Learn more about Search Results ggplot2 - Page 2

- You may be interested
- LMSYS-Chat-1Mとは、25の最新のLLM(Large...
- 「プライバシーを保護しながらジェネラテ...
- アップステージがSolar-10.7Bを発表:一回...
- 空気圧アクチュエータは、ロボットにチー...
- 『LangChain & Flan-T5 XXL の解除 | ...
- 「3Dガウシアンスプラッティング入門」
- 「AWS 研究者がジェミニを紹介:大規模な...
- AIの進歩を促進するための医療データのラ...
- 「機械学習モデルのログと管理のためのト...
- メタは、商用利用に無料のLLaMA 2をリリー...
- 大規模言語モデルの探索-パート2
- データエンジニアのためのデータモデリング
- MetaのTwitterライバルアプリ「Threads」...
- 『AI規制に関するEUの予備的な合意:ChatG...
- あなたのCopy-Paste ChatGPTカスタムの指...

自己学習のためのデータサイエンスカリキュラム
はじめに データサイエンティストになる予定ですが、どこから始めればいいかわからないですか?心配しないでください、私たちがお手伝いします。この記事では、自己学習のためのデータサイエンスカリキュラム全体と、プロセスを早めるためのリソースとプログラムのリストをカバーします。 このカリキュラムでは、優れたデータサイエンティストになるために必要なツール、トリック、知識の基礎をカバーしています。もし科学と統計について少し知識があるなら、良い位置にいます。これらのことについて初めて知る場合は、まずそれらについて学ぶと役立つかもしれません。そして、既にデータに詳しい場合は、これはクイックな復習になるかもしれません。 覚えておいてください、すべてのプロジェクトでこれらのスキルをすべて使うわけではありません。一部のプロジェクトでは、このリストにない特別なトリックやツールが必要です。しかし、このカリキュラムの内容を十分に理解し、習得すると、ほとんどのデータサイエンスの仕事に対応できるようになります。そして、必要なときに新しいことを学ぶ方法も知っています。 さあ、始めましょう! データサイエンスカリキュラムをなぜフォローするのか? データサイエンスのカリキュラムに従うことは、構造化された効果的な学習には欠かせません。これにより、知識とスキルを習得するための明確なパスが提供され、この分野の広大さに圧倒されることなく学ぶことができます。良いカリキュラムは包括的なカバレッジを保証し、基礎的な概念から高度なテクニックまでを案内します。このステップバイステップのアプローチは、複雑なトピックに深入りする前に、堅固な基盤を築くための基礎となります。 さらに、カリキュラムは実践的な応用を促進します。多くのプログラムにはハンズオンのプロジェクトや演習が含まれており、理論的な知識を実世界のスキルに変換することができます。進捗を体系的に追跡することで、学習の旅においてモチベーションを保ち、集中する助けとなります。 即効的な利点を超えて、カリキュラムに従うことは職業にも役立ちます。データサイエンスの構造化された教育を完了することは、潜在的な雇用主に対してコミットメントと熟練度を示し、仕事の見通しを向上させます。さらに、このアプローチは適応性を育成し、自身のニーズに合わせてペースを調整し、困難なテーマに深入りすることができるようにします。 