Learn more about Search Results 15 - Page 306

- You may be interested
- 「トルコ地震ツイートに対する感情分析」
- ビッグデータのための階層的クラスタリン...
- GLM-130B:オープンなバイリンガル事前訓...
- 「7/8から13/8までの週のトップ重要なコン...
- データ分析におけるサンプリング技術
- このAI論文は、MITが化学研究のために深層...
- このAIペーパーは、さまざまなタスクでCha...
- MITとCUHKの研究者たちは、LLM(Long Cont...
- Sudowriteのレビュー:AIが人間らしい小説...
- DataFrameを効率的に操作するためのloc Pa...
- 「Inside LlaVA GPT-4Vのオープンソースの...
- カスタム分類モデルでの予測の品質を向上...
- このAIニュースレターは、あなたが必要と...
- 「リトリーバル付き生成(RAG)の詳細」
- 「衛星画像のための基礎モデル」

新たな能力が明らかに:GPT-4のような成熟したAIのみが自己改善できるのか?言語モデルの自律的成長の影響を探る
研究者たちは、AlphaGo Zeroと同様に、明確に定義されたルールで競争的なゲームに反復的に参加することによってAIエージェントが自己発展する場合、多くの大規模言語モデル(LLM)が人間の関与がほとんどない交渉ゲームでお互いを高め合う可能性があるかどうかを調査しています。この研究の結果は、遠い影響を与えるでしょう。エージェントが独立に進歩できる場合、少数の人間の注釈で強力なエージェントを構築することができるため、今日のデータに飢えたLLMトレーニングに対して対照的です。それはまた、人間の監視がほとんどない強力なエージェントを示唆しており、問題があります。この研究では、エジンバラ大学とAIアレン研究所の研究者が、顧客と売り手の2つの言語モデルを招待して購入の交渉を行うようにしています。 図1:交渉ゲームの設定。彼らは2つのLLMエージェントを招待して、値切りのゲームで売り手と買い手をプレイさせます。彼らの目標は、より高い値段で製品を販売または購入することです。彼らは第三のLLMであるAI批評家に、ラウンド後に向上させたいプレイヤーを指定してもらいます。その後、批判に基づいて交渉戦術を調整するようにプレイヤーに促します。これを数ラウンド繰り返すことで、モデルがどんどん上達するかどうかを確認します。 顧客は製品の価格を下げたいと思っていますが、売り手はより高い価格で販売するように求められています(図1)。彼らは第三の言語モデルに批評家の役割を担ってもらい、取引が成立した後にプレイヤーにコメントを提供させます。次に、批評家LLMからのAI入力を利用して、再度ゲームをプレイし、プレイヤーにアプローチを改善するように促します。彼らは交渉ゲームを選んだ理由は、明確に定義されたルールと、戦術的な交渉のための特定の数量化目標(より低い/高い契約価格)があるためです。ゲームは最初は単純に見えますが、モデルは次の能力を持っている必要があります。 交渉ゲームのテキストルールを明確に理解し、厳密に遵守すること。 批評家LLMによって提供されるテキストフィードバックに対応し、反復的に改善すること。 長期的にストラテジーとフィードバックを反映し、複数のラウンドで改善すること。 