Learn more about Search Results ML - Page 332

- You may be interested
- 「Amazon SageMakerを使用して、薬剤探索...
- 「Amazon SageMakerを使用して、Rayベース...
- アマゾンのキャッシュレス「手のひらで支...
- 「偉大なる遺伝子データの漏洩:知ってお...
- INVE 対話型AIマジックでビデオ編集を革新...
- 「UCLAの研究者が提案するPhyCV:物理に触...
- 「文書理解の進展」
- 学生と教授たちは、建物のセンサーに抗議...
- AIが生成したコンテンツは開発者のリスク...
- 「ファストテキストを使用したシンプルな...
- データサイエンスにおける認知バイアス:...
- 「芸術家にとっての小さな一歩、クリエイ...
- 「なぜマイクロソフトのOrca-2 AIモデルは...
- 「カルロス・アルカラス vs. ビッグ3」
- エッジでのビジュアル品質検査のためのエ...
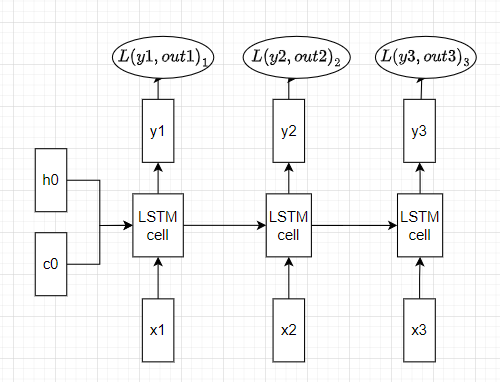
「RNNにおける誤差逆伝播法と勾配消失問題(パート2)」
このシリーズの第1部では、RNNモデルのバックプロパゲーションを解説し、数式と数値を用いてRNNにおける勾配消失問題を説明しましたこの記事では、次のことを行います...

Pythonでインタラクティブなデータビジュアライゼーションを作成する:Plotly入門
データの可視化は、データプロフェッショナルにとって最も重要なタスクの1つですそのため、それをインタラクティブにする方法を学ぶ必要があります
「生成AIが飲食業界のビジネスをサポートする方法」
「はい、私は第二の理由がより重要だと主張しますなぜなら、過去の方法やプロセスを振り返り、データを分析することは重要ですそれによって、失敗を修正する方法を学ぶことができるからです最終的には…」

スタンフォード大学の新しい人工知能研究は、説明が意思決定時のAIシステムへの過度の依存を軽減する方法を示しています
近年の人工知能(AI)のブームは、AIの能力によって仕事がより速く、より少ない労力で行われることによって、人間の生活がどれだけ向上したかと密接に関係しています。現在、AIを利用しない分野はほとんどありません。例えば、AIは、Amazon EchoやGoogle Homeなどの音声アシスタントのAIエージェントからタンパク質構造の予測に機械学習アルゴリズムを使用するまで、あらゆる場所に存在しています。したがって、AIシステムと協力する人間は、それぞれが単独で行動するよりも優れた意思決定を行うと考えるのは合理的です。しかし、実際にはそのようなケースではないことが、以前の研究で示されています。 いくつかの状況では、AIは常に正しい応答を生成するわけではありません。これらのシステムは、バイアスやその他の問題を修正するために再訓練する必要があります。しかし、AIに過度に依存するという関連する現象は、人間とAIの意思決定チームの効果に危険をもたらします。この現象では、人々はAIに影響を受け、AIが正しいかどうかを検証せずに間違った意思決定を受け入れることがよくあります。これは、銀行の詐欺の特定や医学的診断の提供などの重要なタスクを実行する際に非常に有害です。研究者たちは、AIが各ステップでなぜ特定の意思決定をしたのかを説明する説明可能なAIが、このAIへの過剰な依存の問題を解決しないことも示しています。一部の研究者は、過剰な依存を説明するために、認知バイアスや未校正の信頼が人間の認知の必然的な性質に起因していると主張しています。 しかし、これらの研究結果はAIの説明が過剰な依存を減らすべきだという考えを完全に確認していません。この点をさらに探るために、スタンフォード大学のヒューマンセンタードアートフィシャルインテリジェンス(HAI)研究室の研究チームは、人々がAIの説明との関わり方を戦略的に選ぶことができると主張し、AIの説明が人々の過剰な依存を減らすのに役立つ状況が存在することを示しました。