Learn more about Search Results T5 - Page 30

- You may be interested
- 「ジェーン・ザ・ディスカバラー:大規模...
- AIに親しむ
- 百度のAI研究者がVideoGenを紹介:高フレ...
- 「データサイエンス30年:データサイエン...
- 「クラシック音楽の作曲家を識別するため...
- 「MicrosoftがOrca2を公開し、初の控えめ...
- 「帰納バイアスの不思議なお話」
- 「独立性の理解とその因果推論や因果検証...
- 「PhysObjectsに会いましょう:一般的な家...
- Amazon Pollyを使用してテキストが話され...
- フラッシュアテンション:基本原則の解説
- 5つのAI自動化エージェンシーのアイデア(...
- ウィザードコーダー:最高のコーディング...
- 自動化された欺瞞検出:東京大学の研究者...
- 「言語モデルにアルゴリズム的な推論を教...
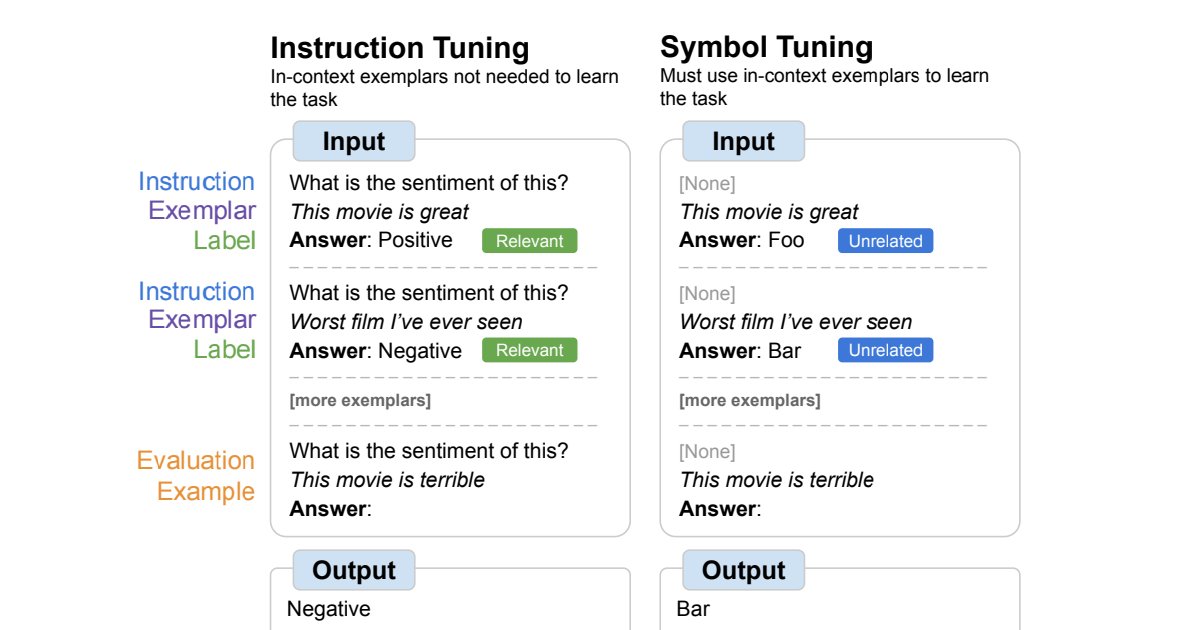
シンボルの調整は言語モデルの文脈における学習を向上させます
Google Researchの学生研究者であるJerry Weiと主任科学者のDenny Zhouによって投稿されました。 人間の知性の重要な特徴の一つは、わずかな例だけを用いて推論することで新しいタスクを学ぶことができることです。言語モデルのスケーリングによって、マシンラーニングにおいて新たな応用やパラダイムを実現することができました。しかし、言語モデルはプロンプトの与え方に敏感であり、頑健な推論を行っているわけではないことを示しています。例えば、言語モデルはしばしばプロンプトエンジニアリングやタスクの指示としてのフレーズのような作業が必要であり、不正確なラベルが表示されてもタスクのパフォーマンスに影響を与えないという予期しない振る舞いを示すことがあります。 「Symbol tuning improves in-context learning in language models」では、シンボルチューニングと呼ばれるシンプルなファインチューニング手法を提案しています。この手法は入力とラベルのマッピングを強調することで、インコンテキスト学習を改善することができます。私たちはFlan-PaLMモデルにおけるシンボルチューニングの実験を行い、さまざまな設定での利点を観察しました。 シンボルチューニングは、未知のインコンテキスト学習タスクにおいてパフォーマンスを向上させ、指示や自然言語のラベルがないような曖昧なプロンプトに対しても非常に頑健です。 シンボルチューニングされたモデルは、アルゴリズムの推論タスクにおいて非常に強力です。 最後に、シンボルチューニングされたモデルは、インコンテキストで提示された反転したラベルを追従する能力が大幅に向上しており、インコンテキスト情報を使用して以前の知識を上書きすることができます。 シンボルチューニングの概要。モデルは自然言語のラベルが任意のシンボルに置き換えられたタスクでファインチューニングされます。シンボルチューニングは、指示や関連するラベルが利用できない場合、モデルがインコンテキストの例を使用してタスクを学ぶ必要があるという直感に基づいています。 動機 指示チューニングは一般的なファインチューニング手法であり、パフォーマンスを向上させ、モデルがインコンテキストの例に従う能力を改善することが示されています。ただし、評価例に指示と自然言語のラベルを通じてタスクが冗長に定義されるため、モデルは例を使用する必要がありません。例えば、上の図の左側では、例がモデルがタスク(感情分析)を理解するのに役立つことができますが、モデルは例を無視してタスクを示す指示を読むことができます。 シンボルチューニングでは、モデルは指示が削除され、自然言語のラベルが意味的に関連のないラベル(例:「Foo」、「Bar」など)に置き換えられた例でファインチューニングされます。