Learn more about Search Results いくつかの - Page 319

- You may be interested
- 「2024年のデータサイエンティストにとっ...
- 中国の研究者が提案する、新しい知識統合...
- 「AIではなく、データプライバシー法の欠...
- 「ChatGPT4は人々の顔を認識して読み取る...
- 「トップデータプライバシーツール2023」
- アマゾンは、革新的なAIスタートアップのA...
- 「ロンドン帝国大学チーム、少ないデモン...
- このAI研究は、深層学習システムが継続的...
- AIが私たちのコーディング方法を変えてい...
- 「ローカルCPUで小規模言語モデルを実行す...
- pd.read_htmlの良い点と悪い点、そして醜い点
- 「生成AIの時代における品質保証の再考」
- 「ファストテキストを使用したシンプルな...
- Scikit-Learnを使用した特徴選択の方法
- 「NVIDIA CUDA Quantumによる研究者の進歩...

多言語での音声合成の評価には、SQuIdを使用する
Googleの研究科学者Thibault Sellamです。 以前、私たちは1000言語イニシアチブとUniversal Speech Modelを紹介しました。これらのプロジェクトは、世界中の何十億人ものユーザーに音声および言語技術を提供することを目的としています。この取り組みの一部は、多様な言語を話すユーザー向けにVDTTSやAudioLMなどのプロジェクトをベースにした高品質の音声合成技術を開発することにあります。 新しいモデルを開発した後は、生成された音声が正確で自然であるかどうかを評価する必要があります。コンテンツはタスクに関連し、発音は正確で、トーンは適切で、クラックや信号相関ノイズなどの音響アーティファクトはない必要があります。このような評価は、多言語音声システムの開発において大きなボトルネックとなります。 音声合成モデルの品質を評価する最も一般的な方法は、人間の評価です。テキストから音声(TTS)エンジニアが最新のモデルから数千の発話を生成し、数日後に結果を受け取ります。この評価フェーズには、聴取テストが含まれることが一般的で、何十もの注釈者が一つずつ発話を聴取して、自然な音に聞こえるかどうかを判断します。人間はテキストが自然かどうかを検出することでまだ敵わないことがありますが、このプロセスは実用的ではない場合があります。特に研究プロジェクトの早い段階では、エンジニアがアプローチをテストして再戦略化するために迅速なフィードバックが必要な場合があります。人間の評価は費用がかかり、時間がかかり、対象言語の評価者の可用性によって制限される場合があります。 進展を妨げる別の障壁は、異なるプロジェクトや機関が通常、異なる評価、プラットフォーム、およびプロトコルを使用するため、apple-to-applesの比較が不可能であることです。この点で、音声合成技術はテキスト生成に遅れを取っており、研究者らが人間の評価をBLEUや最近ではBLEURTなどの自動評価指標と補完して長年にわたって利用してきたテキスト生成から大きく遅れています。 「SQuId: Measuring Speech Naturalness in Many Languages」でICASSP 2023に発表する予定です。SQuId(Speech Quality Identification)という600Mパラメーターの回帰モデルを紹介します。このモデルは、音声がどの程度自然かを示します。SQuIdは、Googleによって開発された事前学習された音声テキストモデルであるmSLAMをベースにしており、42言語で100万件以上の品質評価をファインチューニングし、65言語でテストされました。SQuIdが多言語の評価において人間の評価を補完するためにどのように使用できるかを示します。これは、今までに行われた最大の公開努力です。 SQuIdによるTTSの評価 SQuIdの主な仮説は、以前に収集された評価に基づいて回帰モデルをトレーニングすることで、TTSモデルの品質を評価するための低コストな方法を提供できるということです。このモデルは、TTS研究者の評価ツールボックスに貴重な追加となり、人間の評価に比べて正確性は劣るものの、ほぼ即時に提供されます。 SQuIdは、発話を入力とし、オプションのロケールタグ(つまり、”Brazilian Portuguese”や”British English”などのローカライズされた言語のバリアント)を指定することができます。SQuIdは、音声波形がどの程度自然に聞こえるかを示す1から5までのスコアを返します。スコアが高いほど、より自然な波形を示します。 内部的には、モデルには3つのコンポーネントが含まれています:(1)エンコーダー、(2)プーリング/回帰層、および(3)完全接続層。最初に、エンコーダーはスペクトログラムを入力として受け取り、1,024サイズの3,200ベクトルを含む小さな2D行列に埋め込みます。各ベクトルは、時間ステップをエンコードします。プーリング/回帰層は、ベクトルを集約し、ロケールタグを追加し、スコアを返す完全接続層に入力します。最後に、アプリケーション固有の事後処理を適用して、スコアを再スケーリングまたは正規化して、自然な評価の範囲である[1、5]の範囲内に収まるようにします。回帰損失で全モデルをエンドツーエンドでトレーニングします。…

