Learn more about Search Results ML - Page 329

- You may be interested
- 確定論的 vs 確率的 – 機械学習の基礎
- ツリー構造パーゼン推定器(Hyperopt)を...
- 「LegalBenchとは:英語の大規模言語モデ...
- FitBot — フィットネスチャットボットエー...
- 「OSMネットワークでの移動時間によって重...
- ディープシークLLM:中国の最新の言語モデル
- 「生成AIにおけるニューラル微分方程式の...
- AI「ブレイクスルー」:ニューラルネット...
- バイオセンサーがリアルタイムの透析フィ...
- 「人型ロボットは人間よりも飛行機を操縦...
- エイリアシング:あなたのタイムシリーズ...
- 東京理科大学の研究者は、材料科学におけ...
- Google AIがFlan-T5をオープンソース化 NL...
- UCLAの研究者が、最新の気候データと機械...
- アントロピックは、SKテレコムから1億ドル...

「5層データスタックの構築方法」
「パワフルなツールコンポーネントの選択肢は、データパイプラインの各層が独自の機能を提供する一元化された拡張可能なデータプラットフォームを作り出しますオーガとは異なります...」

画像認識とコンピュータビジョン:違いは何ですか?
現在の人工知能(AI)と機械学習(ML)の業界では、「画像認識」と「コンピュータビジョン」が最も注目されているトレンドの2つですこれらの分野では、視覚的な特徴の識別に取り組むため、これらの用語はしばしば互換性があるとされますいくつかの類似点があるにもかかわらず、コンピュータビジョンと画像認識は異なる技術を表しています[...]
LLMのトレーニングの異なる方法
大規模言語モデル(LLM)の領域では、さまざまなトレーニングメカニズムがあり、異なる手段、要件、目標がありますそれぞれが異なる目的を果たすため、混同しないようにすることが重要です...

『オープンソースAIゲームジャムの結果』
7月7日から7月11日まで、私たちは初めてのオープンソースAIゲームジャムを開催しました。これは、AIを使用して48時間以内に革新的なゲームを作成するというエキサイティングなイベントでした。 主な目的は、少なくとも1つのオープンソースAIツールを組み込んだゲームを作成することでした。プロプライエタリなAIツールも使用できましたが、参加者にはオープンソースのツールをゲームやワークフローに統合することを奨励しました。 私たちの取り組みへの反応は、予想を上回り、1300人以上のサインアップと88の素晴らしいゲームの応募がありました。 こちらで試すことができます👉 https://itch.io/jam/open-source-ai-game-jam/entries テーマ:拡大 創造性を刺激するために、「拡大」というテーマを選びました。これについては解釈を自由にし、開発者がアイデアを探求し実験することを許し、多様なゲームが生まれました。 ゲームは、その楽しさ、創造性、テーマへの適合度に基づいて、同僚や貢献者によって評価されました。 上位10作品は、その後、ディラン・エバート、トーマス・シモニーニ、オマール・サンセヴィエロの3人の審査員によって最優秀作品が選ばれました。 優勝者 🏆🥇 慎重な審議の結果、審査員は1つの優れたゲームをオープンソースAIゲームジャムの優勝者に選びました。 それはohmletの「Snip It」です 👏👏👏。 コード:Ruben Gres AIアセット:Philippe Saade 音楽/SFX:Matthieu Deloffre このAI生成ゲームでは、絵画が生き返る美術館を訪れます。絵画内のオブジェクトを切り取って隠された秘密を明らかにしてください。 こちらでプレイできます 👉…

「OpenAIは、パーソナライズされたAIインタラクションのためのChatGPTのカスタムインストラクションを開始」