彼らの実験では、モデルget-3.5-turbo、get-4、およびClaude-v1.3のみが交渉ルールと戦略を理解し、AIの指示に適切に合致している必要があるという要件を満たしています。その結果、彼らが考慮したモデルすべてがこれらの能力を示さなかったことが示されています(図2)。初めに、彼らはボードゲームやテキストベースのロールプレイングゲームなど、より複雑なテキストゲームもテストしましたが、エージェントがルールを理解して遵守することがより困難であることが判明しました。彼らの方法はICL-AIF(AIフィードバックからのコンテキスト学習)として知られています。 図2:私たちのゲームで必要な能力に基づいて、モデルは複数の階層に分けられます(C2-交渉、C3-AIフィードバック、C4-継続的な改善)。私たちの研究は、gpt-4やclaude-v1.3などの堅牢で適切に合致したモデルだけが反復的なAI入力から利益を得て、常に発展することができることを明らかにしています。 彼らは、AI批評家のコメントと前回の対話履歴ラウンドをコンテキストに応じたデモンストレーションとして利用しています。これにより、プレイヤーの前回の実際の開発と批評家の変更アイデアが、次のラウンドの交渉のためのフューショットキューに変換されます。2つの理由から、彼らはコンテキストでの学習を使用しています:(1)強化学習を用いた大規模な言語モデルの微調整は、高額であるため、(2)コンテキストでの学習は、勾配降下に密接に関連していることが最近示されたため、モデルの微調整を行う場合には、彼らが引き出す結論がかなり一般的になることが期待されます(資源が許される場合)。 人間からのフィードバックによる強化学習(RLHF)の報酬は通常スカラーですが、ICL-AIFでは、フィードバックが自然言語で提供されます。これは、2つのアプローチの注目すべき違いです。各ラウンド後に人間の相互作用に依存する代わりに、よりスケーラブルでモデルの進歩に役立つAIのフィードバックを検討しています。 異なる責任を負うときにフィードバックを与えられた場合、モデルは異なる反応を示します。バイヤー役のモデルを改善することは、ベンダー役のモデルよりも難しい場合があります。過去の知識とオンライン反復的なAIフィードバックを利用して、get-4のような強力なエージェントが常に意味のある開発を続けることができるとしても、何かをより高く売る(またはより少ないお金で何かを購入する)ことは、全く取引が成立しないリスクがあります。彼らはまた、モデルがより簡潔であるがより綿密(そして最終的にはより成功する)交渉に従事できることを証明しています。全体的に、彼らは自分たちの仕事がAIフィードバックのゲーム環境での言語モデルの交渉を向上させる重要な一歩になると期待しています。コードはGitHubで利用可能です。

エンジニアリングリーダーは何を気にしているのか?
私たちのエンジニアリングリーダーズフォーラム ラウンドテーブルのまとめと、VPたちがAI、ChatGPT、リモートワーク、DORAメトリックス、およびRIFについて考えていること

H1Bビザはデータ分析の洞察に基づいて承認されますか?
