Learn more about Search Results TensorFlow - Page 32

- You may be interested
- Amazon AlexaのAI研究者がQUADRoを発表:Q...
- 市民データサイエンティストとは誰で、何...
- 「マーシャンの共同創設者であるイータン...
- 顧客サービス向けAI | トップ10のユースケ...
- 分析から実際の応用へ:顧客生涯価値の事例
- 「プロジェクト管理におけるGenAIスキルの...
- 人工知能に投資するのですか? 考慮すべき...
- 「Pandas 2.1の新機能」
- 「GROOTに会おう:オブジェクト中心の3D先...
- 「2023年のトップAI画像から動画を生成す...
- AIの変革の道:OpenAIのGPT-4を通してのオ...
- これら5つの必須ステップを踏まずにデータ...
- 物体検出のためのIntersection Over Union...
- なぜ無料のランチがあるのか
- 「量子コンピューティングのアプローチ、...

GraphcoreとHugging Faceが、IPU対応の新しいトランスフォーマーのラインアップを発表
GraphcoreとHugging Faceは、Hugging Face Optimumにおいて利用可能な機械学習のモダリティとタスクの範囲を大幅に拡張しました。Hugging Face Optimumは、Transformersのパフォーマンス最適化のためのオープンソースライブラリです。開発者は、GraphcoreのIPUで最高のパフォーマンスを提供するように最適化された幅広いHugging Face Transformerモデルに簡単にアクセスできるようになりました。 Optimum Graphcoreの発売後間もなく提供されたBERT Transformerモデルを含む、開発者は現在、自然言語処理(NLP)、音声、コンピュータビジョンをカバーする10のモデルにアクセスできます。これらのモデルには、IPUの設定ファイルと、事前学習および微調整済みのモデルの重みを使用するための準備が整っています。 新しいOptimumモデル コンピュータビジョン ViT(Vision Transformer)は、主要なコンポーネントとしてTransformerメカニズムを使用した画像認識の画期的な手法です。画像がViTに入力されると、言語システムで単語が処理されるのと同様に、画像は小さなパッチに分割されます。各パッチはTransformer(埋め込み)によってエンコードされ、個別に処理することができます。 NLP GPT-2(Generative Pre-trained Transformer 2)は、非常に大規模な英語のコーパスで自己教師付きの形式で事前学習されたテキスト生成Transformerモデルです。これは、テキストのラベリングを行わずに、公開されているデータを多く使用することができるため、自動的なプロセスでテキストから入力とラベルを生成することによって事前学習されました。より具体的には、文の次の単語を推測して文を生成するようにトレーニングされています。 RoBERTa(Robustly optimized BERT approach)は、自己教師付きの形式で大規模な英語のコーパスで事前学習されたTransformerモデルです(GPT-2と同様)。より具体的には、RoBERTaはマスクされた言語モデリング(MLM)の目的で事前学習されています。文を取り、モデルは入力の15%の単語をランダムにマスクし、全体のマスクされた文をモデルを通して実行し、マスクされた単語を予測する必要があります。RoBERTaはマスクされた言語モデリングに使用することができますが、主に下流タスクで微調整することを意図しています。…

Hugging Face Optimumを使用して、TransformersをONNXに変換する