NeRFを使用して室内空間を再構築する
Marcos Seefelder、ソフトウェアエンジニア、およびDaniel Duckworth、リサーチソフトウェアエンジニア、Google Research 場所を選ぶ際、私たちは次のような疑問を持ちます。このレストランは、デートにふさわしい雰囲気を持っているのでしょうか?屋外にいい席はありますか?試合を見るのに十分なスクリーンがありますか?これらの質問に部分的に答えるために、写真やビデオを使用することがありますが、実際に訪れることができない場合でもそこにいるような感覚には代わりがありません。 インタラクティブでフォトリアルな多次元の没入型体験は、このギャップを埋め、スペースの感触や雰囲気を再現し、ユーザーが必要な情報を自然かつ直感的に見つけることができるようにすることができます。これを支援するために、Google MapsはImmersion Viewを開発しました。この技術は、機械学習(ML)とコンピュータビジョンの進歩を活用して、Street Viewや航空写真など数十億の画像を融合して世界の豊富なデジタルモデルを作成します。さらに、天気、交通、場所の混雑度などの役立つ情報を上に重ねます。Immersive Viewでは、レストラン、カフェ、その他の会場の屋内ビューが提供され、ユーザーが自信を持ってどこに行くかを決めるのに役立ちます。 今日は、Immersion Viewでこれらの屋内ビューを提供するために行われた作業について説明します。私たちは、写真を融合してニューラルネットワーク内で現実的な多次元の再構成を生成するための最先端の手法であるニューラル輝度場(NeRF)に基づいています。私たちは、DSLRカメラを使用してスペースのカスタム写真キャプチャ、画像処理、およびシーン再現を含むNeRFの作成パイプラインについて説明します。私たちは、Alphabetの最近の進歩を活用して、視覚的な忠実度で以前の最先端を上回るか、それに匹敵する方法を設計しました。これらのモデルは、キュレーションされたフライトパスに沿って組み込まれたインタラクティブな360°ビデオとして埋め込まれ、スマートフォンで利用可能になります。 アムステルダムのThe Seafood Barの再構築(Immersive View内)。 写真からNeRFへ 私たちの作業の中核にあるのは、最近開発された3D再構成および新しいビュー合成の方法であるNeRFです。シーンを説明する写真のコレクションがある場合、NeRFはこれらの写真をニューラルフィールドに凝縮し、元のコレクションに存在しない視点から写真をレンダリングするために使用できます。 NeRFは再構成の課題を大部分解決したものの、実世界のデータに基づくユーザー向け製品にはさまざまな課題があります。たとえば、照明の暗いバーから歩道のカフェ、ホテルのレストランまで、再構成品質とユーザー体験は一貫している必要があります。同時に、プライバシーは尊重され、個人を特定する可能性のある情報は削除される必要があります。重要なのは、シーンを一貫してかつ効率的にキャプチャし、必要な写真を撮影するための労力を最小限に抑えたまま、高品質の再構成が確実に得られることです。最後に、すべてのモバイルユーザーが同じ自然な体験を手に入れられるようにすることが重要です。 Immersive View屋内再構築パイプライン。 キャプチャ&前処理 高品質なNeRFを生成するための最初のステップは、シーンを注意深くキャプチャすることです。3Dジオメトリーとカラーを派生させるための複数の異なる方向からの密な写真のコレクションを作成する必要があります。オブジェクトの表面に関する情報が多いほど、モデルはオブジェクトの形状やライトとの相互作用の方法を発見する際により優れたものになります。 さらに、NeRFモデルはカメラやシーンそのものにさらなる仮定を置きます。たとえば、カメラのほとんどのプロパティ(ホワイトバランスや絞りなど)は、キャプチャ全体で固定されていると仮定されます。同様に、シーン自体は時間的に凍結されていると仮定されます。ライティングの変更や動きは避ける必要があります。これは、キャプチャに必要な時間、利用可能な照明、機器の重さ、およびプライバシーなどの実用上の問題とのバランスを取る必要があります。プロの写真家と協力して、DSLRカメラを使用して会場写真を迅速かつ信頼性の高い方法でキャプチャする戦略を開発しました。このアプローチは、現在までのすべてのNeRF再構築に使用されています。…

