Learn more about Search Results A - Page 315

- You may be interested
- 「Rodinに会ってください:さまざまな入力...
- DuckDB Hugging Face Hubに保存されている...
- OpenAIはGPT-4 Turboを搭載した次世代AIの...
- 「Langchain Agentsを使用して、独自のデ...
- リモートワーク時代における新しいデータ...
- 2023年のトップジェネレーティブAI企業
- なぜすべての企業がAI画像生成器を使用す...
- マシンラーニングと最適化アルゴリズムの...
- 「Cassandra To-Doリスト ChatGPTプラグイ...
- グラフ機械学習の概要
- 量子コンピュータを使ってより高度な機械...
- 「コンピュータビジョンと言語モデルが見...
- 「データサイエンスの仕事を得る方法?[8...
- ベースとブラスへの情熱が、より良いツー...
- AI/MLを活用してインテリジェントなサプラ...
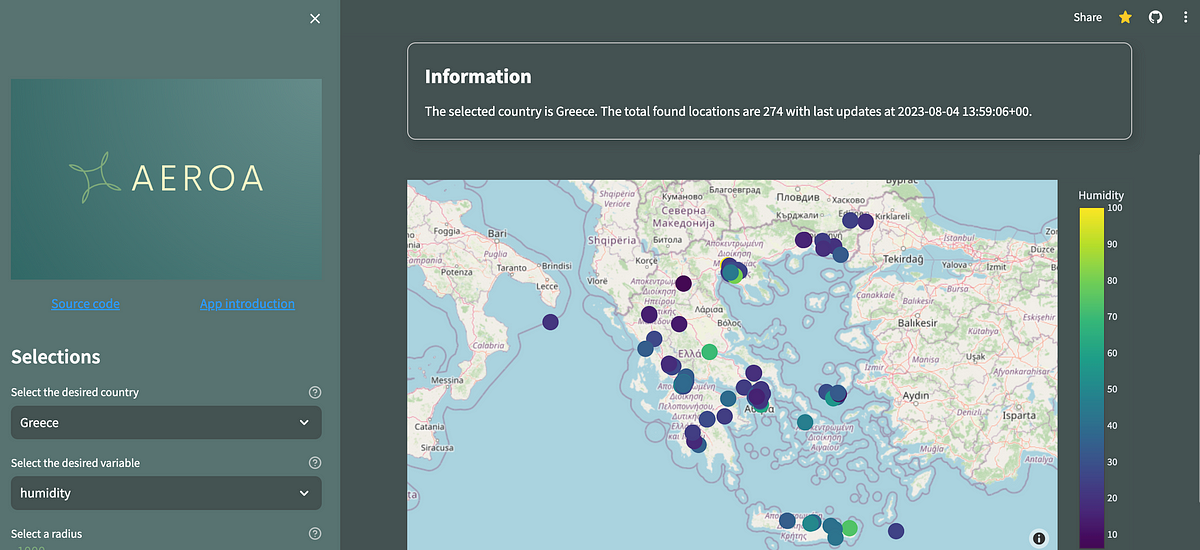
Streamlitの新しいConnections機能とインタラクティブなPlotlyマップでアプリを強化する
最近、Streamlitは、この記事が書かれている時点で、新機能であるst.experimental_connectionを発表しました私はそれを使ってみて、どのように動作するのかを理解することに非常に興味がありました...

メタのオーディオクラフト:AIによる音声と音楽の革命
音楽家やコンテンツクリエーターがシンプルなテキストからオーディオや音楽を生成できるという創造性の無限の可能性を想像してみてくださいMetaの新しいリリース、AudioCraftは、高品質の音が複雑な機器や楽器さえ必要としない有望な未来を予感させますこの画期的なAIツールは、MusicGen、AudioGen、EnCodecの3つのモデルから構成されています[…]

「ChatGPTを使用して完全な製品を作成するために学んだ7つの教訓」
つい最近、私はChatGPTを使って自分自身のフランス語のチューターを作成したことを共有しました(それはオープンソースです、ところで)私はアプリの設計方法(特にバックエンド)と接続方法について説明しました...

