Learn more about Search Results いくつかの - Page 312

- You may be interested
- 「紙からピクセルへ:手書きテキストのデ...
- サムスンはAIとビッグデータを採用し、チ...
- 計算機の進歩により、研究者はより高い信...
- AIキャリアのトレンド:人工知能の世界で...
- ムーバブルインクのCEO兼共同創設者である...
- AI WebTVの構築
- 『MakeBlobs + フィクショナルな合成デー...
- 「量子インターネットへの新たなルート」
- 「データサイエンスにおける頻度論者とベ...
- ランウェイの新しい「モーションブラシ」...
- ビジネスにおけるオープンソースと専有モ...
- 「AIコントロールを手にして、サイバーセ...
- MusicGenを再構築:MetaのAI音楽における...
- パレート、パワーロー、そしてファットテール
- 「エンジニアがセメントとカーボンブラッ...

ChatGPTのデジタル商品をオンラインで販売するプロンプト
ChatGPTは、オンラインでデジタル製品を販売して収益を上げたい人にとって、ありがたい存在です

CapPaに会ってください:DeepMindの画像キャプション戦略は、ビジョンプレトレーニングを革新し、スケーラビリティと学習性能でCLIPに匹敵しています
「Image Captioners Are Scalable Vision Learners Too」という最近の論文は、CapPaと呼ばれる興味深い手法を提示しています。CapPaは、画像キャプションを競争力のある事前学習戦略として確立することを目的としており、DeepMindの研究チームによって執筆されたこの論文は、Contrastive Language Image Pretraining(CLIP)の驚異的な性能に匹敵する可能性を持つと同時に、簡単さ、拡張性、効率性を提供することを強調しています。 研究者たちは、Capと広く普及しているCLIPアプローチを比較し、事前学習コンピュータ、モデル容量、トレーニングデータを慎重に一致させ、公平な評価を確保しました。研究者たちは、Capのビジョンバックボーンが、少数派分類、キャプション、光学式文字認識(OCR)、視覚的問い合わせ(VQA)を含むいくつかのタスクでCLIPモデルを上回ったことがわかりました。