この設定では、インコンテキストの例を見ないとタスクが明確になりません。例えば、上の図の右側では、タスクを理解するために複数のインコンテキストの例が必要です。シンボルチューニングはモデルにインコンテキストの例を推論することを教えるため、シンボルチューニングされたモデルは、インコンテキストの例とそのラベルの間の推論を必要とするタスクにおいてより優れたパフォーマンスを発揮するはずです。 シンボルチューニングに使用されるデータセットとタスクの種類。 シンボル調整手順 私たちは、シンボル調整手順に使用するために、22の公開されている自然言語処理(NLP)データセットを選択しました。これらのタスクは過去に広く使用されており、私たちは離散的なラベルを必要とするため、分類タイプのタスクのみを選択しました。その後、ラベルを整数、文字の組み合わせ、および単語の3つのカテゴリから選択された約30,000の任意のラベルの1つにランダムにマッピングします。 実験では、PaLMの指示に調整されたバリアントであるFlan-PaLMをシンボル調整します。Flan-PaLMモデルの3つの異なるサイズを使用します:Flan-PaLM-8B、Flan-PaLM-62B、およびFlan-PaLM-540B。また、Flan-cont-PaLM-62B(780Bトークンではなく1.3TトークンでのFlan-PaLM-62B)もテストし、62B-cと略称します。…
「10/7から16/7までのトップコンピュータビジョン論文」
コンピュータビジョンは、機械に視覚世界を解釈し理解させることに焦点を当てた人工知能の分野であり、画期的な研究と技術の進化により急速に進化しています

Google AIは、環境の多様性と報酬の指定の課題に対処するための、普遍的なポリシー(UniPi)を提案します
産業に関係なく、人々の生活の質を向上させるために、人工知能(AI)と機械学習(ML)技術は常に取り組んできました。最近のAIの主要な応用の一つは、さまざまなドメインで意思決定タスクを達成できるエージェントを設計・作成することです。たとえば、GPT-3やPaLMのような大規模言語モデルや、CLIPやFlamingoのようなビジョンモデルは、それぞれの分野でゼロショット学習に優れていることが証明されています。しかし、このようなエージェントの訓練には、1つの主要な欠点があります。それは、このようなエージェントが訓練中に環境の多様性を示すという固有の特性を持つためです。単純に言えば、異なるタスクや環境のための訓練は、時折学習や知識の移転、モデルの領域間の一般化能力を妨げるため、さまざまな状態空間の使用を必要とします。さらに、強化学習(RL)ベースのタスクでは、特定のタスクのための報酬関数を作成することが困難になります。 この問題に取り組んで、Google Researchのチームは、このようなツールがより汎用性のあるエージェントの構築に使用できるかどうかを調査しました。彼らの研究では、チームは特にテキストガイドの画像合成に焦点を当て、テキストの形で目標をプランナーに与え、意図した行動のシーケンスを生成し、その後生成されたビデオから制御アクションを抽出する方法を提案しました。したがって、Googleチームは、最近の論文で「テキストガイドされたビデオ生成によるユニバーサルポリシーの学習」と題された論文で、環境の多様性と報酬の指定の課題に取り組むためのユニバーサルポリシー(UniPi)を提案しました。UniPiポリシーは、テキストをタスクの説明のためのユニバーサルなインターフェースとし、ビデオをさまざまな状況でのアクションと観察の振る舞いを伝えるためのユニバーサルなインターフェースとして使用します。具体的には、チームは、ビデオジェネレータをプランナーとして設計し、現在の画像フレームと現在の目標を示すテキストプロンプトを入力として、画像シーケンスまたはビデオの形で軌跡を生成します。