Learn more about Search Results TensorFlow - Page 30

- You may be interested
- 「Amazon Kendraを使用した知的にDrupalコ...
- 「トリントの創設者兼CEO、ジェフ・コフマ...
- 「50以上の最新の最先端人工知能(AI)ツ...
- ソウル国立大学の研究者たちは、効率的か...
- ウェブコンテンツの選択肢と制御を進化さ...
- BERTopicとHugging Face Hubの統合をご紹...
- Taplio LinkedInの成長に最適なAIツール
- このAI論文では、大規模言語モデルでの関...
- 「中小企業オーナーが未来に向けて前向き...
- 「クオリティデータ分析の美学」
- AnomalyGPT:LVLMを使用して産業の異常を...
- JavaScriptの配列を繰り返す方法
- 最高のAIジョブコース(2023年)
- なぜ私たちはニューラルネットワークを持...
- 『EMQX MQTT Brokerクラスタリングの基礎...

「機械学習を使ってイタリアのファンタジーフットボールで勝利した方法」
「機械工学の専門家としてプログラミングとコンピュータサイエンスに興味を持っていた私は、数年前に機械学習と人工知能の世界に魅了されました彼らの重要性を認識し…」
「機械学習を使ったイタリアンファンタジーフットボールで勝利した方法」
数年前からプログラミングとコンピュータサイエンスに興味を持つ機械工学のエンジニアとして、私は機械学習と人工知能の世界に魅了されました彼らの重要性を認識し、
テキストの生成方法:トランスフォーマーを使用した言語生成のための異なるデコーディング方法の使用方法
はじめに 近年、大規模なトランスフォーマーベースの言語モデル(例えば、OpenAIの有名なGPT2モデル)が数百万のウェブページを学習することで、オープンエンドの言語生成に対する関心が高まっています。条件付きのオープンエンドの言語生成の結果は印象的です。例えば、ユニコーンに関するGPT2、XLNet、CTRLでの制御言語生成などです。改良されたトランスフォーマーアーキテクチャや大量の非教示学習データに加えて、より良いデコーディング手法も重要な役割を果たしています。 このブログ記事では、異なるデコーディング戦略の概要と、さらに重要なことに、人気のあるtransformersライブラリを使ってそれらを簡単に実装する方法を紹介します! 以下のすべての機能は、自己回帰言語生成に使用することができます(ここでは復習です)。要するに、自己回帰言語生成は、単語のシーケンスの確率分布を条件付き次の単語の分布の積として分解できるという仮定に基づいています: P(w1:T∣W0)=∏t=1TP(wt∣w1:t−1,W0) ,with w1:0=∅, P(w_{1:T} | W_0 ) = \prod_{t=1}^T P(w_{t} | w_{1: t-1}, W_0) \text{ ,with } w_{1: 0} = \emptyset, P(w1:T∣W0)=t=1∏TP(wt∣w1:t−1,W0) ,with w1:0=∅,…

「The Reformer – 言語モデリングの限界を押し上げる」
Reformerが半ミリオントークンのシーケンスを訓練するために8GB未満のRAMを使用する方法 Reformerモデルは、Kitaev、Kaiserらによって2020年に紹介されたもので、現在のところ最もメモリ効率の良いトランスフォーマーモデルの1つです。 最近、長いシーケンスモデリングは大きな関心を集めており、今年だけでも多くの論文が提出されています(Beltagyら(2020年)、Royら(2020年)、Tayら、Wangらなど)。長いシーケンスモデリングの背後にある動機は、要約、質問応答などの多くのNLPタスクが、BERTなどのモデルよりも長い入力シーケンスを処理する必要があるということです。