ダイナミックAIプロジェクト見積もり’ (Dainamikku AI purojekuto mitsumori)
現在、ほとんどの人が見積もりを使用しています顧客は、プロジェクトの結果を使用するタイミングを計画し制御するためにそれらが必要です見積もりはまた、プロジェクトマネージャーにも役立ちます...

このAI研究は、質問応答の実行能力において、指示に従うモデルの正確さと忠実さを評価します
最近導入された大規模言語モデル(LLM)は、人工知能(AI)コミュニティを席巻しています。これらのモデルは、非常に優れた自然言語処理(NLP)、自然言語生成(NLG)、自然言語理解(NLU)を使用して、人間を成功裏に模倣することができました。LLMは、現実的な会話をするために人間を模倣し、簡単な質問や複雑な質問に答えること、コンテンツの生成、コードの補完、機械翻訳、テキストの要約などが可能です。NLPの目標は、コンピュータシステムが自然言語で与えられた命令を理解し、反応することを可能にすることで、人々がより自然で柔軟な方法でそれらと関わることを可能にすることです。その最良の例が命令に従うモデルです。 これらのモデルは、LLM、教師ありの例、または他のタイプの教示、および自然言語の命令として記述された数千のタスクにさらされることで訓練されます。最近の研究では、Mila Quebec AI Institute、McGill大学、Facebook CIFAR AI Chairのチームが、与えられたテキストパッセージの質問応答(QA)の実行能力を評価するための命令に従うモデルのパフォーマンスを調査しました。これらのモデルは、タスクを記述するプロンプト、質問、およびリトリーバーによって取得された関連するテキストパッセージを提供されると、質問に答えることができ、これらのモデルによって生成される応答は自然で情報豊かであり、ユーザーの信頼と関与の構築に役立ちます。 これらのモデルは、取得したドキュメントと命令のみを入力に追加することで、ユーザーのクエリに自然かつ流暢に応答することができます。しかし、この余分な冗長性により、完全一致(EM)やF1スコアなどの従来のQA評価指標がモデルのパフォーマンスを効果的に定量化するのが難しくなります。これは、モデルの応答が参照回答に直接記載されていない情報も含める可能性があるためですが、それでも正確であることが求められます。チームは、この問題を克服するために、命令に従うモデルを検索に基づいた品質保証(QA)で測定するための2つの基準を提供しています。 情報の必要性、正確性に関するもの:この次元は、モデルがユーザーの情報要件をどれだけ満たしているかを評価します。生成された応答が、直接的に参照回答に記載されていることを超えた関連情報を含んでいるかどうかに関心があります。 提供された情報に対する忠実度:この次元は、モデルが提示された知識に基づいて答えを根拠付ける能力を評価します。真のモデルは、関連しない情報が提示された場合には応答を控えるだけでなく、知識のスニペットにアクセスできる場合には正確な回答を提供するべきです。 著者たちは、オープンドメインQAのためのNatural Questions、マルチホップQAのためのHotpotQA、会話型QAのためのTopiOCQAという3つの異なるQAデータセットで、いくつかの最近の命令に従うモデルを評価しました。彼らは900のモデル応答を手動で分析し、正確性と忠実度の異なる自動評価指標と比較しました。その研究は、参照回答のトークンの一部がモデルの応答にも含まれている割合を測定する再現率が、EMやF1スコアなどの語彙の重複メトリックよりも正確性との相関が強いことを示唆しています。忠実度のための他のトークン重複メトリックと比較して、モデルの回答トークンの一部が知識スニペットに存在する割合であるK-Precisionは、人間の判断とより強い相関関係があります。 結論として、この研究は、命令に従うモデルのQAタスクにおけるより徹底的な評価を進め、その利点と欠点の両方を考慮に入れることを目指しています。チームは、自分たちのコードとデータをGitHubリポジトリで公開することで、この領域でのさらなる進歩を促進しています。

ソルボンヌ大学の研究者は、画像、ビデオ、音声、言語のタスクに対する統合AIモデル「UnIVAL」を紹介しました
