Learn more about Search Results T5 - Page 31

- You may be interested
- Google DeepMindはAlphaCode 2を導入しま...
- フリーMITコース:TinyMLと効率的なディー...
- このAI論文は、医療の視覚的な質問応答に...
- なぜあなたのビジネスは生成型AIを活用す...
- タイムシリーズの異常値のデマイスティフ...
- 📱 アップルが不正な認証からのiMessageア...
- 「明日のニュースを、今日に!」ニュースG...
- 「Xenovaのテキスト読み上げクライアント...
- 「AIシステムへの9つの一般的な攻撃のタイ...
- 5Gパワードロボットがシンガポールの川を清掃
- 「私たちはLLMがツールを使うことを知って...
- 「設定パラメータを使用して、ChatGPTの出...
- 人間だけが解決できるAIの課題
- 研究者たちは、AIシステムを取り巻くガー...
- 「フリーノイズ」にご挨拶:複数のテキス...

「Langchain x OpenAI x Streamlit — ラップソングジェネレーター🎙️」
「LangchainフレームワークをStreamlitとOpenAIのGPT3モデルに統合したWebアプリを作成する方法」
アップリフトモデリング—クレジットカード更新キャンペーンの最適化ガイド データサイエンティストのための
新進のデータサイエンティストとして、私の学術的なバックグラウンドは正確さを成功したプロジェクトの兆候として尊重するように教えてくれました一方、産業界は短期間でお金を生み出し、節約することに関心を持っています...

「テキストから言葉以上へ」 翻訳結果です
こんにちは読者の皆さん、今日は大規模言語モデル(LLM)の時代に生きていますこれにより、GPT4、ChatGPT、DALL·Eなどのソフトウェアや他のAI技術が活用されますこれらの技術はいくつかの責任を持っています...

「トランスフォーマーベースのエンコーダーデコーダーモデル」
!pip install transformers==4.2.1 !pip install sentencepiece==0.1.95 トランスフォーマーベースのエンコーダーデコーダーモデルは、Vaswani et al.によって有名なAttention is all you need論文で紹介され、現在では自然言語処理(NLP)におけるデファクトスタンダードのエンコーダーデコーダーアーキテクチャです。 最近、T5、Bart、Pegasus、ProphetNet、Margeなど、トランスフォーマーベースのエンコーダーデコーダーモデルの異なる事前学習目的に関する多くの研究が行われていますが、モデルのアーキテクチャはほとんど変わっていません。 このブログ記事の目的は、トランスフォーマーベースのエンコーダーデコーダーアーキテクチャがシーケンス対シーケンスの問題をどのようにモデル化しているかを詳細に説明することです。アーキテクチャによって定義された数学モデルとそのモデルを推論に使用する方法に焦点を当てます。途中で、NLPのシーケンス対シーケンスモデルについての背景をいくつか説明し、トランスフォーマーベースのエンコーダーとデコーダーのパーツに分解します。多くのイラストを提供し、トランスフォーマーベースのエンコーダーデコーダーモデルの理論と🤗Transformersにおける実際の使用方法のリンクを確立します。なお、このブログ記事ではそのようなモデルをトレーニングする方法については説明していません。これについては将来のブログ記事のテーマです。 トランスフォーマーベースのエンコーダーデコーダーモデルは、表現学習とモデルアーキテクチャに関する数年にわたる研究の成果です。このノートブックでは、ニューラルエンコーダーデコーダーモデルの歴史の簡単な概要を提供します。詳細については、Sebastion Ruder氏の素晴らしいブログ記事を読むことをお勧めします。また、セルフアテンションアーキテクチャの基本的な理解も推奨されます。以下のJay Alammar氏のブログ記事は、元のトランスフォーマーモデルの復習として役立ちます。 このノートブックの執筆時点では、🤗Transformersには、T5、Bart、MarianMT、Pegasusのエンコーダーデコーダーモデルが含まれており、これらはモデルの要約についてはドキュメントで要約されています。 このノートブックは4つのパートに分かれています: 背景 – ニューラルエンコーダーデコーダーモデルの短い歴史がRNNベースのモデルに焦点を当てて与えられます。 エンコーダーデコーダー…
テキストの生成方法:トランスフォーマーを使用した言語生成のための異なるデコーディング方法の使用方法
はじめに 近年、大規模なトランスフォーマーベースの言語モデル(例えば、OpenAIの有名なGPT2モデル)が数百万のウェブページを学習することで、オープンエンドの言語生成に対する関心が高まっています。条件付きのオープンエンドの言語生成の結果は印象的です。例えば、ユニコーンに関するGPT2、XLNet、CTRLでの制御言語生成などです。改良されたトランスフォーマーアーキテクチャや大量の非教示学習データに加えて、より良いデコーディング手法も重要な役割を果たしています。 このブログ記事では、異なるデコーディング戦略の概要と、さらに重要なことに、人気のあるtransformersライブラリを使ってそれらを簡単に実装する方法を紹介します! 以下のすべての機能は、自己回帰言語生成に使用することができます(ここでは復習です)。要するに、自己回帰言語生成は、単語のシーケンスの確率分布を条件付き次の単語の分布の積として分解できるという仮定に基づいています: P(w1:T∣W0)=∏t=1TP(wt∣w1:t−1,W0) ,with w1:0=∅, P(w_{1:T} | W_0 ) = \prod_{t=1}^T P(w_{t} | w_{1: t-1}, W_0) \text{ ,with } w_{1: 0} = \emptyset, P(w1:T∣W0)=t=1∏TP(wt∣w1:t−1,W0) ,with w1:0=∅,…

