Learn more about Search Results A - Page 322

- You may be interested
- 「セグミンドの生成AIによるエンパワーリ...
- 「ファインチューニング中に埋め込みのア...
- 映像作家のサラ・ディーチシーが今週の「N...
- 新しいAI研究が、転移学習のためのマルチ...
- 「PDFドキュメントを使用したオブジェクト...
- 機械学習の専門家 – ルイス・タンス...
- 「ゼロからヒーローへ:PyTorchで最初のML...
- アカデミックパートナーがスタートアップ...
- 自分のハードウェアでのコード理解
- 「OpenAIがGPT-4へのアクセスを提供」
- 「機械学習を学ぶにはどれくらいの時間が...
- 「VirtuSwapがAmazon SageMaker Studioの...
- LLMOps – MLOpsの次のフロンティア
- 「最適効率のための証明済み戦略:Azure V...
- 「CMUとマックス・プランク研究所の研究者...
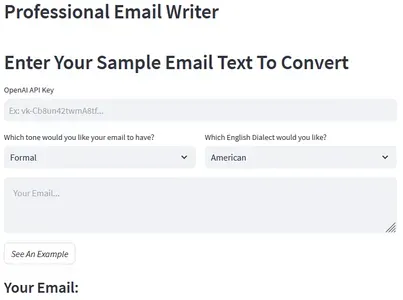
「OpenAIとLangchainを使用した言語的なメール作成Webアプリケーション」
はじめに この記事では、Langchainの助けを借りてOpenAIを使用してウェブアプリケーションを構築する方法について説明します。このウェブアプリは、ユーザーが非構造化のメールを正しくフォーマットされた英語に変換することができます。ユーザーはメールのテキストを入力し、希望するトーンと方言(フォーマル/インフォーマルおよびアメリカン/ブリティッシュイングリッシュ)を指定することができます。アプリは選択したスタイルで美しくフォーマットされたメールを提供します。私たちは毎回スケールアプリケーションを構築することはできません。クエリとともにプロンプトをコピーして貼り付けるだけではありません。代わりに、さあ始めましょう、そしてこの素晴らしい「Professional Email Writer」ツールを構築しましょう。 学習目標 Streamlitを使用して美しいウェブアプリケーションを構築する方法を学ぶ。 プロンプトエンジニアリングとは何か、メールの生成に効果的なプロンプトを作成する方法を理解する。 LangchainのPromptTemplateを使用してOpenAI LLMをクエリする方法を学ぶ。 Streamlitを使用してPythonアプリケーションをデプロイする方法を学ぶ。 この記事はData Science Blogathonの一部として公開されました。 Streamlitのセットアップ まず、Streamlitが何であるか、どのように機能するか、そしてユースケースに設定する方法を理解する必要があります。Streamlitを使用すると、Pythonでウェブアプリケーションを作成し、ローカルおよびWeb上でホストすることができます。まず、ターミナルに移動し、以下のコマンドを使用してStreamlitをインストールします。 pip install streamlit スクリプト用の空のPythonファイルを作成し、以下のコマンドを使用してファイルを実行します。 python -m streamlit run [your_file_name.py]…

「LP-MusicCapsに会ってください:データの乏しさ問題に対処するための大規模言語モデルを使用したタグから疑似キャプション生成アプローチによる自動音楽キャプション作成」
音楽のキャプション生成は、与えられた音楽トラックの自然言語による説明を生成することによる音楽情報の検索です。生成されるキャプションは文章のテキストによる説明であり、音楽タグ付けなどの他の音楽の意味理解のタスクとは異なります。これらのモデルは一般的にエンコーダ・デコーダのフレームワークを使用します。 音楽のキャプション生成に関する研究は大幅に増加しています。しかし、その重要性にもかかわらず、これらの技術を研究する研究者は、データセットの収集に伴う費用のかかる手間のかかる課題に直面しています。また、利用可能な音楽言語データセットの数が限られているため、音楽のキャプションモデルの訓練は容易ではありません。大規模言語モデル(LLM)は、音楽のキャプション生成の潜在的な解決策となる可能性があります。LLMは、10億を超えるパラメータを持つ最先端のモデルであり、少数またはゼロの例を用いてタスクを処理する能力において印象的な能力を示します。これらのモデルは、Wikipedia、GitHub、チャットログ、医学記事、法律記事、書籍、およびインターネットからクロールされたウェブページなど、多様な情報源からの膨大なテキストデータで訓練されます。