Learn more about Search Results ML - Page 333

- You may be interested
- 「AIプログラムがイスラエルの男性の命を...
- 「IDEFICSをご紹介します:最新の視覚言語...
- 「AIおよびARはデータ需要を推進しており...
- 「2023年に知っておく必要のあるトップ10...
- ソフトウェア開発のパラダイムシフト:GPT...
- Relume AIによって生成されたワイヤーフレ...
- 「FourCastNet(フォーキャストネット)と...
- 「言語モデルにアルゴリズム的な推論を教...
- 「ディープラーニングにおける転移学習と...
- Link-credible:Steam、Epic Games Store...
- AWSが開発した目的に特化したアクセラレー...
- テックの雇用削減はAI産業について何を示...
- 室温超伝導体であることが確認されたLK-99...
- 「Googleのジェミニを使い始める方法はこ...
- Pythonにおける型ヒント

「Amazon LexをLLMsで強化し、URLの取り込みを使用してFAQの体験を向上させる」
「現代のデジタル世界では、ほとんどの消費者は、ビジネスやサービスプロバイダに問い合わせるために時間をかけるよりも、自分自身でカスタマーサービスの質問に対する回答を見つけることを好む傾向にありますこのブログ記事では、ウェブサイトの既存のFAQを使用して、Amazon Lexで質問応答チャットボットを構築する革新的なソリューションについて探求します[...]」

「LLMを使用して、会話型のFAQ機能を搭載したAmazon Lexを強化する」
Amazon Lexは、Amazon Connectなどのアプリケーションのために、会話ボット(「チャットボット」)、バーチャルエージェント、およびインタラクティブ音声応答(IVR)システムを迅速かつ簡単に構築できるサービスです人工知能(AI)と機械学習(ML)は、Amazonの20年以上にわたる焦点であり、顧客が利用する多くの機能の一部です
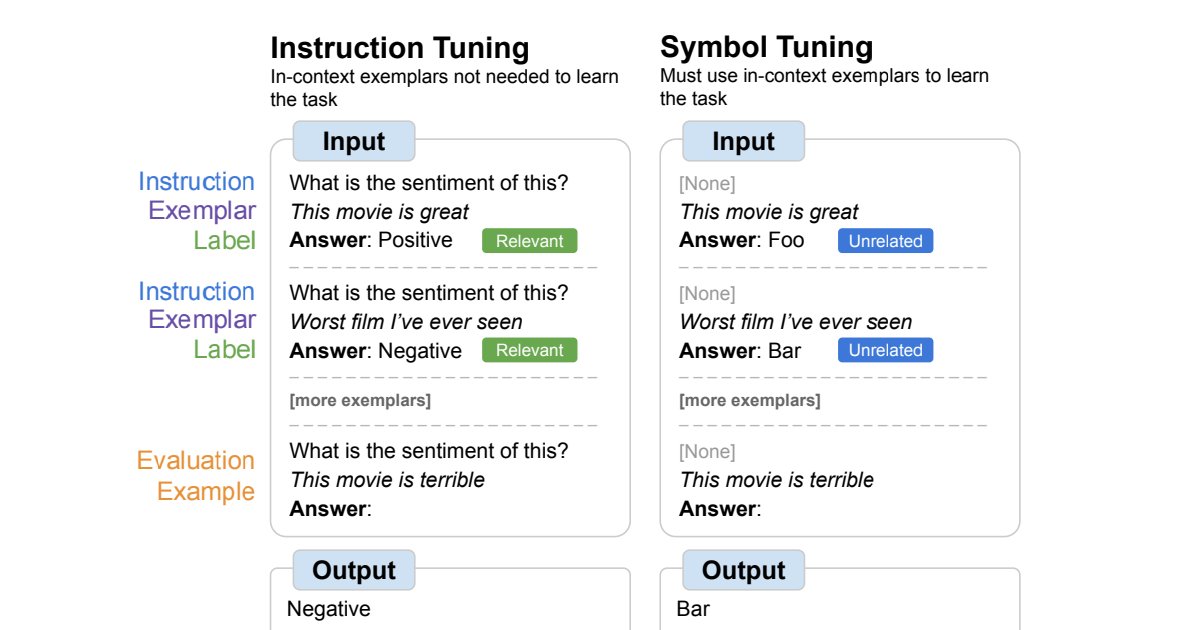
シンボルの調整は言語モデルの文脈における学習を向上させます
Google Researchの学生研究者であるJerry Weiと主任科学者のDenny Zhouによって投稿されました。 人間の知性の重要な特徴の一つは、わずかな例だけを用いて推論することで新しいタスクを学ぶことができることです。言語モデルのスケーリングによって、マシンラーニングにおいて新たな応用やパラダイムを実現することができました。しかし、言語モデルはプロンプトの与え方に敏感であり、頑健な推論を行っているわけではないことを示しています。例えば、言語モデルはしばしばプロンプトエンジニアリングやタスクの指示としてのフレーズのような作業が必要であり、不正確なラベルが表示されてもタスクのパフォーマンスに影響を与えないという予期しない振る舞いを示すことがあります。 「Symbol tuning improves in-context learning in language models」では、シンボルチューニングと呼ばれるシンプルなファインチューニング手法を提案しています。この手法は入力とラベルのマッピングを強調することで、インコンテキスト学習を改善することができます。私たちはFlan-PaLMモデルにおけるシンボルチューニングの実験を行い、さまざまな設定での利点を観察しました。 シンボルチューニングは、未知のインコンテキスト学習タスクにおいてパフォーマンスを向上させ、指示や自然言語のラベルがないような曖昧なプロンプトに対しても非常に頑健です。 シンボルチューニングされたモデルは、アルゴリズムの推論タスクにおいて非常に強力です。 最後に、シンボルチューニングされたモデルは、インコンテキストで提示された反転したラベルを追従する能力が大幅に向上しており、インコンテキスト情報を使用して以前の知識を上書きすることができます。 