はじめに H1Bビザプログラムは、優れた人材が世界中からアメリカに専門知識をもたらすための門戸を開きます。毎年、このプログラムを通じて数千人の才能ある専門家がアメリカに入国し、様々な産業に貢献し、革新を推進しています。外国労働認証局(OFLC)のH1Bビザデータの世界にダイブして、その数字の裏にあるストーリーを探ってみましょう。この記事では、H1Bビザデータの分析を行い、データから知見や興味深いストーリーを得ます。フィーチャーエンジニアリングを通じて、外部ソースから追加情報をデータセットに組み込みます。データラングリングを用いて、データを丁寧に整理して、より理解しやすく分析することができます。最後に、データの可視化によって、2014年から2016年の間におけるアメリカの熟練労働者に関する魅力的なトレンドや未知の知見が明らかになります。 外国労働認証局(OFLC)から提供されたH1Bビザデータを探索し、高度な外国人労働者をアメリカに引き付ける上での重要性を理解する。 データクリーニング、フィーチャーエンジニアリング、データ変換技術などの前処理プロセスについて学ぶ。 H1Bビザの申請の受理率や拒否率を調べ、それらが影響を与える可能性がある。 データの可視化技術に慣れて、効果的な発表やコミュニケーションを行うために。 注:🔗この分析の完全なコードとデータセットは、Kaggle上で公開されています。プロセスや分析の背後にあるコードを探索するには以下のリンクをご覧ください。H1B Analysis on Kaggle この記事は、Data Science Blogathonの一環として公開されました。 H1Bビザとは何ですか? H1Bビザプログラムは、様々な産業において専門的なポジションを埋めるために、優秀な外国人労働者をアメリカに引き付けるためのアメリカの移民政策の重要な要素です。スキル不足を解消し、革新を促進し、経済成長を牽引しています。 H1Bビザを取得するには、以下の重要なステップを踏まなければなりません。 ビザをスポンサーするアメリカの雇用主を見つける。 雇用主が外国人労働者のH1B申請を米国移民局(USCIS)に提出する。 年次枠に制限があり、申請数が受け入れ可能な枠を超えた場合は、抽選が行われる。 選択された場合、USCISは申請の資格とコンプライアンスを審査する。 承認された場合、外国人労働者はH1Bビザを取得し、米国のスポンサー雇用主で働くことができる。 このプロセスには、学士号または同等の資格を持つことなどの特定の要件を満たす必要があり、支配的な賃金決定や雇用主-従業員関係の文書化などの追加の考慮事項を乗り越える必要があります。コンプライアンスと徹底的な準備が、成功したH1Bビザ申請には不可欠です。 データセット 外国労働認証局(OFLC)が提供する2014年、2015年、2016年の結合データセットには、ケース番号、ケースステータス、雇用主名、雇用主都市、雇用主州、職名、SOCコード、SOC名、賃金レート、賃金単位、支配的な賃金、支配的な賃金源、年などのカラムが含まれます。…

ChatGPTのデジタル商品をオンラインで販売するプロンプト
ChatGPTは、オンラインでデジタル製品を販売して収益を上げたい人にとって、ありがたい存在です

CapPaに会ってください:DeepMindの画像キャプション戦略は、ビジョンプレトレーニングを革新し、スケーラビリティと学習性能でCLIPに匹敵しています