幅広い訓練により、これらのモデルはさまざまな文脈とドメインで単語を理解し解釈することができます。 その後、韓国の研究者チームが、LP-MusicCaps(Large language-based Pseudo music caption dataset)と呼ばれる方法を開発しました。これは、LLMを慎重にタグ付けデータセットに適用して音楽のキャプションデータセットを作成するものです。彼らは、自然言語処理のフィールドで使用されるさまざまな定量的評価指標と人間の評価による大規模な音楽のキャプションデータセットの体系的な評価を行いました。その結果、約220万のキャプションと50万のオーディオクリップがペアになりました。まず、彼らは音楽のキャプションデータセットLP-MusicCapsを生成するためのLLMベースのアプローチを提案しました。次に、LLMによって生成された音楽のキャプションのための体系的な評価スキームを提案しました。そして、LP-MusicCapsで訓練されたモデルがゼロショットおよび転移学習のシナリオでうまく機能することを実証し、LLMベースの擬似音楽キャプションの使用を正当化しました。 研究者たちは、既存の音楽タグ付けデータセットから複数のラベルタグを収集することから始めました。これらのタグは、ジャンル、ムード、楽器など、音楽のさまざまな側面を含んでいます。彼らは、音楽トラックの説明的な文を生成するためのタスク指示を慎重に作成し、それが大言語モデルの入力(プロンプト)として機能しました。彼らは、優れたパフォーマンスを持つGPT-3.5 Turbo言語モデルを選択して音楽のキャプション生成を行うために、強力なGPT-3.5 Turbo言語モデルを選択しました。GPT-3.5 Turboのトレーニングプロセスは、膨大なデータコーパスを使用した初期フェーズがあり、膨大な計算能力の恩恵を受けました。その後、人間のフィードバックによる強化学習を用いて微調整を行いました。この微調整プロセスは、モデルの指示との効果的な相互作用能力を向上させることを目的としています。 研究者たちは、このLLMベースのキャプション生成器をテンプレートベースの方法(タグの連結、プロンプトテンプレート)およびK2C拡張と比較しました。K2C拡張の場合、指示が存在しない場合、生成されるキャプションから入力タグが省略され、曲の説明とは関係のない文が生成される可能性があります。一方、テンプレートベースのモデルは、テンプレートに含まれる音楽のコンテキストの恩恵を受けるため、パフォーマンスが向上します。 彼らはBERT-Score指標を使用して生成されたキャプションの多様性を評価しました。このフレームワークは、より多様な語彙を持つキャプションを生成し、高いBERT-Score値を示しました。これは、この方法によって生成されたキャプションが、より広範な言語表現とバリエーションを持ち、魅力的で文脈豊かなものとなることを意味します。 研究者たちは、アプローチをさらに磨き、向上させながら、言語モデルの力を利用して音楽のキャプション生成を進め、音楽情報の検索に貢献することを期待しています。

「Med-Flamingoに会ってください:医療分野向けのマルチモーダルな文脈学習を実行できるユニークな基盤モデル」
人工知能(AI)の人気が高まるにつれて、基礎モデルはラベル付きのインスタンスによって提供されるわずかな情報だけで、さまざまな問題を処理する驚異的な能力を示しています。コンテキスト内での学習のアイデアは、モデルのパラメータを調整せずに、いくつかの例からタスクを引き継がせる能力を持つため、注目を浴びています。医療分野と医療領域を考えると、コンテキスト内での学習は現在の医療AIモデルを指数関数的に改善する可能性があります。 コンテキスト内での学習は医療データの複雑さと多様性、および達成しなければならないさまざまなタスクにより、医療環境での実装に困難を伴います。過去にはさまざまなマルチモーダル医療基礎モデルが試みられてきました。例えば、胸部X線を読むことに特化したChexZeroや、生物学の文献からのキャプションと関連付けられたさまざまな画像で訓練されたBiomedCLIPなどです。手術映像や電子健康記録(EHR)データにはいくつかのモデルが開発されています。しかし、これらのモデルにはマルチモーダル医療領域のコンテキスト学習は含まれていません。 限界を克服するために、研究チームは医療領域に特化したユニークで高効果な基礎モデルであるMed-Flamingoを提案しています。このビジョン言語モデルは、コンテキスト内での学習とフューショット学習の能力を示す最初のビジョン言語モデルの1つであるFlamingoに基づいています。