OpenAIは、AI言語モデルChatGPTのユーザーコントロールを向上させるために、新しい機能「カスタムインストラクション」を導入することで、重要な一歩を踏み出しました。この最新のアップデートは、インタラクションを効率化し、ユーザーによりパーソナライズされた体験を提供することを目的としています。本記事では、この新機能のさまざまな側面を探り、有効にする方法を学びます。 また読む:GoogleがNotebookLMを導入:あなたのパーソナライズされた仮想研究アシスタント 効率的な会話のための強化されたコントロール カスタムインストラクション機能により、ChatGPTのユーザーは、AIチャットボットとの対話時に繰り返しの指示プロンプトを回避することができます。ユーザーは、会話の中で「1,000単語以下で回答を書く」といった指示や「返答のトーンを形式的に保つ」といった指示を繰り返し含める必要がもはやありません。代わりに、一度設定するだけで、ChatGPTが対話全体でコンテキストを覚えておくことができます。これにより、プロセスがより効率的かつユーザーフレンドリーになります。 また読む:プロンプトエンジニアリング:強力なプロンプトの作成術 パーソナライズされたAIインタラクションの導入 カスタムインストラクションの主な利点は、より適したAIインタラクション体験を作り出す能力です。この機能により、ユーザーは自分の好みやガイドラインを確立し、ChatGPTが彼らのニーズに正確に合った応答を生成することができます。カスタマイズオプションは、学術的な執筆、プロフェッショナルな文通、クリエイティブなストーリーテリングなど、さまざまなユースケースに対応するように設計されています。 また読む:MicrosoftがLLM向けの自動プロンプト最適化フレームワークを導入 プラグインとのシームレスな統合 カスタムインストラクション機能の興味深い側面の一つは、プラグインとの互換性です。たとえば、ユーザーはプラグインを使用しながらカスタムインストラクションを利用することで、現在の位置に基づいたパーソナライズされた推奨を受けることができます。この統合により、AIによる体験がさらに豊かになり、レストランの提案や現在地に特化したフライトオプションを探しているユーザーに特に役立つことがあります。 また読む:ChatGPTのプラグインとWebブラウジングは何に使えるのか? 利用可能性の制限 本日より、カスタムインストラクションのベータ版がPlusプランのユーザーに提供されています。その後の数週間を通じて、この機能は徐々にすべてのChatGPTユーザーに拡大され、より広範なユーザーがこの改良されたユーザーエクスペリエンスにアクセスできるようになります。ただし、カスタムインストラクション機能は、ヨーロッパ連合(EU)およびイギリス(UK)に拠点を置くユーザーには現時点では利用できないことに注意が必要です。 また読む:OpenAIがChatGPTの「Bingでブラウズする」機能を無効化:何が起こったのか? データの利用とモデルのトレーニング OpenAIは、これらのカスタマイズされた応答を通じて収集されたデータを、APIモデルのパフォーマンス向上に活用することを重視しています。これにより、ユーザーがカスタムインストラクションを使用してChatGPTとの対話を続ける限り、AI言語モデルは継続的に改善され、より正確でコンテキストに即した応答が提供されます。 データプライバシーに関する懸念に対応するため、OpenAIはユーザーが自分の情報を制御できると断言しています。モデルのトレーニングへの貢献を望まないユーザーは、データコントロールを通じてこのオプションを無効にすることができます。 また読む:生成的AIツールを使用する際のプライバシー保護のための6つの手順 OpenAIが別のChatGPTアップデートを発表 カスタムインストラクションの導入と同時に、OpenAIはChatGPT Plusの顧客向けのメッセージ容量を大幅に増やすことを発表しました。来週から、Plusプランのユーザーは3時間あたり最大50件のメッセージを送信することができ、以前の制限の倍増となります。この拡大により、ChatGPTとの有意義なAI対話に参加するためのさらなる可能性が開かれます。 また読む:ChatGPTがより安価になり、新機能が追加されました ChatGPTでカスタムインタラクションを有効にする方法 私たちの意見…