大きな入力シーケンスを処理する必要があるタスクでは、長いシーケンスモデルはメモリオーバーフローを避けるために入力シーケンスを切り詰める必要がなく、従って標準の「BERT」のようなモデルを上回る性能を示すことが示されています(Beltagyら(2020年)による)。 Reformerは、このデモに示されているように、一度に最大で半ミリオンのトークンを処理する能力により、長いシーケンスモデリングの限界を em em ます。比較のために、従来の bert-base-uncased モデルでは、入力の長さを512トークンに制限しています。Reformerでは、標準のトランスフォーマーアーキテクチャの各部分が最小限のメモリ要件を最適化するために再設計されており、性能の大幅な低下を伴わずにメモリの改善がなされています。 メモリの改善は、Reformerの作者がトランスフォーマーワールドに導入した4つの特徴に帰属できます: Reformer Self-Attention Layer – ローカルコンテキストに制限されることなく自己注意を効率的に実装する方法は? Chunked Feed Forward Layers – 大規模なフォワードレイヤーの時間とメモリのトレードオフを改善する方法は? Reversible Residual Layers…

エンコーダー・デコーダーモデルのための事前学習済み言語モデルチェックポイントの活用
Transformerベースのエンコーダーデコーダーモデルは、Vaswani et al.(2017)で提案され、最近ではLewis et al.(2019)、Raffel et al.(2019)、Zhang et al.(2020)、Zaheer et al.(2020)、Yan et al.(2020)などにおいて大きな関心を集めています。 BERTやGPT2と同様に、大規模な事前学習済みエンコーダーデコーダーモデルは、Lewis et al.(2019)、Raffel et al.(2019)などのさまざまなシーケンス対シーケンスのタスクにおいて性能を大幅に向上させることが示されています。しかし、エンコーダーデコーダーモデルの事前学習には膨大な計算コストがかかるため、そのようなモデルの開発は主に大企業や研究所に限定されています。 Sascha Rothe、Shashi Narayan、Aliaksei Severynによる「シーケンス生成タスクのための事前学習済みチェックポイントの活用」(2020)では、事前学習済みのエンコーダーやデコーダーのみのチェックポイント(例:BERT、GPT2)でエンコーダーデコーダーモデルを初期化して、コストのかかる事前学習をスキップする方法が紹介されています。著者らは、このようなウォームスタートされたエンコーダーデコーダーモデルが、T5やPegasusなどの大規模な事前学習済みエンコーダーデコーダーモデルと比較して、複数のシーケンス対シーケンスのタスクで競争力のある結果をもたらすことを示しています。 このノートブックでは、エンコーダーデコーダーモデルをウォームスタートする方法の詳細を説明し、Rothe et…
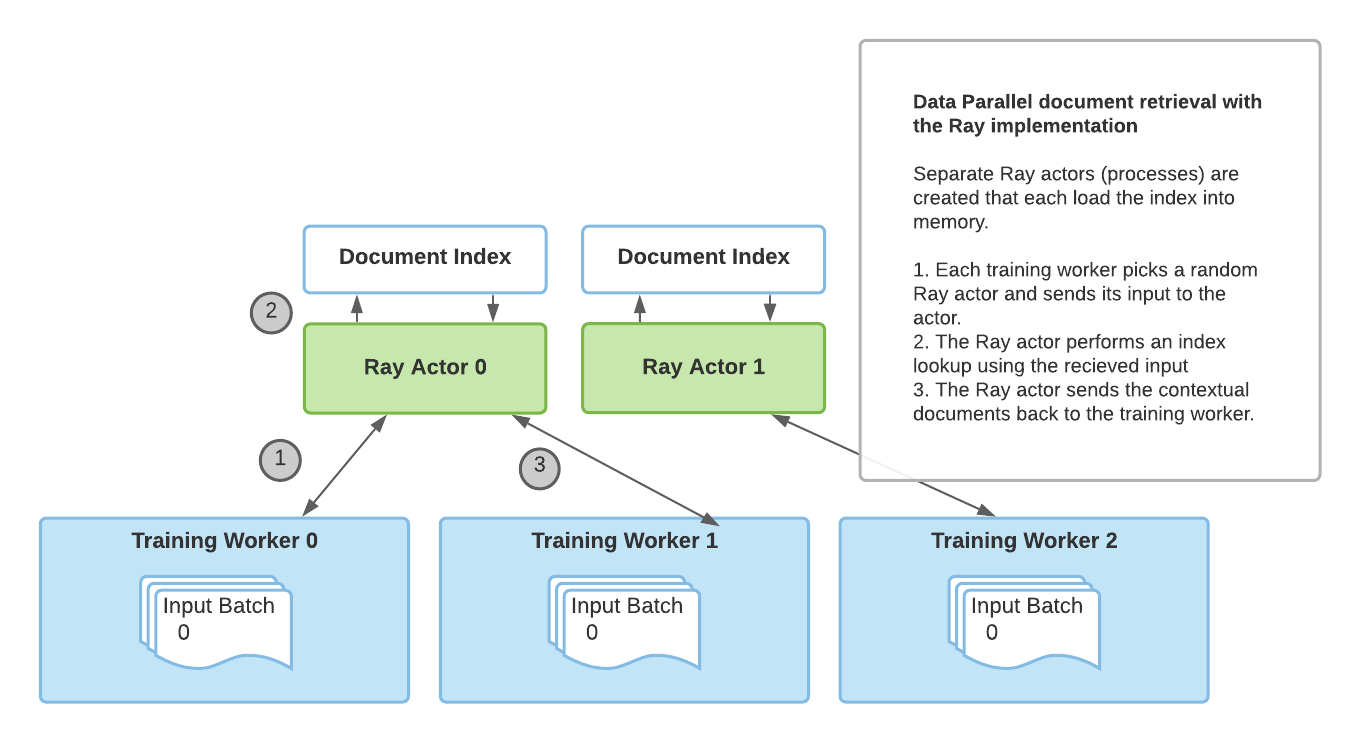
Huggingface TransformersとRayを使用した検索増強生成