要するに、データサイエンスのカリキュラムは必須のスキルを身につけるだけでなく、データサイエンスの常に進化する分野で独立して学び続ける能力を養うことも可能です。 自己学習のためのデータサイエンスカリキュラム 以下は、データサイエンスの旅を始める際に探索するための主要な領域の簡略化されたロードマップです: 数学の基礎 多変数微積分:複数の変数の関数、導関数、勾配、ステップ関数、シグモイド関数、コスト関数などを理解する。 線形代数:ベクトル、行列、転置や逆行列などの行列演算、行列式、内積、固有値、固有ベクトルを習得する。 最適化手法:コスト関数、尤度関数、誤差関数などについて学び、勾配降下法(および確率的勾配降下法などの変種)などのアルゴリズムを理解する。 プログラミングの基礎 PythonまたはRを主要な言語として選択する。 Pythonの場合、NumPy、pandas、scikit-learn、TensorFlow、PyTorchなどのライブラリを習得する。 データの基礎 さまざまな形式(CSV、PDF、テキスト)でのデータ操作を学ぶ。 データのクリーニング、補完、スケーリング、インポート、エクスポート、Webスクレイピングのスキルを習得する。 PCAやLDAなどのデータ変換や次元削減の手法を探索する。 確率と統計の基礎…

「Rプログラミング言語を使った統計学入門」
基礎的な概念から高度な技術まで、この記事は包括的なガイドです。Rはオープンソースのツールであり、データ愛好家にデータの探索、分析、可視化を正確に行う能力を与えます。記述統計、確率分布、洗練された回帰モデルに取り組んでいる場合でも、Rの多様性と豊富なパッケージにより、シームレスな統計的探索が容易に行えます。 Rが提供する機能とパッケージを活用して、基礎を学び、複雑な手法を解説し、Rがデータ駆動の世界をより深く理解する手助けとなるような学習の旅に出ましょう。 Rとは何ですか? Rは、統計解析向けに特別に設計された強力なオープンソースのプログラミング言語および環境です。統計学者によって開発され、データの操作、可視化、モデリングにおいて多目的なプラットフォームとして機能します。その広範なパッケージのコレクションにより、Rを使用することで複雑なデータの洞察力を解き明かし、情報に基づいた意思決定を推進することができます。統計学者やデータアナリストにとって頼りになるツールとして、Rはデータの探索と解釈へのアクセス可能なゲートウェイを提供します。 詳しくはこちら:Scratchからデータサイエンスを学ぶための完全なチュートリアル Rプログラミングの基礎 統計解析言語としてのRを使用する前に、Rプログラミングの基本概念に慣れることが重要です。より複雑な解析に取り組む前に、統計計算とデータ操作を駆動するエンジンであるRの基礎を理解することは不可欠です。 インストールとセットアップ Rをコンピュータにインストールすることは必要な最初のステップです。公式ウェブサイト(The R Project for Statistical Computing)からプログラムをインストールおよびダウンロードすることができます。RStudio(Posit)は、Rコーディングをより実用的にするために使用するかもしれない統合開発環境(IDE)です。 Rの環境の理解 Rは、直接コマンドを入力して実行できるインタラクティブな環境を提供します。それはプログラミング言語であり、環境でもあります。IDEまたはコマンドラインインターフェースの2つの方法でRとコミュニケーションを取ることができます。計算、データ分析、可視化などのタスクをすべて実行できます。 ワークスペースと変数 Rでは、セッション中に作成した変数やオブジェクトを現在のワークスペースに保持します。代入演算子('<- ‘または ‘=’)を使用して、変数に値を与えることで変数を作成することができます。論理値、テキスト、数値などを含むデータを変数に格納することができます。 基本構文 Rには学習しやすい直感的な構文があります。関数名の後に括弧で囲まれた引数を続けて書きます。たとえば、何かを印刷するには ‘print()’関数を使用します。 データ構造…

