Learn more about Search Results 認証 - Page 31

- You may be interested
- 「アップルのiMessageでのBeeper Miniのブ...
- 「目標を見据えて データプログラムの中心...
- 機械学習洞察のディレクター【パート4】
- 「ベストのTableauコース(2023年)」
- 「New DeepMindの研究で、言語モデルのた...
- 「NVIDIAの人工知能がOracle Cloud Market...
- スタンフォード大学の研究者がRT-Sketchを...
- 「Pythonクライアントを使用してMyScaleを...
- 「さて、あなたはあなたの RAG パイプライ...
- 「コイントスを毎回勝つ方法」
- Pythonコード生成のためのLlama-2 7Bモデ...
- ChatGPTのデジタル商品をオンラインで販売...
- UCバークレーの研究者たちは、「リングア...
- 「セマンティックウェブはどうなったのか?」
- 「機械学習を使ったイタリアンファンタジ...

LLMの巨人たちの戦い:Google PaLM 2 vs OpenAI GPT-3.5
2023年5月10日、GoogleはOpenAIのGPT-4に対する見事な対抗策としてPaLM 2をリリースしました最近のI/Oイベントで、Googleは最小から最大までの魅力的なPaLM 2モデルファミリーを発表しました

Amazon SageMaker Data WranglerのSnowflakeへの直接接続でビジネスインサイトまでの時間を短縮してください
Amazon SageMaker Data Wranglerは、1つのビジュアルインターフェイスで、コードを書くことなく機械学習(ML)ワークフローでデータの選択とクリーニング、特徴量エンジニアリングの実行に必要な時間を週から分単位に短縮することができ、データの準備を自動化することができますSageMaker Data Wranglerは、人気のあるSnowflakeをサポートしています
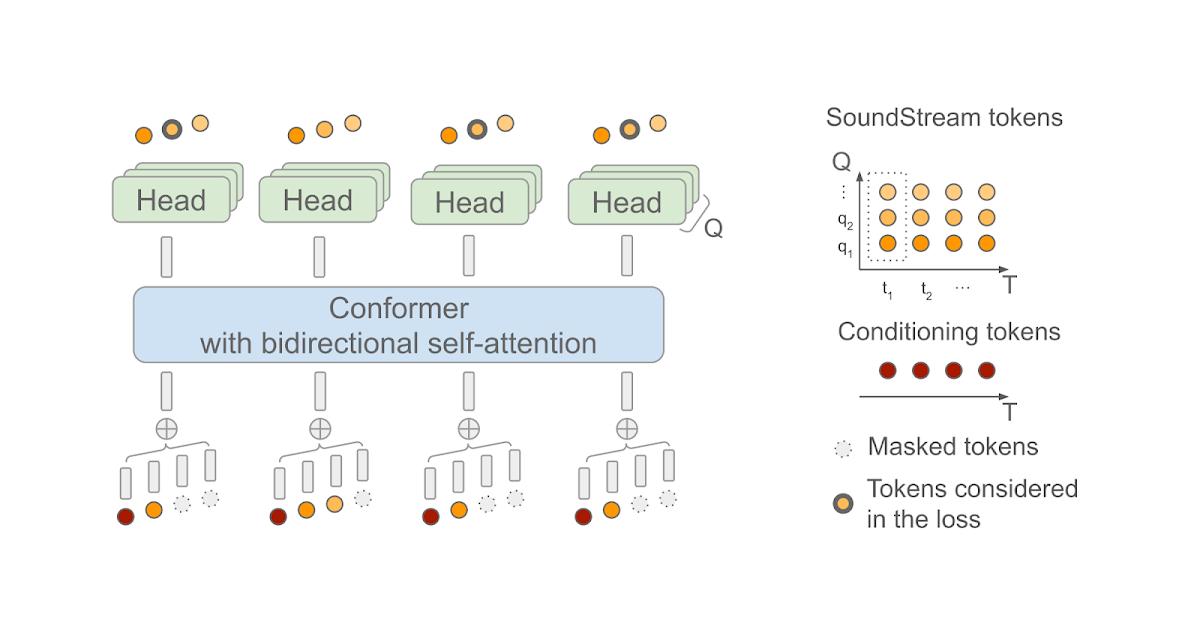
SoundStorm:効率的な並列音声生成
Zalán Borsos氏(リサーチソフトウェアエンジニア)とMarco Tagliasacchi氏(シニアスタッフリサーチサイエンティスト)がGoogle Researchで発表した記事です。 最近の生成AIの進歩により、テキスト、ビジョン、オーディオなど、さまざまな領域で新しいコンテンツを作成する可能性が開かれました。これらのモデルは、生データが最初にトークンのシーケンスとして圧縮されることに依存しています。オーディオの場合、ニューラルオーディオコーデック(例えば、SoundStreamまたはEnCodec)を使用して、波形をコンパクトな表現に効率的に圧縮することができます。これにより、元のオーディオ信号の近似値を再構成できます。この表現は、音の局所的な特性(たとえば、音素)および時間的構造(たとえば、韻律)を捉えた離散的な音声トークンのシーケンスで構成されています。オーディオを離散的なトークンのシーケンスとして表現することで、Transformerベースのシーケンスツーシーケンスモデルを使用してオーディオ生成を実行できるようになりました。これにより、音声継続性(AudioLMを使用した)、テキストから音声への変換(SPEAR-TTSを使用した)、一般的なオーディオや音楽の生成(AudioGenおよびMusicLMを使用した)において急速な進歩が可能になりました。多くの生成オーディオモデル、AudioLMを含む、自己回帰デコーディングに依存しています。