アノスケールのチームからのゲストブログ投稿:Amog Kamsetty氏 Huggingface Transformersは最近、Retrieval Augmented Generation(RAG)モデルを追加しました。これは、外部のドキュメント(ウィキペディアなど)を活用して知識を拡充し、知識集約的なタスクで最先端の結果を実現する新しいNLPアーキテクチャです。このブログ投稿では、スケーラブルなアプリケーションを構築するためのライブラリであるRayをRAGの文脈におけるドキュメント検索メカニズムに統合する方法を紹介します。これにより、検索呼び出しの速度が2倍に向上し、RAGの分散ファインチューニングのスケーラビリティが向上します。 Retrieval Augmented Generation(RAG)とは何ですか? RAGの概要です。モデルは外部のデータセットから文脈ドキュメントを取得し、実行の一環として使用します。これらの文脈ドキュメントは元の入力と組み合わせて出力を生成するために使用されます。このGIFはFacebookのオリジナルのブログ投稿から取得されました。 最近、HuggingfaceはFacebook AIと提携して、RAGモデルをTransformersライブラリの一部として導入しました。 RAGは他のseq2seqモデルと同様に機能しますが、外部の知識ベース(ウィキペディアのテキストコーパスなど)から文脈ドキュメントを取得する中間コンポーネントを持っています。これらのドキュメントは入力シーケンスと組み合わせて基礎となるseq2seqジェネレータに渡されます。 この情報検索ステップにより、RAGはモデルパラメータに埋め込まれた知識と文脈のパッセージに含まれる情報という複数の知識源を活用することができます。これにより、質問応答などのタスクで他の最先端モデルを上回るパフォーマンスを発揮します。Huggingfaceが提供するデモを使用して、自分自身で試すこともできます。 ファインチューニングのスケーリング これらの文脈ドキュメントの取得は、RAGの最先端の結果にとって重要ですが、追加の複雑さをもたらします。データ並列トレーニングルーチンを介してトレーニングプロセスをスケーリングアップする際、ドキュメントの検索の単純な実装はトレーニングのボトルネックになることがあります。さらに、検索コンポーネントで使用されるドキュメントインデックスは非常に大きいため、各トレーニングワーカーが自分自身の複製されたインデックスを読み込むことは不可能です。 以前のRAGファインチューニングの実装では、torch.distributed通信パッケージを使用してドキュメント検索部分を活用していました。しかし、この実装は柔軟性に欠け、スケーラビリティに制約がありました。 その代わりに、フレームワークに依存しないアドホックな並行プログラミングのためのより柔軟な実装が必要です。それには、Rayが完璧に適しています。Rayは一般的な分散および並列プログラミングのためのシンプルで強力なPythonライブラリです。Rayを使用して分散ドキュメント検索を行うことで、torch.distributedに比べて検索呼び出しごとに2倍の高速化と、ファインチューニングのスケーラビリティの向上を実現しました。 ドキュメント検索のためのRay torch.distributedの実装によるドキュメント検索 torch.distributedを使用したドキュメント検索の主な欠点は、トレーニングに使用されるプロセスグループに依存していて、ランク0のトレーニングワーカーのみがインデックスをメモリに読み込んでいたことです。 その結果、この実装にはいくつかの制限がありました: 同期のボトルネック:ランク0のワーカーはすべてのワーカーから入力を受け取り、インデックスクエリを実行し、その結果を他のワーカーに送信する必要がありました。これにより、複数のトレーニングワーカーでのパフォーマンスが制限されました。 PyTorch固有の:ドキュメント検索プロセスグループはトレーニングに使用される既存のプロセスグループに依存する必要があり、トレーニングにはPyTorchを使用する必要がありました。…

Google Cloud上のサーバーレストランスフォーマーパイプラインへの私の旅