シンボルチューニングの概要。モデルは自然言語のラベルが任意のシンボルに置き換えられたタスクでファインチューニングされます。シンボルチューニングは、指示や関連するラベルが利用できない場合、モデルがインコンテキストの例を使用してタスクを学ぶ必要があるという直感に基づいています。 動機 指示チューニングは一般的なファインチューニング手法であり、パフォーマンスを向上させ、モデルがインコンテキストの例に従う能力を改善することが示されています。ただし、評価例に指示と自然言語のラベルを通じてタスクが冗長に定義されるため、モデルは例を使用する必要がありません。例えば、上の図の左側では、例がモデルがタスク(感情分析)を理解するのに役立つことができますが、モデルは例を無視してタスクを示す指示を読むことができます。 シンボルチューニングでは、モデルは指示が削除され、自然言語のラベルが意味的に関連のないラベル(例:「Foo」、「Bar」など)に置き換えられた例でファインチューニングされます。この設定では、インコンテキストの例を見ないとタスクが明確になりません。例えば、上の図の右側では、タスクを理解するために複数のインコンテキストの例が必要です。シンボルチューニングはモデルにインコンテキストの例を推論することを教えるため、シンボルチューニングされたモデルは、インコンテキストの例とそのラベルの間の推論を必要とするタスクにおいてより優れたパフォーマンスを発揮するはずです。 シンボルチューニングに使用されるデータセットとタスクの種類。 シンボル調整手順 私たちは、シンボル調整手順に使用するために、22の公開されている自然言語処理(NLP)データセットを選択しました。これらのタスクは過去に広く使用されており、私たちは離散的なラベルを必要とするため、分類タイプのタスクのみを選択しました。その後、ラベルを整数、文字の組み合わせ、および単語の3つのカテゴリから選択された約30,000の任意のラベルの1つにランダムにマッピングします。 実験では、PaLMの指示に調整されたバリアントであるFlan-PaLMをシンボル調整します。Flan-PaLMモデルの3つの異なるサイズを使用します:Flan-PaLM-8B、Flan-PaLM-62B、およびFlan-PaLM-540B。また、Flan-cont-PaLM-62B(780Bトークンではなく1.3TトークンでのFlan-PaLM-62B)もテストし、62B-cと略称します。…

「サンノゼは歩行者の交通事故死を防ぐために人工知能を活用する方法をここで紹介します」
「AIは、先週末に発生したひき逃げ事故で2人の命が失われた都市において、交通事故や歩行者の死亡について話す際には、貴重なツールと考えられるかもしれません」

「ポッドキャスティングのためのトップAIツール(2023年)」
ポディウム ポディウムと呼ばれるAIパワードの技術は、ポッドキャストのポストプロダクションを大幅に加速することを意図しています。この技術により、トランスクリプト、ハイライト、チャプター、エピソードの要約を迅速に作成することができます。 このアプリケーションは使いやすく、アカウントの作成は必要ありません。必要なのはオーディオファイルを提出するだけです。ポディウムのAIは迅速に引用可能な箇所を見つけ出し、チャプターやタイトルを作成し、エピソードの要約を提供します。これらは簡単にソーシャルメディアで共有することができます。 また、アクセシビリティと検索エンジン最適化のために優れたトランスクリプトも提供されます。このアプリケーションは最初は無料ですが、一度に多くのエピソードを扱う必要がある場合は、安価な使用料金または特別な価格設定に変更されます。 リスナー.fm リスナー.fmのAIツールは、AIを活用したショーノート、タイトル、および説明の作成を通じて、ポッドキャストのポストプロダクションを改善することを目的としています。