「データサイエンスは難しいのか?現実を知ろう」
過去数年間、熟練なデータサイエンティストへの需要は増加してきましたが、AIによって風景は変わりました。重点はルーチンタスクからより複雑な役割に移りました。最新のデータサイエンスの進歩にしっかりと理解を持つことは、有望なキャリアに欠かせません。データサイエンスは難しいのでしょうか?学習の道は本質的に簡単または難しいものではありませんが、データサイエンスには険しい学習曲線があります。しかし、常に最新の情報にアップデートし続ける意欲を持ち続けることで、課題にもかかわらず、旅はよりスムーズになることがあります。 データサイエンスを学ぶ価値はあるのでしょうか? 企業は主にデータの潜在能力を活用して意思決定を行っています。このタスクはデータサイエンスを通じて貢献された技術的進歩を用いて行われます。それはその分野で優れた能力を持つ専門家によって処理されます。したがって、データサイエンスは、キャリアを選ぶ個人や成長のためにそれを利用する組織にとって有望な機会を提供しています。数多くの課題と連続的な進化のプラットフォームを提供することで、この分野は非常にダイナミックであり、自己のマインドセットと知識を磨くために最適です。データサイエンスの高い価値により、「データサイエンスは難しいのか」という質問は無意味です。 データサイエンスが良いキャリア選択肢なのかどうかを知るために、この記事を読んでください! データサイエンティストはコーディングをするのでしょうか? データサイエンティストは膨大な量のデータを扱います。これらに取り組むためには、プログラミング言語RとPythonの習熟が必要です。そのようなデータの処理には基本的なコーディングの知識が必要です: クリーニング、前処理、データ変換 Matplotlibやggplot2などのPythonとRのライブラリやツールを使ってインサイトを伝えるための支援 統計分析、機械学習、データモデリング データ関連の問題に対するカスタマイズされたソリューションの作成 データの前処理、結果の評価、モデルのトレーニングなどの繰り返しタスク アイデアや仮説の素早いテスト アルゴリズムによるパターンの識別 データサイエンスの多面的な性質 データサイエンスは、多くの分野を包括する広範な分野です: 統計学:確率、回帰分析、仮説検定、実験設計の理解は、正確かつ意味のある分析には重要です。 プログラミングとデータ操作:いくつかのデータ最適化技術や専門ソフトウェアを用いたプログラミング言語の知識 ドメイン知識:産業固有の知識、ビジネスプロセス、適切な質問の提起、関連する特徴の選択、結果の解釈など コミュニケーション:技術的な観点と非技術的な観点の両方と対話し、明確かつ正確に自分自身を理解して伝える能力 この情報は、データの処理、データのコミュニケーション、データの取り扱いに必要な技術的な専門知識の重要性を示しています。産業固有の知識と問題解決能力を持つことで、データサイエンスの効率は何倍にも向上し、個人のビジネスやキャリアに役立ちます。 学習曲線と継続的な学習 データサイエンスは絶えず進化する分野であり、継続的な学習が必要です。