彼らの論文によると、関連するAIの説明が手順よりも理解しやすい場合や、それによる利益が大きい場合(金銭的な報酬の形である場合)は、人々はAIの予測に依存する可能性が低くなります。彼らはまた、対象にそれを提供するだけでなく、説明との関わりに焦点を当てることで、AIへの過剰な依存をかなり減らすことができることを示しました。 チームは、この戦略的な意思決定を検証するために、コストと利益のフレームワークを導入しました。このフレームワークでは、タスクへの積極的な参加のコストと利益をAIに依存することのコストと利益と比較します。彼らはオンラインのクラウドワーカーに、3つの異なる複雑さレベルの迷路の課題をAIと協力して解決するように求めました。対応するAIモデルは答えを提供し、説明なしまたは次のステップのための単一の指示から迷路全体の出口までのターンバイターンの指示まで、さまざまな程度の正当化を提供しました。試験の結果、タスクの難易度や説明の難易度などのコスト、および金銭的な報酬などの利益が、過剰な依存に大きな影響を与えることがわかりました。AIモデルがステップバイステップの指示を提供する複雑なタスクでは、生成された説明を解読することが迷路を単独でクリアするのと同じくらい難しいため、過剰な依存は全く減少しませんでした。また、迷路を自力で脱出するのが簡単な場合、ほとんどの正当化は過剰な依存に影響を与えませんでした。 チームは、作業が難しく、関連する説明が明確な場合、説明は過剰な依存を防ぐのに役立つことを結論付けました。しかし、作業と説明の両方が難しいか単純な場合、これらの説明は過剰な依存にほとんど影響を与えません。作業が簡単に行える場合、説明はあまり重要ではありません。人々は説明に頼る代わりに自分自身でタスクを実行できるからです。また、作業が複雑な場合、人々には2つの選択肢があります。タスクを手動で完了するか、生成されたAIの説明を検討するかですが、これらの説明は頻繁に同様に複雑です。これの主な原因は、AIの研究者にとってはタスクを手動で実行するよりも検証にはるかに少ない努力が必要な説明ツールがほとんどないためです。そのため、人々はAIの判断を疑問視することなく信頼する傾向があるのは驚くことではありません。 追加の実験として、研究者たちは経済的な利益の要素を方程式に導入しました。彼らは、さまざまな難易度の迷路を独自に解くか、少ない報酬と引き換えにAIの支援を受けるかをクラウドワーカーに選択肢として提供しました。その際、説明なしまたは複雑なターンバイターンの指示付きでのAIの支援が行われました。その結果、タスクが難しい場合にはクラウドワーカーはAIの支援をより価値あるものとし、複雑な説明よりも簡単な説明を好むことがわかりました。また、過剰な依存は長期的なAIの利用の利益が増えるにつれて減少することがわかりました(この例では、金銭的な報酬)。 スタンフォードの研究者たちは、自己の発見が、説明が過度に依存することを少しでも軽減することに悩む学者たちに何らかの慰めを提供することになると期待しています。さらに、彼らは説明可能なAIの研究者たちを彼らの仕事で鼓舞し、AIの説明の向上と効率化のための説得力のある議論を提供することを望んでいます。 論文とスタンフォードの記事をチェックしてください。この研究に関するすべてのクレジットは、このプロジェクトの研究者に帰属します。また、最新のAI研究ニュース、クールなAIプロジェクトなどを共有している26k+のML SubReddit、Discordチャンネル、およびメールニュースレターにぜひ参加してください。 Tensorleapの説明可能性プラットフォームで、ディープラーニングの秘密を解き放つ この記事は、MarkTechPostに掲載されています。

GPT-エンジニア:あなたの新しいAIコーディングアシスタント
GPT-Engineerは、プロジェクトの説明からコードベースを生成するAIパワードのアプリケーションビルダーですこれにより、キーバリューデータベースの例を含むアプリケーションの構築が簡素化され、GPT-4ともうまく連携します

マルチモーダル言語モデル:人工知能(AI)の未来