ハグフェース・ハブには、毎日何百ものトランスフォーマーの実験とモデルがアップロードされています。これらの実験を行う機械学習エンジニアや学生は、PyTorch、TensorFlow/Keras、その他のさまざまなフレームワークを使用しています。これらのモデルはすでに数千の企業によって使用され、AIを搭載した製品の基盤となっています。 トランスフォーマーのモデルを本番環境で展開する場合、まずは特殊なランタイムとハードウェア上で読み込み、最適化、実行できるシリアライズされた形式にエクスポートすることをお勧めします。 このガイドでは、以下のことについて学びます: ONNXとは何か Hugging Face Optimumとは何か どのトランスフォーマーアーキテクチャがサポートされているか トランスフォーマーモデル(BERT)をONNXに変換する方法 次は何か さあ、始めましょう! 🚀 モデルを最大限の効率で実行するために最適化することに興味がある場合は、🤗 Optimumライブラリをチェックしてください。 5. 次は何か トランスフォーマーモデルをONNXに正常に変換したので、最適化および量子化ツールの全セットが使用できるようになりました。次のステップとしては、以下のことが考えられます: Optimumとトランスフォーマーパイプラインを使用した高速推論にONNXモデルを使用する モデルに静的量子化を適用して、レイテンシを約3倍改善する トレーニングにONNXランタイムを使用する ONNXモデルをTensorRTに変換してGPUパフォーマンスを向上させる … モデルを最大限の効率で実行するために最適化することに興味がある場合は、🤗 Optimumライブラリをチェックしてください。…

埋め込みを使った始め方
ノートブックコンパニオンを使用したこのチュートリアルをチェックしてください: 埋め込みの理解 埋め込みは、テキスト、ドキュメント、画像、音声などの情報の数値表現です。この表現は、埋め込まれているものの意味を捉え、多くの産業アプリケーションに対して堅牢です。 テキスト「投票の主な利点は何ですか?」に対する埋め込みは、たとえば、384個の数値のリスト(例:[0.84、0.42、…、0.02])でベクトル空間で表現されることがあります。このリストは意味を捉えているため、異なる埋め込み間の距離を計算して、2つの文の意味がどれだけ一致するかを判断するなど、興味深いことができます。 埋め込みはテキストに限定されません!画像の埋め込み(たとえば、384個の数値のリスト)を作成し、テキストの埋め込みと比較して文が画像を説明しているかどうかを判断することもできます。この概念は、画像検索、分類、説明などの強力なシステムに適用されています! 埋め込みはどのように生成されるのでしょうか?オープンソースのライブラリであるSentence Transformersを使用すると、画像やテキストから最先端の埋め込みを無料で作成することができます。このブログでは、このライブラリを使用した例を紹介しています。 埋め込みの用途は何ですか? 「[…] このMLマルチツール(埋め込み)を理解すると、検索エンジンからレコメンデーションシステム、チャットボットなど、さまざまなものを構築できます。データサイエンティストやMLの専門家である必要はありませんし、大規模なラベル付けされたデータセットも必要ありません。」- デール・マルコウィッツ、Google Cloud。 情報(文、ドキュメント、画像)が埋め込まれると、創造性が発揮されます。いくつかの興味深い産業アプリケーションでは、埋め込みが使用されます。たとえば、Google検索ではテキストとテキスト、テキストと画像をマッチングさせるために埋め込みを使用しています。Snapchatでは、「ユーザーに適切な広告を適切なタイミングで提供する」ために埋め込みを使用しています。Meta(Facebook)では、ソーシャルサーチに埋め込みを使用しています。 埋め込みから知識を得る前に、これらの企業は情報を埋め込む必要がありました。埋め込まれたデータセットを使用することで、アルゴリズムは素早く検索、ソート、グループ化などを行うことができます。