一般的なモデルを作成するための大きな進歩の一つは、大規模な言語モデル(LLM)の出現です。彼らの驚異的なテキスト理解および生成パフォーマンスは、通常、Transformerアーキテクチャおよび単一の次のトークン予測目標に基づいています。しかし、彼らは現在、テキスト以外の情報にアクセスすることができないため、制約があります。これは、さまざまなモダリティを使用してさまざまなタスクを実行できる信頼性のあるマルチモーダルモデルの要求を強調しています。 最近の取り組みでは、より強力なマルチモーダルモデルを構築するためのタスク/モダリティ特有の技術の改善が試みられています。これらの方法のいくつかは、画像/ビデオ-テキストなど2つ以上のモダリティを含めることを目指していますが、これらの取り組みのほとんどは、画像-テキストの仕事に専念しています。 この問題に対処するため、ソルボンヌ大学の研究者は、どんな問題にも対応できる汎用モデルを開発することから始めました。彼らはUnIVALという手法を導入しました。UnIVALは、単一のモダリティに依存しない方法です。UnIVALは、テキスト、画像、ビデオ、音声の4つのモダリティを統合しています。 UnIVALは、統一されたアーキテクチャ、語彙、入出力形式、およびトレーニング目標を使用して、画像、ビデオ、音声の言語の課題を解決する最初のモデルです。大量のデータや巨大なモデルサイズを必要とせずに、0.25億のパラメータモデルは、特定のモダリティに合わせた従来のアートと同等のパフォーマンスを提供します。研究者たちは同じサイズのモデルでいくつかの仕事で新たなSoTAを得ました。 彼らの事前トレーニングタスクおよびモダリティ間の知識の相互作用と転送に関する研究は、従来の単一タスクの事前トレーニングと比較して、マルチタスクの事前トレーニングの価値を示しています。彼らはまた、モデルを追加のモダリティで事前トレーニングすることが、未訓練のモダリティへの一般化を改善することを発見しました。特に、音声-テキストの問題でFine-tuneされた場合、UnIVALは音声の事前トレーニングなしでSoTAと競争力のあるパフォーマンスを達成することができます。 以前の研究に基づいて、チームはまた、重み補間によるマルチモーダルモデルの結合に関する新しい調査を発表しています。彼らは、重み空間での補間が、複数のFine-tuneされた重みのスキルを成功裏に結合し、さまざまなマルチモーダルタスクに対して統一された事前トレーニングモデルを使用する際に、推論のオーバーヘッドを必要としないより堅牢なマルチタスクモデルを作成することができることを示しています。マルチモーダルベースラインモデルにおける重み補間は、これまでテストされたことがありませんでしたが、この研究は初めて成功させたものです。 研究者たちはまた、UnIVALの2つの重要な欠点についても言及しています: UnIVALは幻覚に対して弱いです。特に、視覚的な説明で新しいオブジェクトを発明する場合があります(オブジェクトのバイアス)。それは正確さよりも一貫性に重点を置く傾向があります。 複雑な指示の追跡に問題があります。複雑な指示(例:似たような物の中から1つの物を選ぶ、遠くまたは極端に近いものを見つける、数字を認識するなど)が与えられた場合、モデルのパフォーマンスが低下することがわかりました。 研究者たちは、彼らの研究結果が他の科学者を刺激し、モダリティに依存しない汎用アシスタントエージェントの構築プロセスを加速することを願っています。
lazy_staticを使用してランタイムでRustの定数を初期化する
「コンパイル時に定数を初期化することがプログラミングにおいて良い慣行であることは秘密ではありません初期化のオーバーヘッドを削減するだけでなく、コンパイラがより簡単に処理できるようにもします...」

ライトオンAIは、Falcon-40Bをベースにした新しいオープンソースの言語モデル(LLM)であるAlfred-40B-0723をリリースしました