初心者の学習曲線は険しいものであり、プログラミング言語の学習に直面する課題があるためです。 では、「データサイエンスは難しいのか?」いいえ、データサイエンスの知識と興味を持った個人にとっては難しくありません。ただし、データサイエンスの分野での定期的かつ急速な進歩は、分野内で最新の情報にアップデートし続ける必要性を増大させています。 例えば、現在の進歩としては、自動機械学習やエッジコンピューティングの導入があります。トップのデータサイエンスのトレンドはTinyML、small…

データサイエンティストやアナリストのための統計の基礎
データサイエンスまたはデータ分析の旅における重要な統計的概念

「データサイエンスの仕事を得る方法?[8つの簡単なステップで解説]」
データサイエンス分野での有望なキャリアは競争が激化しています。多くの候補者が役職を得るために激しく競い合っている中、機会はしばしば適切なスキルと経験を持つ人々に与えられます。データサイエンスの仕事を得るための前提条件や答えは、以下の8つの詳細なステップにあります。 データサイエンスの仕事を得るための8つのステップ 以下の8つのステップに従って、希望するデータサイエンスの仕事を得ることができます。 ステップ1:目標とパスを明確にする データサイエンスのキャリア目標を明確にする キャリアの目標を明確に定義し、経験レベルと専門知識に基づいてデータサイエンスのキャリア目標を明確に定義します。短期目標として、インターンシップや初級職のデータアナリストになることを考えてください。中期目標には、専門家としての知識を持ち、研究論文を発表することが含まれます。長期目標には、トップのデータサイエンティストになること、企業との協力、企業の立ち上げ、大学や学術誌への貢献などが含まれる場合があります。 さまざまなデータサイエンスの役割を調査し、自分の興味とスキルに合ったものを選ぶ さまざまなデータサイエンスの役割を調査し、興味とスキルに合った役割を選択します。データアナリストになる、機械学習をマスターする、自然言語処理に特化する、ビッグデータプロジェクトに取り組む、またはディープラーニングを進めるなどの選択肢があります。 希望する役割に必要なスキルと知識を特定し、学習計画を作成する データサイエンスに入る方法について考えていますか?学習計画を作成しましょう。これには、認定コースへの参加、YouTubeでの無料講義の受講、書籍からの情報収集、他の専門家との協力などが含まれます。さらに、新卒者としてデータアナリストの仕事を得る方法やデータサイエンスの仕事を得る方法についての回答をするために、以下の表にはさまざまなデータサイエンスの役割に必要なスキルと知識が示されています。 役割 スキル 知識 データアナリスト データの操作と可視化、Excel、SQL、データの可視化ライブラリ データのクリーニング、前処理、クエリ、可視化 機械学習 アルゴリズム、ハイパーパラメータの調整、モデルの選択、評価指標、TensorFlow、scikit-learn、PyTorch 教師あり学習と教師なし学習、クラスタリング、回帰、分類、アンサンブル法、ディープラーニングのアーキテクチャ 自然言語処理 NLPライブラリ、フレームワーク、spaCy、NLTK、transformers、分類、エンティティ認識、感情分析、言語モデルの微調整 単語の埋め込み、再帰型ニューラルネットワーク(RNN)と畳み込みニューラルネットワーク(CNN)、テキストの前処理 ビッグデータ 大規模データ処理、分散環境でのストレージと処理…

データサイエンスと統計学の違い
