Learn more about Search Results ML - Page 330

- You may be interested
- 「時系列の外れ値を解読する:1/4」
- AIがオンエア中:世界初のRJボット、アシ...
- 「驚くほど速い、コード不要のPython Foli...
- Google AIがFlan-T5をオープンソース化 NL...
- 「Chat-GPTとPythonを使用して、自分の記...
- AIを使用してAI画像の改ざんを防ぐ
- 「サンドイッチされた半導体により、伸縮...
- 「ビジネスインテリジェンスとは何ですか?」
- 「UCSDとByteDanceの研究者が、アクターズ...
- 「LLMsを活用してリコメンデーション知識...
- AIによるなりすましからの戦い
- コンテンツモデレーションからゼロショッ...
- 大規模言語モデルにおける推論力の向上:...
- カスタムレンズを使用してウェルアーキテ...
- 書評「AIの仕組み 魔術から科学へ」 ロナ...

エネルは、Amazon SageMakerを使用して大規模な電力グリッド資産管理と異常検知を自動化しています
マリオ・ナムタオ・シャイアンティ・ラルチェル(Enelのコンピュータビジョン部門の責任者)によるゲスト投稿ですエネルギーのためのイタリアの国営機関として始まったEnelは、現在、32か国に進出し、7400万人のユーザーを持つ世界初の民間ネットワークオペレーターですまた、再生可能エネルギーの分野で最初の企業としても認識されています

スタンフォード研究所がFlashAttention-2を発表:長い文脈の言語モデルの速度と効率の飛躍
過去の1年間、自然言語処理は著しい進歩を遂げており、長い文脈を備えた言語モデルが登場しました。これらのモデルには、32kの文脈長を持つGPT-4、65kの文脈を持つMosaicMLのMPT、そして驚異的な100kの文脈長を誇るAnthropicのClaudeなどがあります。長いドキュメントのクエリやストーリー作成などのアプリケーションが成長し続ける中、拡張された文脈を持つ言語モデルの需要が明らかになってきました。ただし、課題は、トランスフォーマーの文脈長を拡大することであり、その注意層は入力シーケンスの長さと二乗的に増加する計算とメモリの要件があります。 この課題に取り組むために、わずか1年前にリリースされた革新的なアルゴリズムであるFlashAttentionは、さまざまな組織や研究所で急速に採用されました。このアルゴリズムは、精度を損なうことなく注意の計算を加速し、そのメモリの使用量を削減することに成功しました。初期リリース時に最適化されたベースラインと比較して2〜4倍高速なパフォーマンスを発揮したFlashAttentionは、画期的な進歩を証明しました。しかし、A100 GPUで最大124 TFLOPs/sを達成した高速最適化マトリックス乗算(GEMM)操作には及びませんでした。 次なる飛躍を遂げたFlashAttentionの開発者は、FlashAttention-2という前作を大幅に上回る再発明版を発表しました。NvidiaのCUTLASS 3.xとCuTeコアライブラリを活用したFlashAttention-2は、A100 GPU上で最大230 TFLOPs/sの驚異的なスピードアップを実現しています。さらに、GPTスタイルの言語モデルのエンドツーエンドトレーニングでは、FlashAttention-2は最大225 TFLOPs/sのトレーニング速度を実現し、驚異的な72%のモデルFLOP利用率を達成しています。 FlashAttention-2の主な改良点は、より優れた並列性と作業の分割戦略にあります。最初に、FlashAttentionはバッチサイズとヘッド数を並列化し、GPU上の計算リソースを効果的に活用しました。しかし、バッチサイズが小さいか、ヘッド数が少ない長いシーケンスの場合、FlashAttention-2はシーケンス長の次元で並列化するようになり、これによりこれらのシナリオで大幅なスピードアップが実現されました。 