オーディオ録音を提出すると、AIが各オーディオエピソードに合わせた魅力的で注意を引くタイトル、説明、およびショーノートを作成します。このアプリケーションは、人間の介入なしで興味深く教育的なコンテンツを簡単に作成することができます。 このAIツールにより、すべてのポッドキャスターはオーディオファイルを簡単に管理し、コンテンツを改善し、視聴者を増やすことができます。このツールは使いやすく効果的であり、迅速かつ高品質なポストプロダクションを保証します。プラットフォームでは透明な価格設定、新機能への早期アクセス、カスタマーサポート、簡単な価格オプションを提供しています。これはアマチュア、プロ、ポッドキャストネットワークにも適しています。 ショーノート AIパワードのショーノートは、各ポッドキャストエピソードを自動的に要約し、トランスクリプトとキャプションファイルを含むランディングページを生成します。chatGPTを使用してYouTubeの自動キャプションを変換し、魅力的な引用を生成し、トランスクリプトをブログ投稿に変換することができます。 ショーノートが提供する3つのオプションは、無料プラン、クリエータープラン、およびプロプランです。無料プランには1つのショーノート、要約されたトランスクリプト、ランディングページ、および一般に公開されているすべてのショーが含まれています。 クリエータープランには毎月2つのショーノート、要約されたトランスクリプト、ランディングページ、ショーを非公開にするオプション、ランディングページエディター、完全なトランスクリプト、umsとahsが含まれています。 プロプランには無制限のショーノート、要約されたトランスクリプト、ランディングページ、ショーを非公開にするオプション、ランディングページエディター、完全なトランスクリプト、umsとahs、キャプションファイルが含まれています。 キャストマジック キャストマジックと呼ばれるAIパワードの技術は、ポッドキャスターが時間を節約し、高品質のコンテンツを作成するのに役立ちます。これにより、トランスクリプト、ショーノート、要約、ハイライト、引用、ソーシャルメディアの投稿など、公開の準備が整ったテキストにオーディオを変換できます。骨の折れるポストプロダクションの作業を自動化し、ポッドキャスターが高品質のオーディオコンテンツの制作に集中できるようにします。また、ZoomとSlackと互換性があります。 キャストマジックは、Chrome、Safari、Firefox、Windows、Linux、およびmacOSと互換性のある使いやすいプログラムで、コーディングは必要ありません。また、ユーザーは無料のトライアル期間中にプラットフォームを試すことができます。キャストマジックを使用することで、ポッドキャスターは毎週20時間以上の時間を節約できるだけでなく、リスナーごとに個別化されたコンテンツを生成することができます。特定のユーザーにカスタマイズされたダイナミックなウェブサイト体験を提供することは、ポッドキャストの露出を向上させ、収益を最適化するのに役立ちます。 Mood AI 強力なMood AIジェネレーティブポッドキャストマーケティングキットの助けを借りて、ポッドキャスターは大規模な視聴者に自分のコンテンツを届けることができます。ポッドキャストエピソードに基づいて、ジェネレーティブAIを使用して包括的なトランスクリプト、要約、キーワード、簡単な説明、重要なトピック、タイトル、ブログ投稿、ソーシャルメディアの投稿、ビデオクリップなどを自動的に作成します。 迅速なコンテンツとマーケティング資材の生成、およびコンテンツの効果を追跡することで、ポッドキャスト制作者はより広い視聴者を引き付けるのが簡単になります。 Adobe Podcast Adobe Podcastは、AIの機能を備えたオンラインのオーディオ録音および編集ツールです。オーディオの作成を簡素化するために、テキストへのオーディオ変換、ノイズリダクションなど、さまざまな機能を提供しています。ユーザーは、このプラットフォーム上で簡単かつ効果的にオーディオコンテンツを制作、編集、配布することができます。AIパワードのツールにより、Adobe…