Med-Flamingoは、複数の医療分野からのマルチモーダルな知識源の事前トレーニングを提供することで、これらの能力を医療領域に拡大しています。 最初のフェーズでは、信頼性の高い医療知識の信頼できるソースから4K以上の医療テキストからオリジナルの交互に配置された画像とテキストのデータセットを作成します。Med-Flamingoを評価するために、研究者たちは生成的な医療ビジュアルクエスチョンアンサリング(VQA)タスクに焦点を当てています。このタスクでは、モデルが事前定義された可能性を評価するのではなく、オープンエンドの回答を直接作成します。また、人間の評価スコアを主要なパラメータとする新しい現実的な評価プロセスが開発されました。さらに、困難なUSMLEスタイルのタスクを含むビジュアルUSMLEデータセットも開発されました。このデータセットには、画像や症例ビネット、検査結果も含まれています。 3つの生成的医療VQAデータセットで、Med-Flamingoは以前のモデルよりも臨床評価スコアで優れたパフォーマンスを示し、医師はモデルの予測を好む傾向があります。複雑な医療クエリに対応し、理由を提示することで、これまでにマルチモーダル医療基礎モデルが行っていなかった医療推論スキルを発揮しています。ただし、トレーニングデータの多様性とアクセスの容易さ、および一部の医療タスクの難しさによって、モデルの効果は制約される場合があります。 チームは以下の貢献をまとめています。 Med-Flamingoは、医療領域に特化した最初のマルチモーダルフューショット学習者であり、根拠の生成やコンテキストの条件付けなどの新しい臨床応用を提供します。 研究者たちは、医療領域でのマルチモーダルフューショット学習に適した、ユニークなデータセットを構築しました。 彼らはまた、ビジュアルクエスチョンアンサリングにおける複雑な医療推論を取り入れたUSMLEスタイルの問題を含む評価データセットを導入しました。 既存の評価戦略を批評し、医療評価者を巻き込んだ専用のアプリを使用してモデルのオープンエンドVQA生成を評価するための詳細な臨床評価研究が実施されました。

大規模な言語モデルを税理士として活用する:このAI論文は、税法の適用におけるLLMの能力を探求します
AIの進歩が進んでいます。大規模言語モデル(LLM)は急速に進化しています。現代のLLMは、ツールを使用し、計画を立て、標準化された評価を通過することができます。しかし、LLMはその作成者にとっても単なる神秘的な箱です。内部の思考方法についてはあまり知られておらず、LLMが新しい状況でどのように行動するかを予測することはできません。研究の範囲外でモデルを使用する前に、LLMのパフォーマンスを長いベンチマークリストで評価するのがベストプラクティスです。しかし、これらのベンチマークは、しばしばLLMのトレーニング中に記憶されたかもしれない私たちにとって重要な実世界の活動を反映する必要があります。パフォーマンス評価に必要なデータは、LLMのトレーニングに使用されるデータセットに一般的に含まれており、これらのデータセットは頻繁にインターネットからダウンロードされます。 重複はモデルのパフォーマンスを過大評価し、単純な認識だけであるように理解される印象を作り出す可能性があります。彼らは特に、三つの理由からLLMの法的な分析スキルに評価の努力を集中させています。まず、LLMが法律をどれだけ理解しているかを判断することは、LLMや自動化システムのより一般的な規制に役立ちます。政策に関連する戦略の一つは、「法律に基づいたAI」において、民主的な手続きと立法によって確立された社会的な理念に沿った「法律に基づいたAI」をLLMに利用することです。この「法律がコードに影響を与える」戦略は、反復的な審議と訴訟を通じて信託義務などの柔軟な法的規範を生成する民主的なプロセスの実証された能力に基づいています。法の精神を教えることで、AIシステムが未知の状況で弁護可能な決定を下すのに役立つという考え方です。LLMを搭載したシステムが人間の原則を支持する場合、信託責任が違反されたときに検出するこの初期の能力は、より安全なAIの展開を可能にするかもしれません。第二に、自己サービスまたは資格のある弁護士を通じて、LLMは人々がより迅速かつ効果的に法的サービスを提供するためのツールとして利用されるかもしれません。法律をよりよく理解できる場合、モデルはより信頼性が高く価値があるかもしれません。LLMは、ケース予測から契約分析までさまざまな活動に役立つことがあり、法的援助へのアクセスを民主化し、法制度を理解するのが困難な個人にとっての費用と複雑さを低下させるかもしれません。 法的業務の繊細さを考慮すると、これらのモデルが実装される際には特定の保護措置が必要です。