画期的な動きとして、LightOnは誇りを持って、Falcon-40Bに基づく革新的なオープンソースの言語モデル(LLM)であるAlfred-40B-0723のローンチを発表しました。この最先端のモデルは、ジェネレーティブAIをシームレスにワークフローに統合したい企業のニーズに特化して設計された、そのようなモデルとしては初めてのものです。エンタープライズは、Alfredとともに、ジェネレーティブAIのフルポテンシャルを引き出し、効率的に目標を達成するための頼れるパートナーを手に入れました。 Alfredは、そのコアとなる強力かつ多機能な言語モデルで、従来のLLMとは一線を画するさまざまなキーフィーチャーを提供しています。その1つの特徴的な機能は、「プロンプトエンジニアリング」であり、Alfredはユーザーが特定のニーズに合わせて効果的なプロンプトを構築し評価するのに優れています。このユニークな機能により、高い精度とパフォーマンスが保証され、企業は各自の産業で競争力を持つことができます。 さらに、Alfredの「ノーコードアプリケーション開発」機能を利用すると、コーディングの知識がなくてもアプリケーションを作成することができます。この時間の節約機能は、開発を加速するだけでなく、貴重なリソースを節約するため、ワークフローを最適化したい企業にとって理想的な選択肢です。 最先端の機能に加えて、Alfredは、コンテンツの要約、ドキュメントのクエリ応答、コンテンツの分類、およびキーワードの抽出など、言語モデルに期待されるすべての従来のタスクを実行することができます。その多様性により、さまざまな産業において広範な応用が可能な貴重なツールとなっています。 Alfred-40B-0723は、ジェネレーティブAIのコパイロットであるFalcon RLHFによってパワードされており、この分野での重要な進歩を表しています。人間のフィードバックからの強化学習を活用したAlfredは、LightOnの専任チームによって注釈が施された公開データセットと高度にキュレーションされたデータのミックスを用いて徹底的にトレーニングされています。この入念なトレーニングプロセスにより、Alfredは頑健でありながらも複雑なタスクに対して高品質な出力を理解し提供する能力を備えています。 エンタープライズ向けのジェネレーティブAIプラットフォームであるParadigmは、Alfred-40B-0723の真のポテンシャルを最大限に活用しています。Alfredは、ユーザーがタスクの成功基準を定義し、プロンプトを洗練させるのをサポートするジェネレーティブAIのコパイロットとして、この進化し続ける分野への進出を検討している人々にとって、すぐに使えるソリューションを提供します。ただし、LightOnはAlfredをオープンソースモデルとして提供していますが、Paradigmプラットフォームバージョンにはさらなる進化があり、ジェネレーティブAIの限界を押し広げることにLightOnが取り組んでいることを示しています。 Alfred-40B-0723のトレーニングには、スケーラブルなインフラストラクチャを提供するAWS SagemakerとのLightOnのパートナーシップが重要な役割を果たしています。このコラボレーションにより、モデルの効率性と信頼性が確保され、個々の開発者と大規模な組織の両方にアクセス可能となっています。ジェネレーティブAIコミュニティ内でのコラボレーションとイノベーションを促進するためのLightOnの取り組みの一環として、Alfredは現在HuggingFaceでも利用可能であり、Foundation Models向けのAWS Jumpstartでも近日中に利用可能となります。 オープンソースモデルとしてAlfred-40B-0723を共有することで、LightOnは開発者、研究者、組織に対して可能性を探求し、さらなる開発に貢献することを招待しています。ジェネレーティブAIコミュニティ内での協力は、その全ての可能性を解き放つために不可欠であり、さまざまな産業を変革するのに役立ちます。 まとめると、Alfred-40B-0723は、ジェネレーティブAIの世界での大きな進歩を表しています。その高度な機能と協力的でオープンなアプローチにより、ワークフローを向上させ、ジェネレーティブAIの変革力を活用することを求める企業にとって貴重な資産となっています。信頼できる味方としてのAlfredと共に、エンタープライズは革新の旅に乗り出し、最先端のテクノロジーによって支えられた未来を受け入れることができます。
「Hugging Face Transformersライブラリを解剖する」
これは、実践的に大規模言語モデル(LLM)を使用するシリーズの3番目の記事ですここでは、Hugging Face Transformersライブラリについて初心者向けのガイドを提供しますこのライブラリは、簡単で...