生成されたビデオは、その後、実行される基礎となるアクションを抽出する逆ダイナミクスモデルに入力されます。このアプローチは、言語とビデオの普遍性を利用して、新しい目標や異なる環境に対して一般化することができるという点で特筆すべきです。 ここ数年、テキストガイドの画像合成の分野で著しい進歩が達成され、洗練された画像を生成する驚異的な能力を持つモデルが生み出されています。これが研究チームがこの問題を選んだ動機となりました。Googleの研究者が提案するUniPiアプローチは、主に次の4つのコンポーネントで構成されています:タイリングによる軌跡の一貫性、階層的な計画、柔軟な行動調整、およびタスク固有のアクション適応。これらについて詳しく説明します。 1. タイリングによる軌跡の一貫性: 既存のテキストからビデオへの方法では、生成されるビデオは基礎となる環境状態が大きく変化することがあります。しかし、正確な軌跡プランナーを構築するためには、すべてのタイムスタンプで環境が一定であることが重要です。したがって、条件付けられたビデオ合成において環境の一貫性を強制するために、研究者は生成されたビデオの各フレームをノイズ除去しながら観測された画像を提供します。時間を超えて基盤となる環境状態を保持するために、UniPiは各ノイズの混入した中間フレームをサンプリングステップごとに条件付けられた観測された画像と直接連結します。 2. 階層的な計画: 複雑で洗練された環境で計画を立てる際には、すべての必要なアクションを生成することは困難です。この問題を克服するために、計画手法は自然な階層を利用して、小さい空間で大まかな計画を作成し、それをより詳細な計画に洗練していきます。同様に、ビデオ生成プロセスでは、UniPiはまず望ましいエージェントの振る舞いを示す粗いレベルのビデオを作成し、欠落しているフレームを埋めたり、滑らかにしたりして、より現実的なものに改善します。これは、各ステップがビデオの品質を向上させ、望ましい詳細レベルに達するまでビデオを改善する階層を使用することで実現されます。 3. 柔軟な行動調整: 小さな目標のためのアクションのシーケンスを計画する際には、生成されたプランを変更するために外部の制約を簡単に組み込むことができます。これは、プランの特性に基づいて望ましい制約を反映する確率的な事前知識を組み込むことによって行われることができます。この事前知識は、学習された分類器または特定の画像上のディラックデルタ分布を使用してプランを特定の状態に誘導するものです。このアプローチはUniPiとも互換性があります。研究者たちは、テキストに条件付けられたビデオ生成モデルを訓練するためにビデオ拡散アルゴリズムを使用しました。このアルゴリズムは、Text-To-Text Transfer Transformer(T5)からエンコードされた事前学習言語特徴量で構成されています。 4. タスク固有のアクション適応: 小さな逆動力学モデルは、合成されたビデオセットを使用してビデオフレームを低レベルの制御アクションに変換するためにトレーニングされます。このモデルはプランナーとは別であり、シミュレータによって生成された別の小さなデータセットでトレーニングすることができます。逆動力学モデルは、入力フレームと現在の目標のテキスト説明を取り、イメージフレームを合成し、将来の手順を予測するためのアクションのシーケンスを生成します。その後、エージェントはこれらの低レベルの制御アクションをクローズドループ制御を使用して実行します。 要約すると、Googleの研究者たちは、テキストベースのビデオ生成を使用して、組み合わせ的な汎化、マルチタスク学習、および現実世界の転送が可能なポリシーを表現する価値を示すことで、印象的な貢献をしました。研究者たちは、新しい言語ベースのタスクのいくつかで彼らのアプローチを評価し、UniPiが他のベースライン(Transformer BC、Trajectory Transformer、Diffuserなど)と比較して、言語のプロンプトの見たことも知らない組み合わせにもうまく一般化することが結論付けられました。これらの励みに満ちた発見は、生成モデルと利用可能な膨大なデータが、多目的な意思決定システムを作成するための貴重な資源としての潜在能力を浮き彫りにしています。