これには、データプライバシーの向上、偏見の減少、これらのモデルの選択に対する責任の維持、および特定のユースケースに対するLLMの適用可能性の評価が含まれます。したがって、体系的な評価が必要です。第三に、LLMが十分な法的知識を持っている場合、政府、人々、学者によって法的な矛盾点を見つけるために使用されるかもしれません。LLMは政府の全体的な効果と透明性を向上させることができます。たとえば、LLMは複雑な規則や規制をわかりやすく説明することができることがよくあります。 将来的には、LLMは新しい法律や政策の予想される影響を予測することができるかもしれません。LLMは、膨大な量の法的言語と関連する実施方法をスキャンすることで、立法府や規制当局がガイドラインを与える他の類似のケースで、法が沈黙している可能性のある「時代遅れの」法律を特定することができるかもしれません。この研究では、スタンフォード大学、ミシガン大学、ワシントン大学、南カリフォルニア大学、ノースウェスタン・プリッツカー法科大学院、およびSimPPLの研究者が、米国法典(連邦法のコレクション)および米国連邦規則(CFR)のテキストを使用したリトリーバル増強型LLMの作成を調査しています。彼らは税法の理解を進化させるために、一群のLLMの税法の理解を評価しました。彼らは税法を選んだ理由が4つあります。 税法の法的権限は、主にCFRの下の財務省規則と米国法典第26編(一般に内国歳入法として知られています)に含まれています。これは、教義が複数の先例から抽出される多くの法的領域とは対照的です。これにより、事前に定義された関連文書の事前定義された宇宙を使用してLLMのリトリーバルを補完することができます。第二に、多くの税法は問いに確定的な回答を許可します。これにより、一貫した自動的な検証ワークフローを設定することができます。第三に、特定のケースに対する税法の質問には、通常、関連する法的権限を単に読む以上のことが必要です。そのため、LLMの能力を実際の実務に適用する方法で評価することができます。第四に、税法はほとんどの市民や企業の日常的な経済活動に大きな影響を与えています。LLMのみを使用したり、基になる法的テキストとLLMを統合したり、さまざまなリトリーバル手法(異なるリトリーバル方法間での比較を行ったり)を含むいくつかの実験的なセットアップを使用して、LLMが税法の数千の問い合わせに対して生成する回答の正確さを評価します。私たちは、最も小さく最も弱いモデルから最も大きな現代のモデルであるOpenAIのGPT-4まで、さまざまなLLMの範囲でこれらのテストを行いました。私たちが調査した各LLMは、最初に提供されたときに最新のものでした。 彼らは、LLMsの法的理解能力の開発の証拠を発見し、徐々に大きなモデルを分析することで、各モデルのリリースごとに向上させています。もし技術が急速に成長し続けるならば、彼らはまもなく超人的なAIの法的能力の発展を目撃するかもしれません。

ロラハブにお会いしましょう:新しいタスクにおいて適応性のあるパフォーマンスを達成するために、多様なタスクでトレーニングされたロラ(低ランク適応)モジュールを組み立てるための戦略的なAIフレームワーク
大規模な事前学習言語モデル(LLM)であるOpenAI GPT、Flan-T5、LLaMAは、NLPの急速な進歩に大きく貢献してきました。これらのモデルは、さまざまなNLPアプリケーションで非常に優れたパフォーマンスを発揮します。しかし、その巨大なパラメータサイズのため、ファインチューニング中には計算効率とメモリ使用率の問題が生じます。 近年、Low-Rank Adaptation(LoRA)がチューニングのための強力なツールとして台頭しています。これにより、LLMのトレーニングに必要なメモリと計算量が減少し、トレーニングのスピードが向上します。LoRAは、LLMのパラメータを固定し、指定されたタスクで信頼性の高い小さな補完モジュールを学習することでこれを実現します。 LoRAによる効率の向上は、以前の研究の焦点でしたが、LoRAモジュールのモジュラリティと組み合わせ可能性についてはほとんど注目されていませんでした。LoRAモジュールが未知の問題に効率的に一般化できるかどうかについての研究が必要です。 Sea AI Lab、ワシントン大学、Allen Institute for AIの研究者グループは、LoRAのモジュラリティを使用して、特定のタスクのトレーニングに制限するのではなく、新しい課題で柔軟なパフォーマンスを実現することを決定しました。彼らのアプローチの主な利点は、LoRAモジュールを人間の介入や専門知識なしで自動的に組み立てることができることです。 