ただし、これは費用がかかり、技術的にも複雑な場合があります。この投稿では、シンプルなオープンソースのツールを使用して、データセットを埋め込み、分析する方法を紹介します。 埋め込みの始め方 小規模なよく寄せられる質問(FAQ)エンジンを作成します。ユーザーからのクエリを受け取り、最も類似したFAQを特定します。米国社会保障メディケアFAQを使用します。 しかし、まず、データセットを埋め込む必要があります(他のテキストでは、エンコードと埋め込みの用語を交換可能に使用します)。Hugging FaceのInference APIを使用すると、簡単なPOSTコールを使用してデータセットを埋め込むことができます。 質問の意味を埋め込みが捉えるため、異なる埋め込みを比較してどれだけ異なるか、または類似しているかを確認することができます。これにより、クエリに最も類似した埋め込みを取得し、最も類似したFAQを見つけることができます。このメカニズムの詳細な説明については、セマンティックサーチのチュートリアルをご覧ください。 要するに、以下の手順を実行します: Inference APIを使用してメディケアのFAQを埋め込む。 埋め込まれた質問を無料ホスティングするためにHubにアップロードする。…

敵対的なデータを使用してモデルを動的にトレーニングする方法
ここで学ぶこと 💡ダイナミックな敵対的データ収集の基本的なアイデアとその重要性。 ⚒敵対的データを動的に収集し、モデルをそれらでトレーニングする方法 – MNIST手書き数字認識タスクを例に説明します。 ダイナミックな敵対的データ収集(DADC) 静的ベンチマークは、モデルの性能を評価するための広く使用されている方法ですが、多くの問題があります:飽和していたり、バイアスがあったり、抜け穴があったりし、研究者が指標の増加を追い求める代わりに、信頼性のあるモデルを構築することができません1。 ダイナミックな敵対的データ収集(DADC)は、静的ベンチマークのいくつかの問題を緩和する手法として大いに期待されています。DADCでは、人間が最先端のモデルを騙すための例を作成します。このプロセスには次の2つの利点があります: ユーザーは、自分のモデルがどれだけ堅牢かを評価できます。 より強力なモデルをさらにトレーニングするために使用できるデータを提供します。 このように騙し、敵対的に収集されたデータでモデルをトレーニングするプロセスは、複数のラウンドにわたって繰り返され、人間と合わせてより堅牢なモデルが得られるようになります1。 敵対的データを使用してモデルを動的にトレーニングする ここでは、ユーザーから敵対的なデータを動的に収集し、それらを使用してモデルをトレーニングする方法を説明します – MNIST手書き数字認識タスクを使用します。 MNIST手書き数字認識タスクでは、28×28のグレースケール画像の入力から数字を予測するようにモデルをトレーニングします(以下の図の例を参照)。数字の範囲は0から9までです。 画像の出典:mnist | Tensorflow Datasets このタスクは、コンピュータビジョンの入門として広く認識されており、標準(静的)ベンチマークテストセットで高い精度を達成するモデルを簡単にトレーニングすることができます。しかし、これらの最先端のモデルでも、人間がそれらを書いてモデルに入力したときに正しい数字を予測するのは難しいとされています:研究者は、これは静的テストセットが人間が書く非常に多様な方法を適切に表現していないためだと考えています。したがって、人間が敵対的なサンプルを提供し、モデルがより一般化するのを助ける必要があります。 この手順は以下のセクションに分けられます: モデルの設定 モデルの操作…

🤗 Datasetsでの新しいオーディオとビジョンのドキュメンテーションを紹介します
