Learn more about Search Results 15 - Page 310

- You may be interested
- 「ChatGPTを使ってデータサイエンスを学ぶ...
- 「ロボットのセンシングと移動のためのア...
- 大規模言語モデルの応用の最先端テクニック
- 「地震をAIで把握する:研究者が深層学習...
- MITの研究者たちは「MechGPT」を導入しま...
- 「Juliaでスクラッチから作成するゲート付...
- 「AUDITに会おう:潜在拡散モデルに基づく...
- 革新的なAI会社Ludaが革命的なリアルタイ...
- ACM(Association for Computing Machiner...
- 「FathomNetをご紹介します:人工知能と機...
- CMUの研究者が「WebArena」を導入:有用な...
- 「Pythonで時系列ネットワークグラフの可...
- 欧州とイスラエルのAIファーストスタート...
- ランダムフォレストにおける変数の重要性
- Pythonコードの行数を100行未満で使用した...

中国の研究者グループが開発したWebGLM:汎用言語モデル(GLM)に基づくWeb強化型質問応答システム
大規模言語モデル(LLM)には、GPT-3、PaLM、OPT、BLOOM、GLM-130Bなどが含まれます。これらのモデルは、言語に関してコンピュータが理解し、生成できる可能性の限界を大きく押し上げています。最も基本的な言語アプリケーションの一つである質問応答も、最近のLLMの突破によって大幅に改善されています。既存の研究によると、LLMのクローズドブックQAおよびコンテキストに基づくQAのパフォーマンスは、教師ありモデルのものと同等であり、LLMの記憶容量に対する理解に貢献しています。しかし、LLMにも有限な容量があり、膨大な特別な知識が必要な問題に直面すると、人間の期待には及びません。したがって、最近の試みでは、検索やオンライン検索を含む外部知識を備えたLLMの構築に集中しています。 たとえば、WebGPTはオンラインブラウジング、複雑な問い合わせに対する長い回答、同等に役立つ参照を行うことができます。人気があるにもかかわらず、元のWebGPTアプローチはまだ広く採用されていません。まず、多数の専門家レベルのブラウジング軌跡の注釈、よく書かれた回答、および回答の優先順位のラベリングに依存しており、これらは高価なリソース、多くの時間、および広範なトレーニングが必要です。第二に、システムにウェブブラウザとのやり取り、操作指示(「検索」、「読む」、「引用」など)を与え、オンラインソースから関連する材料を収集させる行動クローニングアプローチ(すなわち、模倣学習)は、基本的なモデルであるGPT-3が人間の専門家に似ている必要があります。 最後に、ウェブサーフィンのマルチターン構造は、ユーザーエクスペリエンスに対して過度に遅いことがあり、WebGPT-13Bでは、500トークンのクエリに対して31秒かかります。本研究の清華大学、北京航空航天大学、Zhipu.AIの研究者たちは、10億パラメータのジェネラル言語モデル(GLM-10B)に基づく、高品質なウェブエンハンスド品質保証システムであるWebGLMを紹介します。図1は、その一例を示しています。このシステムは、効果的で、手頃な価格で、人間の嗜好に敏感であり、最も重要なことに、WebGPTと同等の品質を備えています。システムは、LLM-拡張検索器を含む、いくつかの新しいアプローチや設計を使用して、良好なパフォーマンスを実現しています。精製されたリトリーバーと粗い粒度のウェブ検索を組み合わせた2段階のリトリーバーである。 GPT-3のようなLLMの能力は、適切な参照を自発的に受け入れることです。これは、小型の密集リトリーバーを改良するために洗練される可能性があります。引用に基づく適切なフィルタリングを使用して高品質のデータを提供することで、LLMはWebGPTのように高価な人間の専門家に頼る必要がありません。オンラインQAフォーラムからのユーザーチャムアップシグナルを用いて教えられたスコアラーは、さまざまな回答に対する人間の多数派の嗜好を理解することができます。 図1は、WebGLMがオンラインリソースへのリンクを含むサンプルクエリに対する回答のスナップショットを示しています。 彼らは、適切なデータセットアーキテクチャがWebGPTの専門家ラベリングに比べて高品質のスコアラーを生成できることを示しています。