大規模言語モデル(LLM)は、テキストの分析や生成などのタスクをこなすことができるコンピュータモデルです。これらは膨大なテキストデータで訓練され、テキスト生成やコーディングなどのパフォーマンスを向上させます。 現在のほとんどのLLMはテキストのみであり、テキストベースのアプリケーションに優れ、他の種類のデータを理解する能力に制限があります。 テキストのみのLLMの例には、GPT-3、BERT、RoBERTaなどがあります。 それに対して、マルチモーダルLLMは、テキストに加えて画像、動画、音声、その他の感覚入力など、他のデータタイプを組み合わせます。マルチモーダル性をLLMに統合することで、現在のテキストのみのモデルの制限を解消し、以前は不可能だった新しいアプリケーションの可能性を開くことができます。 最近リリースされたOpen AIのGPT-4はマルチモーダルLLMの一例です。画像とテキストの入力を受け付け、多くのベンチマークで人間レベルのパフォーマンスを示しています。 マルチモーダルAIの台頭 マルチモーダルAIの進展は、2つの重要な機械学習技術、表現学習と転移学習によってもたらされています。 表現学習により、モデルはすべてのモダリティに共有の表現を開発することができます。一方、転移学習により、モデルは特定のドメインでの微調整の前に基礎的な知識を学習することができます。 これらの技術は、マルチモーダルAIを実現し、CLIP(画像とテキストを整合させる)、DALL·E 2およびStable Diffusion(テキストプロンプトから高品質の画像を生成する)などの最近のブレークスルーによって効果的であります。 異なるデータモダリティ間の境界が不明瞭になるにつれて、複数のモダリティ間の関係を活用するAIアプリケーションがさらに増えることが予想され、フィールド全体でパラダイムシフトが起こります。アドホックなアプローチは徐々に時代遅れになり、さまざまなモダリティ間の関連を理解する重要性はますます高まるでしょう。 出典:https://jina.ai/news/paradigm-shift-towards-multimodal-ai/ マルチモーダルLLMの働き方 テキストのみの言語モデル(LLM)は、言語を理解し生成するためのトランスフォーマーモデルによって動作します。このモデルは入力テキストを「単語埋め込み」と呼ばれる数値表現に変換します。これらの埋め込みは、モデルがテキストの意味と文脈を理解するのに役立ちます。 トランスフォーマーモデルは、その後、「アテンションレイヤー」と呼ばれるものを使用して、入力テキストの異なる単語どうしの関係を処理し、出力の最も可能性の高い次の単語を予測します。 一方、マルチモーダルLLMは、テキストだけでなく、画像、音声、ビデオなどの他のデータ形式も扱います。これらのモデルは、テキストと他のデータタイプを共通のエンコーディング空間に変換するため、すべてのデータタイプを同じメカニズムで処理することができます。これにより、モデルは複数のモダリティからの情報を組み込んだ応答を生成し、より正確かつコンテキストに即した出力が可能となります。 マルチモーダル言語モデルの必要性 GPT-3やBERTのようなテキストのみのLLMは、記事の執筆、メールの作成、コーディングなど、幅広いアプリケーションに利用されています。ただし、このテキストのみのアプローチは、これらのモデルの制限も浮き彫りにしました。 言語は人間の知能の重要な部分ですが、それは私たちの知覚や能力の一側面を表すだけです。私たちの認知能力は、過去の経験や世界の動作の理解によって大きく形成された無意識の知覚と能力に大きく依存しています。 テキストだけで訓練されたLLMは、常識や世界の知識を組み込む能力に制限があります。トレーニングデータセットを拡大することはある程度役立つかもしれませんが、これらのモデルはまだ知識の予期せぬギャップに遭遇する可能性があります。マルチモーダルアプローチは、これらの課題のいくつかを解決することができます。 これをよりよく理解するために、ChatGPTとGPT-4の例を考えてみましょう。 ChatGPTは非常に有用な言語モデルであり、多くのコンテキストで非常に役立つことが証明されていますが、複雑な推論などの領域では制限があります。…