鑑識分類器をだます:敵対的な顔生成における生成モデルの力
ディープラーニング(DL)の最近の進歩、特に生成的対抗ネットワーク(GAN)の領域では、存在しない高度にリアルかつ多様な人間の顔の生成が可能になりました。これらの人工的に作られた顔は、ビデオゲーム、メイクアップ産業、コンピュータ支援設計などの領域で多くの有益な応用が見られますが、誤用時には重要なセキュリティと倫理上の懸念が生じます。 合成または偽の顔の誤用は、深刻な結果をもたらす可能性があります。例えば、GANによって生成された顔画像がアメリカの選挙で使用され、偽のソーシャルメディアプロファイルを作成することで、対象のグループに対して迅速に誤情報を広めることができました。同様に、17歳の高校生が強力な生成モデルであるStyleGAN2を利用して、アメリカの議会候補の偽のプロフィール写真をTwitterに認証させることに成功しました。これらの出来事は、GANによって生成された顔画像の誤用に関連する潜在的なリスクを強調し、それらの使用のセキュリティと倫理的な意味に対処することの重要性を示しています。 GANによって生成された偽の顔と実際の顔を区別するために、さまざまな方法が提案されています。これらの研究で報告された結果は、シンプルで監視されたディープラーニングベースの分類器がGANによって生成された画像の検出に非常に効果的であることを示しています。これらの分類器は、一般的に法科学分類器またはモデルと呼ばれます。 しかし、知的な攻撃者は、敵対的な機械学習技術を使用してこれらの偽の画像を操作し、高い視覚品質を維持しながら法科学分類器を回避することができます。最近の研究では、敵対的な攻撃者が生成モデルの潜在空間最適化を介して生成モデルの多様体を敵対的に探索することで、対象の法科学検出器によって誤分類されるリアルな顔を生成できることを示しています。さらに、敵対的な偽の顔は、画像空間に制約を課す従来の敵対的な攻撃よりも少ないアーティファクトを示すことも示されています。 ただし、この研究には重要な制限があります。具体的には、生成された敵対的な顔の属性(肌の色、表情、年齢など)を制御する能力が欠けています。これらの顔の属性を制御することは、特定の民族や年齢層をターゲットにして社会メディアプラットフォームを通じて迅速に虚偽のプロパガンダを広めることを目指す攻撃者にとって重要です。 潜在的な影響を考えると、画像法科学の研究者が属性条件付け攻撃に取り組み、開発することが重要です。これにより、既存の法科学顔分類器の脆弱性が明らかにされ、将来的に効果的な防御メカニズムの設計に取り組むことができます。この記事で説明されている研究は、属性制御が敵対的な攻撃において必要な理解を提供し、脆弱性の包括的な把握と堅牢な対策の開発を促すために行われています。 提案手法の概要は以下の通りです。 属性ベースの生成とテキスト生成に関連する2つのアーキテクチャが提示されています。画像に基づいているか、テキストによって誘導されているかに関係なく、提案手法は統一されたフレームワーク内で法科学顔検出器を欺くことができるリアルな敵対的な偽の顔を生成することを目指しています。この技術は、StyleGAN2の高度に分解された潜在空間を利用して、提供されたリファレンス画像に存在する属性を持つ偽の顔を生成するために、属性固有の潜在変数を敵対的に最適化する効率的なアルゴリズムを導入します。