彼らの定量的な欠損テストと詳細な人間評価の結果は、WebGLMシステムがどれだけ効率的かつ効果的かを示しています。特に、WebGLM(10B)は、彼らのチューリングテストでWebGPT(175B)を上回り、同じサイズのWebGPT(13B)よりも優れています。Perplexity.aiの唯一の公開可能なシステムを改善するWebGLMは、この投稿時点で最高の公開可能なウェブエンハンスドQAシステムの一つです。結論として、著者らは次のことを提供しています。・人間の嗜好に基づく、効果的なウェブエンハンスド品質保証システムであるWebGLMを構築しました。WebGPT(175B)と同等のパフォーマンスを発揮し、同じサイズのWebGPT(13B)よりもはるかに優れています。 WebGPTは、LLMsと検索エンジンによって動力を与えられた人気システムであるPerplexity.aiをも凌駕します。•彼らは、WebGLMの現実世界での展開における制限を特定しています。彼らは、ベースラインシステムよりも効率的でコスト効果の高い利点を実現しながら、高い精度を持つWebGLMを可能にするための新しい設計と戦略を提案しています。•彼らは、Web強化QAシステムを評価するための人間の評価メトリックを定式化しています。広範な人間の評価と実験により、WebGLMの強力な能力が示され、システムの将来的な開発についての洞察が生成されました。コードの実装はGitHubで利用可能です。

LLM-Blenderに会いましょう:複数のオープンソース大規模言語モデル(LLM)の多様な強みを活用して一貫して優れたパフォーマンスを達成するための新しいアンサンブルフレームワーク
大規模言語モデルは、さまざまなタスクにおいて驚異的なパフォーマンスを発揮しています。ユニークでクリエイティブなコンテンツの生成や回答の提供から、言語の翻訳や文章の要約まで、LLMは人間のまねをすることに成功しました。GPT、BERT、PaLMなどのよく知られたLLMは、正確に指示に従い、大量の高品質データにアクセスすることで、話題になっています。GPT4やPaLMのようなモデルはオープンソースではないため、アーキテクチャやトレーニングデータを理解することができない人がいるのに対して、Pythia、LLaMA、Flan-T5などのオープンソースLLMの存在により、研究者がカスタム指示データセットでモデルを微調整し、改善する機会を提供しています。これにより、Alpaca、Vicuna、OpenAssistant、MPTなどのより小型で効率的なLLMの開発が可能になります。 市場をリードするオープンソースLLMはひとつではありません。多様な例において最高のLLMは大きく異なるため、これらのLLMを動的にアンサンブルすることは、改良された回答を継続して生み出すために必要不可欠です。さまざまなLLMの独自の貢献を統合することで、バイアス、エラー、不確実性を低減し、人間の好みにより近い結果を得ることができます。この問題に対処するため、人工知能アレン研究所、南カリフォルニア大学、浙江大学の研究者らは、複数のオープンソース大規模言語モデルの多くの利点を利用して、常に優れたパフォーマンスを発揮するアンサンブルフレームワークであるLLM-BLENDERを提案しました。 LLM-BLENDERは、PAIRRANKERとGENFUSERの2つのモジュールで構成されています。これらのモジュールは、異なる例に対して最適なLLMが大きく異なることを示しています。最初のモジュールであるPAIRRANKERは、潜在的な出力の微小な変化を特定するために開発されました。これは、元のテキストと各LLMからの2つの候補出力を入力として、高度なペアワイズ比較技術を使用します。入力と候補ペアを共にエンコードするために、RoBERTaなどのクロスアテンションエンコーダを使用し、PAIRRANKERはこのエンコードを使用して2つの候補の品質を決定することができます。 2番目のモジュールであるGENFUSERは、上位ランクに入った候補を統合して改善された出力を生成することに焦点を当てています。GENFUSERは、選択されたLLMの利点を最大限に活用しつつ、欠点を最小限に抑えることを目的としています。GENFUSERは、さまざまなLLMの出力を統合することで、1つのLLMの出力よりも優れた出力を開発することを目指しています。 