この方法では、以前に認識されなかったタスクのわずかなサンプルだけで適切なLoRAモジュールを自動的に配置できます。研究者は、どのタスクでトレーニングされたLoRAモジュールが統合できるかについての仮定を行わないため、要件を満たすすべてのモジュールがマージの対象となります(例:同じLLMを利用すること)。彼らは、この技術をLoraHub学習と呼び、すでに存在するさまざまなLoRAモジュールを使用します。 チームは、業界標準のBBHベンチマークとFlan-T5を基盤としたLLMを使用して、彼らの手法の有効性を評価しました。結果は、新しいタスクのためのLoRAモジュールを作成するためのフューショットLoraHub学習プロセスの価値を示しています。驚くべきことに、この戦略はフューショットでコンテキスト学習に非常に近い結果を得ます。LLMへの入力としてのインスタンスの必要性も、インコンテキスト学習と比較して推論コストを大幅に削減します。この学習技術は、LoRAモジュールの係数を生成するために勾配フリーアプローチを採用し、わずかな推論ステップのみを必要とします。たとえば、単一のA100を使用して、わずか1分でBBHでトップレベルのパフォーマンスを実現できます。 LoraHubでの学習には、LLMの推論の処理方法を知っているだけで十分です。そのため、CPUのみでこの作業を行うことができます。この作業の柔軟性と高いパフォーマンスは、トレーニングされたLoRAモジュールが容易に共有、アクセス、およびこのドメインで新しいジョブに適用されるプラットフォームの創造を可能にする道を開きます。チームは、LoRAノードを動的に組み合わせて、LLMの機能を改善する作業に取り組んでいます。
モジラのコモンボイスでの音声言語認識 — Part I.
「話者の言語を特定することは、後続の音声テキスト変換のために最も困難なAIのタスクの一つですこの問題は、例えば人々が住んでいる場所で発生することがあります...」

AIを使用してKYC登録が簡単になりました
キャピタルマーケットのプレーヤーは、CAMSKRAのAI組み込みKYCソリューションのおかげで、長くて手間のかかるKYC登録プロセスとお別れすることができます。人工知能の力を活用して、この新しい提案はシームレスで超高速な顧客オンボーディングを約束し、ビジネスが顧客を確認する方法を革新します。詳細について掘り下げ、この革新的なテクノロジーが金融業界のゲームを変える方法を発見しましょう。 また読む:Google CloudがMacquarie BankのAI銀行業務能力を向上させるのを支援 AIによる簡素化されたKYC登録 CAMSKRAは、CAM(Computer Age Management Services)の下での主要なKYC登録機関として、画期的なAI駆動のKYCソリューションを導入しました。この最先端システムは、顧客のアイデンティティを効率的に検証するためにカスタム画像分類と抽出モデルを利用しています。長い書類作成や手動検証プロセスの日々は終わりました。ビジネスは新しいクライアントのKYC登録を10分以内で完了できるため、オンボーディングの旅を効率化することができます。 包括的なアイデンティティ検証 CAMSKRA KYCソリューションは、エラーや不完全な検証の余地を残しません。AIの能力を活用したこのプラットフォームは、Aadhaar OTP、PANカード、銀行口座の検証を含む包括的なアイデンティティチェックを提供します。これにより、ビジネスは顧客のアイデンティティに完全な信頼を置くことができ、セキュリティとリスクの軽減が実現されます。 また読む:FACEIOアプリ:新しい時代の顔認証 スムーズな顧客体験 新しいAI組み込みKYCソリューションにより、企業は顧客にシームレスなオンボーディング体験を提供することができます。摩擦のないプロセスは、顧客の時間を節約するだけでなく、全体的な顧客体験を向上させます。オンボーディングからKYC完了、取引までのシームレスな旅は、ビジネスが変換率を向上させ、成長を推進する力を与えます。 また読む:AIソフトウェアによるコールセンターが顧客サービスを革新 セキュリティの中心 速度と利便性が中心に置かれる中、CAMSKRAはデータセキュリティを最も重要視しています。このプラットフォームでは、暗号化、データバックアップ、アクセス制御など、業界をリードするセキュリティ対策を採用しており、顧客データを保護します。これらの対策により、機密情報が未承認者に対して保護され、アクセスできないようになっています。 また読む:銀行業界におけるディープラーニング:コロンビアのペソ紙幣の検出 投資の景色を変える CAMSのマネージングディレクターであるAnuj Kumar氏は、この画期的な提案に興奮を表明しました。KYC登録時間を数日から数分に大幅に短縮することで、このソリューションは時間の重要な要素となる投資プロセスを変革することができます。AIをバックにしたこの技術により、手間のかかる手動検証の必要性がなくなり、コストが削減され、ビジネスの正確性が向上します。 また読む:2023年の銀行および金融業界での機械学習とAIの応用…