オープンで再現可能なデータセットは、良い機械学習を進めるために不可欠です。同時に、データセットは大規模な言語モデルの燃料として非常に大きく成長しています。2020年、Hugging Faceは🤗 Datasetsというライブラリを立ち上げ、以下のために専用のライブラリを提供しています: 1行のコードで標準化されたデータセットにアクセスを提供すること。 大規模なデータセットを迅速かつ効率的に処理するためのツールを提供すること。 コミュニティのおかげで、私たちは多言語および方言のNLPデータセットを数百追加しました! 🤗 ❤️ しかし、テキストデータセットは始まりに過ぎません。データは🎵 音声、📸 画像、音声とテキストの組み合わせ、画像とテキストなど、より豊かな形式で表現されています。これらのデータセットでトレーニングされたモデルは、画像の内容を説明したり、画像に関する質問に答えたりするなど、素晴らしいアプリケーションを可能にします。 🤗 Datasetsチームは、これらのデータセットタイプとの作業をできるだけ簡単にするためのツールと機能を開発してきました。音声および画像データセットの読み込みと処理についての詳細を学ぶための新しいドキュメントも追加しました。 クイックスタート クイックスタートは、ライブラリの機能についての要点を把握するために新しいユーザーが最初に訪れる場所の一つです。そのため、クイックスタートを更新して、🤗 Datasetsを使用して音声および画像データセットを処理する方法を含めました。作業したいデータセットの形態を選択し、データセットを読み込んで処理し、PyTorchまたはTensorFlowでトレーニングに使用する準備ができるまでのエンドツーエンドの例を参照してください。 クイックスタートには、新しいto_tf_dataset関数も追加されています。この関数は、データセットをtf.data.Datasetに変換するために必要なコードを自動的に記述します。これにより、データセットからシャッフルしてバッチを読み込むためのコードを書く必要がなくなります。データセットをtf.data.Datasetに変換した後は、通常のTensorFlowまたはKerasのメソッドでモデルをトレーニングすることができます。 今日はクイックスタートをチェックして、さまざまなデータセット形態での作業方法を学び、新しいto_tf_dataset関数を試してみましょう! データセットの冒険を選ぶ! 専用ガイド 各データセット形態には、それらを読み込んで処理する方法に固有のニュアンスがあります。例えば、音声データセットを読み込む場合、音声信号はAudio機能によって自動的にデコードおよびリサンプリングされます。これはテキストデータセットを読み込む場合とはかなり異なります! モダリティ固有のドキュメントをより見つけやすくするために、各モダリティごとに専用のセクションが新たに設けられ、各モダリティの読み込みと処理方法を示すガイドが提供されています。データセット形態での作業に関する特定の情報を探している場合は、まずこれらの専用セクションをご覧ください。一方で、特定ではなく広く使用できる関数は一般的な使用方法のセクションに記述されています。このような方法でドキュメントを再編成することで、将来サポートする予定の他のデータセット形式にもよりスケーラブルに対応できるようになります。 ガイドは、🤗 Datasetsの最も重要な側面をカバーするセクションに整理されています。…
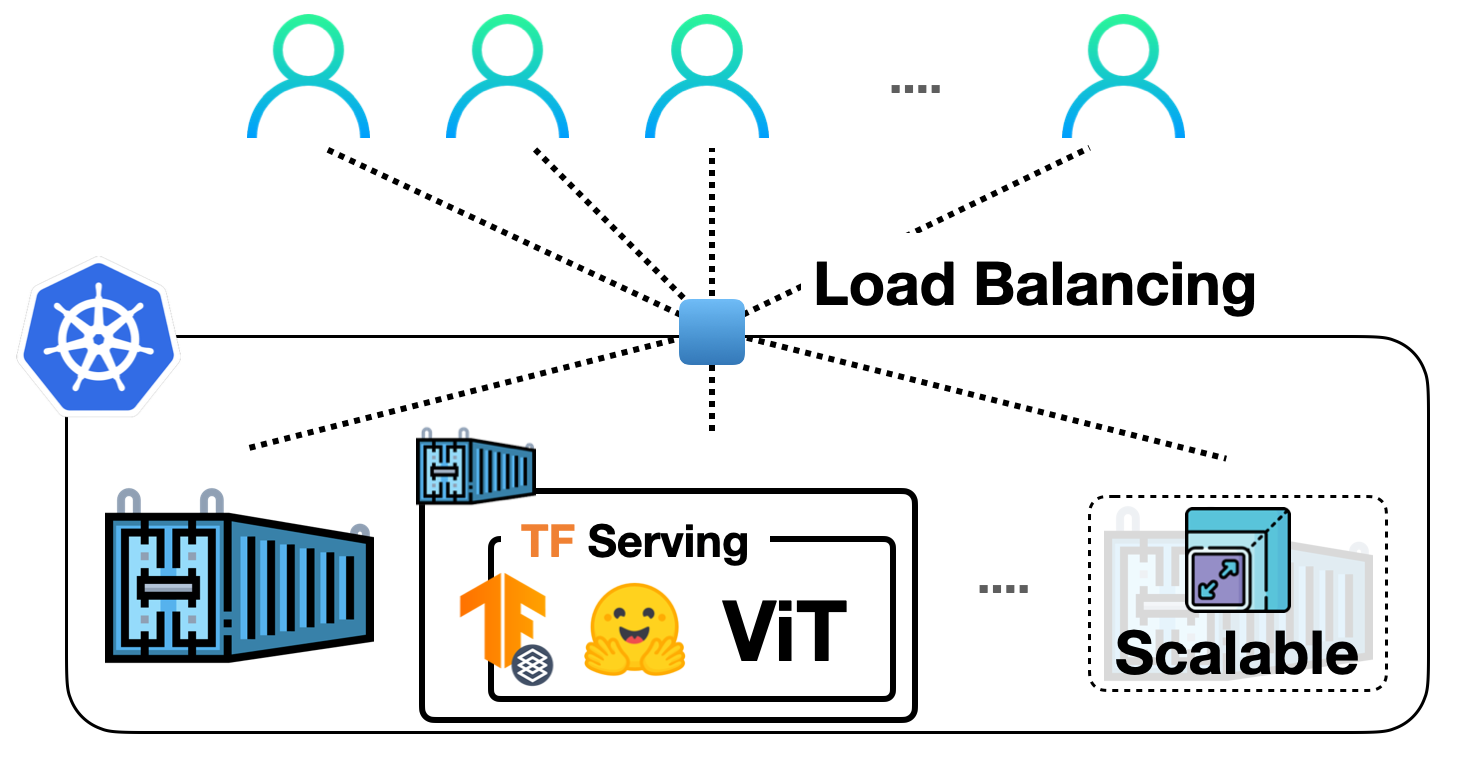
TF Servingを使用してKubernetes上に🤗 ViTをデプロイする