評価には、MixInstructというベンチマークデータセットが提供されており、Oracleペアワイズ比較を組み合わせ、さまざまな指示データセットを組み合わせています。このデータセットでは、11の人気のあるオープンソースLLMを使用して、各入力に対して複数の候補を生成し、さまざまな指示に従うタスクを実行します。自動評価のためにOracle比較が使用されており、候補出力に対するグランドトゥルースランキングが与えられているため、LLM-BLENDERや他のベンチマーク技術のパフォーマンスを評価することができます。 実験結果は、LLM-BLENDERが個別のLLMやベースライン技術よりも優れたパフォーマンスを発揮することを示しています。LLM-BLENDERのアンサンブル手法を使用することで、単一のLLMやベースライン方法を使用する場合と比較して、より高品質な出力が得られることが示されています。PAIRRANKERの選択は、参照ベースのメトリックやGPT-Rankにおいて、個別のLLMモデルを上回っています。GENFUSERは、PAIRRANKERのトップピックを利用して、効率的な融合を通じて応答品質を大幅に改善しています。 LLM-BLENDERは、Vicunaなどの個別のLLMを上回り、アンサンブル学習を通じてLLMの展開と研究を改善する可能性を示しています。

WAYVE社がGAIA-1を発表:ビデオ、テキスト、アクション入力を活用して現実的な運転ビデオを作成する自律性のための新しい生成AIモデル
自動車産業は長年、自律走行を目指し、交通を革命化し、道路安全性を高めることを認識してきました。しかし、複雑な現実のシナリオを効果的にナビゲートできる自律システムを開発することは、大きな課題となっています。この課題に対応する最先端の生成AIモデルであるGAIA-1が紹介され、自律性を目的として設計されました。 GAIA-1は、ビデオ、テキスト、およびアクション入力を利用して、リアルな運転ビデオを生成しながら、自己車両の振る舞いやシーンの特徴に細かい制御を提供する、研究用モデルです。現実世界の生成ルールを体現するユニークな能力は、具体的なシステムが現実の習慣や振る舞いを理解し、再現できるようにする、具現化されたAIの重要な進展を表しています。GAIA-1の導入により、自律性分野での革新の可能性が無限に開かれ、自律運転技術の向上と加速化が促進されます。 GAIA-1モデルは、ビデオ、テキスト、およびアクション入力を活用して、リアルな運転ビデオを生成する、マルチモーダルなアプローチです。実際のイギリスの都市運転データの大規模なコーパスでトレーニングを行うことにより、モデルはビデオシーケンスの次のフレームを予測することを学び、大規模言語モデル(LLMs)に類似した自己回帰予測能力を示します。GAIA-1は、単なる生成ビデオモデル以上のもので、実際のワールドモデルとして機能します。車両、歩行者、道路レイアウト、信号機など重要な運転コンセプトを理解して分離し、自己車両の振る舞いやシーンの特徴に正確な制御を提供します。 GAIA-1の注目すべき偉業の1つは、世界の潜在的な生成ルールを具現化できる能力です。多様な運転データでの広範なトレーニングを通じて、モデルは自然界の固有の構造とパターンを合成し、高度にリアルな様々な運転シーンを生成します。このブレークスルーは、人工システムが世界と相互作用し、そのルールや振る舞いを理解して再現できる具現化されたAIを実現するための重要な一歩を示しています。 自律運転の重要な要素の1つは、世界モデルです。蓄積された知識と観察に基づいて世界を表現するものです。世界モデルにより、将来のイベントを予測することができ、自律運転にとって基本的要件となります。これらのモデルは、モデルベースの強化学習と計画のためのシミュレータを学習することができます。ワールドモデルを運転モデルに組み込むことで、人間の判断をより理解し、現実世界の状況での汎用性の向上につながることができます。GAIA-1は、将来の予測、運転シミュレーション、鳥瞰図予測、5年以上にわたる世界モデルの学習など、予測と世界モデルに関する幅広い研究を基盤としています。 さらに、GAIA-1は、トレーニングデータを超えて予測することができ、これにより、モデルを安全かつコントロールされた環境で評価するために使用される、正しくない運転行動を表すシミュレートされたデータを生成できます。この機能は、安全評価にとって貴重であり、自律運転モデルを評価するために使用されます。 GAIA-1は、自律性分野での研究、シミュレーション、トレーニングの進歩において、巨大な潜在能力を持つ、ゲームチェンジングな生成AI研究モデルを表します。リアルな様々な運転シーンを生成する能力により、複雑な現実のシナリオをより効果的にナビゲートするための自律システムのトレーニングに新しい可能性が開かれます。GAIA-1に関する継続的な研究と洞察が期待されており、自律運転の限界を押し広げ続けることになります。