このプロセスにより、リファレンス画像から生成された偽の画像に望ましい粗いまたは細かい詳細を効果的に転送することができます。画像ベースの属性条件付けを行う際には、知覚損失によって誘導されながら敵対的な空間を探索することで、望ましい属性を生成された偽の画像に転送することができます。 さらに、Contrastive Language-Image Pre-training(CLIP)の共同画像テキスト表現能力を活用して、提供されたテキストの説明に基づいて偽の顔を生成します。これにより、生成された敵対的な顔画像と関連するテキストの説明との整合性を確保することができます。CLIPのテキストによるガイド付き特徴空間を利用することで、この特徴空間内で敵対的な潜在コードを検索し、関連するテキストで説明された属性に合致する偽の顔を生成することが可能になります。 論文で提供されているいくつかの結果を以下に示します。 これは、法医学的な分類器を回避するために現実的な敵対的な顔を生成するための新しいAI技術の要約でした。もし興味があり、この研究についてさらに詳しく知りたい場合は、以下のリンクをクリックして詳細情報を見つけることができます。

「AI駆動の洞察:LangChainとPineconeを活用したGPT-4」
「質的データと効果的に取り組むことは、プロダクトマネージャーが持つべき最も重要なスキルの一つですデータを収集し、分析し、効率的な方法で伝えることができるようにすることは、...」

「SimCLRの最大の問題を修正する〜BYOL論文の解説」
SimCLRは対比学習のアイデアを成功裏に実装し、当時新たな最先端の性能を達成しました!それにもかかわらず、このアイデアには根本的な弱点があります!…に対する感度が高いのです

「Text2Cinemagraphによるダイナミックな画像の力を探索:テキストプロンプトからシネマグラフを生成するための革新的なAIツール」
もしこの用語について初めて知ったのなら、シネマグラフについて何か疑問に思うかもしれませんが、おそらくすでに見かけたことがあるでしょう。シネマグラフは、特定の要素が連続的な動きを繰り返す一方で、他のシーンは静止しているビジュアルに魅了されるイラストです。それらは画像ではありませんが、ビデオとも分類できません。特定の瞬間を捉えながら、ダイナミックなシーンを特色付けるユニークな方法を提供します。 シネマグラフは、社会メディアプラットフォームや写真共有サイトでのショートビデオやアニメーションGIFとして人気を集めています。また、オンライン新聞、商業ウェブサイト、仮想会議でもよく見られます。しかし、シネマグラフを作成することは非常に困難な作業であり、カメラを使用してビデオや画像を撮影し、シームレスなループ動画を生成するために半自動の技術を利用する必要があります。このプロセスには、適切なフッテージを撮影すること、ビデオフレームを安定化させること、アニメーション化された領域と静止した領域を選択すること、モーションの方向を指定することなど、多くのユーザーの関与が必要とされます。 本記事で提案されている研究では、新たな課題であるテキストベースのシネマグラフの合成に取り組み、データキャプチャと労力のかかる手作業を大幅に減らすことが目指されています。この研究で提案されている手法は、「水の落下」と「流れる川」といったモーション効果を捉えることが困難な、静止画や既存のテキストから画像への変換技術を用いたモーション合成です。重要な点は、この手法によってシネマグラフで実現可能なスタイルと構図の範囲が広がり、コンテンツクリエーターが多様な芸術的スタイルを指定し、想像力豊かなビジュアル要素を表現できることです。この研究で紹介されている手法は、現実的なシネマグラフと創造的または異世界的なシーンの両方を生成する能力を持っています。 現在の手法は、この新しい課題に対処する際に重要な課題に直面しています。