「Image Captioners Are Scalable Vision Learners Too」という最近の論文は、CapPaと呼ばれる興味深い手法を提示しています。CapPaは、画像キャプションを競争力のある事前学習戦略として確立することを目的としており、DeepMindの研究チームによって執筆されたこの論文は、Contrastive Language Image Pretraining(CLIP)の驚異的な性能に匹敵する可能性を持つと同時に、簡単さ、拡張性、効率性を提供することを強調しています。 研究者たちは、Capと広く普及しているCLIPアプローチを比較し、事前学習コンピュータ、モデル容量、トレーニングデータを慎重に一致させ、公平な評価を確保しました。研究者たちは、Capのビジョンバックボーンが、少数派分類、キャプション、光学式文字認識(OCR)、視覚的問い合わせ(VQA)を含むいくつかのタスクでCLIPモデルを上回ったことがわかりました。さらに、大量のラベル付きトレーニングデータを使用した分類タスクに移行する際、CapのビジョンバックボーンはCLIPと同等の性能を発揮し、マルチモーダルなダウンストリームタスクにおける潜在的な優位性を示しています。 さらに、研究者たちは、Capの性能をさらに向上させるために、CapPa事前学習手順を導入しました。この手順は、自己回帰予測(Cap)と並列予測(Pa)を組み合わせたものであり、画像理解に強いVision Transformer(ViT)をビジョンエンコーダーとして利用しました。画像キャプションを予測するために、研究者たちは、標準的なTransformerデコーダーアーキテクチャを使用し、ViTエンコードされたシーケンスをデコードプロセスに効果的に使用するために、クロスアテンションを組み込みました。 研究者たちは、訓練段階でモデルを自己回帰的にのみ訓練するのではなく、モデルがすべてのキャプショントークンを独立して同時に予測する並列予測アプローチを採用しました。これにより、デコーダーは、並列でトークン全体にアクセスできるため、予測精度を向上させるために、画像情報に強く依存できます。この戦略により、デコーダーは、画像が提供する豊富な視覚的文脈を活用することができます。 研究者たちは、画像分類、キャプション、OCR、VQAを含むさまざまなダウンストリームタスクにおけるCapPaの性能を、従来のCapおよび最先端のCLIPアプローチと比較するための研究を行いました。その結果、CapPaはほぼすべてのタスクでCapを上回り、CLIP*と同じバッチサイズで訓練された場合、CapPaは同等または優れた性能を発揮しました。さらに、CapPaは強力なゼロショット機能を備え、見知らぬタスクにも効果的な汎化が可能であり、スケーリングの可能性があります。 全体的に、この論文で提示された作業は、画像キャプションを競争力のあるビジョンバックボーンの事前学習戦略として確立することを示しています。CapPaの高品質な結果をダウンストリームタスクにおいて実現することにより、研究チームは、ビジョンエンコーダーの事前トレーニングタスクとしてのキャプションの探索を促進することを望んでいます。その簡単さ、拡張性、効率性により、CapPaは、ビジョンベースのモデルを進化させ、マルチモーダル学習の境界を押し広げるための興味深い可能性を開拓しています。
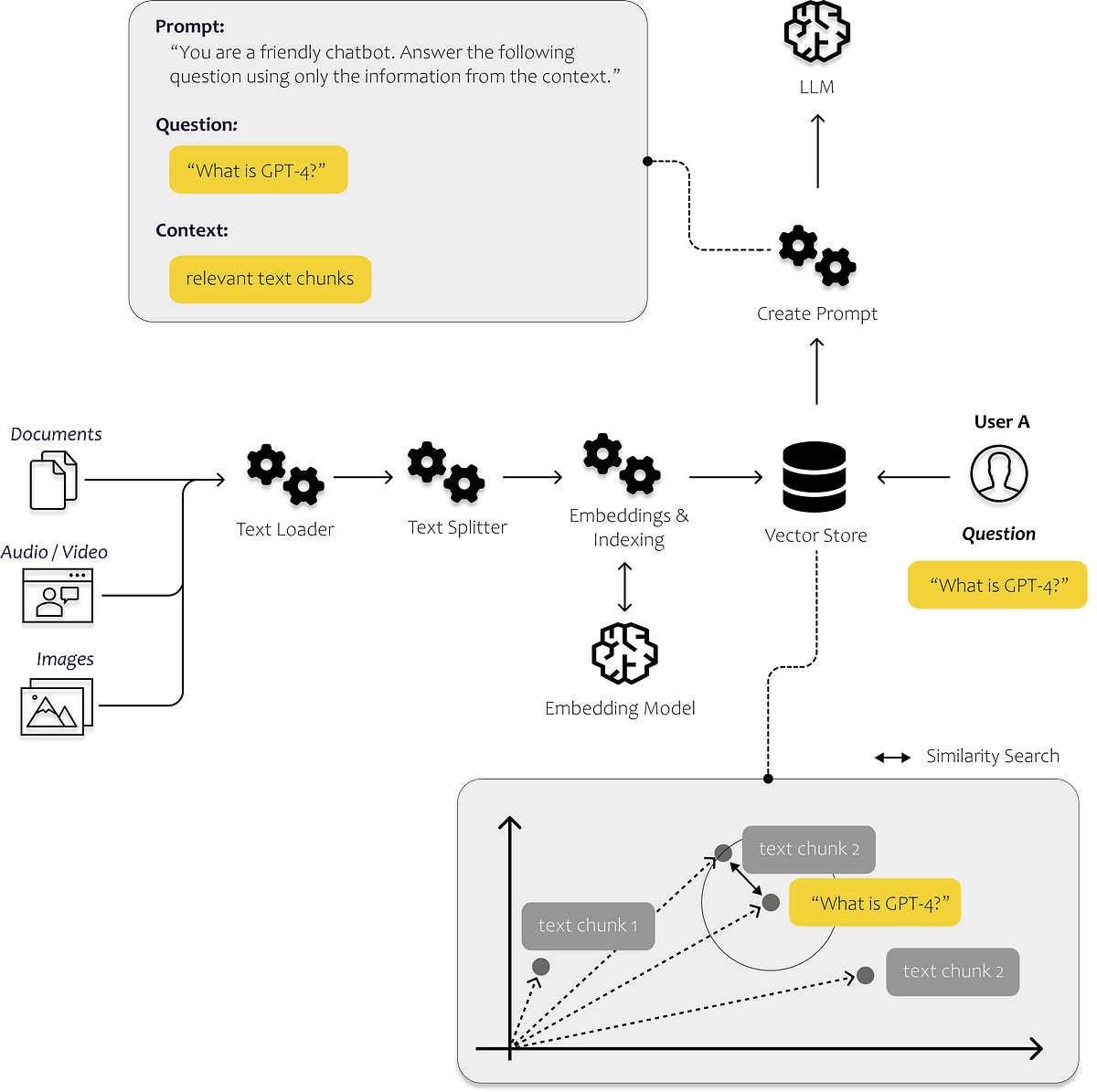
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...