OpenAIを使用してカスタムチャットボットを開発する
はじめに チャットボットは自動化されたサポートと個別の体験を提供し、ビジネスが顧客とつながる方法を革新しました。人工知能(AI)の最新の進展により、チャットボットの機能性の基準が引き上げられました。この詳細な書籍では、強力な言語モデルで知られるAIプラットフォームのリーディングカンパニーであるOpenAIを使用してカスタムチャットボットを作成するための詳細な手順が提供されています。 この記事はData Science Blogathonの一環として公開されました。 チャットボットとは何ですか? チャットボットは人間の会話を模倣するコンピュータプログラムです。自然言語処理(NLP)の技術を使用して、ユーザーの言っていることを理解し、関連性のある助言を提供します。 大量のデータセットと優れた機械学習アルゴリズムの利用可能性により、チャットボットは近年ますます賢くなっています。これらの機能により、チャットボットはユーザーの意図をより良く把握し、より本物らしい返答を提供することができます。 チャットボットの具体的な利用例: 顧客サービスのチャットボットは、よく寄せられる質問に答えて、消費者に24時間体制でサポートを提供します。 マーケティングのチャットボットは、リードの質を確認し、リードを生成し、製品やサービスに関する質問に答えるのを支援することができます。 教育のチャットボットは、個別指導を提供し、学生が自分のペースで学ぶことができるようにします。 医療のチャットボットは、健康に関する情報を提供し、薬に関する質問に答え、患者を医師や他の医療専門家とつなげることができます。 OpenAIの紹介 OpenAIは人工知能の研究開発の最前線にあります。自然言語の解釈と生成に優れた言語モデルの開発に先駆けて取り組んでいます。 OpenAIは、GPT-4、GPT-3、Text-davinciなどの高度な言語モデルを提供しており、チャットボットの構築などのNLP活動に広く使用されています。 チャットボットの利点 コーディングと実装に入る前に、チャットボットの利点を理解しましょう。 24時間365日の利用可能性: チャットボットはユーザーに24時間体制でサポートを提供し、人間の顧客サービス担当者の制約をなくし、ビジネスが顧客の要求に対応できるようにします。 改善された顧客サービス: チャットボットは頻繁に問い合わせられる質問に迅速かつ正確に応答することができます。これにより、顧客サービス全体の品質が向上します。 コスト削減: ビジネスは顧客サポートの業務を自動化し、大規模なサポートスタッフの必要性を減らすことで、長期的に多額の費用を節約することができます。…
「PythonでPandasを使うための包括的なガイド」
データ分析、エンジニアリング、または科学の文脈でPythonを使用し始めるとき、おそらく最初に学ぶべきライブラリの1つがpandasですこの素晴らしいライブラリは…

「2023年に知っておく必要のあるトップ10のディープラーニングツール」
コンピュータと人工知能の世界の複雑な問題には、ディープラーニングツールの支援が必要です。課題は時間とともに変化し、分析パターンも変わります。問題に対処するためのツールの定期的な更新と新しい視点には、実地の専門知識とディープラーニングツールの経験が必要です。トップツールの更新されたリストと各ツールの主な機能を確認してください。 ディープラーニングとは何ですか? ディープラーニングは、機械学習のサブセットであり、コンピュータの操作学習に重要な人工知能の一部です。関連するディープラーニングツールは、コンピュータのデータとパターンを処理して意思決定を行うプログラムのキュレーションを担当しています。アルゴリズムによる予測分析が可能です。 トップ10のビッグデータツール ビッグデータツールは、従来のシステムでは効率的に処理できない大量のデータを扱うために不可欠です。