デジタルルネッサンス:NVIDIAのNeuralangelo研究が3Dシーンを再構築
NVIDIA Researchによる新しいAIモデル、Neuralangeloは、ニューラルネットワークを使用して3D再構築を行い、2Dビデオクリップを詳細な3D構造に変換し、建物、彫刻、およびその他の現実世界のオブジェクトのリアルなバーチャルレプリカを生成します。 ミケランジェロが大理石のブロックから驚くべきリアルなビジョンを彫刻したように、Neuralangeloは複雑なディテールと質感を持つ3D構造を生成します。クリエイティブなプロフェッショナルは、これらの3Dオブジェクトをデザインアプリケーションにインポートし、アート、ビデオゲーム開発、ロボット工学、および産業用デジタルツインに使用するためにさらに編集することができます。 Neuralangeloは、屋根の瓦、ガラスの板、滑らかな大理石などの複雑な素材の質感を、従来の手法を大幅に上回る精度で2Dビデオから3Dアセットに変換することができます。この高い信頼性により、開発者やクリエイティブなプロフェッショナルは、スマートフォンでキャプチャされた映像を使用してプロジェクトに使用できる仮想オブジェクトを迅速に作成できます。 「Neuralangeloが提供する3D再構築機能は、クリエイターにとって大きな利益になります。現実世界をデジタル世界に再現するのを支援することで、開発者は小さな像や巨大な建築物などの詳細なオブジェクトを仮想環境にインポートできるようになります。」と、研究のシニアディレクターであり、論文の共著者でもあるMing-Yu Liu氏は述べています。 デモでは、NVIDIAの研究者が、ミケランジェロのダビデ像やフラットベッドトラックなどといったアイコニックなオブジェクトを再現する方法を紹介しました。Neuralangeloは、建物の内部および外部も再構築することができ、NVIDIAのベイエリアキャンパスの公園の詳細な3Dモデルで実証されました。 ニューラルレンダリングモデルが3Dで見る 3Dシーンを再構築するための以前のAIモデルは、繰り返しのテクスチャパターン、同質的な色、および強い色の変化を正確に捉えることができませんでした。Neuralangeloは、これらの微細なディテールを捉えるために、NVIDIA Instant NeRFの背後にある技術であるインスタントニューラルグラフィックスプリミティブを採用しています。 さまざまな角度から撮影されたオブジェクトまたはシーンの2Dビデオを使用して、モデルは異なる視点を捉えたいくつかのフレームを選択します。これは、アーティストが対象を多角的に考慮して深度、サイズ、および形状を把握するのと同じです。 フレームごとのカメラ位置が決定されたら、NeuralangeloのAIはシーンの大まかな3D表現を作成します。これは、彫刻家が主題の形を彫刻し始めるのと同じです。 次に、モデルはレンダリングを最適化してディテールをシャープにします。これは、彫刻家が石を注意深く削って布の質感や人物の形を再現するのと同じです。 最終的な結果は、仮想リアリティアプリケーション、デジタルツイン、またはロボット工学の開発に使用できる3Dオブジェクトまたは大規模なシーンです。 CVRPでNVIDIA Researchを見つける、6月18日〜22日 Neuralangeloは、6月18日から22日にバンクーバーで開催されるコンピュータビジョンとパターン認識のカンファレンス(CVRP)で発表されるNVIDIA Researchの約30のプロジェクトの1つです。これらの論文は、ポーズ推定、3D再構築、およびビデオ生成などのトピックをカバーしています。 これらのプロジェクトの1つであるDiffCollageは、長いランドスケープ方向、360度パノラマ、およびループモーション画像を含む大規模なコンテンツを作成する拡散法です。標準的なアスペクト比の画像のトレーニングデータセットをフィードすると、DiffCollageはこれらの小さな画像をコラージュのピースのように扱い、より大きなビジュアルのセクションとして扱います。これにより、拡散モデルは、同じスケールの画像のトレーニングを必要とせずに、継ぎ目のない大規模なコンテンツを生成できるようになります。 この技術は、テキストプロンプトをビデオシーケンスに変換することもできます。これは、人間の動きを捉える事前訓練された拡散モデルを使用して実証されました。 NVIDIA Researchについてもっと学ぶ。