DeepMindの研究者たちは、任意のポイントを追跡するための新しいAIモデルであるTAPIRをオープンソース化しましたこのモデルは、ビデオシーケンス内のクエリポイントを効果的に追跡します
コンピュータビジョンは、人工知能の最も人気のある分野の1つです。コンピュータビジョンを使用したモデルは、デジタル画像、動画、またはその他の視覚的入力など、さまざまな種類のメディアから有意義な情報を導き出すことができます。それは、機械が視覚情報を知覚・理解し、その詳細に基づいて行動する方法を教えるものです。新しいモデルであるTracking Any Point with per-frame Initialization and Temporal Refinement(TAPIR)の導入により、コンピュータビジョンは大きく前進しました。TAPIRは、ビデオシーケンスで特定の関心点を効果的に追跡することを目的として設計されました。 TAPIRモデルの背後にあるアルゴリズムは、Google DeepMind、VGG、エンジニアリングサイエンス学科、そしてオックスフォード大学の研究者チームによって開発されました。TAPIRモデルのアルゴリズムは、2つのステージ、すなわちマッチングステージとリファインメントステージから構成されています。マッチングステージでは、TAPIRモデルは各ビデオシーケンスフレームを個別に分析し、クエリポイントに適した候補点マッチを見つけます。このステップは、各フレームでクエリポイントの最も関連性が高い点を特定することを目的としており、TAPIRモデルがビデオ全体でクエリポイントの移動を追跡できるようにするため、フレームごとにこの手順を実行します。 候補点マッチが特定されるマッチングステージには、リファインメントステージの使用が続きます。このステージでは、TAPIRモデルは、局所的相関に基づいて軌跡(クエリポイントがたどるパス)とクエリ特徴を更新し、各フレームの周囲の情報を考慮してクエリポイントの追跡の精度と正確性を向上させます。リファインメントステージにより、局所的相関を統合することで、モデルのクエリポイントの動きを正確に追跡し、ビデオシーケンスの変動に対応する能力が向上します。 TAPIRモデルの評価には、ビデオトラッキングタスクの標準化された評価データセットであるTAP-Vidベンチマークが使用されました。その結果、TAPIRモデルは、ベースライン技術よりも明らかに優れた性能を発揮しました。性能改善は、平均ジャッカード(AJ)という指標を用いて測定され、DAVIS(Densely Annotated VIdeo Segmentation)ベンチマークにおいて、TAPIRモデルは他の手法に比べてAJで約20%の絶対的な改善を達成したことが示されました。 モデルは、長いビデオシーケンスでの高速な並列推論を容易にするように設計されており、複数のフレームを同時に処理できるため、トラッキングタスクの効率を向上させます。チームは、モデルをライブで適用できるように設計し、新しいビデオフレームが追加されるたびにポイントを処理・追跡できるようにしています。256×256ビデオで256ポイントを約40フレーム/秒の速度で追跡でき、解像度の高い映画を処理できるように拡張することもできます。 チームは、ユーザーがインストールせずにTAPIRを試すことができる2つのオンラインGoogle Colabデモを提供しています。最初のColabデモでは、ユーザーが自分のビデオでモデルを実行し、モデルのパフォーマンスをテストして観察するインタラクティブな体験を提供します。2番目のデモでは、オンラインでTAPIRを実行することに焦点を当てています。また、提供されたコードベースをクローンし、モダンなGPUで自分自身のWebカメラのポイントを追跡することによって、ユーザーはTAPIRをライブで実行することができます。