前の投稿では、TensorFlow Servingを使用して🤗 TransformersからVision Transformer(ViT)モデルをローカルに展開する方法を示しました。ビジョントランスフォーマーモデル内での埋め込み前処理および後処理操作、gRPCリクエストの処理など、さまざまなトピックをカバーしました! ローカル展開は、有用なものを構築するための優れたスタート地点ですが、実際のプロジェクトで多くのユーザーに対応できる展開を実行する必要があります。この投稿では、前の投稿のローカル展開をDockerとKubernetesでスケーリングする方法を学びます。したがって、DockerとKubernetesに関する基本的な知識が必要です。 この投稿は前の投稿に基づいていますので、まずそれをお読みいただくことを強くお勧めします。この投稿で説明されているコードは、このリポジトリで確認することができます。 私たちの展開をスケールアップする基本的なワークフローは、次のステップを含みます: アプリケーションロジックのコンテナ化:アプリケーションロジックには、リクエストを処理して予測を返すサービスモデルが含まれます。コンテナ化するために、Dockerが業界標準です。 Dockerコンテナの展開:ここにはさまざまなオプションがあります。最も一般的に使用されるオプションは、DockerコンテナをKubernetesクラスターに展開することです。Kubernetesは、展開に便利な機能(例:自動スケーリングとセキュリティ)を提供します。ローカルでKubernetesクラスターを管理するためのMinikubeのようなソリューションや、Elastic Kubernetes Service(EKS)のようなサーバーレスソリューションを使用することもできます。 SagemakerやVertex AIのような、MLデプロイメント固有の機能をすぐに利用できる時代に、なぜこのような明示的なセットアップを使用するのか疑問に思うかもしれません。それは考えるのは当然です。 上記のワークフローは、業界で広く採用され、多くの組織がその恩恵を受けています。長年にわたってすでに実戦投入されています。また、複雑な部分を抽象化しながら、展開に対してより細かな制御を持つことができます。 この投稿では、Google Kubernetes Engine(GKE)を使用してKubernetesクラスターをプロビジョニングおよび管理することを前提としています。GKEを使用する場合、請求を有効にしたGCPプロジェクトが既にあることを想定しています。また、GKEで展開を行うためにgcloudユーティリティを構成する必要があります。ただし、Minikubeを使用する場合でも、この投稿で説明されているコンセプトは同様に適用されます。 注意:この投稿で表示されるコードスニペットは、gcloudユーティリティとDocker、kubectlが構成されている限り、Unixターミナルで実行できます。詳しい手順は、付属のリポジトリで入手できます。 サービングモデルは、生のイメージ入力をバイトとして処理し、前処理および後処理を行うことができます。 このセクションでは、ベースのTensorFlow Servingイメージを使用してそのモデルをコンテナ化する方法を示します。TensorFlow Servingは、モデルをSavedModel形式で消費します。前の投稿でSavedModelを取得した方法を思い出してください。ここでは、SavedModelがtar.gz形式で圧縮されていることを前提としています。万が一必要な場合は、ここから入手できます。その後、SavedModelは<MODEL_NAME>/<VERSION>/<SavedModel>という特別なディレクトリ構造に配置する必要があります。これにより、TensorFlow Servingは異なるバージョンのモデルの複数の展開を同時に管理できます。 Dockerイメージの準備…
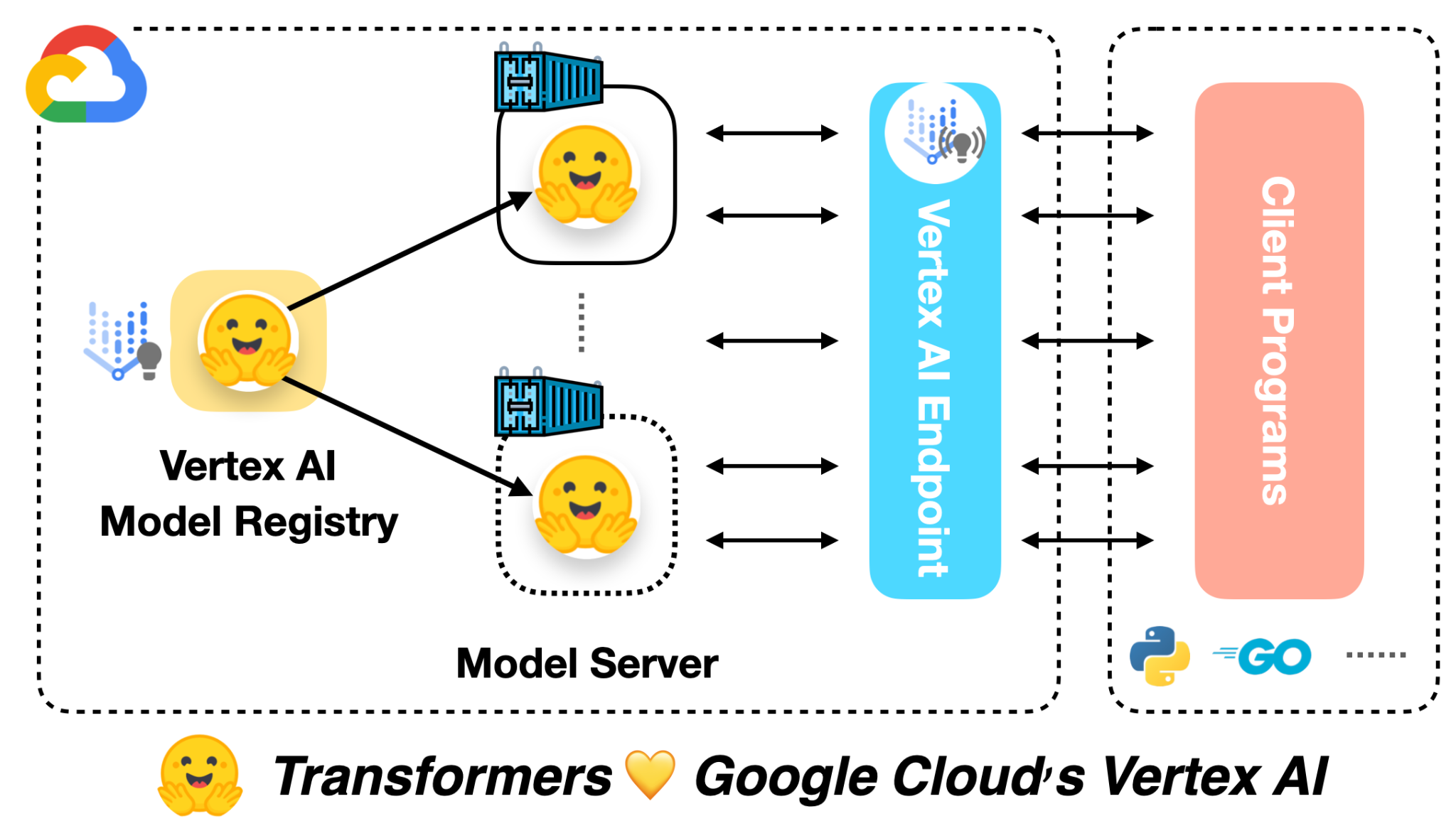
🤗 ViTをVertex AIに展開する