この方法は高い音響品質を実現しますが、特に長いシーケンスをデコードする場合、推論(出力の計算)が遅くなることがあります。 この問題に対処するため、「SoundStorm: Efficient Parallel Audio Generation」という記事で、効率的かつ高品質なオーディオ生成の新しい方法を提案しています。SoundStormは、SoundStreamニューラルコーデックによって生成されるオーディオトークンの特性に適合するアーキテクチャと、MaskGITと呼ばれる最近提案された画像生成の方法に着想を得たデコードスキームの2つの新しい要素に依存して、長いオーディオトークンシーケンスの生成の問題に対処します。これにより、AudioLMの自己回帰デコーディングアプローチと比較して、SoundStormはトークンを並列に生成できるため、長いシーケンスの推論時間を100倍短縮することができ、同じ品質で、声質や音響条件の一貫性が高いオーディオを生成できます。さらに、SPEAR-TTSのテキストから意味論的モデリング段階と組み合わせたSoundStormは、例えば以下の例で示されるように、高品質で自然な対話を合成することができ、話される内容(トランスクリプトを介して)、話者の声(短い音声プロンプトを介して)、話者のターン(トランスクリプト注釈を介して)を制御できます。 入力:テキスト(オーディオ生成を駆動するトランスクリプトは太字) 今朝、私にとてもおかしなことが起こりました。| え、本当に?|普段通りに起きて、朝食を食べに下に降りたんです。|なるほど。| 食べ始めてから10分後に、今夜中だと気づいたんです。| あ、それはおもしろい。| 昨晩よく眠れなかったんだ。|え、どうしたの?|よくわからないんだ。どうしても寝付けなくて、一晩中寝返りを打ち続けたんだ。|そうなんだ。今晩は早く寝た方がいいかもしれないし、本でも読んでみるのはどうかな。|ああ、ありがとう。そうだといいんだけど。|どういたしまして。よく眠れるといいね。 入力:オーディオプロンプト 出力:オーディオプロンプト+生成されたオーディオ SoundStormの設計 以前のAudioLMの研究で、オーディオ生成を2つのステップに分解できることを示しました。1つ目は、意味的なトークンを生成する意味モデリングであり、前の意味トークンまたは条件信号(SPEAR-TTSのトランスクリプトやMusicLMのようなテキストプロンプトなど)から意味トークンを生成します。2つ目は、意味トークンから音声トークンを生成する音響モデリングです。SoundStormでは、より高速な並列デコードによって、より遅い自己回帰デコーディングを置き換え、音響モデリングに特に対処しています。 SoundStormは、トランスフォーマーと畳み込みを組み合わせたモデルアーキテクチャであるConformerに双方向アテンションを依存しており、トークンのシーケンスのローカルおよびグローバルな構造を捕捉します。具体的には、AudioLMが生成した意味トークンのシーケンスを入力として与えられた場合、SoundStreamによって生成されたオーディオトークンを予測するようにモデルが訓練されます。この際、各時間ステップtにおいて、SoundStreamは、右側に示すように、残差ベクトル量子化(RVQ)として知られる方法を使用して、最大Qトークンまでオーディオを表現します。主要な考え方は、各ステップで生成されるトークンの数が1からQに増えるにつれて、再構築されたオーディオの品質が徐々に向上するということです。 推論時には、入力として意味トークンを与えた場合、SoundStormは、すべてのオーディオトークンをマスクアウトし、RVQレベルq = 1の粗いトークンから始めて、より細かいトークンまでレベル別に進み、レベルq…