一つのアプローチは、芸術的な画像を生成し、それをアニメーション化するためのテキストから画像への変換モデルを利用することです。しかし、単一の画像に対して動きを生成する既存のアニメーション手法は、主に実際のビデオデータセットで訓練されているため、芸術的な入力に対して意味のあるモーションを生成することが困難です。個々のシネマグラフを作成し、多様な芸術的スタイルを含む大規模なループ動画データセットを構築することは複雑であり、実用的ではありません。 また、テキストベースのビデオモデルを直接利用してビデオを生成する方法もあります。ただし、これらの手法では、静止した領域に目立つ時間的なチラつきのアーティファクトを導入する場合があり、望ましい半周期的なモーションを生成できないことがあります。 本研究では、実際のビデオ用に設計されたアニメーションモデルと芸術的な画像との間のギャップを埋めるために、ツインイメージ合成に基づいたText2Cinemagraphというアルゴリズムが提案されています。この手法の概要は、以下の画像に示されています。 https://arxiv.org/abs/2307.03190 この手法では、ユーザーが提供するテキストプロンプトから2つの画像が生成されます – 一つは芸術的で、もう一つは現実的な画像であり、同じ意味のレイアウトを共有しています。芸術的な画像は最終的な出力のスタイルと外観を表し、現実的な画像は現在のモーション予測モデルがより簡単に処理できる入力として機能します。現実的な画像に対してモーションが予測された後、この情報は芸術的な画像に転送され、最終的なシネマグラフの合成が可能になります。 現実的な画像は最終的な出力として表示されるわけではありませんが、既存のモデルと互換性がありながら芸術的な画像のセマンティックレイアウトに似た中間層として重要な役割を果たします。モーション予測を向上させるために、テキストプロンプトと現実的な画像のセマンティックセグメンテーションからの追加情報が活用されます。 以下に結果が報告されています。 https://arxiv.org/abs/2307.03190 これは、リアルなシネマグラフの生成を自動化するための革新的なAI技術であるText2Cinemagraphの概要でした。もし興味があり、この研究についてさらに詳しく知りたい場合は、以下のリンクをクリックして詳細情報を見つけることができます。

「信頼性の高い医療用AIツールの開発」
「私たちはGoogle Researchとの共同論文をNature Medicineに掲載しましたこの論文では、CoDoC(Complementarity-driven Deferral-to-Clinical Workflow)というAIシステムを提案していますこのシステムは、医療画像の最も正確な解釈について、予測AIツールに頼るべきか、臨床医に委ねるべきかを学習します」

「Hugging Faceにおけるオープンソースのテキスト生成とLLMエコシステム」
テキスト生成と対話技術は古くから存在しています。これらの技術に取り組む上での以前の課題は、推論パラメータと識別的なバイアスを通じてテキストの一貫性と多様性を制御することでした。より一貫性のある出力は創造性が低く、元のトレーニングデータに近く、人間らしさに欠けるものでした。最近の開発により、これらの課題が克服され、使いやすいUIにより、誰もがこれらのモデルを試すことができるようになりました。ChatGPTのようなサービスは、最近GPT-4のような強力なモデルや、LLaMAのようなオープンソースの代替品が一般化するきっかけとなりました。私たちはこれらの技術が長い間存在し、ますます日常の製品に統合されていくと考えています。 この投稿は以下のセクションに分かれています: テキスト生成の概要 ライセンス Hugging FaceエコシステムのLLMサービス用ツール パラメータ効率の良いファインチューニング(PEFT) テキスト生成の概要 テキスト生成モデルは、不完全なテキストを完成させるための目的で訓練されるか、与えられた指示や質問に応じてテキストを生成するために訓練されます。