Google DeepMindの研究者たちは、RT-2という新しいビジョン・言語・行動(VLA)モデルを紹介しましたこのモデルは、ウェブデータとロボットデータの両方から学習し、それを行動に変えます
大規模な言語モデルは、流暢なテキスト生成、新たな問題解決、文章やコードの創造的な生成を可能にします。対照的に、ビジョン・ランゲージモデルは、開放的な語彙の視覚的認識を可能にし、画像中のオブジェクト-エージェントの相互作用について複雑な推論さえ行うことができます。ロボットが新しいスキルを学ぶ最適な方法は明確にする必要があります。ウェブ上で最も高度な言語モデルとビジョン・ランゲージモデルを訓練するために使用される数十億のトークンと写真に比べて、ロボットから収集されるデータ量は同等ではないでしょう。しかし、これらのモデルを即座にロボットの活動に適応することも困難です。なぜなら、これらのモデルは意味、ラベル、およびテキストのプロンプトについて推論を行う一方、ロボットはカルテシアンエンドエフェクタを使用したなどの低レベルのアクションを指示される必要があります。 Google DeepMindの研究は、ビジョン・ランゲージモデルを直接エンドツーエンドのロボット制御に組み込むことで一般化を改善し、新たな意味論的推論を可能にすることを目指しています。ウェブベースの言語データとビジョン・ランゲージデータの助けを借りて、ロボットの観測結果をアクションにリンクするために一つの包括的に訓練されたモデルを作成することを目指しています。彼らはロボットの軌跡データとインターネット上で行われる大規模な視覚的な質問応答演習のデータを使用して、最先端のビジョン・ランゲージモデルを共同でファインチューニングすることを提案しています。他の手法とは異なり、彼らは簡単で汎用的な手法を提案しています。つまり、ロボットのアクションをテキストトークンとして表現し、それらを自然言語トークンとしてモデルの訓練セットに直接組み込むことです。研究者はビジョン・ランゲージ・アクションモデル(VLA)を研究し、RT-2はそのようなモデルの一つです。厳格なテスト(6,000回の評価試行)を通じて、RT-2がインターネットスケールの訓練によってさまざまな新たなスキルを獲得し、パフォーマンスの高いロボットポリシーを実現することが分かりました。 Google DeepMindは、ロボットの操作を直接実行できるウェブソースのテキストと画像で訓練されたTransformerベースのモデルであるRT-2を公開しました。これは、Robotics Transformerモデル1の後継として開発されました。ロボットのアクションをテキストトークンとして表現し、オンラインで利用可能な大規模なビジョン・ランゲージデータセットと一緒に教えることができます。推論では、テキストトークンをロボットの振る舞いに変換し、フィードバックループを介して制御することができます。これにより、ビジョン・ランゲージモデルの一般化、意味理解、推論の一部をロボットポリシーの学習に活用することができます。プロジェクトのウェブサイト(https://robotics-transformer2.github.io/)では、RT-2の使用例のライブデモンストレーションを提供しています。 このモデルは、ロボットデータで見つかる分布に一致する方法で物理的なスキルを展開する能力を保持しています。しかし、ウェブから収集された知識を使用して、新しい文脈でこれらのスキルを使用することも学習します。ロボットデータには正確な数値やアイコンなどの意味的な手がかりは含まれていませんが、このモデルは学習したピックアンドプレイスのスキルを再利用することができます。ロボットデモではそのような関係は提供されませんでしたが、このモデルは正しいオブジェクトを選び、正しい位置に配置することができました。