さらに、大量のラベル付きトレーニングデータを使用した分類タスクに移行する際、CapのビジョンバックボーンはCLIPと同等の性能を発揮し、マルチモーダルなダウンストリームタスクにおける潜在的な優位性を示しています。 さらに、研究者たちは、Capの性能をさらに向上させるために、CapPa事前学習手順を導入しました。この手順は、自己回帰予測(Cap)と並列予測(Pa)を組み合わせたものであり、画像理解に強いVision Transformer(ViT)をビジョンエンコーダーとして利用しました。画像キャプションを予測するために、研究者たちは、標準的なTransformerデコーダーアーキテクチャを使用し、ViTエンコードされたシーケンスをデコードプロセスに効果的に使用するために、クロスアテンションを組み込みました。 研究者たちは、訓練段階でモデルを自己回帰的にのみ訓練するのではなく、モデルがすべてのキャプショントークンを独立して同時に予測する並列予測アプローチを採用しました。これにより、デコーダーは、並列でトークン全体にアクセスできるため、予測精度を向上させるために、画像情報に強く依存できます。この戦略により、デコーダーは、画像が提供する豊富な視覚的文脈を活用することができます。 研究者たちは、画像分類、キャプション、OCR、VQAを含むさまざまなダウンストリームタスクにおけるCapPaの性能を、従来のCapおよび最先端のCLIPアプローチと比較するための研究を行いました。その結果、CapPaはほぼすべてのタスクでCapを上回り、CLIP*と同じバッチサイズで訓練された場合、CapPaは同等または優れた性能を発揮しました。さらに、CapPaは強力なゼロショット機能を備え、見知らぬタスクにも効果的な汎化が可能であり、スケーリングの可能性があります。 全体的に、この論文で提示された作業は、画像キャプションを競争力のあるビジョンバックボーンの事前学習戦略として確立することを示しています。CapPaの高品質な結果をダウンストリームタスクにおいて実現することにより、研究チームは、ビジョンエンコーダーの事前トレーニングタスクとしてのキャプションの探索を促進することを望んでいます。その簡単さ、拡張性、効率性により、CapPaは、ビジョンベースのモデルを進化させ、マルチモーダル学習の境界を押し広げるための興味深い可能性を開拓しています。
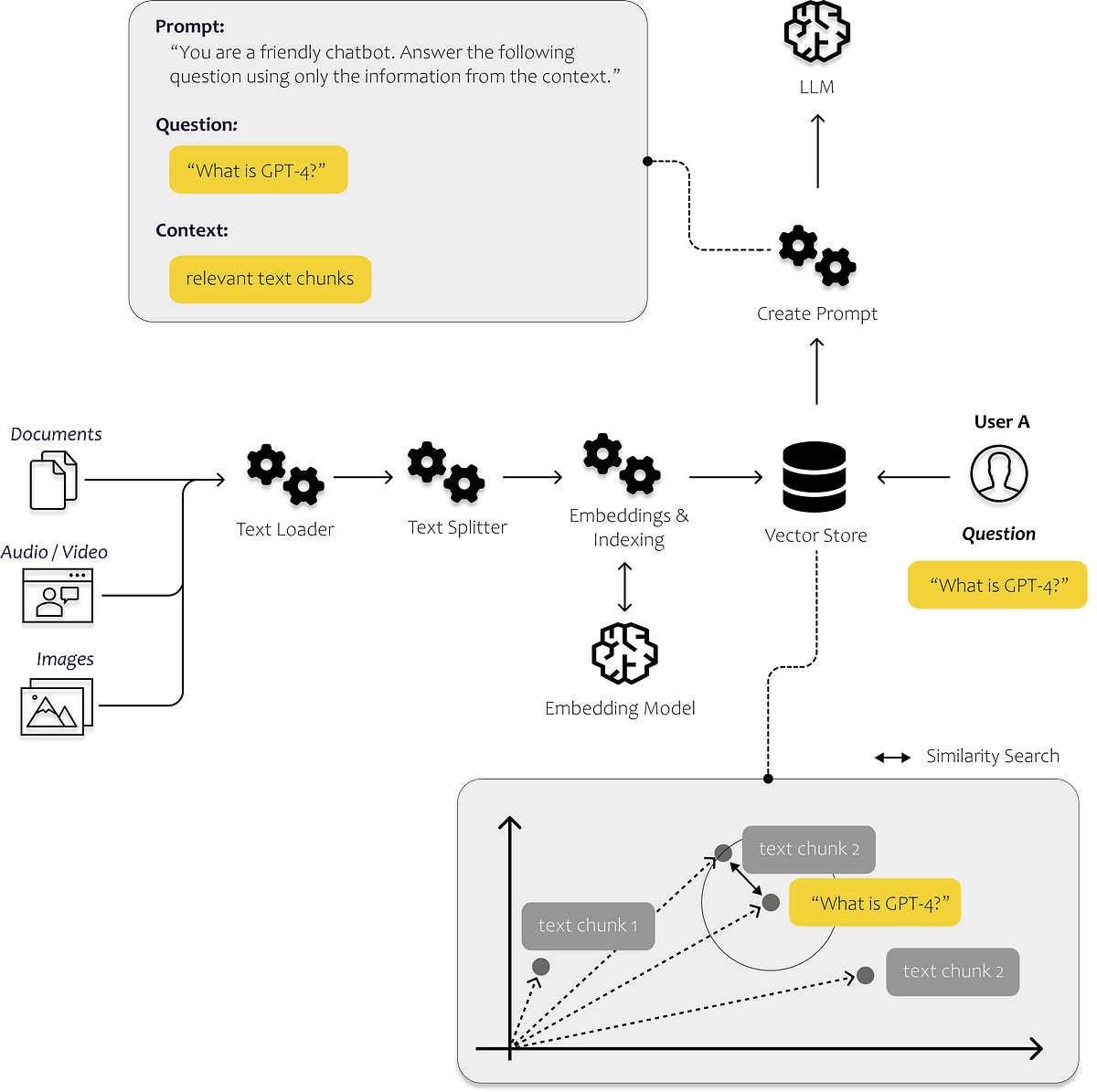
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...