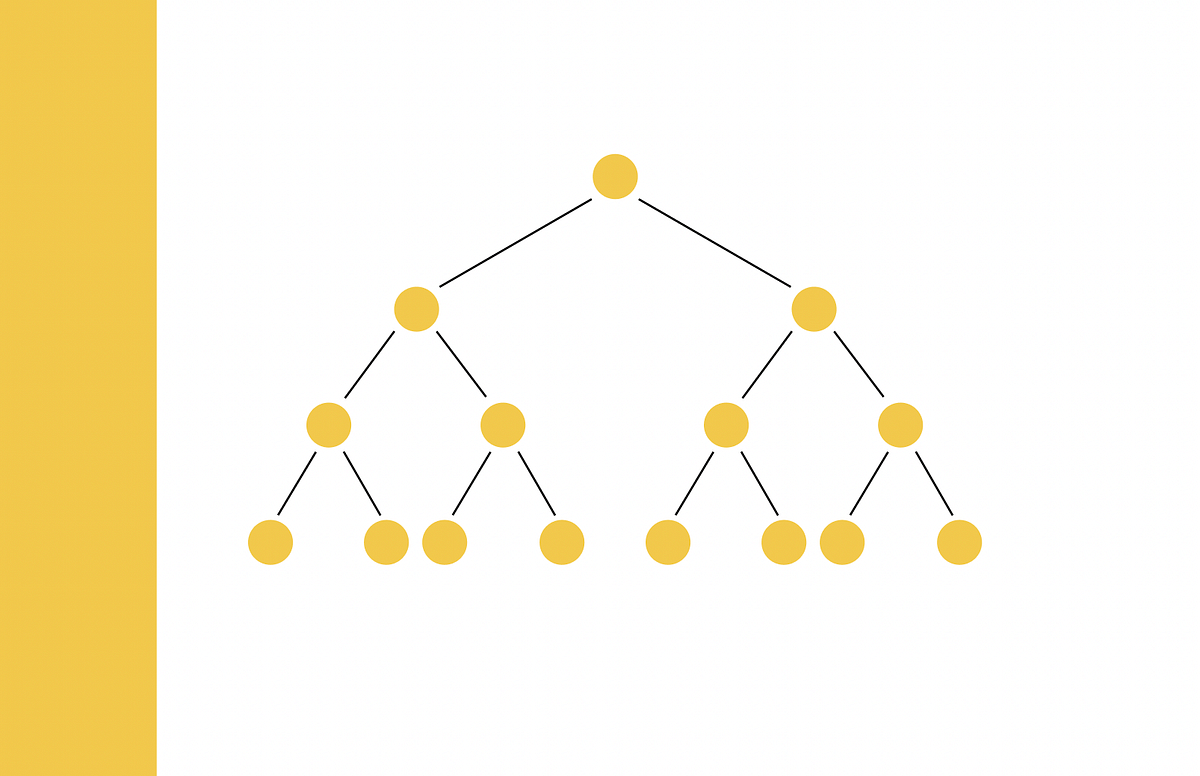
類似検索、パート6:LSHフォレストによるランダム射影
「類似検索」とは、クエリが与えられた場合に、データベース内のすべてのドキュメントの中から、それに最も類似したドキュメントを見つけることを目指す問題ですデータサイエンスにおいては、類似検索はしばしばNLP(自然言語処理)で現れます...

このAI論文では、「Retentive Networks(RetNet)」を大規模言語モデルの基礎アーキテクチャとして提案していますトレーニングの並列化、低コストの推論、そして良好なパフォーマンスを実現しています
Transformerは、最初に順次トレーニングの問題を解決するために開発されたものであり、その後、大規模な言語モデルのデファクトアーキテクチャとして受け入れられるようになりました。TransformerのO(N)のステップごとの複雑さとメモリバウンドのキーバリューキャッシュは、デプロイメントには適しておらず、トレーニングの並列性を犠牲にして推論性能が低下します。シーケンスの長さの増加は推論速度を遅くし、レイテンシを増加させ、GPUメモリをより多く使用します。次世代のアーキテクチャは、トランスフォーマーと同様のトレーニングの並列性と競争力のあるパフォーマンスを維持しながら、効果的なO(1)の推論を実現するために、広範な開発が続けられています。 図1:RetNetは「不可能な三角形」を実現し、トレーニングの並列性、高いパフォーマンス、低コストの推論を同時に実現します。 図1の「不可能な三角形」は、上記の目標を同時に達成するのがどれだけ困難であるかを示しています。3つの主要な研究分野が存在します。まず、線形化されたアテンションは、カーネルϕ(q)。ϕ(k)を使用して従来のアテンションスコアexp(q。k)を近似することで、自己回帰的な推論を書き直します。この手法は、トランスフォーマーに比べてパフォーマンスが劣るため、人気が向上する可能性があります。2番目の研究では、効果的な推論のために、並列トレーニングを捨てて再帰モデルを使用します。要素ごとの演算子を使用してアクセラレーションを修正しますが、これにより表現能力とパフォーマンスが犠牲になります。3番目の研究では、S4やその変種などの代替メカニズムをアテンションに代わって使用することが調査されています。 以前の研究では、トランスフォーマーと比較して明確な勝者はいません。マイクロソフトリサーチと清華大学の研究者は、RetNetと呼ばれる保持ネットワーク(RetNet)を提案しました。RetNetは、低コストの推論、効果的な長シーケンスモデリング、トランスフォーマーと同等のパフォーマンス、並列モデルトレーニングを同時に提供します。彼らは、マルチスケールの保持メカニズムを提供し、マルチヘッドアテンションを置き換えるために類似、再帰、チャンクごとの再帰表現を使用します。まず、並列表現により、トレーニングの並列性を完全にGPUデバイスで利用できます。次に、再帰表現により、メモリと計算に関して効率的なO(1)の推論が可能になります。デプロイメントの費用とレイテンシを大幅に削減できます。 キーバリューキャッシュ技術を使用せずに、この手法ははるかに簡単です。さらに、チャンクごとの再帰表現を使用することで、効果的な長シーケンスモデリングが可能です。彼らは、グローバルブロックを繰り返しエンコードしてGPUメモリを節約し、同時に各ローカルブロックをエンコードして処理を高速化します。RetNetをトランスフォーマーとその派生物と比較するために、包括的な試験を行います。