不完全なテキストを完成させるモデルは因果関係言語モデルと呼ばれ、有名な例としてOpenAIのGPT-3やMeta AIのLLaMAがあります。 次に進む前に知っておく必要がある概念はファインチューニングです。これは非常に大きなモデルを取り、このベースモデルに含まれる知識を別のユースケース(下流タスクと呼ばれます)に転送するプロセスです。これらのタスクは指示の形で提供されることがあります。モデルのサイズが大きくなると、事前トレーニングデータに存在しない指示にも一般化できるようになりますが、ファインチューニング中に学習されたものです。 因果関係言語モデルは、人間のフィードバックに基づいた強化学習(RLHF)と呼ばれるプロセスを使って適応されます。この最適化は、テキストの自然さと一貫性に関して行われますが、回答の妥当性に関しては行われません。RLHFの仕組みの詳細については、このブログ投稿の範囲外ですが、こちらでより詳しい情報を見つけることができます。 例えば、GPT-3は因果関係言語のベースモデルですが、ChatGPTのバックエンドのモデル(GPTシリーズのモデルのUI)は、会話や指示から成るプロンプトでRLHFを用いてファインチューニングされます。これらのモデル間には重要な違いがあります。 Hugging Face Hubでは、因果関係言語モデルと指示にファインチューニングされた因果関係言語モデルの両方を見つけることができます(このブログ投稿で後でリンクを提供します)。LLaMAは最初のオープンソースLLMの1つであり、クローズドソースのモデルと同等以上の性能を発揮しました。Togetherに率いられた研究グループがLLaMAのデータセットの再現であるRed Pajamaを作成し、LLMおよび指示にファインチューニングされたモデルを訓練しました。詳細についてはこちらをご覧ください。また、Hugging Face Hubでモデルのチェックポイントを見つけることができます。このブログ投稿が書かれた時点では、オープンソースのライセンスを持つ最大の因果関係言語モデルは、MosaicMLのMPT-30B、SalesforceのXGen、TII UAEのFalconの3つです。 テキスト生成モデルの2番目のタイプは、一般的にテキスト対テキスト生成モデルと呼ばれます。これらのモデルは、質問と回答または指示と応答などのテキストのペアで訓練されます。最も人気のあるものはT5とBARTです(ただし、現時点では最先端ではありません)。Googleは最近、FLAN-T5シリーズのモデルをリリースしました。FLANは指示にファインチューニングするために開発された最新の技術であり、FLAN-T5はFLANを使用してファインチューニングされたT5です。現時点では、FLAN-T5シリーズのモデルが最先端であり、オープンソースでHugging Face Hubで利用可能です。入力と出力の形式は似ているかもしれませんが、これらは指示にファインチューニングされた因果関係言語モデルとは異なります。以下は、これらのモデルがどのように機能するかのイラストです。 より多様なオープンソースのテキスト生成モデルを持つことで、企業はデータをプライベートに保ち、ドメインに応じてモデルを適応させ、有料のクローズドAPIに頼る代わりに推論のコストを削減することができます。Hugging…
ハギングフェイスTGIを使用した大規模言語モデルの展開
大型言語モデル(LLM)は、ほぼ毎週新しいものがリリースされることで人気が高まり続けていますこれらのモデルの数が増えるにつれ、ホストする方法の選択肢も増えています私の…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.