再帰型ニューラルネットワークの基礎からの説明と視覚化
再帰型ニューラルネットワーク(RNN)は、順次操作が可能なニューラルネットワークです数年前ほど人気はありませんが、重要な発展を表しています...
ランダムフォレストと欠損値
オンラインで見つかる過剰にクリーンされたデータセット以外に、欠損値はどこにでもあります実際、データセットが複雑で大きいほど、欠損値がより多く存在する可能性があります...

CVPR 2023におけるGoogle
Googleのプログラムマネージャー、Shaina Mehtaが投稿しました 今週は、バンクーバーで開催される最も重要なコンピュータビジョンとパターン認識の年次会議であるCVPR 2023の始まりを迎えます(追加のバーチャルコンテンツもあります)。Google Researchはコンピュータビジョンの研究のリーダーであり、プラチナスポンサーであり、メインカンファレンスで約90の論文が発表され、40以上のカンファレンスワークショップやチュートリアルに積極的に参加しています。 今年のCVPRに参加する場合は、是非、ブースに立ち寄って、最新のマシンパーセプションの様々な分野に応用するための技術を積極的に探求している研究者とお話ししてください。弊社の研究者は、MediaPipeを使用したオンデバイスのMLアプリケーション、差分プライバシーの戦略、ニューラル輝度場技術など、いくつかの最近の取り組みについても話し、デモを行います。 以下のリストでCVPR 2023で発表される弊社の研究についても詳しくご覧いただけます(Googleの所属は太字で表示されています)。 理事会と組織委員会 シニアエリアチェアには、Cordelia Schmid、Ming-Hsuan Yangが含まれます。 エリアチェアには、Andre Araujo、Anurag Arnab、Rodrigo Benenson、Ayan Chakrabarti、Huiwen Chang、Alireza Fathi、Vittorio Ferrari、Golnaz Ghiasi、Boqing Gong、Yedid Hoshen、Varun Jampani、Lu…

非アーベル任意子の世界で初めてのブレードング
Google Quantum AIチームの研究員であるTrond AndersenとYuri Lenskyが投稿 同じ2つのオブジェクトを見せられて、目を閉じます。目を開けると、同じ2つのオブジェクトが同じ位置にあります。それらが交換されたかどうかをどのように判断できますか?直感と量子力学の法則は同意します:オブジェクトが本当に同じ場合、判断する方法はありません。 これは常識のように聞こえますが、これは私たちが知る3次元の世界にのみ適用されます。研究者たちは、2次元(2D)平面内でのみ移動することが制限された特別な粒子である任意子と呼ばれる特別なタイプの粒子に対して、量子力学がかなり異なるものを可能にすると予測しています。任意子は互いに区別できず、一部の非アーベル任意子は、交換時に共有量子状態の観測可能な差異を引き起こす特別な性質を持っており、互いに完全に区別できないにもかかわらず、交換されたときに判断できます。研究者たちは、その親戚であるアーベル任意子を検出することに成功しましたが、交換に対する変化が微妙で直接検出することができないため、「非アーベル交換行動」を実現することは、制御と検出の両方の課題によりより困難でした。 「超伝導プロセッサーにおけるグラフ頂点の非アーベル結び目」では、この非アーベル交換行動を初めて観測しました。非アーベル任意子は、粒子を交換し、まるでストリングが絡まるように交換し合うことで量子演算が実現される新しい方法を開く可能性があります。私たちの超伝導量子プロセッサーでこの新しい交換行動を実現することは、環境ノイズに対して頑強であるという利点を持つトポロジカル量子計算の代替ルートになる可能性があります。 交換統計と非アーベル任意子 この奇妙な非アーベル的な振る舞いがどのように発生するかを理解するには、2本のストリングを結ぶことの類比が役立ちます。同じ2本のストリングを取り、互いに平行に置きます。その後、エンドを交換してダブルヘリックス形状を形成します。ストリングは同じですが、エンドを交換するときにお互いを巻き込むため、エンドが交換されたときは非常に明確になります。 