2023年に知っておく必要があるデータ分析ツール
成功するデータアナリストになるために知っておく必要があるツールは何ですか?
Rによるディープラーニング
このチュートリアルでは、Rで深層学習タスクを実行する方法を学びます

エンジニアからDeclarative MLを使ったMLエンジニアになろう
機械学習の宣言的アプローチを用いて、わずか数行のコードでAIモデルを簡単に構築し、独自のLLMをカスタマイズする方法を学んでください
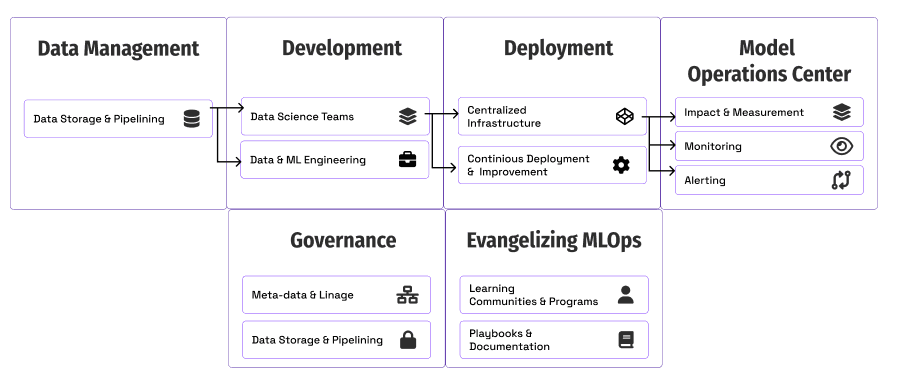
MLOpsを拡張するためのプレイブック
MLOpsチームは、AIを拡大するための能力を向上させるように圧力を受けています私たちはフォード・モーターと協力して、組織内でMLOpsを拡大する方法や、どのように始めるかを探ることにしました

PandasGUIによるデータ分析の革新
PandasGUIは、前例のないシンプルで効率的なデータ分析を実現します

AIの10年間のレビュー
画像分類からチャットボット療法まで

プロンプトエンジニアリングの芸術:ChatGPTのデコード
OpenAIとDeepLearning.AIのコースを受講して、AIとの相互作用の原理と実践をマスターする
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.