SalesForceのAI研究者が、マスク不要のOVISを紹介:オープンボキャブラリーインスタンスセグメンテーションマスクジェネレータ
インスタンスセグメンテーションは、複数のオブジェクトを同じクラスに属するものとして、それらを異なるエンティティとして識別するコンピュータビジョンのタスクを指します。深層学習技術の急速な進歩により、過去数年間でセグメンテーション技術のインスタンス数が著しく増加しています。たとえば、畳み込みニューラルネットワーク(CNN)やMask R-CNNなどの先進的なアーキテクチャを使用してインスタンスセグメンテーションが行われます。このような技術の主要な特徴は、オブジェクト検出機能とピクセル単位のセグメンテーションを組み合わせることにより、画像内の各インスタンスに対して正確なマスクを生成し、全体像をより良く理解することができることです。 しかし、既存の検出モデルには、識別できる基本カテゴリの数に関するある種の欠点があります。以前の試行では、COCOデータセットでトレーニングされた検出モデルは、約80のカテゴリを検出する能力を獲得できることが示されています。しかし、追加のカテゴリを識別するには、労力と時間がかかります。これに対処するために、Open Vocabulary(OV)メソッドが存在し、画像とキャプションのペアとビジョン言語モデルを活用して新しいカテゴリを学習します。しかし、基本カテゴリと新しいカテゴリを学習するときの監督には大きな違いがあります。これは、基本カテゴリに過剰適合し、新しいカテゴリに対して一般化が不十分になることが多いためです。そのため、人間の介入がほとんど必要なく新しいカテゴリを検出する方法が必要です。これにより、モデルは現実世界のアプリケーションにとってより実用的でスケーラブルになります。 この問題に対処するため、Salesforce AIの研究者は、画像キャプションペアからバウンディングボックスとインスタンスマスク注釈を生成する方法を考案しました。彼らの提案された方法、Mask-free OVISパイプラインは、擬似マスク注釈を使用して、ビジョン言語モデルから派生した弱い監督を利用することで、基本的なカテゴリと新しいカテゴリを学習します。このアプローチにより、労力を要する人間の注釈が不要になり、過剰適合の問題が解決されます。実験的評価により、彼らの方法論が既存の最先端のオープンボキャブラリーインスタンスセグメンテーションモデルを超えることが示されました。さらに、彼らの研究は、2023年の著名なコンピュータビジョンとパターン認識会議で認められ、受け入れられました。 Salesforceの研究者は、擬似マスクの生成とオープンボキャブラリーインスタンスセグメンテーションの2つの主要なステージで構成されるパイプラインを考案しました。最初のステージでは、画像キャプションペアから対象物の擬似マスク注釈を作成します。事前にトレーニングされたビジョン言語モデルを利用して、オブジェクトの名前がテキストプロンプトとして機能し、オブジェクトをローカライズします。さらに、GradCAMを使用して反復的なマスキングプロセスを実行し、擬似マスクを精度良くオブジェクト全体にカバーするようにします。2番目のステージでは、以前生成されたバウンディングボックスを使用して、GradCAMアクティベーションマップと最も重なりが高い提案を選択するために、弱く監督されたセグメンテーション(WSS)ネットワークがトレーニングされます。最後に、生成された擬似注釈を使用してMask-RCNNモデルがトレーニングされ、パイプラインが完了します。 このパイプラインは、事前にトレーニングされたビジョン言語モデルと弱い監督モデルの力を利用して、追加のトレーニングデータとして使用できる擬似マスク注釈を自動生成することにより、人間の介入が不要になります。研究者たちは、MS-COCOやOpenImagesなどの人気のあるデータセットでいくつかの実験を行い、彼らのアプローチに擬似注釈を使用することで、検出およびインスタンスセグメンテーションのタスクで優れた性能を発揮することが示されました。Salesforceの研究者による独自のビジョン言語ガイドアプローチによる擬似注釈生成は、人間の注釈者を必要としないより高度で正確なインスタンスセグメンテーションモデルの誕生の道を開きます。