もう一つの改善点は、各スレッドブロック内の異なるワープ間での効率的な作業の分割です。FlashAttentionでは、KとVを4つのワープに分割し、Qをすべてのワープでアクセス可能な状態に保つ「sliced-K」スキームは、不要な共有メモリの読み書きを引き起こし、計算を遅くしました。FlashAttention-2は異なるアプローチを取り、KとVをすべてのワープでアクセス可能な状態に保ちながら、Qを4つのワープに分割するようにしました。これにより、ワープ間の通信が不要となり、共有メモリの読み書きが大幅に削減され、パフォーマンスがさらに向上しました。 FlashAttention-2は、その適用範囲を広げ、機能を向上させるためにいくつかの新機能を導入しています。最大256のヘッド次元をサポートし、GPT-J、CodeGen、CodeGen2、およびStableDiffusion 1.xなどのモデルを収容できるようになり、より高速化とメモリの節約の機会が広がりました。さらに、FlashAttention-2はマルチクエリアテンション(MQA)およびグループ化クエリアテンション(GQA)のバリアントに対応し、クエリの複数のヘッドがキーと値の同じヘッドにアテンドできるようになり、推論のスループットとパフォーマンスが向上します。 FlashAttention-2のパフォーマンスは本当に印象的です。A100 80GB SXM4 GPUでベンチマークを行った結果、前作と比較して約2倍の高速化を実現し、PyTorchの標準的なアテンション実装と比較して最大9倍の高速化を達成しました。さらに、GPTスタイルのモデルのエンドツーエンドトレーニングに使用すると、FlashAttention-2は既に高度に最適化されたモデルに比べて1.3倍のエンドツーエンドの高速化を実現します。 FlashAttention-2の将来の応用は非常に有望です。前作の8k文脈モデルと同じ価格で16kより長い文脈のモデルをトレーニングできる能力により、この技術は長い本、レポート、高解像度の画像、音声、ビデオの分析に役立つことができます。H100 GPUやAMD GPUなどのデバイスへの広範な適用と、fp8などの新しいデータタイプへの最適化の計画も進行中です。さらに、FlashAttention-2の低レベルの最適化を高レベルのアルゴリズムの変更と組み合わせることで、前例のない長い文脈でのAIモデルのトレーニングの可能性が開かれるかもしれません。プログラム性を向上させるためのコンパイラ研究者との協力も展望されており、次世代の言語モデルに明るい未来が約束されています。

「Gensimを使ったWord2Vecのステップバイステップガイド」
はじめに 数か月前、Office Peopleで働き始めた当初、私は言語モデル、特にWord2Vecに興味を持ちました。ネイティブのPythonユーザーとして、私は自然にGensimのWord2Vecの実装に集中し、論文やオンラインのチュートリアルを探しました。私は複数の情報源から直接コードの断片を適用し、複製しました。私はさらに深く探求し、自分の方法がどこで間違っているのかを理解しようとしました。Stackoverflowの会話、GensimのGoogleグループ、およびライブラリのドキュメントを読みました。 しかし、私は常にWord2Vecモデルを作成する上で最も重要な要素の一つが欠けていると考えていました。私の実験の中で、文をレンマ化することやフレーズ/バイグラムを探すことが結果とモデルのパフォーマンスに重要な影響を与えることを発見しました。前処理の影響はデータセットやアプリケーションによって異なりますが、この記事ではデータの準備手順を含め、素晴らしいspaCyライブラリを使って処理することにしました。 これらの問題のいくつかは私をイライラさせるので、自分自身の記事を書くことにしました。