「拡散モデルの助けを借りて、画像間の補間を組み込むためのAI研究」についてのAI研究
人工知能は、開発者や研究者の間で最新の話題です。自然言語処理や自然言語理解からコンピュータビジョンまで、AIはほぼすべてのドメインを革新しています。最近のDALL-Eなどの大規模言語モデルは、テキストのプロンプトから美しい画像を生成するのに成功しています。画像の生成と操作には大きな進歩があるものの、現在使用されている画像生成パイプラインでは、2つの入力画像の間の補間はできません。 画像生成モデルに補間機能を追加することで、新しい革新的なアプリケーションが実現できます。最近、MIT CSAILの研究チームが、事前学習された潜在拡散モデルを使用して、さまざまなドメインとレイアウトの画像間で高品質な補間を行うための戦略を提案する研究論文を公開しました。彼らは、潜在拡散モデルを使用したゼロショット補間の含まれ方が、どのように役立つかを共有しています。彼らの戦略は、2つの入力画像の対応する潜在表現の間で補間を行うことで、生成モデルの潜在空間で作業することを含んでいます。 補間手順は、ノイズの異なる段階で進行的に下方向に行われます。ここで、ノイズとは、潜在ベクトルに適用されるランダムな摂動であり、生成された画像の外観に影響を与えます。研究者たちは、補間を完了した後に、追加ノイズの影響を最小化するために補間された表現をデノイズする方法を共有しています。これにより、補間された画像の改善が図られます。 デノイズステージでは、テキスト反転で得られた補間されたテキスト埋め込みが必要です。テキスト反転によって、書かれた説明は等価の視覚的特徴に変換され、モデルが意図した補間の特性を理解することができます。主体のポーズは意図的に組み込まれており、モデルが写真内のオブジェクトや人物の配置と向きに関する情報を提供するように、補間手順を指示するのに役立ちます。 この手法は、高品質の結果と柔軟性を保証するために、複数の候補補間を生成することができます。画像とテキストの内容を理解することができるニューラルネットワークであるCLIPを使用して、これらの候補を対比し、特定の要件やユーザーの好みに基づいて最適な補間を選択することができます。主体のポーズ、画像スタイル、画像コンテンツなど、さまざまな設定で、この手法が信じられる補間を提供することをチームは示しています。 チームは、生成された画像の品質を評価するために一般的に使用されるFID(フレシェ・インセプション・ディスタンス)などの従来の定量的指標は、補間の品質を測定するためには不十分であると共有しています。導入されたパイプラインは、テキスト条件付け、ノイズスケジューリング、作成された候補から手動で選択する選択肢などを通じて、ユーザーに大きな柔軟性を提供するため、有用で容易に展開可能です。 結論として、この研究は、画像編集の領域でほとんど注目されていなかった問題に取り組んでいます。この戦略では、すでに訓練された潜在拡散モデルが使用され、他の補間手法や定性的な結果と比較して、その有効性が示されています。

スタビリティAIは、Beluga 1およびStable Beluga 2の新しいオープンアクセスLLMをリリースしました
新しいブログで、Stability AIとそのCarperAI研究所は、Stable Beluga 1とその後継機であるStable Beluga 2(以前はFreeWillyとして知られていました)を発表しました彼らの投稿によれば、これら2つの大規模言語モデルの目標は、オープンアクセスのAI研究の拡大と新たな基準の創造ですStable Beluga...

「生成AIとAmazon Kendraを使用して、エンタープライズスケールでキャプションの作成と画像の検索を自動化する」
Amazon Kendraは、機械学習(ML)によって駆動されるインテリジェントな検索サービスですAmazon Kendraは、ウェブサイトやアプリケーションのための検索を再構築し、従業員や顧客が組織内の複数の場所やコンテンツリポジトリに散らばっているコンテンツを簡単に見つけることができるようにしますAmazon Kendraはさまざまなドキュメントをサポートしています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.