AIAgentに会ってみましょう:APIキーを必要とせず、GPT4によって動力を得るWebベースのAutomateGPT
AIAgentは、ユーザーが特定のタスクや目標に合わせてカスタマイズされたAIエージェントを作成する力を与える強力なWebベースのアプリケーションです。このアプリケーションは、目標を小さなタスクに分解し、それらを個別に完了することで機能します。このアプリの利点には、複数のAIエージェントを同時に実行できることや、最先端の技術を民主化することが挙げられます。 AIエージェントを使用することで、ユーザーはAIにタスクを指示することができます。たとえば、製品の競合他社を検索し、調査結果のレポートを作成したり、コードスニペットではなく、完全なアプリケーションを作成したりすることができます。 GPT-4の機能とインターネットアクセスを備えたAIAgentは、SEO最適化を伴うブログの自動化、ポッドキャストのトピックの研究などに最適です。APIキーは必要せず、クリーンでシンプルなユーザーインターフェイスを備えているため、AIエージェントとの作業がより簡単になります。 AIAgentは、ファイルの読み取りと書き込みができるため、ユーザーのドキュメントワークフローを効率化することができます。また、構文のハイライトを備えたインラインコードブロックや、サードパーティプラットフォームとのシームレスなコラボレーションなどの機能も備えています。 このツールの現在のバージョンは、ユーザーがGPT-3.5モデルを利用できる無料ティアを提供しています。ただし、GPT-4モデルにアクセスするためには、月額料金が必要です。 使用例 AIAgentは、SEO最適化が最優先事項であるブログコンテンツの調査や執筆を自動化するのに最適です。 ユーザーは、ツールを使用してTwitterの投稿スケジュールを明確に定義し、常にオーディエンスと価値あるコンテンツを共有することができます。 AIAgentは、インターネットアクセスを備えているため、ポッドキャストのトピックの研究に貴重なリソースとなります。さまざまなオンラインソースから重要な情報を取得し、ポッドキャストを充実させることができます。 このツールは、マーケティング分野で、経験豊富な専門家から戦略を学ぶことができます。マーケティングのプロフェッショナルからの記事や専門家の意見にアクセスして分析し、成功したマーケティング技術に関する洞察を得ることができます。 利点 AIAgentは、最新の自然言語処理と理解の最新技術を取り入れたGPT-4モデルによって動作します。 APIキーが不要であるため、シームレスで手間のかからない体験を提供できます。 シンプルでクリーンなユーザーインターフェイス(UI)により、ユーザーがシステムをスムーズに操作できます。 ツールにはインターネットアクセスがあり、オンラインリソースを活用してリアルタイム情報を取得することができます。 個人は、特定のニーズや好みに応じてタスクを完全にカスタマイズおよび変更することができます。 結論 以上より、AIAgentは、様々なタスクにカスタマイズされたAIエージェントを作成することができる強力なWebベースのアプリケーションです。高度なGPT-4モデルとインターネットアクセスにより、ブログの自動化、ポッドキャストのトピックの研究、マーケティング戦略の学習などの利点があります。AIAgentのユーザーフレンドリーなインターフェース、APIキーの不要性、複数のAIエージェントを同時に実行できる能力により、AIツールの分野でChatGPT、AutoGPT、AgentGPTなどの類似プラットフォームとの競合力が高まっています。

GitHubトピックススクレイパー | PythonによるWebスクレイピング
「GitHub Topics Scraper」このプロジェクトは、GitHub Topicsページから情報を取得し、リポジトリ名と詳細を抽出することを目的としています

最後のチャンス!認定AIワークショップが24時間後に開始されます!見逃さないでください!