機械学習によるストレス検出の洞察を開示
イントロダクション ストレスとは、身体や心が要求や挑戦的な状況に対して自然に反応することです。外部の圧力や内部の思考や感情に対する身体の反応です。仕事に関するプレッシャーや財政的な困難、人間関係の問題、健康上の問題、または重要な人生の出来事など、様々な要因によってストレスが引き起こされることがあります。データサイエンスと機械学習によるストレス検知インサイトは、個人や集団のストレスレベルを予測することを目的としています。生理学的な測定、行動データ、環境要因などの様々なデータソースを分析することで、予測モデルはストレスに関連するパターンやリスク要因を特定することができます。 この予防的アプローチにより、タイムリーな介入と適切なサポートが可能になります。ストレス予測は、健康管理において早期発見と個別化介入、職場環境の最適化に役立ちます。また、公衆衛生プログラムや政策決定にも貢献します。ストレスを予測する能力により、これらのモデルは個人やコミュニティの健康増進と回復力の向上に貢献する貴重な情報を提供します。 この記事は、データサイエンスブログマラソンの一部として公開されました。 機械学習を用いたストレス検知の概要 機械学習を用いたストレス検知は、データの収集、クリーニング、前処理を含みます。特徴量エンジニアリング技術を適用して、ストレスに関連するパターンを捉えることができる意味のある情報を抽出したり、新しい特徴を作成したりすることができます。これには、統計的な測定、周波数領域解析、または時間系列解析などが含まれ、ストレスの生理学的または行動的指標を捉えることができます。関連する特徴量を抽出またはエンジニアリングすることで、パフォーマンスを向上させることができます。 研究者は、ロジスティック回帰、SVM、決定木、ランダムフォレスト、またはニューラルネットワークなどの機械学習モデルを、ストレスレベルを分類するためのラベル付きデータを使用してトレーニングします。彼らは、正解率、適合率、再現率、F1スコアなどの指標を使用してモデルのパフォーマンスを評価します。トレーニングされたモデルを実世界のアプリケーションに統合することで、リアルタイムのストレス監視が可能になります。継続的なモニタリング、更新、およびユーザーフィードバックは、精度向上に重要です。 ストレスに関連する個人情報の扱いには、倫理的な問題やプライバシーの懸念を考慮することが重要です。個人のプライバシーや権利を保護するために、適切なインフォームドコンセント、データの匿名化、セキュアなデータストレージ手順に従う必要があります。倫理的な考慮事項、プライバシー、およびデータセキュリティは、全体のプロセスにおいて重要です。機械学習に基づくストレス検知は、早期介入、個別化ストレス管理、および健康増進に役立ちます。 データの説明 「ストレス」データセットには、ストレスレベルに関する情報が含まれています。データセットの特定の構造や列を持たない場合でも、パーセンタイルのためのデータ説明の一般的な概要を提供できます。 データセットには、年齢、血圧、心拍数、またはスケールで測定されたストレスレベルなど、数量的な測定を表す数値変数が含まれる場合があります。また、性別、職業カテゴリ、または異なるカテゴリ(低、VoAGI、高)に分類されたストレスレベルなど、定性的な特徴を表すカテゴリカル変数も含まれる場合があります。 # Array import numpy as np # Dataframe import pandas as pd #Visualization…
ランダムフォレストと欠損値
オンラインで見つかる過剰にクリーンされたデータセット以外に、欠損値はどこにでもあります実際、データセットが複雑で大きいほど、欠損値がより多く存在する可能性があります...