完璧だったり、Word2Vecを実装する最良の方法だったりすることは約束しませんが、他の多くの情報源よりも良いと思います。 学習目標 単語の埋め込みと意味的な関係の捉え方を理解する。 GensimやTensorFlowなどの人気のあるライブラリを使用してWord2Vecモデルを実装する。 Word2Vecの埋め込みを使用して単語の類似度を計測し、距離を算出する。 Word2Vecによって捉えられる単語の類推や意味的関係を探索する。 Word2Vecを感情分析や機械翻訳などのさまざまな自然言語処理のタスクに適用する。 特定のタスクやドメインに対してWord2Vecモデルを微調整するための技術を学ぶ。 サブワード情報や事前学習された埋め込みを使用して未知語を処理する。 Word2Vecの制約やトレードオフ、単語の意味の曖昧さや文レベルの意味について理解する。 サブワード埋め込みやWord2Vecのモデル最適化など、高度なトピックについて掘り下げる。 この記事はData Science Blogathonの一部として公開されました。 Word2Vecについての概要 Googleの研究チームは2013年9月から10月にかけて2つの論文でWord2Vecを紹介しました。研究者たちは論文とともにCの実装も公開しました。Gensimは最初の論文の後すぐにPythonの実装を完了しました。 Word2Vecの基本的な仮定は、文脈が似ている2つの単語は似た意味を持ち、モデルからは似たベクトル表現が得られるというものです。例えば、「犬」、「子犬」、「子犬」は似た文脈で頻繁に使用され、同様の周囲の単語(「良い」、「ふわふわ」、「かわいい」など)と共に使用されるため、Word2Vecによると似たベクトル表現を持ちます。 この仮定に基づいて、Word2Vecはデータセット内の単語間の関係を発見し、類似度を計算したり、それらの単語のベクトル表現をテキスト分類やクラスタリングなどの他のアプリケーションの入力として使用することができます。 Word2vecの実装 Word2Vecのアイデアは非常にシンプルです。単語の意味は、それが関連する単語と共に存在することによって推測できるという仮定をしています。これは「友だちを見せて、君が誰かを教えてあげよう」という言葉に似ています。以下はword2vecの実装例です。…

メタの戦略的な優れた点:Llama 2は彼らの新しいソーシャルグラフかもしれません
テック業界の注目を集めている動きとして、Metaは最近、無料でオープンソースの大規模言語モデル(LLM)の第2版であるLlama 2のリリースを発表しました。私は大規模言語モデルを利用した製品のユーザーおよび開発者として、この進展に喜びを感じました。しかし、Metaの戦略について詳しく掘り下げると、同社の戦術的かつ戦略的な優れた点に本当に感銘を受けました。本記事では、MetaがLlama 2をオープンソース化するという決定、ML主導の製品の競争の激しい環境におけるその影響、およびMetaがテック業界における独自の立場に対応する方法について探求します。 LLMの戦い- Meta、Microsoft、およびGoogle:今日、Microsoft/OpenAIやGoogleなどの業界の巨人は、最高のML主導製品を開発・マーケティングすることで激しく競い合っています。この戦いは、OpenAIのChatGPTやGoogleのBardなどの各社のLLMの品質にも及んでいます。これらの企業は、自社のLLMを貴重な資産として厳重に保護しています。しかし、Llama 2をオープンソース化するというMetaの決定は、ゲームチェンジングな戦略的な動きを表しています。 オープンソースLLMの戦術的利点:Metaは、Llama 2をオープンソース化することで、GoogleやMicrosoftなどの競合他社に頼る可能性のある潜在的な顧客を先回りし、戦術的な利点を得ることができます。Metaは、オープンソースコミュニティの協力力を活用し、ユーザーや開発者を自社プラットフォームに引き付ける価値を認識しています。 