言語モデリングの実験結果によると、RetNetはスケーリング曲線とコンテキスト学習の面で一貫して競争力があります。また、RetNetの推論コストは長さに影響されません。 RetNetは、7Bモデルと8kシーケンス長の場合、キーバリューキャッシュを使用するトランスフォーマーよりも8.4倍高速にデコードされ、メモリ使用量が70%減少します。RetNetは、通常のトランスフォーマーよりもトレーニングが加速し、高度に最適化されたFlashAttentionよりも優れたパフォーマンスを発揮しながら、25〜50%のメモリを節約します。RetNetの推論レイテンシはバッチサイズに影響されず、非常に高いスループットが可能です。RetNetは、魅力的な機能を備えた大規模な言語モデルのための強力なトランスフォーマーの代替です。
「AIスタートアップのトレンド:Y Combinatorの最新バッチからの洞察」
シリコンバレーを拠点とする有名なスタートアップアクセラレータであるY Combinator(YC)は、最近、2023年冬のコホートを発表しました予想通り、269社のうち約31%のスタートアップ(80社)がAIを自己申告しています

「Hugging Faceを使用してLLMsを使ったテキスト要約機を構築する」
はじめに 最近、LLMs(Large Language Models)を使用したテキスト要約は多くの関心を集めています。これらのモデルは、GPT-3やT5などの事前訓練モデルであり、人間のようなテキストやテキスト分類、要約、翻訳などのタスクを生成することができます。Hugging Faceは、LLMsを使用するための人気のあるライブラリの一つです。 この記事では、特にHugging Faceに焦点を当てて、LLMの能力について検討し、難解なNLPの問題を解決するための適用方法について説明します。また、Hugging FaceとLLMsを使用して、Streamlit用のテキスト要約アプリケーションを構築する方法についても説明します。まずは、この記事の学習目標について見てみましょう。 学習目標 Hugging Faceをプラットフォームとして使用したLLMsとTransformersの機能と機能を探索する。 Hugging Faceが提供する事前訓練モデルとパイプラインを活用して、チャットボットなどのさまざまなNLPタスクを実行する方法を学ぶ。 Hugging FaceとLLMsを使用したテキスト要約の実践的な理解を開発する。 テキスト要約のための対話型Streamlitアプリケーションを作成する。 この記事は、データサイエンスのブログマラソンの一環として公開されました。 大規模言語モデル(LLMs)の理解 LLMモデルは大量のテキストデータで訓練されます。これらのモデルは、前の文脈に基づいて次の単語を予測することにより、複雑な言語パターンを捉え、一貫したテキストを生成することができます。 LLMsは大量のパラメータを含むデータセットで訓練されます。訓練データの膨大な量により、LLMsは言語の微妙なニュアンスを学び、印象的な言語生成能力を提供することができます。 LLMsは機械翻訳、テキスト生成、質問応答、感情分析などのさまざまなタスクでの突破口を可能にし、NLPの分野に大きな影響を与えました。 これらのモデルはベンチマークで優れたパフォーマンスを発揮し、多くのNLPタスクにおいて頼りになるツールとなっています。 Hugging Face…

魅力的な生成型AIの進化