非アーベル任意子の交換は、同様の方法で視覚化できます。ここでは、ストリングは、粒子の位置を時間次元に拡張して「ワールドライン」を形成することによって作成されます。2つの粒子の位置を時間に対してプロットすることを想像してください。粒子がその場にとどまる場合、プロットは単に、それらの定常位置を表す2本の平行線になります。しかし、粒子の場所を交換すると、ワールドラインがお互いに絡み合います。2回交換すると、結び目ができます。 少し視覚化するのは難しいですが、4次元(3つの空間プラス1つの時間次元)の結び目は常に簡単に解除できます。それらは自明です。シューレースのように、片方の端を引っ張って解きます。しかし、粒子が2次元空間に制限されている場合、結び目は3次元にあり、私たちの日常的な3Dの生活から知っているように、常に簡単には解除できません。非アーベル任意子のワールドラインの結び目は、粒子の状態を変換するための量子計算操作として使用できます。 非アーベル任意子の重要な側面は「退化度」です。いくつかの分離された任意子の完全な状態はローカル情報によって完全に指定されるわけではなく、同じ任意子構成はいくつかの量子状態の重ね合わせを表すことができます。非アーベル任意子を互いに巻き付けることで、エンコードされた状態が変化する可能性があります。 非アーベル任意子の作り方 Googleの量子プロセッサーの1つで非アーベル結び目を実現するにはどうすればよいでしょうか?私たちは最近、量子誤り訂正のマイルストーンを達成したサーフェスコードから始めます。量子ビットはチェッカーボードパターンの頂点に配置されます。チェッカーボードの各色の正方形は、正方形の四隅にある量子ビットの2つの可能な共同測定の1つを表します。これらの「スタビライザー測定」は、+または-1の値を返すことができます。後者はプラケット違反と呼ばれ、単一量子ビットのXおよびZゲートを適用して、斜めに作成および移動できます(チェスのビショップのように)。最近、これらのビショップのようなプラケット違反はアーベル任意子であることを示しました。非アーベル任意子とは対照的に、アーベル任意子の状態は、交換されたときにわずかに変化します。非常に微妙で、直接検出することは不可能です。アーベル任意子は興味深いですが、非アーベル任意子ほどトポロジカル量子計算にとって有望ではありません。 非アーベルアニオンを生成するには、 degeneracy(つまり、すべてのスタビライザー測定が+1になる波動関数の数)を制御する必要があります。スタビライザー測定は2つの可能な値を返すため、各スタビライザーはシステムの degeneracy を半分に減らし、十分な数のスタビライザーで、1つの波動関数だけが基準を満たすようになります。したがって、 degeneracy を増やす簡単な方法は、2つのスタビライザーを合併することです。そうすることで、スタビライザーグリッドから1つのエッジを除去し、3つのエッジが交差する2つの点が生じます。これらの点は、「degree-3 vertices」(D3Vs)と呼ばれ、非アーベルアニオンであると予測されています。 D3Vをブレードするためには、それらを動かす必要があります。つまり、スタビライザーを新しい形に伸ばしたり、圧縮したりする必要があります。これは、アニオンとその近隣の間に2キュビットゲートを実装することによって実現します(下の中央と右のパネルを参照)。 スタビライザーコード内の非アーベルアニオン。a:…

AIの仕事を見つけるための最高のプラットフォーム
あなたのキャリアの目標、好みの仕事スタイル、およびAIの専門分野に依存するAIの仕事に最適なプラットフォームについてもっと学びましょう
Rにおける二元配置分散分析
二元分散分析(Two-way ANOVA)は、二つのカテゴリカル変数が量的連続変数に与える同時効果を評価することができる統計的方法です二元分散分析は…

より小さい相手による言語モデルからの知識蒸留に深く潜入する:MINILLMによるAIのポテンシャルの解放