興奮するニュースです! 予想されていたAIワークショップが約24時間後に開始されますこの素晴らしい機会を逃さないようにしたいと思います! このメールは、あなたの場所を確保するための重要なリマインダーとして役立ちます...

Google フォトのマジックエディター:写真を再構築するための新しいAI編集機能
Magic Editorは、AIを使用して写真を再構想するのを手助けする実験的な編集体験です今年後半には、選択されたPixel電話での早期アクセスが計画されています
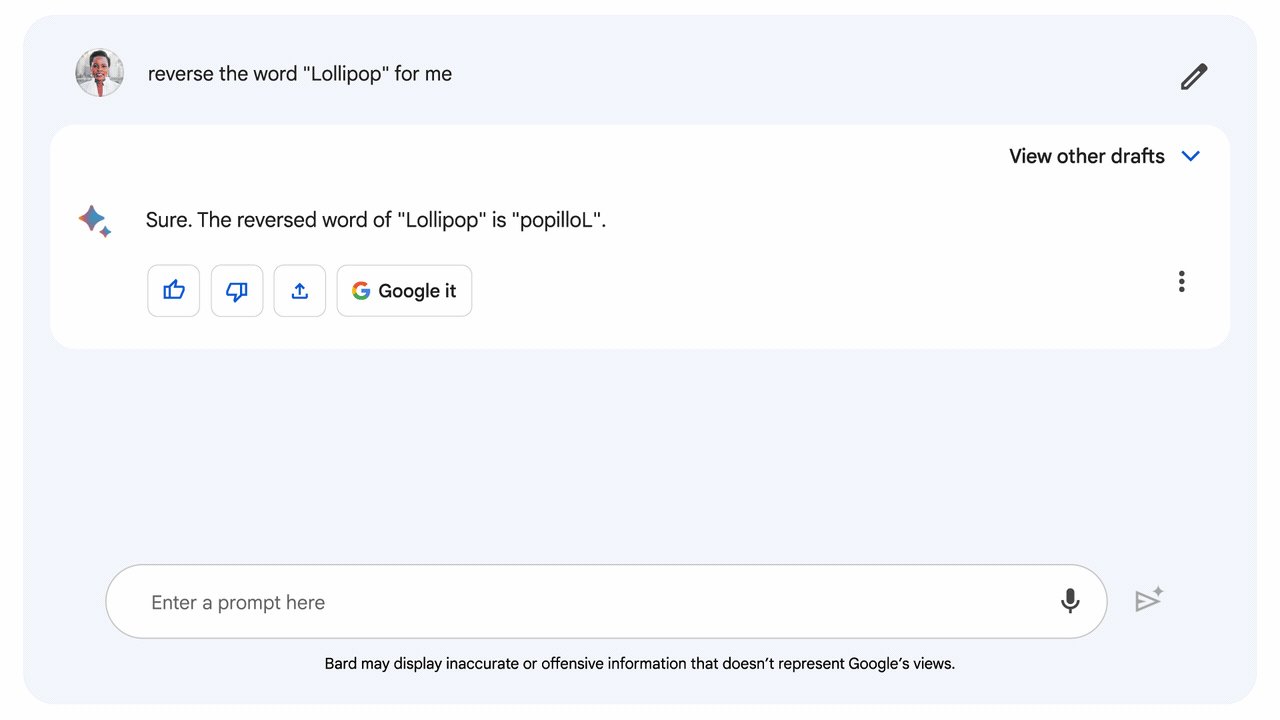
バードは論理と推論力においてますます上達しています
精度の高い回答を得るための2つの改善点と、Google Sheetsへのエクスポートに向けた改善点がBardに導入されます
欠陥が明らかにされる:MLOpsコース作成の興味深い現実
不完全なものが明らかにされる舞台裏バッチ特徴ストアMLパイプラインMLプラットフォームPythonGCPGitHub ActionsAirflowMLOpsCI/CDコース
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.