また、他社にLLMを公開することで、貴重なフィードバック、テスト、および改善が可能になります。これらのミスは、比較的小規模な企業にとっては無害ですが、公に監視される大企業にとっては大きな損害をもたらす可能性があります。 Metaにとっての戦略的な意義:Metaは、主要なテック企業の中で比較的多様化された収益ストリームを持っていないため、一部のアナリストからはより露出が高くまたは脆弱と見なされています。Metaは、直接ソフトウェアやハードウェアを販売していません。さらに、GoogleやAmazon、Microsoftのような広範な商業クラウドインフラを持っていません。しかし、Metaはこれまでのメタバースへの投資を、広告の単なる集積業者を超えて多様化する手段として捉えています。メタバースには、複雑なB2BおよびB2Cの提供の可能性があり、Metaのこの新たな領域への戦略的な賭けは緻密かつ計算された動きです。 産業規模の第1の無形資産:MetaのオープンソースLLMイニシアチブを特筆するのは、LLMそのものの戦略的な意義です。大規模な言語モデルの構築には、膨大なトレーニングセット、優れた研究科学者のチーム、および高価なハードウェアが必要です。そのため、LLMは産業規模の最初の無形資産と見なされることができます。MicrosoftがOpenAIに100億ドルを投資したことは、LLMの開発に必要な膨大なリソースの証です。そのため、ごく一部の企業のみがこのようなモデルを構築することができます。さらに、フリーリリース後に様々なビジネスモデルを通じてLLMを収益化することができます。 多様化を推進する資産:Yann Lecunの優れた研究チームの専門知識を活用することで、MetaはLlama 2という強力な資産を獲得しました。このLLMに基づく革新的なソリューションを提供することで、Metaは広告以外の主要な収益源に多様化することができます。この戦略的な動きは、Metaの業界での地位を強化するだけでなく、テック企業との競争力を高める可能性も与えています。MetaがLlama 2をオープンソースLLMとしてリリースするという決定は、戦術的かつ戦略的な優れた点を示しています。これにより、Metaは潜在的な顧客を先手に打つことができ、コミュニティ主導の開発の恩恵を受けることができます。さらに、Llama 2への投資とその広範な可能性を活かすことで、Metaは従来の収益源を超えて多様化する位置づけを築いています。テックの景色が変化する中、MetaのオープンソースLLMイニシアチブは、革新、協力、および変化し続ける業界での長期的な成功へのコミットメントを示す先見の明を持ったアプローチです。 The post Meta’s Strategic Brilliance: Llama 2 May…

「Amazon SageMakerを使用して、効率的にカスタムアンサンブルをトレーニング、チューニング、デプロイする」
「人工知能(AI)は、テクノロジーコミュニティで重要かつ人気のあるトピックとなっていますAIが進化するにつれて、さまざまなタイプの機械学習(ML)モデルが登場してきましたアンサンブルモデリングとして知られるアプローチは、データサイエンティストや実践者の間で急速に注目を集めていますこの記事では、アンサンブルモデルとは何かについて議論します...」
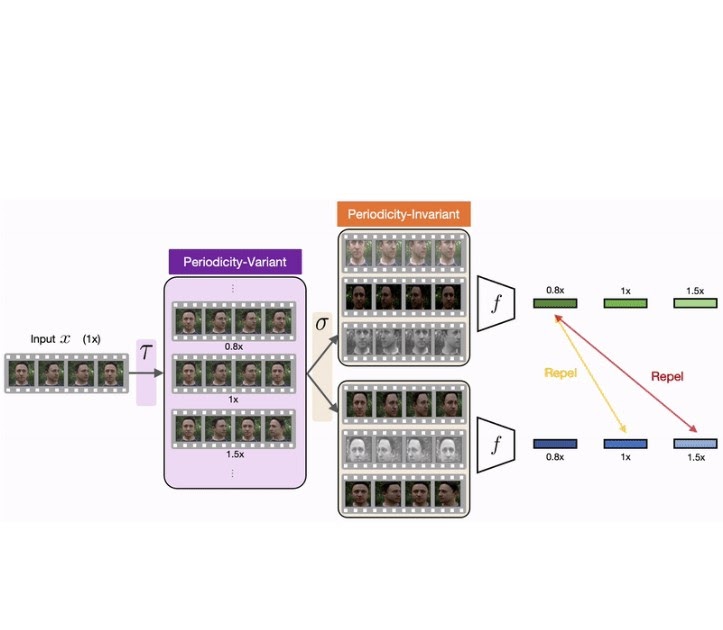
SimPer:周期的なターゲットの簡単な自己教示学習