イントロダクション 人工知能の広がり続ける領域において、研究者、技術者、愛好家の想像力を捉えているのは、ジェネラティブAIという魅力的な分野です。これらの巧妙なアルゴリズムは、ロボットが日々できることや理解できる範囲の限界を em>押し広げ、新たな発明と創造性の時代を迎えています。このエッセイでは、ジェネラティブAIの進化の航海に乗り出し、その謙虚な起源、重要な転換点、そしてその進路に影響を与えた画期的な展開について探求します。 ジェネラティブAIが芸術や音楽、医療や金融などさまざまな分野を革新した方法について調べ、単純なパターンを作成しようとする初期の試みから、現在の息をのむような傑作まで進化してきたことを見ていきます。ジェネラティブAIの将来の可能性について深い洞察を得るためには、その誕生につながった歴史的な背景と革新を理解する必要があります。機械が創造、発明、想像力の能力を持つようになった経緯を探求しながら、人工知能と人間の創造性の分野を永遠に変えた過程をご一緒に見ていきましょう。 ジェネラティブAIの進化のタイムライン 人工知能の絶え間なく進化する景色の中で、ジェネラティブAIという分野は、他のどの分野よりも多くの魅力と好奇心を引き起こしました。初期の概念から最近の驚異的な業績まで、ジェネラティブAIの旅は非常に特異なものでした。 このセクションでは、時間をかけて魅力的な旅に乗り出し、ジェネラティブAIの発展を形作ったマイルストーンを解明していきます。我々は、重要なブレイクスルー、研究論文、進歩を探求し、その成長と進化を包括的に描写します。 革新的な概念の誕生、影響力のある人物の出現、ジェネラティブAIの産業への浸透を見ながら、我々と一緒に歴史の旅に出かけ、生活を豊かにし、私たちが知っているAIを革新するジェネラティブAIの誕生を目撃しましょう。 1805年:最初のニューラルネットワーク(NN)/ 線形回帰 1805年、アドリアン=マリー・ルジャンドルは、入力層と単一の出力ユニットを持つ線形ニューラルネットワーク(NN)を導入しました。ネットワークは、重み付け入力の合計として出力を計算します。これは、現代の線形NNの基礎となる最小二乗法を用いた重みの調整を行い、浅い学習とその後の複雑なアーキテクチャの基礎となりました。 1925年:最初のRNNアーキテクチャ 1920年代、物理学者のエルンスト・イージングとヴィルヘルム・レンツによって、最初の非学習RNNアーキテクチャ(イージングまたはレンツ・イージングモデル)が導入され、分析されました。これは、入力条件に応じて平衡状態に収束し、最初の学習RNNの基盤となりました。 1943年:ニューラルネットワークの導入 1943年、ウォーレン・マクカロックとウォルター・ピッツによって、ニューラルネットワークの概念が初めて紹介されました。生物のニューロンの働きがそのインスピレーションとなっています。ニューラルネットワークは、電気回路を用いてモデル化されました。 1958年:MLP(ディープラーニングなし) 1958年、フランク・ローゼンブラットが最初のMLPを導入しました。最初の層は学習しない非学習層であり、重みはランダムに設定され、適応的な出力層がありました。これはまだディープラーニングではありませんでしたが、最後の層のみが学習されるため、ローゼンブラットは正当な帰属なしに後にエクストリームラーニングマシン(ELM)として再ブランドされるものを基本的に持っていました。 1965年:最初のディープラーニング 1965年、アレクセイ・イヴァハネンコとヴァレンティン・ラパによって、複数の隠れ層を持つディープMLPのための最初の成功した学習アルゴリズムが紹介されました。 1967年:SGDによるディープラーニング 1967年、甘利俊一は、スクラッチから確率的勾配降下法(SGD)を用いて複数の層を持つマルチレイヤーパーセプトロン(MLP)を訓練する方法を提案しました。彼らは、高い計算コストにもかかわらず、非線形パターンを分類するために2つの変更可能な層を持つ5層のMLPを訓練しました。 1972年:人工RNNの発表 1972年、阿弥俊一はレンツ・イジング再帰型アーキテクチャを適応的に変更し、接続重みを変えることで入力パターンと出力パターンを関連付ける学習を可能にしました。10年後、阿弥ネットワークはホプフィールドネットワークとして再発表されました。 1979年:ディープコンボリューショナルNN…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.