前の投稿では、Vision Transformers(ViT)モデルを🤗 Transformersを使用してローカルおよびKubernetesクラスター上に展開する方法を紹介しました。この投稿では、同じモデルをVertex AIプラットフォームに展開する方法を示します。Kubernetesベースの展開と同じスケーラビリティレベルを実現できますが、コードは大幅に簡略化されます。 この投稿は、上記にリンクされた前の2つの投稿を基に構築されています。まだチェックしていない場合は、それらを確認することをお勧めします。 この投稿の冒頭にリンクされたColab Notebookには、完全に作成された例があります。 Google Cloudによると: Vertex AIは、さまざまなモデルタイプと異なるレベルのMLの専門知識をサポートするツールを提供します。 モデルの展開に関しては、Vertex AIは次の重要な機能を統一されたAPIデザインで提供しています: 認証 トラフィックに基づく自動スケーリング モデルのバージョニング 異なるバージョンのモデル間のトラフィックの分割 レート制限 モデルの監視とログ記録 オンラインおよびバッチ予測のサポート TensorFlowモデルに対しては、この投稿で紹介されるいくつかの既製のユーティリティが提供されます。ただし、PyTorchやscikit-learnなどの他のフレームワークにも同様のサポートがあります。 Vertex AIを使用するには、請求が有効なGoogle Cloud…
トランスフォーマーにおける対比的探索を用いた人間レベルのテキスト生成 🤗
1. 紹介: 自然言語生成(テキスト生成)は自然言語処理(NLP)の中核的なタスクの一つです。このブログでは、現在の最先端のデコーディング手法であるコントラスティブサーチを神経テキスト生成のために紹介します。コントラスティブサーチは、元々「A Contrastive Framework for Neural Text Generation」[1]([論文] [公式実装])でNeurIPS 2022で提案されました。さらに、この続編の「Contrastive Search Is What You Need For Neural Text Generation」[2]([論文] [公式実装])では、コントラスティブサーチがオフザシェルフの言語モデルを使用して16の言語で人間レベルのテキストを生成できることが示されています。 [備考] テキスト生成に馴染みのないユーザーは、このブログ記事を詳しくご覧ください。 2.…
タンパク質を用いたディープラーニング
この記事を書く際には、2つの対象読者を想定しています。1つ目は機械学習に入門しようとしている生物学者であり、もう1つは生物学に入門しようとしている機械学習者です。もし生物学または機械学習のいずれにも詳しくない場合でも、どうぞご参加ください。ただし、時折混乱するかもしれません。そして、両方に詳しい場合は、この記事は必要ないかもしれません – これらのモデルが実際にどのように機能するかを確認するために、直接例のノートブックに移動できます: タンパク質言語モデルのファインチューニング(PyTorch、TensorFlow) ESMFoldを使用したタンパク質の折りたたみ(現時点ではopenfoldの依存関係のため、PyTorchのみ) 生物学者向けの紹介:言語モデルとは一体何なのか? タンパク質を扱うモデルは、BERTやGPTのような大規模な言語モデルに強く影響を受けています。したがって、これらのモデルがどのように機能するかを理解するために、2016年ごろに遡ってみましょう。ドナルド・トランプはまだ選出されておらず、Brexitも起こっておらず、ディープラーニング(DL)は毎日新記録を打ち立てている最新の技術です。DLの成功の鍵は、人工ニューラルネットワークを使用してデータの複雑なパターンを学習することです。ただし、DLには1つの重大な問題があります – 実際には、良い結果を得るためには非常に多くのデータが必要であり、多くのタスクではそのデータが利用できませんでした。 例えば、英語の文を入力として受け取り、それが文法的に正しいかどうかを判断するためのDLモデルを訓練したいとしましょう。そのためにトレーニングデータを集めると、以下のようなものになるでしょう: 理論的には、当時このタスクは完全に可能でした – このようなトレーニングデータをDLモデルに与えれば、新しい文が文法的に正しいかどうかを予測することができるようになるはずです。