「自動推論とツールの利用(ART)を紹介します:凍結された大規模言語モデル(LLM)を使用して、推論プログラムの中間段階を迅速に生成するフレームワーク」
大規模言語モデルは、いくつかのデモとリアルな言語の指示を与えることで、新しいタスクに迅速に適応し、コンテキスト内での学習を利用することができます。これにより、LLMのホスティングや大規模なデータセットの注釈付けを回避することができますが、マルチステップの推論、数学、最新の情報の取得など、パフォーマンスに関する重要な課題があります。最近の研究では、LLMに高度な推論段階をサポートするためのツールへのアクセスを与えるか、マルチステップの推論のための推論チェーンのエミュレーションを課題とすることで、これらの制約を緩和することが提案されています。ただし、新しい活動やツールに対してチェーン化された理由付けの確立されたアプローチを適応することは困難であり、特定の活動やツールに特化したファインチューニングやプロンプトエンジニアリングが必要です。 図1:タスクライブラリから類似のタスク分解(A)を選択し、LLM生成と組み合わせてツールライブラリからツールを選択して適用することで、ARTは新しいタスクの自動マルチステップ分解(B)を開発します。人間は分解を変更してパフォーマンスを向上させることができます(コードの修正や変更など)(C)。 本研究では、ワシントン大学、マイクロソフト、メタ、カリフォルニア大学、アレン人工知能研究所の研究者が、新しいタスクの例に対して自動的に分解(マルチステップ推論)を作成するフレームワークであるAutomated Reasoning and Tool usage(ART)を開発しました。ARTはタスクライブラリから類似のタスクの例を引っ張ってきて、少数のデモとツールの使用を可能にすることで、さらなる作業に活用します。これらの例では、柔軟で構造化されたクエリ言語が使用されており、中間段階を読みやすくし、外部ツールの使用を一時停止して、そのツールの出力が含まれるまで再開することが簡単になっています(図1)。また、フレームワークは各段階で最適なツール(検索エンジンやコード実行など)を選択して使用します。 ARTはARTから各種関連活動のインスタンスを分解する方法や、これらの例で描かれたツールライブラリからツールを選択して使用する方法について、LLMにデモを提供します。これにより、モデルは例から新しいタスクを分解し、適切なツールを利用してジョブを行うことができます。また、ユーザーはタスクとツールのライブラリを更新し、論理の連鎖に誤りがある場合や新しいツール(例:対象のタスクに対して)を追加するために必要な最新の例を追加することができます。 彼らは15のBigBenchタスク用のタスクライブラリを作成し、19のBigBenchテストタスク(以前に見たことのないもの)、6つのMMLUタスク、および関連するツールの使用研究(SQUAD、TriviaQA、SVAMP、MAWPS)から数多くのタスクでARTをテストしました。34のBigBench問題のうち32問とすべてのMMLUタスクでは、ARTは平均でコンピュータによって作成されたCoT推論チェーンを22ポイント以上上回るか、または一致させます。ツールの使用が許可されると、テストタスクのパフォーマンスは平均で約12.3ポイント向上します。 平均して、ARTはBigBenchとMMLUの両方のタスクで直接のフューショットプロンプティングよりも10.8ポイント優れています。ARTは、数学的およびアルゴリズム的な推論を要求する未知のタスクにおいて、直接のフューショットプロンプティングよりも12.5ポイント優れ、分解とツールの使用のための監視を含むGPT3の最もよく知られた結果よりも6.1ポイント優れています。タスクとツールのライブラリを新しい例で更新することで、人間との相互作用と推論プロセスの向上が可能になり、最小限の人間の入力で任意のジョブのパフォーマンスを劇的に向上させることができます。追加の人間のフィードバックが与えられた場合、ARTは12のテストタスクで最もよく知られたGPT3の結果を平均で20%以上上回ります。