AIは自己を食べるのか?このAI論文では、モデルの崩壊と呼ばれる現象が紹介されており、モデルが時間の経過とともに起こり得ないイベントを忘れ始める退行的な学習プロセスを指します
安定した拡散により、言葉だけで画像を作ることができます。GPT-2、GPT-3(.5)、およびGPT-4は、多くの言語の課題で驚異的なパフォーマンスを発揮しました。この種の言語モデルについての一般の知識は、ChatGPTを通じて最初に公開されました。大規模言語モデル(LLM)は恒久的なものとして確立され、オンラインテキストおよび画像エコシステム全体を大幅に変えることが期待されています。大量のWebスクレイピングデータからのトレーニングは、十分な考慮が与えられた場合にのみ維持できます。実際に、LLMが生成したコンテンツをインターネットから収集したデータに含めることで、システムとの真の人間の相互作用に関する取得されたデータの価値は高まるでしょう。 英国とカナダの研究者は、モデルの崩壊が、あるモデルが他のモデルによって生成されたデータから学習すると発生することを発見しました。この退化的なプロセスにより、モデルは時間の経過とともに真の基盤となるデータ分布の追跡を失い、変化がない場合でも、誤って解釈されるようになります。彼らは、ガウス混合モデル、変分オートエンコーダー、および大規模言語モデルの文脈でモデルの失敗の事例を提供することによって、この現象を説明しています。彼らは、獲得された行動が世代を超えて推定値に収束し、この真の分布に関する知識の喪失が尾の消失から始まる方法を示し、この結果が機能推定エラーがないほぼ最適な状況でも不可避であることを示しています。 研究者たちは、モデルの崩壊の大きな影響について述べ、基盤となる分布の尾の場所を特定するために生データにアクセスすることがどれだけ重要かを指摘しています。したがって、LLMとの人間の相互作用に関するデータがインターネット上で大規模に投稿される場合、データ収集を汚染し、トレーニングに使用することがますます役立つようになるでしょう。 モデル崩壊とは何ですか? 学習済みの生成モデルの一世代が次の世代に崩壊するとき、後者は汚染されたデータでトレーニングされるため、世界を誤解することになり、破綻的な忘却過程とは対照的に、このアプローチでは、時間を通じて多くのモデルを考慮することを考慮しています。モデルは以前に学習したデータを忘れないで、彼らのアイデアを強化することで彼らが実際に現実であると認識するものを誤って解釈するようになります。これは、様々な世代を通じて組み合わされた二つの異なる誤り源によって起こるため、過去のモデルから生じるものであり、この特定の誤りメカニズムが最初の世代を超えて生き残る必要があります。 モデル崩壊の原因 モデルの失敗の基本的および二次的な原因は以下の通りです。 最も一般的なエラーは統計的近似の結果であり、有限のサンプルがあると起こりますが、サンプルサイズが無限に近づくにつれて減少します。 関数近似器が十分に表現力がない(または元の分布を超えて過剰に表現力がある場合がある)ために引き起こされる二次的なエラーを機能近似エラーと呼びます。 これらの要因は、モデル崩壊の可能性を悪化または緩和することができます。より良い近似力は、統計的ノイズを増幅または減衰させることができるため、基盤となる分布のより良い近似をもたらす一方で、それを増幅することもできます。 モデル崩壊は、再帰的にトレーニングされた生成モデルすべてで発生すると言われており、すべてのモデル世代に影響を与えます。彼らは実際のデータに適用されると崩壊する基本的な数学モデルを作成することができますが、興味のある値の解析方程式を導くために使用することができます。彼らの目標は、様々なエラータイプの影響を元の分布の最終近似に置く数値を示すことです。 研究者たちは、別の生成モデルからのデータでトレーニングすることによってモデル崩壊が引き起こされることがわかり、分布のシフトが生じるため、モデルがトレーニング問題を誤って解釈するようになると示しています。長期的な学習には、元のデータソースにアクセスし、LLMsによって生成された他のデータを時間をかけて利用する必要があります。LLMsの開発と展開に参加するすべての当事者が、証明問題を解決するために必要なデータを伝達し、共有するためにコミュニティ全体で調整することが1つのアプローチです。技術が広く採用される前にインターネットからクロールされたデータまたは人間によって提供されたデータにアクセスすることができるため、LLMsの後続バージョンをトレーニングすることがますます簡単になる可能性があります。 以下をチェックしてください: 論文と参考記事。 24k+ ML SubReddit、Discordチャンネル、および電子メールニュースレターに参加することを忘れないでください。そこでは、最新のAI研究ニュース、クールなAIプロジェクトなどを共有しています。上記の記事に関する質問がある場合や、何か見落としがあった場合は、お気軽に[email protected]までメールでお問い合わせください。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.