これらのツールを活用することで、企業はデータに基づいた意思決定を行い、競争力を持ち、全体的な業務効率を向上させることができます。以下はトップ10のビッグデータツールです: TensorFlow Keras PyTorch OpenNN CNTK MXNet DeeplearningKit Deeplearning4J Darknet PlaidML TensorFlow 主な機能: TensorFlowは、Go、Java、Pythonなどの異なる言語でインターフェースを提供しています。 グラフィックの可視化を可能にします。 組み込みおよびモバイルデバイスを含む、ビルドおよび展開のためのモデルを含んでいます。 コミュニティのサポート 効率的なドキュメンテーション機能 コンピュータビジョン、テキスト分類、画像処理、音声認識が可能です。 多層の大規模なニューラルネットワークに適しています。…

Google AIは、環境の多様性と報酬の指定の課題に対処するための、普遍的なポリシー(UniPi)を提案します
産業に関係なく、人々の生活の質を向上させるために、人工知能(AI)と機械学習(ML)技術は常に取り組んできました。最近のAIの主要な応用の一つは、さまざまなドメインで意思決定タスクを達成できるエージェントを設計・作成することです。たとえば、GPT-3やPaLMのような大規模言語モデルや、CLIPやFlamingoのようなビジョンモデルは、それぞれの分野でゼロショット学習に優れていることが証明されています。しかし、このようなエージェントの訓練には、1つの主要な欠点があります。それは、このようなエージェントが訓練中に環境の多様性を示すという固有の特性を持つためです。単純に言えば、異なるタスクや環境のための訓練は、時折学習や知識の移転、モデルの領域間の一般化能力を妨げるため、さまざまな状態空間の使用を必要とします。さらに、強化学習(RL)ベースのタスクでは、特定のタスクのための報酬関数を作成することが困難になります。 この問題に取り組んで、Google Researchのチームは、このようなツールがより汎用性のあるエージェントの構築に使用できるかどうかを調査しました。彼らの研究では、チームは特にテキストガイドの画像合成に焦点を当て、テキストの形で目標をプランナーに与え、意図した行動のシーケンスを生成し、その後生成されたビデオから制御アクションを抽出する方法を提案しました。したがって、Googleチームは、最近の論文で「テキストガイドされたビデオ生成によるユニバーサルポリシーの学習」と題された論文で、環境の多様性と報酬の指定の課題に取り組むためのユニバーサルポリシー(UniPi)を提案しました。UniPiポリシーは、テキストをタスクの説明のためのユニバーサルなインターフェースとし、ビデオをさまざまな状況でのアクションと観察の振る舞いを伝えるためのユニバーサルなインターフェースとして使用します。具体的には、チームは、ビデオジェネレータをプランナーとして設計し、現在の画像フレームと現在の目標を示すテキストプロンプトを入力として、画像シーケンスまたはビデオの形で軌跡を生成します。生成されたビデオは、その後、実行される基礎となるアクションを抽出する逆ダイナミクスモデルに入力されます。このアプローチは、言語とビデオの普遍性を利用して、新しい目標や異なる環境に対して一般化することができるという点で特筆すべきです。 ここ数年、テキストガイドの画像合成の分野で著しい進歩が達成され、洗練された画像を生成する驚異的な能力を持つモデルが生み出されています。これが研究チームがこの問題を選んだ動機となりました。Googleの研究者が提案するUniPiアプローチは、主に次の4つのコンポーネントで構成されています:タイリングによる軌跡の一貫性、階層的な計画、柔軟な行動調整、およびタスク固有のアクション適応。これらについて詳しく説明します。 1. タイリングによる軌跡の一貫性: 既存のテキストからビデオへの方法では、生成されるビデオは基礎となる環境状態が大きく変化することがあります。