fairseqのwmt19翻訳システムをtransformersに移植する
Stas Bekmanさんによるゲストブログ記事 この記事は、fairseq wmt19翻訳システムがtransformersに移植された方法をドキュメント化する試みです。 私は興味深いプロジェクトを探していて、Sam Shleiferさんが高品質の翻訳者の移植に取り組んでみることを提案してくれました。 私はFacebook FAIRのWMT19ニュース翻訳タスクの提出に関する短い論文を読み、オリジナルのシステムを試してみることにしました。 最初はこの複雑なプロジェクトにどう取り組むか分からず、Samさんがそれを小さなタスクに分解するのを手伝ってくれました。これが非常に助けになりました。 私は、両方の言語を話すため、移植中に事前学習済みのen-ru / ru-enモデルを使用することを選びました。ドイツ語は話せないので、de-en / en-deのペアで作業するのははるかに難しくなります。移植プロセスの高度な段階で出力を読んで意味を理解することで翻訳の品質を評価できることは、多くの時間を節約することができました。 また、最初の移植をen-ru / ru-enモデルで行ったため、de-en / en-deモデルが統合されたボキャブラリを使用していることに全く気づいていませんでした。したがって、2つの異なるサイズのボキャブラリをサポートするより複雑な作業を行った後、統合されたボキャブラリを動作させるのは簡単でした。 手抜きしましょう 最初のステップは、もちろん手抜きです。大きな努力をするよりも小さな努力をする方が良いです。したがって、fairseqへのプロキシとして機能し、transformersのAPIをエミュレートする数行のコードで短いノートブックを作成しました。 もし基本的な翻訳以外のことが必要なければ、これで十分でした。しかし、もちろん、完全な移植を行いたかったので、この小さな勝利の後、より困難な作業に移りました。 準備 この記事では、~/portingの下で作業していると仮定し、したがってこのディレクトリを作成します:…

エンコーダー・デコーダーモデルのための事前学習済み言語モデルチェックポイントの活用
Transformerベースのエンコーダーデコーダーモデルは、Vaswani et al.(2017)で提案され、最近ではLewis et al.(2019)、Raffel et al.(2019)、Zhang et al.(2020)、Zaheer et al.(2020)、Yan et al.(2020)などにおいて大きな関心を集めています。 BERTやGPT2と同様に、大規模な事前学習済みエンコーダーデコーダーモデルは、Lewis et al.(2019)、Raffel et al.(2019)などのさまざまなシーケンス対シーケンスのタスクにおいて性能を大幅に向上させることが示されています。しかし、エンコーダーデコーダーモデルの事前学習には膨大な計算コストがかかるため、そのようなモデルの開発は主に大企業や研究所に限定されています。 Sascha Rothe、Shashi Narayan、Aliaksei Severynによる「シーケンス生成タスクのための事前学習済みチェックポイントの活用」(2020)では、事前学習済みのエンコーダーやデコーダーのみのチェックポイント(例:BERT、GPT2)でエンコーダーデコーダーモデルを初期化して、コストのかかる事前学習をスキップする方法が紹介されています。著者らは、このようなウォームスタートされたエンコーダーデコーダーモデルが、T5やPegasusなどの大規模な事前学習済みエンコーダーデコーダーモデルと比較して、複数のシーケンス対シーケンスのタスクで競争力のある結果をもたらすことを示しています。 このノートブックでは、エンコーダーデコーダーモデルをウォームスタートする方法の詳細を説明し、Rothe et…
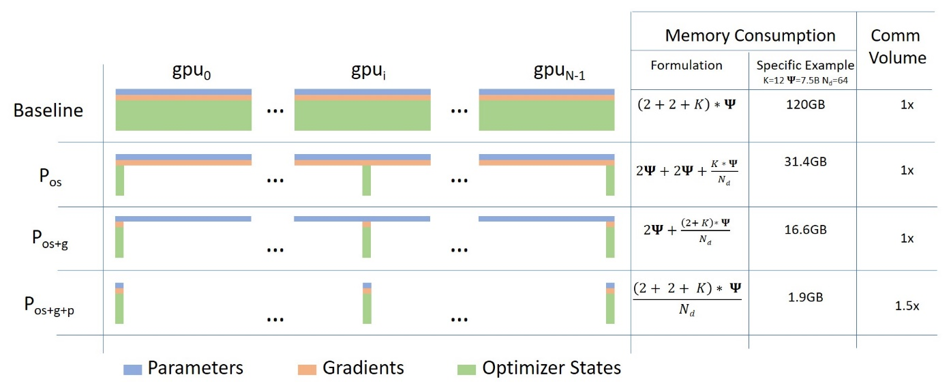
ZeROを使用して、DeepSpeedとFairScaleを介してより多くのフィットと高速なトレーニングを実現
Hugging FaceフェローであるStas Bekmanによるゲストブログ投稿 最近の機械学習モデルは、新しくリリースされたカードに追加されるGPUメモリ量よりもはるかに速く成長しているため、多くのユーザーはこれらの巨大なモデルを自分のハードウェアにトレーニングしたり、ロードしたりすることができません。これらの巨大なモデルをより管理しやすいサイズに縮小するための取り組みが進行中ですが、それらの努力は十分に早く小さなモデルを生み出すことはありません。 2019年の秋に、Samyam Rajbhandari、Jeff Rasley、Olatunji Ruwase、Yuxiong Heが「ZeRO: Memory Optimizations Toward Training Trillion Parameter Models」という論文を発表しました。この論文には、以前に考えられていたよりもハードウェアを遥かに高い性能で動作させるための、多くの独創的なアイデアが含まれています。その後しばらくして、DeepSpeedがリリースされ、その論文のアイデアのほとんどをオープンソースで実装しました(いくつかのアイデアはまだ進行中です)。同時に、FacebookのチームもZeROの論文のいくつかの核心的なアイデアを実装したFairScaleをリリースしました。 Hugging FaceのTrainerを使用している場合、transformers v4.2.0以降、DeepSpeedとFairScaleのZeRO機能の実験的なサポートが提供されています。新しい--sharded_ddpおよび--deepspeedコマンドラインのTrainer引数は、それぞれFairScaleとDeepSpeedの統合を提供します。こちらが完全なドキュメントです。 このブログ投稿では、単一のGPUを所有している場合でも、複数のGPUを所有している場合でも、ZeROの利点をどのように得るかについて説明します。 翻訳タスクの実験として、t5-largeモデルとtransformers GitHubリポジトリのexamples/seq2seq内にあるfinetune_trainer.pyスクリプトを使用して、小規模な微調整を行います。 テストには2つの24GB(Titan RTX)GPUを使用します。…