コミュニティメンバーのマクサンス・ドミニシによるゲストブログ投稿 この記事では、Google Cloudにtransformers感情分析パイプラインを展開するまでの道のりについて説明します。まず、transformersの簡単な紹介から始め、実装の技術的な部分に移ります。最後に、この実装をまとめ、私たちが達成したことについてレビューします。 目標 Discordに残された顧客のレビューがポジティブかネガティブかを自動的に検出するマイクロサービスを作成したかったです。これにより、コメントを適切に処理し、顧客の体験を向上させることができます。たとえば、レビューがネガティブな場合、顧客に連絡し、サービスの品質の低さを謝罪し、サポートチームができるだけ早く連絡し、問題を修正するためにサポートすることができる機能を作成できます。1か月あたり2,000件以上のリクエストは予定していないため、時間と拡張性に関してはパフォーマンスの制約を課しませんでした。 Transformersライブラリ 最初に.h5ファイルをダウンロードしたとき、少し混乱しました。このファイルはtensorflow.keras.models.load_modelと互換性があると思っていましたが、実際にはそうではありませんでした。数分の調査の後、ファイルがケラスモデルではなく重みのチェックポイントであることがわかりました。その後、Hugging Faceが提供するAPIを試して、彼らが提供するパイプライン機能についてもう少し調べました。APIおよびパイプラインの結果が素晴らしかったため、自分自身のサーバーでモデルをパイプラインを通じて提供することができると判断しました。 以下は、TransformersのGitHubページの公式の例です。 from transformers import pipeline # 感情分析のためのパイプラインを割り当てる classifier = pipeline('sentiment-analysis') classifier('We are very happy to include…

パートナーシップ:Amazon SageMakerとHugging Face
この笑顔をご覧ください! 本日、私たちはHugging FaceとAmazonの戦略的パートナーシップを発表しました。これにより、企業が最先端の機械学習モデルを活用し、最新の自然言語処理(NLP)機能をより迅速に提供できるようになります。 このパートナーシップを通じて、Hugging Faceはお客様にサービスを提供するためにAmazon Web Servicesを優先的なクラウドプロバイダーとして活用しています。 共通のお客様に利用していただくための第一歩として、Hugging FaceとAmazonは新しいHugging Face Deep Learning Containers(DLC)を導入し、Amazon SageMakerでHugging Face Transformerモデルのトレーニングをさらに簡単にする予定です。 Amazon SageMaker Python SDKを使用して新しいHugging Face DLCにアクセスし、使用する方法については、以下のガイドとリソースをご覧ください。 2021年7月8日、私たちはAmazon SageMakerの統合を拡張し、Transformerモデルの簡単なデプロイと推論を追加しました。Hugging…
CPU上でBERT推論をスケーリングアップする(パート1)
.centered { display: block; margin: 0 auto; } figure { text-align: center; display: table; max-width: 85%; /* デモです; 必要に応じていくつかの量 (px や %) を設定してください */…

スケールにおけるトランスフォーマーの最適化ツールキット、Optimumをご紹介します