新たなディープ強化学習(DRL)フレームワークは、シミュレートされた環境で攻撃者に対応し、サイバー攻撃がエスカレートする前に95%をブロックすることができます
サイバーセキュリティの防御者は、技術の発展とシステムの複雑さのレベルが上昇するにつれて、自分たちの技術と戦術を動的に適応させる必要があります。過去10年間にわたる機械学習(ML)および人工知能(AI)の研究の進歩とともに、これらの技術のサイバーセキュリティに関連するさまざまな領域での利用事例も進化してきました。既存の多くのセキュリティアプリケーションでは、頑強な機械学習アルゴリズムによって支えられたいくつかの機能が、大規模なデータセットでトレーニングされています。そのような例の1つが、MLアルゴリズムを電子メールセキュリティゲートウェイに統合した2010年代初頭です。 実世界のシナリオでは、自律型のサイバーシステム防御戦略と行動の推奨事項を作成することは非常に困難です。なぜなら、このようなサイバーシステムの防御メカニズムに対する意思決定支援には、攻撃者と防御者の間のダイナミクスの組み込みとシステム状態の不確実性の動的特性化が必要だからです。さらに、サイバー防御者は、コスト、労力、時間などのさまざまなリソース制約に直面することが多いです。AIを使用しても、積極的な防御が可能なシステムの開発は理想的な目標のままです。 この問題に対する解決策を提供するため、米国エネルギー省太平洋北西国立研究所(PNNL)の研究者たちは、シミュレートされた環境で攻撃者に対応し、サイバー攻撃の95%をエスカレートさせる前に停止できる新しいDRL(深層強化学習)に基づくAIシステムを開発しました。研究者たちは、ネットワーク内で攻撃者と防御者の間で行われるマルチステージのデジタル紛争を示すカスタムのシミュレーション環境を作成しました。そして、報酬を最大化することに基づいて妥協を回避し、ネットワークの混乱を減らすことを目指した強化学習の原則を使用して、4つのDRLニューラルネットワークをトレーニングしました。このチームの研究成果は、また、ワシントンDCで開催された人工知能の進歩協会で発表され、多くの称賛を受けました。 このようなシステムを開発する際のチームの理念は、まずDRLアーキテクチャを成功裏にトレーニングできることを示すことでした。洗練された構造に取り組む前に、彼らは有用な評価メトリックを示したいと考えました。研究者たちが最初に行ったことは、Open AI Gymツールキットを使用して抽象的なシミュレーション環境を作成することでした。次に、この環境を使用して、MITRE ATT&CKフレームワークの15のアプローチと7つの戦術から選ばれたサブセットに基づいてスキルと持続性レベルを示す攻撃者エンティティを開発しました。攻撃者の目標は、初期アクセスと偵察フェーズから他の攻撃フェーズまでの7つの攻撃チェーンステップを進むことで、最終目標である影響と流出フェーズに到達することです。 重要なポイントとして、チームは環境内で攻撃を開始する敵をブロックするためのモデルを開発する意図はありませんでした。むしろ、システムが既に侵害されていると想定しています。その後、研究者たちは強化学習を使用して4つのニューラルネットワークをトレーニングしました。研究者たちは、強化学習を利用せずにこのようなモデルをトレーニングすることも可能ですが、良いメカニズムを開発するには長い時間がかかると述べています。一方、深層強化学習は、人間の行動の一部を模倣することで、この巨大な探索空間を非常に効率的に利用します。 研究者たちがシミュレートされた攻撃環境でAIシステムをトレーニングすることができることを実証するための努力により、AIモデルがリアルタイムで攻撃に対する防御反応が可能であることが示されました。研究者たちは、実際のマルチステージの攻撃シーケンスに対する4つのモデルフリーDRLアルゴリズムのパフォーマンスを厳密に評価するために、いくつかの実験を実施しました。彼らの研究は、異なるスキルと持続性レベルを持つマルチステージの攻撃プロファイルでDRLアルゴリズムをトレーニングできることを示し、シミュレートされた環境で効果的な防御結果を生み出すことを示しました。