パートナーシップ:Amazon SageMakerとHugging Face
この笑顔をご覧ください! 本日、私たちはHugging FaceとAmazonの戦略的パートナーシップを発表しました。これにより、企業が最先端の機械学習モデルを活用し、最新の自然言語処理(NLP)機能をより迅速に提供できるようになります。 このパートナーシップを通じて、Hugging Faceはお客様にサービスを提供するためにAmazon Web Servicesを優先的なクラウドプロバイダーとして活用しています。 共通のお客様に利用していただくための第一歩として、Hugging FaceとAmazonは新しいHugging Face Deep Learning Containers(DLC)を導入し、Amazon SageMakerでHugging Face Transformerモデルのトレーニングをさらに簡単にする予定です。 Amazon SageMaker Python SDKを使用して新しいHugging Face DLCにアクセスし、使用する方法については、以下のガイドとリソースをご覧ください。 2021年7月8日、私たちはAmazon SageMakerの統合を拡張し、Transformerモデルの簡単なデプロイと推論を追加しました。Hugging…

ハグフェイスでの夏
夏は公式に終わり、この数か月はHugging Faceでかなり忙しかったです。Hubの新機能や研究、オープンソースの開発など、私たちのチームはオープンで協力的な技術を通じてコミュニティを支援するために一生懸命取り組んできました。 このブログ投稿では、6月、7月、8月のHugging Faceで起こったすべてのことをお伝えします! この投稿では、私たちのチームが取り組んでいるさまざまな分野について取り上げていますので、最も興味のある部分にスキップすることを躊躇しないでください 🤗 新機能 コミュニティ オープンソース ソリューション 研究 新機能 ここ数か月で、Hubは10,000以上のパブリックモデルリポジトリから16,000以上のモデルに増えました!コミュニティの皆さんが世界と共有するために素晴らしいモデルをたくさん共有してくれたおかげです。そして、数字の背後には、あなたと共有するためのたくさんのクールな新機能があります! Spaces Beta ( hf.co/spaces ) Spacesは、ユーザープロファイルまたは組織hf.coプロファイルに直接機械学習デモアプリケーションをホストするためのシンプルで無料のソリューションです。GradioとStreamlitの2つの素晴らしいSDKをサポートしており、Pythonで簡単にクールなアプリを構築することができます。数分でアプリをデプロイしてコミュニティと共有することができます! 🚀 Spacesでは、シークレットの設定、カスタム要件の許可、さらにはGitHubリポジトリから直接管理することもできます。ベータ版にはhf.co/spacesでサインアップできます。以下はいくつかのお気に入りです! Chef Transformerの助けを借りてレシピを作成 HuBERTを使用して音声をテキストに変換…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.