しかし、実際にはうまくいかなかったのです。なぜなら、2016年当時、ほとんどの人々が各タスクごとに新しいモデルをランダムに初期化していたからです。これはつまり、モデルがトレーニングデータの例だけから必要なすべての知識を学ぶ必要があったということです! それがどれほど困難であるかを理解するために、機械学習モデルであり、私があなたに学習してほしいタスクのトレーニングデータを与えるとします。以下に示します: ここで、あなたが見たことのない言語を選んだため、おそらく自信を持ってこのタスクを学習できるとは思えません。おそらく何百回も何千回もの例を見るまで、入力の中で再発する単語やパターンをいくつか見つけ出すことができるかもしれません。その場合でも、新しい単語や一般的でない表現が登場すると、あなたは間違った予測をする可能性があります。偶然ではありませんが、当時のDLモデルの性能もほぼ同じでした! では、同じタスクを英語で試してみましょう: 今回は簡単です – タスクは単に映画のレビューがポジティブ(1)かネガティブ(0)かを予測することです。2つのポジティブな例と2つのネガティブな例だけで、おそらくほぼ100%の正確さでこのタスクを達成できるでしょう。なぜなら、英語の語彙や文法、映画や感情表現に関する文化的な文脈について、すでに豊富な前提知識を持っているからです。その知識がなければ、最初のタスクのような状況になります – 入力の中にさえ表面的なパターンを見つけるには、膨大な数の例を読む必要があります。そして、何十万もの例を研究する時間をかけても、英語のタスクにおいてたった4つの例だけで得られるよりもはるかに正確な予測はできません。 重要なブレークスルー:転移学習 機械学習では、このような既知の知識を新しいタスクに転移する概念を「転移学習」と呼びます。このような転移学習をDLにうまく適用することは、2016年ごろのこの分野の主要な目標でした。2016年までには、事前学習された単語ベクトル(非常に興味深いものですが、このブログ記事の範囲外です!)などが存在し、一部の知識が新しいモデルに転移できるようになっていましたが、この知識の転移はまだ比較的表面的であり、モデルはまだ大量のトレーニングデータが必要でした。 この状況は2018年まで続きました。その年、ULMFiTと後にBERTという2つの重要な論文が発表されました。これらは、自然言語の転移学習を本当にうまく機能させた最初の論文であり、特にBERTは事前学習された大規模な言語モデルの時代の始まりを示しました。両論文で共有されているトリックは、ディープラーニングの人工ニューラルネットワークの内部構造を利用したものです…

人間のフィードバックからの強化学習(RLHF)の説明
この記事は以下の言語に翻訳されています:中国語(簡体字)とベトナム語。他の言語に翻訳に興味がありますか?nathan at huggingface.co までお問い合わせください。 言語モデルは、過去数年間に人間の入力プロンプトから多様で魅力的なテキストを生成する能力を示してきました。しかし、「良い」テキストとは何かは、主観的で文脈に依存するため、本質的に定義するのは難しいです。創造性を求める物語の執筆などの多くのアプリケーションでは、真実であるべき情報の断片、または実行可能なコードのスニペットなどが必要です。 これらの属性を捉えるための損失関数を作成することは困難であり、ほとんどの言語モデルはまだ単純な次のトークン予測の損失(例:クロスエントロピー)で訓練されています。損失自体の欠点を補うために、人々はBLEUやROUGEなど、人間の優先順位をより適切に捉えるように設計されたメトリクスを定義しています。これらのメトリクスは、パフォーマンスを測定する上で損失関数自体より適しているものの、生成されたテキストを単純なルールで参照テキストと比較するだけなので、制約もあります。生成されたテキストに対する人間のフィードバックをパフォーマンスの指標として使用するか、さらに進んでそのフィードバックを損失としてモデルを最適化することができれば、素晴らしいことではないでしょうか?