『AI論文によると、大規模な言語モデルの一般的なパターンマシンとしての異なるレベルの専門知識を説明します』
LLM(Large Language Models)は、言語の構造に織り込まれている多くのパターンを取り入れるように教えられます。これらはロボット工学で使用され、高レベルの計画者として命令に従うタスク、ロボットポリシーを表すプログラムの合成、報酬関数の設計、およびユーザーの好みの一般化を行うことができます。また、論理的な推論の連鎖を生成したり、ロジックパズルを解いたり、数学の問題を解いたりするなど、さまざまなアウトオブザボックスの能力も示します。これらの設定は、入出力の形式を確立するテキストプロンプトのインコンテキスト例に依存しており、入出力は意味論的なままです。 彼らの研究の重要な発見の1つは、LLMがより抽象的で非言語的なパターンを表現、変更、および推測する能力により、より単純なタイプの一般パターンマシンとして機能する可能性があることです。この発見は、従来の知恵に反するかもしれません。このトピックを説明するために、抽象的な推論コーパスを考えてみましょう。この広範なAIベンチマークには、インフィリング、カウント、オブジェクトの回転などの抽象的な概念を示唆するパターンを持つ2Dグリッドのコレクションが含まれています。各タスクは、関連する結果を予測するためのいくつかの入出力の関係のインスタンスから始まり、テスト入力に移行します。多くのプログラム合成ベースのアプローチは、ドメイン固有の言語を使用して手動で構築されるか、ベンチマークの簡略化バリエーションまたはサブセットに対して評価されます。 彼らの実験によれば、ASCIIアートのスタイルでインコンテキストのプロンプトを行うLLMは、800問の問題のうち最大85問の解を正しく予測し、これまでの最も優れた手法を凌駕し、追加のモデルトレーニングやファインチューニングの必要はありません。一方、エンドツーエンドの機械学習手法は、ごく少数のテスト問題しか解決できません。驚くべきことに、このことはASCII数字についてだけでなく、LLMがトークンの代わりにレキシコンからランダムに選択されたトークンへのマッピングである場合でも、良い回答を生成する可能性があることが分かります。これらの発見は、特定のトークンに依存しないより広範な表現能力と推測能力をLLMが持つ可能性を提起しています。 図1は、任意のトークンで表される複雑なARCパターンを(ハイライト表示で)自動的に完了するLLMの能力を示しています。 これは、インコンテキストの分類に使用された場合、正解ラベルがランダムなまたは抽象的なラベルマッピングよりも優れたパフォーマンスを発揮することを前の研究が示していることと一致し、支持しています。ロボット工学や順序決定問題では、言葉で正確に推論するのが難しいパターンを含む幅広い問題が存在するため、彼らはARCでのパターン推論を支える能力が異なる抽象レベルで一般的なパターン操作を可能にすると仮定しています。たとえば、テーブルトップ上で物を空間的に再配置するための手法は、ランダムなトークンを使用して表現することができます(図2を参照)。別の例は、報酬関数に基づいた軌道の最適化のために、状態とアクションのトークンのシーケンスを増やすことです。 スタンフォード大学、Google DeepMind、TU Berlinの研究者は、この研究に対して2つの主な目標を持っています。1つ目は、LLMがすでに一定レベルの一般的なパターン操作を実行するために含んでいるゼロショットの能力を評価すること、2つ目は、これらの能力がロボット工学でどのように使用されるかを調査することです。これらの取り組みは、大量のロボットデータで事前トレーニングを行うことや、ダウンストリームタスクにファインチューニングできるロボットファウンデーションモデルを開発することとは直交しており、補完的なものです。