Googleのスタッフ研究者であるDaniel McDuffと学生研究者のYuzhe Yangによって投稿されました。 周期的なデータ(心拍や地球表面の日々の気温変化など、繰り返される信号)から学ぶことは、天候システムの監視から生体徴候の検出まで、多くの実世界のアプリケーションにとって重要です。例えば、環境遠隔検出の領域では、降水パターンや地表温度などの環境変化のナウキャスティングを可能にするために周期的な学習がしばしば必要です。健康領域では、ビデオ測定から学んだ結果、心房細動や睡眠時無呼吸などの(準)周期的な生体徴候を抽出することが示されています。 RepNetなどのアプローチは、これらのタスクの重要性を強調し、単一のビデオ内で繰り返されるアクティビティを認識する解決策を提供しています。ただし、これらは教師ありのアプローチであり、繰り返されるアクティビティを捉えるために大量のデータと、アクションが繰り返された回数を示すラベルが必要です。このようなデータのラベリングは、しばしば難しくリソースを消費するため、研究者は興味の対象のモダリティ(ビデオや衛星画像など)と同期したゴールドスタンダードの時間的計測を手動でキャプチャする必要があります。 代わりに、自己教師あり学習(SSL)の手法(SimCLRやMoCo v2など)は、周期的または準周期的な時間的ダイナミクスを捉える表現を学習するためにラベルの付いていない大量のデータを活用することで、分類タスクの解決に成功しています。しかし、これらの手法は、データの固有の周期性(つまり、フレームが周期的なプロセスの一部であるかどうかを識別する能力)を見落とし、周期的な属性や周波数属性を捉える堅牢な表現を学習することができません。これは、周期的な学習が一般的な学習タスクとは異なる特性を持つためです。 周期的表現の文脈での特徴の類似性は、静的な特徴(例えば画像)とは異なります。例えば、短い時間遅れでオフセットされたビデオや反転されたビデオは、元のサンプルと類似しているべきです。一方、ビデオのアップサンプリングやダウンサンプリングは、元のサンプルから因子xで異なるはずです。 これらの課題に対処するために、私たちは「SimPer: Simple Self-Supervised Learning of Periodic Targets」という論文で、データ内の周期的な情報を学習するための自己教師ありの対照的なフレームワークを紹介しました。具体的には、SimPerは周期性不変および周期性変動の拡張によって、同じ入力インスタンスから正例と負例のサンプルを取得することで、周期性のあるターゲットの時間的特性を活用します。周期的な特徴の類似性を提案し、周期的な学習の文脈で類似性を測定する方法を明示的に定義します。さらに、古典的なInfoNCE損失をソフト回帰バリアントに拡張した汎用の対照的な損失を設計し、連続したラベル(周波数)を対照することを可能にします。次に、SimPerが最新のSSL手法と比較して効果的に周期的な特徴表現を学習することを示し、データの効率性、誤った相関に対する堅牢性、分布のシフトに対する一般化能力など、その興味深い特性を強調します。最後に、私たちはSimPerのコードリポジトリを研究コミュニティと共有することを楽しみにしています。 SimPerフレームワーク SimPerは、時間的な自己対照的学習フレームワークを導入します。正例と負例のサンプルは、周期性不変および周期性変動の拡張によって同じ入力インスタンスから取得されます。時間的なビデオの例では、周期性不変の変更にはトリミング、回転、反転があり、周期性変動の変更にはビデオの速度の増減が含まれます。 周期的な学習の文脈で類似性を測定する方法を明示的に定義するために、SimPerは周期的な特徴の類似性を提案します。この構成により、トレーニングを対照的な学習タスクとして定式化することができます。モデルはラベルのないデータでトレーニングされ、必要に応じて学習された特徴を特定の周波数値にマッピングするために微調整されることができます。 入力シーケンスxが与えられた場合、関連する周期的な信号が存在することがわかります。そして、xを変換して速度や周波数が変化したサンプルのシリーズを作成し、基になる周期的なターゲットを変更し、異なる負のビューを作成します。元の周波数は不明ですが、ラベルのない入力xに対して擬似的な速度や周波数のラベルを効果的に考案します。 