しかし、正確な軌跡プランナーを構築するためには、すべてのタイムスタンプで環境が一定であることが重要です。したがって、条件付けられたビデオ合成において環境の一貫性を強制するために、研究者は生成されたビデオの各フレームをノイズ除去しながら観測された画像を提供します。時間を超えて基盤となる環境状態を保持するために、UniPiは各ノイズの混入した中間フレームをサンプリングステップごとに条件付けられた観測された画像と直接連結します。 2. 階層的な計画: 複雑で洗練された環境で計画を立てる際には、すべての必要なアクションを生成することは困難です。この問題を克服するために、計画手法は自然な階層を利用して、小さい空間で大まかな計画を作成し、それをより詳細な計画に洗練していきます。同様に、ビデオ生成プロセスでは、UniPiはまず望ましいエージェントの振る舞いを示す粗いレベルのビデオを作成し、欠落しているフレームを埋めたり、滑らかにしたりして、より現実的なものに改善します。これは、各ステップがビデオの品質を向上させ、望ましい詳細レベルに達するまでビデオを改善する階層を使用することで実現されます。 3. 柔軟な行動調整: 小さな目標のためのアクションのシーケンスを計画する際には、生成されたプランを変更するために外部の制約を簡単に組み込むことができます。これは、プランの特性に基づいて望ましい制約を反映する確率的な事前知識を組み込むことによって行われることができます。この事前知識は、学習された分類器または特定の画像上のディラックデルタ分布を使用してプランを特定の状態に誘導するものです。このアプローチはUniPiとも互換性があります。研究者たちは、テキストに条件付けられたビデオ生成モデルを訓練するためにビデオ拡散アルゴリズムを使用しました。このアルゴリズムは、Text-To-Text Transfer Transformer(T5)からエンコードされた事前学習言語特徴量で構成されています。 4. タスク固有のアクション適応: 小さな逆動力学モデルは、合成されたビデオセットを使用してビデオフレームを低レベルの制御アクションに変換するためにトレーニングされます。このモデルはプランナーとは別であり、シミュレータによって生成された別の小さなデータセットでトレーニングすることができます。逆動力学モデルは、入力フレームと現在の目標のテキスト説明を取り、イメージフレームを合成し、将来の手順を予測するためのアクションのシーケンスを生成します。その後、エージェントはこれらの低レベルの制御アクションをクローズドループ制御を使用して実行します。 要約すると、Googleの研究者たちは、テキストベースのビデオ生成を使用して、組み合わせ的な汎化、マルチタスク学習、および現実世界の転送が可能なポリシーを表現する価値を示すことで、印象的な貢献をしました。研究者たちは、新しい言語ベースのタスクのいくつかで彼らのアプローチを評価し、UniPiが他のベースライン(Transformer BC、Trajectory Transformer、Diffuserなど)と比較して、言語のプロンプトの見たことも知らない組み合わせにもうまく一般化することが結論付けられました。これらの励みに満ちた発見は、生成モデルと利用可能な膨大なデータが、多目的な意思決定システムを作成するための貴重な資源としての潜在能力を浮き彫りにしています。

メタからのLlama 2基盤モデルは、Amazon SageMaker JumpStartで利用可能になりました
「本日、Metaによって開発されたLlama 2 ファウンデーションモデルがAmazon SageMaker JumpStartを通じてお客様に提供できることを喜んでお知らせしますLlama 2 ファミリーは、7兆から700兆のパラメータを持つ事前学習および微調整済みの生成テキストモデルのコレクションです微調整済みのLLMはLlama-2-chatと呼ばれています」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.