これらのスキルは、特化したアルゴリズムを完全に置き換えるには十分ではありませんが、一般的なロボットモデルをトレーニングする際に重点を置くべき最も重要な領域を特定するのに役立つことができます。彼らの評価によれば、LLMはシーケンス変換、シーケンス完全性、またはシーケンス拡張の3つのカテゴリに分類されます(図2を参照)。 図2:事前トレーニングされたLLMは、抽象的なロボット工学および順序決定問題を反映した数値またはランダム(記号)トークンのシーケンスを認識し、完了することにより、最も基本的なタイプのユニバーサルパターンマシンとして振る舞うことができます。実験の結果は、LLMがある程度の範囲でシーケンス変換(たとえば、ダウンサンプルされた画像上の動力学モデリングと次状態予測のための空間的なシンボルの再配置に関する推論)、単純な関数の完了(たとえば、運動学的デモの推測)、またはリターン条件付きポリシーの改善のためのメタパターン(たとえば、CartPoleの安定化のための振動行動の発見)を学習できることを示しています。 まず、彼らはLLMがいくつかのトークンの不変性を持つ増加的な複雑さのシーケンス変換を一般化できることを実証し、これが空間思考を必要とするロボットアプリケーションで使用される可能性があることを示唆しています。次に、彼らはLLMのパターン補完能力を評価し、単純な関数(例えば正弦波)からのパターンの拡張に使用される可能性を示しています。これは、触覚デモンストレーションから拭き取り動作を延長したり、ホワイトボード上にパターンを作成したりするロボットの活動に使用される可能性があります。LLMは、外挿と文脈におけるシーケンス変換の組み合わせにより、基本的な種類のシーケンス改善を行うことができます。彼らは、報酬付きの軌道文脈とオンラインインタラクションを使用することで、LLMベースのエージェントが小さなグリッド内を移動し、安定化したCartPoleコントローラを見つけ、人間との相互作用に基づく「クリッカー」インセンティブトレーニングを使用して基本的な軌道を最適化する方法を示しています。彼らは、コード、ベンチマーク、および動画を公開しています。

「2023年のトップ50以上のAIコーディングアシスタントツール」
ChatGPT ChatGPTは、既存のコード参照に頼らずにコードを書くことができます。さらに、ユーザーのコードを効率的にデバッグすることもできます。コードインタプリタを組み込むことで、ChatGPTは自身のコードの自己テストを含めた機能を拡張しました。 Bard GoogleのBardは、ChatGPTと同様に会話形式で対話することができ、コードの作成とデバッグに適しています。 GitHub Copilot GitHub Copilotは、コンテキストのあるコードを分析し、関連するコードスニペットを提案することで、リアルタイムのフィードバックと推奨を提供するAIパワードのコード補完ツールです。 Tabnine Tabnineは、GitHub Copilotの代替となるAIベースのコード補完ツールで、完全な機能を備えたAIコード補完能力を提供することで特徴的です。 Code Snippets AI Code Snippetsは、ユーザーが質問をコードに変換できるツールです。コードの説明、スニペットライブラリなどの機能を備えたオールインワンツールです。 MutableAI MutableAIは、ボイラープレートコードを頻繁に使用し、効率的なオートコンプリート機能を求める開発者にとって最適な選択肢です。コード補完とコードの論理的なグループへの整理と整頓の機能を提供しています。 Cogram Cogramは、自然言語を使用して効率的なSQLクエリを記述することを可能にするSQLコード生成ツールです。 Amazon CodeWhisperer CodeWhispererは、コメントと既存のコードに基づいてインテリジェントな補完を行う、AWSによって開発されたコード補完ツールです。 Replit…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.