さらに、コマンドに思考プロンプトのようなチェーンを補完することで、モデルはより複雑な意味的な推論を行うこともできます。例えば、岩が自作のハンマーの最良の選択肢であることや、疲れている人にとってエナジードリンクが最良の選択肢であることを知っている場合です。 Google DeepMindの主な貢献は、ロボットデータを使用して前処理されたビジョン・ランゲージモデルをファインチューニングすることで、一般化が可能で意味論的に意識したロボットルールとなるモデル群であるRT-2です。55兆のパラメータを持つモデルを公開データから学習し、ロボットの動作コマンドで注釈付けされました。6,000回のロボット評価を通じて、RT-2はオブジェクト、シーン、および命令の一般化においてかなりの進歩を実証し、ウェブスケールのビジョン・ランゲージプリトレーニングの副産物としてさまざまな新たな能力を示すことを示しました。 主な特徴 RT-2の推論、シンボルの解釈、人間の識別能力は、さまざまな実用的なシナリオで活用することができます。 RT-2の結果は、ロボットデータを使用してVLMを事前学習することで、ロボットを直接制御できる強力なビジョン・ランゲージ・アクション(VLA)モデルに変えることができることを示しています。 RT-2のように、現実世界で様々な活動を完了するための情報の解釈や問題解決、思考能力を持つ汎用的な物理ロボットを構築するための有望な方向性です。 RT-2は、言語とビジュアルのトレーニングデータからロボットの動きへの情報の移行を処理する能力と効率性を持っています。 制約事項 RT-2は一般化の性質が励ましいものの、いくつかの欠点があります。ウェブスケールの事前学習をVLMを通じて組み込むことが、意味的および視覚的な概念の一般化を改善するという研究結果もあるものの、これによってロボットが動作を行う能力に新たな能力が付与されるわけではありません。モデルは、ロボットデータで見つかった物理的な能力のみを新しい方法で使用することができますが、それらの能力をより良く活用することを学習します。これは、競争力の次元でサンプルの多様性が必要であるとされます。人間の映像などの新しいデータ収集パラダイムは、新しいスキルを獲得するための将来的な研究の興味深い機会となります。 まとめると、Google DeepMindの研究者は、大規模なVLAモデルをリアルタイムで実行できることを示しましたが、これはかなりの計算負荷を要します。これらの手法が高頻度制御を必要とする状況に適用される際には、リアルタイム推論のリスクが重要なボトルネックとなります。このようなモデルがより速く、またはより安価なハードウェア上で動作できるようにする量子化および蒸留手法は、将来の研究の魅力的な領域です。また、RT-2の開発には比較的少数のVLMモデルしか利用できないという既存の制約も関連しています。 Google DeepMindの研究者は、ビジョン・ランゲージ・アクション(VLA)モデルのトレーニングプロセスを、事前学習とビジョン・ランゲージモデル(VLM)とロボットからのデータの統合によって要約しました。それから、VLAs(RT-2-PaLM-EおよびRT-2-PaLI-X)の2つのバリアントを紹介しました。これらのモデルは、ロボットの軌跡データで微調整され、テキストとしてトークン化されたロボットのアクションを生成します。さらに重要なことに、彼らはこの技術が一般化性能とウェブスケールのビジョン・ランゲージ事前学習から受け継がれた新しい能力を向上させることを示し、非常に効果的なロボットポリシーを導くと述べています。Google DeepMindによれば、ロボット学習の分野はこの簡単で普遍的な方法論によって他の分野の改善から戦略的に利益を得ることができるようになりました。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.