この投稿は、Hugging Faceが最先端の機械学習プロダクションパフォーマンスを民主化するための旅の第一歩です。目指すところに到達するために、私たちはハードウェアパートナーと手を組んで取り組む予定です。以下のIntelと協力しています。この旅に参加して、新しいオープンソースライブラリであるOptimumをフォローしてください! なぜ 🤗 Optimum なのか? 🤯 Transformersのスケーリングは難しい Tesla、Google、Microsoft、Facebook、これらの企業に共通するものは何でしょうか?もちろんいくつかありますが、その1つは毎日数十億のTransformerモデルの予測を実行していることです。TeslaのAutoPilotのためのTransformer、Gmailの文章補完のためのTransformer、Facebookの投稿のリアルタイム翻訳のためのTransformer、Bingの自然言語クエリに対する回答のためのTransformerなど、さまざまな用途で使用されています。 Transformerは機械学習モデルの精度を飛躍的に向上させ、NLPを征服し、SpeechやVisionなどの他のモダリティにも広がっています。しかし、これらの巨大なモデルを本番環境に持ち込み、スケールで高速に実行することは、どの機械学習エンジニアリングチームにとっても大きな課題です。 上記の企業のように、数百人の高度に熟練した機械学習エンジニアを雇っていない場合はどうでしょうか?私たちの新しいオープンソースライブラリであるOptimumを通じて、Transformerのプロダクションパフォーマンスのための究極のツールキットを構築し、特定のハードウェア上でモデルをトレーニングおよび実行するための最大の効率性を実現することを目指しています。 🏭 OptimumがTransformerを活用します 最適なパフォーマンスでモデルをトレーニングおよび提供するためには、モデルのアクセラレーション技術は対象のハードウェアと互換性が必要です。各ハードウェアプラットフォームは、パフォーマンスに大きな影響を与える特定のソフトウェアツール、機能、ノブを提供しています。同様に、スパース化や量子化などの高度なモデルアクセラレーション技術を活用するためには、最適化されたカーネルがシリコン上の演算子と互換性があり、モデルアーキテクチャから派生したニューラルネットワークグラフに特化している必要があります。この3次元の互換性行列やモデルアクセラレーションライブラリの使用方法について詳しく調査するのは、ほとんどの機械学習エンジニアにとって困難な作業です。 Optimumはこの作業を簡単にすることを目指し、効率的なAIハードウェアを対象としたパフォーマンス最適化ツールを提供し、ハードウェアパートナーとの共同開発で機械学習エンジニアをML最適化の魔術師に変えます。 Transformerライブラリでは、最先端のモデルを研究者やエンジニアが簡単に使用できるようにし、フレームワーク、アーキテクチャ、パイプラインの複雑さを抽象化しました。 Optimumライブラリでは、エンジニアが利用可能なすべてのハードウェア機能を活用し、ハードウェアプラットフォーム上でのモデルアクセラレーションの複雑さを抽象化することで、エンジニアに簡単になります。 🤗 Optimumの実践:Intel Xeon CPU向けのモデルの量子化方法 🤔 量子化の重要性と正しい方法 BERTなどの事前学習済み言語モデルは、さまざまな自然言語処理タスクで最先端の結果を達成しており、ViTやSpeech2Textなどの他のTransformerベースのモデルも、コンピュータビジョンや音声タスクで最先端の結果を達成しています。Transformerは機械学習の世界で広く使われており、今後も使われ続けます。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.