大規模言語モデルの急速な発展による過剰な計算リソースの需要を減らすために、大きな先生モデルの監督の下で小さな学生モデルを訓練する知識蒸留は、典型的な戦略です。よく使われる2つのKDは、先生の予測のみにアクセスするブラックボックスKDと、先生のパラメータを使用するホワイトボックスKDです。最近、ブラックボックスKDは、LLM APIによって生成されたプロンプト-レスポンスペアで小さなモデルを最適化することで、励ましを示しています。オープンソースのLLMが開発されるにつれて、ホワイトボックスKDは、研究コミュニティや産業セクターにとってますます有用になります。なぜなら、学生モデルはホワイトボックスのインストラクターモデルからより良いシグナルを得るため、性能が向上する可能性があるためです。 生成的LLMのホワイトボックスKDはまだ調査されていませんが、小規模(1Bパラメータ)の言語理解モデルについては、主にホワイトボックスKDが調査されています。この論文では、彼らはLLMのホワイトボックスKDを調べています。彼らは、一般的なKDが課題を生成的に実行するLLMにとってより優れている可能性があると主張しています。シーケンスレベルモデルのいくつかの変種を含む標準的なKD目標は、教師と学生の分布の近似前方クルバック・ライブラー発散(KLD)を最小化し、KLとして知られています。教師分布p(y|x)と学生分布q(y|x)によってパラメータ化され、pがqのすべてのモードをカバーするように強制する。出力空間が有限の数のクラスを含むため、テキスト分類問題においてKLはよく機能します。したがって、p(y|x)とq(y|x)の両方に少数のモードがあることが保証されます。 しかし、出力空間がはるかに複雑なオープンテキスト生成問題では、p(y|x)はq(y|x)よりもはるかに広い範囲のモードを表す場合があります。フリーラン生成中、前方KLDの最小化は、qがpの空白領域に過剰な確率を与え、pの下で非常にありそうもないサンプルを生成することにつながる可能性があります。この問題を解決するために、コンピュータビジョンや強化学習で一般的に使用される逆KLD、KLを最小化することを提案しています。パイロット実験は、KLを過小評価することで、qがpの主要なモードを探し、空いている領域を低い確率で与えるように駆動することを示しています。 これは、LLMの言語生成において、学生モデルがインストラクター分布の長いテールバージョンを学習しすぎず、誠実さと信頼性が必要な実世界の状況で重要な応答の正確性に集中することを意味します。彼らは、ポリシーグラディエントで目標の勾配を生成してmin KLを最適化します。最近の研究では、PLMの最適化にポリシーオプティマイゼーションの効果が示されています。ただし、モデルのトレーニングはまだ過剰な変動、報酬のハッキング、および世代の長さのバイアスに苦しんでいることがわかりました。そのため、彼らは以下を含めます。 バリエーションを減らすための単一ステップの正則化。 報酬のハッキングを減らすためのティーチャー混合サンプリング。 長さのバイアスを減らすための長さ正規化。 広範なNLPタスクを含む指示に従う設定では、The CoAI Group、清華大学、Microsoft Researchの研究者は、MINILLMと呼ばれる新しい技術を提供し、パラメータサイズが120Mから13Bまでのいくつかの生成言語モデルに適用します。5つの指示に従うデータセットと評価のためのRouge-LおよびGPT-4フィードバックを使用します。彼らのテストは、MINILMがすべてのデータセットでベースラインの標準KDモデルを常に打ち負かすことを示しています(図1を参照)。さらに研究により、MINILLMは、より多様な長い返信を生成するのに適しており、露出バイアスが低く、キャリブレーションが向上していることがわかりました。モデルはGitHubで利用可能です。 図1は、MINILLMとシーケンスレベルKD(SeqKD)の評価セットでの平均GPT-4フィードバックスコアの比較を示しています。左側にはGPT-2-1.5Bがあり、生徒としてGPT-2 125M、340M、および760Mが動作します。中央には、GPT-2 760M、1.5B、およびGPT-Neo 2.7Bが生徒であり、GPT-J 6Bがインストラクターです。右側にはOPT 13Bがあり、生徒としてOPT 1.3B、2.7B、および6.7Bが動作しています。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.