPよりも強力なテキストエンコーダであるT5-XXLの出力で訓練されます。 その結果、IFは高周波の詳細(例:人の顔や手など)を持つ画像を生成する能力に優れており、信頼性のあるテキスト付き画像を生成できる最初のオープンソースの画像生成モデルです。 ピクセルスペースで動作し、より強力なテキストエンコーダを使用することのデメリットは、IFが大幅に多くのパラメータを持っていることです。T5、IFのテキストから画像へのUNet、IFのアップスケーラUNetは、それぞれ4.5B、4.3B、1.2Bのパラメータを持っています。それに対して、Stable Diffusion 2.1のテキストエンコーダとUNetは、それぞれ400Mと900Mのパラメータしか持っていません。 しかし、メモリ使用量を低減させるためにモデルを最適化すれば、一般のハードウェア上でもIFを実行することができます。このブログ記事では、🧨ディフューザを使用してその方法を紹介します。 1.)では、テキストから画像への生成にIFを使用する方法を説明し、2.)と3.)では、IFの画像バリエーションと画像インペインティングの機能について説明します。 💡 注意:メモリの利得と引き換えに速度の利得を得るために、IFを無料ティアのGoogle Colab上で実行できるようにしています。A100などの高性能なGPUにアクセスできる場合は、公式のIFデモのようにすべてのモデルコンポーネントをGPU上に残して、最大の速度で実行することをお勧めします。…

Instruction-tuning Stable Diffusion with InstructPix2PixのHTMLを日本語に翻訳してください
この投稿では、安定拡散を教えるための指示調整について説明します。この方法では、入力画像と「指示」(例:自然画像に漫画フィルタを適用する)を使用して、安定拡散を促すことができます。 ユーザーの指示に従って安定拡散に画像編集を実行させるアイデアは、「InstructPix2Pix: Learning to Follow Image Editing Instructions」で紹介されました。InstructPix2Pixのトレーニング戦略を拡張して、画像変換(漫画化など)や低レベルな画像処理(画像の雨除去など)に関連するより具体的な指示に従う方法について説明します。以下をカバーします: 指示調整の紹介 この研究の動機 データセットの準備 トレーニング実験と結果 潜在的な応用と制約 オープンな問い コード、事前学習済みモデル、データセットはこちらで見つけることができます。 導入と動機 指示調整は、タスクを解決するために言語モデルに指示を従わせる教師ありの方法です。Googleの「Fine-tuned Language Models Are Zero-Shot Learners (FLAN)」で紹介されました。最近では、AlpacaやFLAN V2などの作品が良い例であり、指示調整がさまざまなタスクにどれだけ有益であるかを示しています。…

bitsandbytes、4ビットの量子化、そしてQLoRAを使用して、LLMをさらに利用しやすくする
LLMは大きいことで知られており、一般のハードウェア上で実行またはトレーニングすることは、ユーザーにとって大きな課題であり、アクセシビリティも困難です。私たちのLLM.int8ブログポストでは、LLM.int8論文の技術がtransformersでどのように統合され、bitsandbytesライブラリを使用しているかを示しています。私たちは、モデルをより多くの人々にアクセス可能にするために、再びbitsandbytesと協力することを決定し、ユーザーが4ビット精度でモデルを実行できるようにしました。これには、テキスト、ビジョン、マルチモーダルなどの異なるモダリティの多くのHFモデルが含まれます。ユーザーはまた、Hugging Faceのエコシステムからのツールを活用して4ビットモデルの上にアダプタをトレーニングすることもできます。これは、DettmersらによるQLoRA論文で今日紹介された新しい手法です。論文の概要は以下の通りです: QLoRAは、1つの48GBのGPUで65Bパラメータモデルをフィントゥーニングするためのメモリ使用量を十分に削減しながら、完全な16ビットのフィントゥーニングタスクのパフォーマンスを維持する効率的なフィントゥーニングアプローチです。QLoRAは、凍結された4ビット量子化された事前学習言語モデルをLow Rank Adapters(LoRA)に逆伝搬させます。私たちの最高のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達しますが、1つのGPUでのフィントゥーニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています:(a)通常分布された重みに対して情報理論的に最適な新しいデータ型である4ビットNormalFloat(NF4)(b)量子化定数を量子化して平均メモリフットプリントを減らすためのダブル量子化、および(c)メモリスパイクを管理するためのページドオプティマイザ。私たちはQLoRAを使用して1,000以上のモデルをフィントゥーニングし、高品質のデータセットを使用した指示の追跡とチャットボットのパフォーマンスの詳細な分析を提供しています。これは通常のフィントゥーニングでは実行不可能である(例えば33Bおよび65Bパラメータモデル)モデルタイプ(LLaMA、T5)とモデルスケールを横断したものです。私たちの結果は、QLoRAによる小規模な高品質データセットでのフィントゥーニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。さらに、ヒューマンとGPT-4の評価に基づいてチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価がヒューマンの評価に対して安価で合理的な代替手段であることを示しています。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するための信頼性がないことがわかります。レモンピックされた分析では、GuanacoがChatGPTに比べてどこで失敗するかを示しています。私たちは4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 リソース このブログポストとリリースには、4ビットモデルとQLoRAを始めるためのいくつかのリソースがあります: 元の論文 基本的な使用法Google Colabノートブック-このノートブックでは、4ビットモデルとその変種を使用した推論の方法、およびGoogle ColabインスタンスでGPT-neo-X(20Bパラメータモデル)を実行する方法を示しています。 フィントゥーニングGoogle Colabノートブック-このノートブックでは、Hugging Faceエコシステムを使用してダウンストリームタスクで4ビットモデルをフィントゥーニングする方法を示しています。Google ColabインスタンスでGPT-neo-X 20Bをフィントゥーニングすることが可能であることを示しています。 論文の結果を再現するための元のリポジトリ Guanaco 33b playground-または以下のプレイグラウンドセクションをチェック はじめに モデルの精度と最も一般的なデータ型(float16、float32、bfloat16、int8)について詳しく知りたくない場合は、これらの概念の詳細について視覚化を含めた簡単な言葉で説明している私たちの最初のブログポストの紹介を注意深くお読みいただくことをお勧めします。 詳細については、このwikibookドキュメントを通じて浮動小数点表現の基本を読むことをお勧めします。 最近のQLoRA論文では、4ビットFloatと4ビットNormalFloatという異なるデータ型を探求しています。ここでは、理解しやすい4ビットFloatデータ型について説明します。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.