アルトコインへの投資:暗号市場の包括的ガイド
アルトコインとは、ビットコインの後に登場した他の暗号通貨のことですこれらのデジタル通貨は、分散型ブロックチェーン技術を介して運営され、先駆的な暗号通貨であるビットコインとは異なる用途を提供しています 「アルトコイン」という用語は、暗号空間で数年間使用されており、ビットコインを除く多数の暗号通貨を指します… アルトコインへの投資:暗号市場の包括的ガイド 詳細はこちら»

H1Bビザはデータ分析の洞察に基づいて承認されますか?
はじめに H1Bビザプログラムは、優れた人材が世界中からアメリカに専門知識をもたらすための門戸を開きます。毎年、このプログラムを通じて数千人の才能ある専門家がアメリカに入国し、様々な産業に貢献し、革新を推進しています。外国労働認証局(OFLC)のH1Bビザデータの世界にダイブして、その数字の裏にあるストーリーを探ってみましょう。この記事では、H1Bビザデータの分析を行い、データから知見や興味深いストーリーを得ます。フィーチャーエンジニアリングを通じて、外部ソースから追加情報をデータセットに組み込みます。データラングリングを用いて、データを丁寧に整理して、より理解しやすく分析することができます。最後に、データの可視化によって、2014年から2016年の間におけるアメリカの熟練労働者に関する魅力的なトレンドや未知の知見が明らかになります。 外国労働認証局(OFLC)から提供されたH1Bビザデータを探索し、高度な外国人労働者をアメリカに引き付ける上での重要性を理解する。 データクリーニング、フィーチャーエンジニアリング、データ変換技術などの前処理プロセスについて学ぶ。 H1Bビザの申請の受理率や拒否率を調べ、それらが影響を与える可能性がある。 データの可視化技術に慣れて、効果的な発表やコミュニケーションを行うために。 注:🔗この分析の完全なコードとデータセットは、Kaggle上で公開されています。プロセスや分析の背後にあるコードを探索するには以下のリンクをご覧ください。H1B Analysis on Kaggle この記事は、Data Science Blogathonの一環として公開されました。 H1Bビザとは何ですか? H1Bビザプログラムは、様々な産業において専門的なポジションを埋めるために、優秀な外国人労働者をアメリカに引き付けるためのアメリカの移民政策の重要な要素です。スキル不足を解消し、革新を促進し、経済成長を牽引しています。 H1Bビザを取得するには、以下の重要なステップを踏まなければなりません。 ビザをスポンサーするアメリカの雇用主を見つける。 雇用主が外国人労働者のH1B申請を米国移民局(USCIS)に提出する。 年次枠に制限があり、申請数が受け入れ可能な枠を超えた場合は、抽選が行われる。 選択された場合、USCISは申請の資格とコンプライアンスを審査する。 承認された場合、外国人労働者はH1Bビザを取得し、米国のスポンサー雇用主で働くことができる。 このプロセスには、学士号または同等の資格を持つことなどの特定の要件を満たす必要があり、支配的な賃金決定や雇用主-従業員関係の文書化などの追加の考慮事項を乗り越える必要があります。コンプライアンスと徹底的な準備が、成功したH1Bビザ申請には不可欠です。 データセット 外国労働認証局(OFLC)が提供する2014年、2015年、2016年の結合データセットには、ケース番号、ケースステータス、雇用主名、雇用主都市、雇用主州、職名、SOCコード、SOC名、賃金レート、賃金単位、支配的な賃金、支配的な賃金源、年などのカラムが含まれます。…

Google Cloudを使用してレコメンドシステムを構築する
Google CloudのRecommendation AIを使用して、高度な推薦システムを実装してください

GPT-4 新しいOpenAIモデル
近年、人工知能に基づく自然言語システムの開発は前例のない進歩を遂げています
AgentGPT ブラウザ内の自律型AIエージェント
あなたのAIエージェントに名前と目標を与え、割り当てられた目的を達成するのを見てください

GitHubトピックススクレイパー | PythonによるWebスクレイピング
「GitHub Topics Scraper」このプロジェクトは、GitHub Topicsページから情報を取得し、リポジトリ名と詳細を抽出することを目的としています

ChatGPT 4 API、Google Meet、Google Drive&Docs APIを使用した会議議事録生成
この技術記事では、Google Meet、Google Drive、およびGoogle Docs APIとChatGPT 4 APIを活用して、ミーティング議事録を自動生成する方法について調べます議事録を取ること...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.