それが「人間のフィードバックによる強化学習(RLHF)」のアイデアです。強化学習の手法を使用して、言語モデルを人間のフィードバックで直接最適化するのです。RLHFにより、言語モデルは一般的なテキストデータのコーパスで訓練されたモデルを複雑な人間の価値に合わせることができるようになりました。 RLHFの最近の成功例は、ChatGPTでの使用です。ChatGPTの印象的な能力を考慮して、RLHFについて説明してもらいました: それは驚くほどうまくいっていますが、すべてをカバーしているわけではありません。それらのギャップを埋めましょう! 人間のフィードバックによる強化学習(RL from human preferencesとも呼ばれます)は、複数のモデルのトレーニングプロセスと異なる展開の段階を伴うため、難しい概念です。このブログ記事では、トレーニングプロセスを次の3つの主要なステップに分解します: 言語モデル(LM)の事前トレーニング データの収集と報酬モデルのトレーニング 強化学習によるLMの微調整 まず、言語モデルの事前トレーニングについて見ていきましょう。 言語モデルの事前トレーニング RLHFの出発点として、クラシカルな事前トレーニング目標で既に事前トレーニングされた言語モデルを使用します(詳細については、このブログ記事を参照してください)。OpenAIは、最初の人気のあるRLHFモデルであるInstructGPTに対して、より小さなバージョンのGPT-3を使用しました。Anthropicは、このタスクのためにトレーニングされた1,000万から520億のパラメータを持つトランスフォーマーモデルを使用しました。DeepMindは、2800億のパラメータモデルGopherを使用しました。 この初期モデルは、追加のテキストや条件で微調整することもできますが、必ずしも必要ではありません。たとえば、OpenAIは「好ましい」とされる人間が生成したテキストを微調整し、Anthropicは彼らの「助けになり、正直で無害な」基準に基づいて元のLMを蒸留することで、RLHFのための初期LMを生成しました。これらは共に、私が高価な増強データと呼ぶものの一部ですが、RLHFを理解するために必要なテクニックではありません。 一般的に、「どのモデル」がRLHFの出発点として最適かは明確な答えがありません。このブログ記事では、RLHFのトレーニングにおけるオプションの設計空間が完全に探索されていないという共通のテーマになります。 次に、言語モデルが必要なデータを生成して、人間の優先順位がシステムに統合される「報酬モデル」をトレーニングする必要があります。 報酬モデルのトレーニング 人間の優先順位に合わせてキャリブレーションされた報酬モデル(RM、優先モデルとも呼ばれます)を生成することは、RLHFの比較的新しい研究の出発点です。その基本的な目標は、テキストのシーケンスを受け取り、数値で人間の優先順位を表すべきスカラー報酬を返すモデルまたはシステムを取得することです。システムはエンドツーエンドのLMであるか、報酬を出力するモジュラーシステム(例:モデルが出力をランク付けし、ランキングが報酬に変換される)である場合があります。出力がスカラーの報酬であることは、既存のRLアルゴリズムが後のRLHFプロセスにシームレスに統合されるために重要です。 報酬モデリングのためのこれらの言語モデルは、別の微調整された言語モデルまたは好みのデータでスクラッチからトレーニングされた言語モデルのいずれかです。例えば、Anthropicは、これらのモデルを事前トレーニング(好みモデルの事前トレーニング、PMP)の後に初期化するために専門の微調整方法を使用しています。彼らは、これが微調整よりもサンプル効率が高いと結論付けましたが、報酬モデリングのバリエーションの中で明確な最良の選択肢はありません。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.