従来の類似性尺度(例:コサイン類似度)は、2つの特徴ベクトル間の厳密な近接性を強調し、インデックスがシフトした特徴(異なるタイムスタンプを表す)、逆転した特徴、および周波数が変化した特徴に対して敏感です。一方、周期的な特徴類似性は、時間的なシフトが小さく、または逆転したインデックスがあるサンプルに対して高くなるべきであり、特徴の周波数が変化する際に連続的な類似性の変化を捉えるべきです。これは、フーリエ変換間の距離など、周波数領域の類似度尺度によって実現できます。 周波数領域で増強されたサンプルの固有の連続性を活用するために、SimPerは一般化された対照的損失を設計します。この損失は、古典的なInfoNCE損失をソフト回帰のバリアントに拡張し、連続的なラベル(周波数)に対して対比を可能にします。これにより、心拍などの連続信号を回復するという回帰タスクに適しています。 SimPerは、周波数領域でデータのネガティブビューを構築することによって、データの変換を行います。入力シーケンスxには、関連する周期的な信号があります。SimPerは、xを変換して速度や周波数が変化したサンプルのシリーズを作成します。これにより、基礎となる周期的なターゲットが変わり、異なるネガティブビューが作成されます。元の周波数は不明ですが、未ラベルの入力xに対して疑似的な速度や周波数ラベル(周期性変数の増強τ)を効果的に設計します。SimPerは、入力の識別を変更しない変換を取り、これらを周期性に関して不変な増強σと定義し、サンプルの異なるポジティブビューを作成します。そして、これらの増強ビューをエンコーダfに送り、対応する特徴を抽出します。 結果 SimPerの性能を評価するために、人間の行動分析、環境リモートセンシング、および医療の共通の実世界タスクに対して、SimPerを最新のSSLスキーム(例:SimCLR、MoCo…

「PandasのDataFrameに列を追加する10の方法」
DataFrameは、ラベル付きの行と列を持つ2次元のデータ構造ですデータ分析や特徴エンジニアリングの一環として、新しい列を追加する必要がしばしばありますさまざまな方法があります...

「Mojo」という新しいプログラミング言語は、Pythonの使いやすさとCのパフォーマンスを組み合わせ、AIハードウェアのプログラム可能性とAIモデルの拡張性を他のどの言語よりも優れたものにします
人工知能の領域は急速に発展しています。近年、AIとMLは徐々に進化し、今ではすべての組織が製品にAIを導入し、その応用を普及させようとしています。最近、人気のあるスタートアップ企業、モジュラーAIがMojoという新しいプログラミング言語をリリースしました。Mojoは人工知能コンピューティングハードウェアに直接アクセスできるため、AIベースの発明には素晴らしい追加となります。 MojoはPythonとC言語の両方の機能を持ち、Pythonの使いやすさとCのパフォーマンスを兼ね備えています。モジュラーAIはこのプログラミング言語を開発し、Pythonの制限を克服するためにしました。Pythonはスケーラビリティが低く、大規模なワークロードやエッジデバイスで使用することはできません。スケーラビリティの問題により、C++やCUDAなどの他の言語もAIをプロダクション環境にシームレスに実装するために含まれています。 Mojoは、Numpy、Matplotlib、および独自のカスタムコードなど、さまざまなライブラリをシームレスに統合することで、Pythonエコシステムとのスムーズな相互運用性を実現します。Mojoを使用すると、ユーザーは高度なコンパイラと異種ランタイムを使用して、複数のコア、ベクトルユニット、および専用アクセラレータユニットなどのハードウェアの全機能を活用することができます。ユーザーは、C++やCUDAの必要性なしに、Pythonで低レベルのAIハードウェア向けに最適化されたアプリケーションを開発することができますが、これらの言語と同様のパフォーマンスを維持します。 Mojoは、プログラムの実行速度と開発者の生産性を向上させるために、モダンなコンパイル技術を使用しています。Mojoのキーとなる機能は、メモリ割り当てとデータ表現に関するコンパイラのより良い判断を可能にするタイプデザインです。これにより、実行パフォーマンスが指数関数的に向上します。Mojoはゼロコストの抽象化もサポートしており、パフォーマンスを損なうことなく高レベルの構造を定義することができます。この機能により、効率の良い低レベルの操作を維持しながら、表現力豊かで読みやすいコードの作成が可能となります。 Mojoにはメモリセーフティもあり、バッファオーバーフローやダングリングポインタなどの一般的なメモリ関連のエラーを防ぐのに役立ちます。また、Mojoは自動調整とコンパイル時メタプログラミングの機能も提供しています。自動調整は、コンパイル時にプログラムのパフォーマンスを最適化し、コンパイルフェーズ中にプログラムの構造と振る舞いを変更することができるコンパイル時メタプログラミングは、特定のコンパイル時条件に基づいて専門化された実装を生成することにより、より効率的なコードの作成を可能にします。 MojoはAIコンピューティングハードウェアに直接アクセスできるため、Pythonよりも計算パフォーマンスが優れています。Mandelbrotなどのアルゴリズムを実行する際、Pythonよりも35,000倍高速です。モジュラーの高性能ランタイムとマルチレベル中間表現技術を完全に適用することで、Mojoはスレッド、TensorCores、AMX拡張などの低レベルハードウェア機能を直接操作します。Mojoはまだ開発中であり、研究者は最終的にはPythonの厳格なスーパーセットとなると述べています。 まとめると、MojoはすべてのAI開発者にとって有望な言語のようです。PythonとCの機能を組み合わせ、AIハードウェアのプログラム可能性とAIモデルの拡張性を比類のないものにします。

「PIP、Conda、requirements.txtを忘れましょう!代わりにPoetryを使って、私に感謝してください」
「痛みのない依存関係管理がついに実現しました」

ハッピーな1周年 🤗 ディフューザーズ!
🤗 Diffusersは、1周年を迎えることを喜んでいます!エキサイティングな1年であり、コミュニティとオープンソースの貢献者のおかげで、私たちは遠くまで来ることができました。昨年、DALL-E 2、Imagen、およびStable Diffusionなどのテキストから画像を生成するモデルが世界の注目を集め、生成AIの興味と開発が急速に広がりました。しかし、これらの強力なモデルへのアクセスは制限されていました。 Hugging Faceでは、協力し合い、オープンで倫理的なAIの未来を共に築くために、良い機械学習を民主化することをミッションとしています。このミッションに基づき、🤗 Diffusersライブラリを作成しました。これにより、誰もがテキストから画像を実験、研究、または単に遊ぶことができます。そのため、ライブラリをモジュール化されたツールボックスとして設計しました。モデルのコンポーネントをカスタマイズするか、そのまま使うことができます。 🤗 Diffusersが1周年を迎えるにあたり、コミュニティの助けを借りてライブラリに追加されたいくつかの注目すべき機能について概要をご紹介します。私たちは、アクセスしやすい使用方法を促進し、テキストから画像を生成するだけでなく、拡散モデルをさらに推進し、万能なインスピレーションを提供する熱心なコミュニティの一員であることを誇りに思っています。 目次 写真のリアルさを追求する ビデオパイプライン テキストから3Dモデルへ 画像編集パイプライン 高速拡散モデル 倫理と安全 LoRAのサポート Torch 2.0の最適化 コミュニティのハイライト 🤗 Diffusersを使用して製品を作成する 将来に向けて 写真のリアルさを追求する…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.