イントロダクション Indeedによるデータサイエンティストの求人数が256%増加したことで、データサイエンスは業界のキーワードとなりました。さまざまな分野でのデータサイエンスの役割の需要の増加により、多くの人々がデータサイエンスの専門学位や研修プログラムを選ぶようになりました。ビジネスや政府はデータを広範に利用して重要な選択や将来の投資や活動の計画を立てています。しかし、データサイエンスでは統計の手法も意思決定に同等に貢献しています。 どちらがより有用か気になりますか?データサイエンス vs 統計を比較してみましょう! さあ、探ってみましょう! データサイエンスとは? データサイエンスは、ビジネスの重要な洞察を得るためのデータの分析です。統計、人工知能、数学、コンピュータサイエンスなど、さまざまな学問分野が組み合わさっており、これらを使用して膨大な量のデータを分析します。データサイエンティストは、なぜ問題が発生したのか、何が予想されるのか、そして何がさらに達成できるのかといった問題に対する解決策を見つけるために自身の知識を活用します。 今日では、多くの産業がデータサイエンスを利用して消費者の傾向やトレンドを予測し、新しい見通しを見つけ出しています。これにより、ビジネスは製品開発や販売に関するよく根拠のある意思決定を行うことができます。データサイエンスはプロセス改善や詐欺検出のための学問分野として機能します。政府もデータサイエンスを利用して公共サービスの効率を向上させています。 統計とは? 統計学はデータの収集と分析によってパターンやトレンドを発見し、バイアスを排除し、意思決定を支援するための数学の応用科学です。統計学はビジネスインテリジェンスの一環であり、商業データの収集と分析、トレンドの提示を含みます。 企業は統計的評価を利用してさまざまな方法で利益を得ることができます。最もパフォーマンスの良い製品ラインを特定したり、売り上げが低い営業担当者を特定したり、収益成長が異なる地域にどのように変動するかを理解したりするために統計的評価を使用することがあります。 予測モデリングは統計分析手法の利用によって恩恵を受けることができます。統計分析ツールは、さまざまな外部イベントが影響を与える可能性がある単純なトレンド予測ではなく、より重要な詳細を表示するために企業がより深く見ることができます。 データサイエンス vs 統計 データサイエンスと統計の主な違いは次の通りです: データサイエンス 統計 科学的な計算手法に基づいています。統計と応用数学を使用してビッグデータから新しい情報を導き出します。 統計学はデータの研究です。統計的関数やアルゴリズムを適用してデータから値を決定します。 データ関連の問題を解決するために適用されます。 統計はデータに基づいて実世界の問題を設計し、構築します。 生データや構造化されたデータから洞察を抽出します。…

PythonとRにおける機械学習アルゴリズムの比較
PythonとRで最も一般的に使用される機械学習アルゴリズムのリストは、初心者エンジニアや愛好家が最もよく使用されるアルゴリズムに慣れるのを支援することを目的としています
Rにおける二元配置分散分析
二元分散分析(Two-way ANOVA)は、二つのカテゴリカル変数が量的連続変数に与える同時効果を評価することができる統計的方法です二元分散分析は…
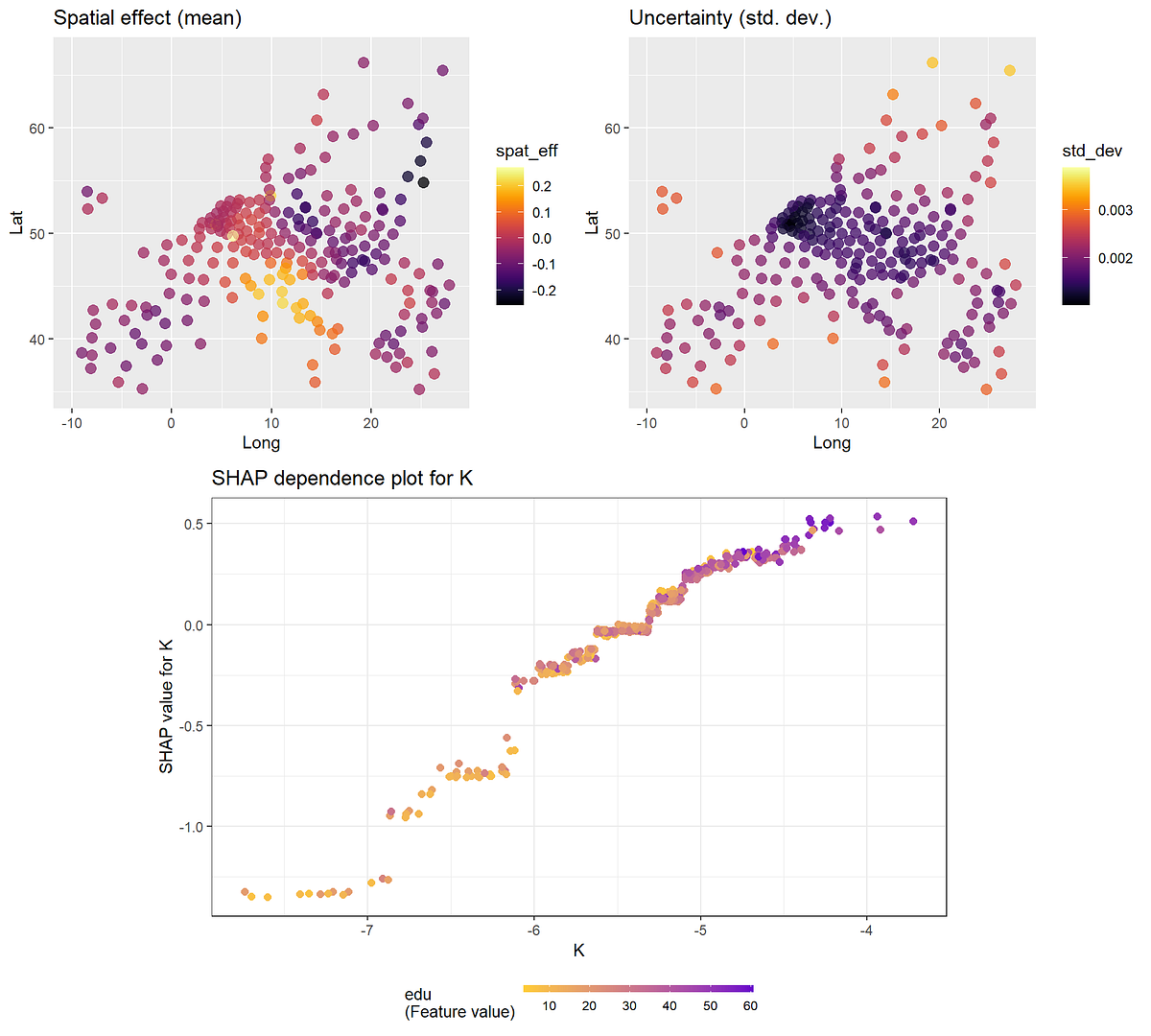
グループ化および空間計量データの混合効果機械学習におけるGPBoost
GPBoostを用いたグループ化されたおよび地域空間計量データの混合効果機械学習 - ヨーロッパのGDPデータを用いたデモ
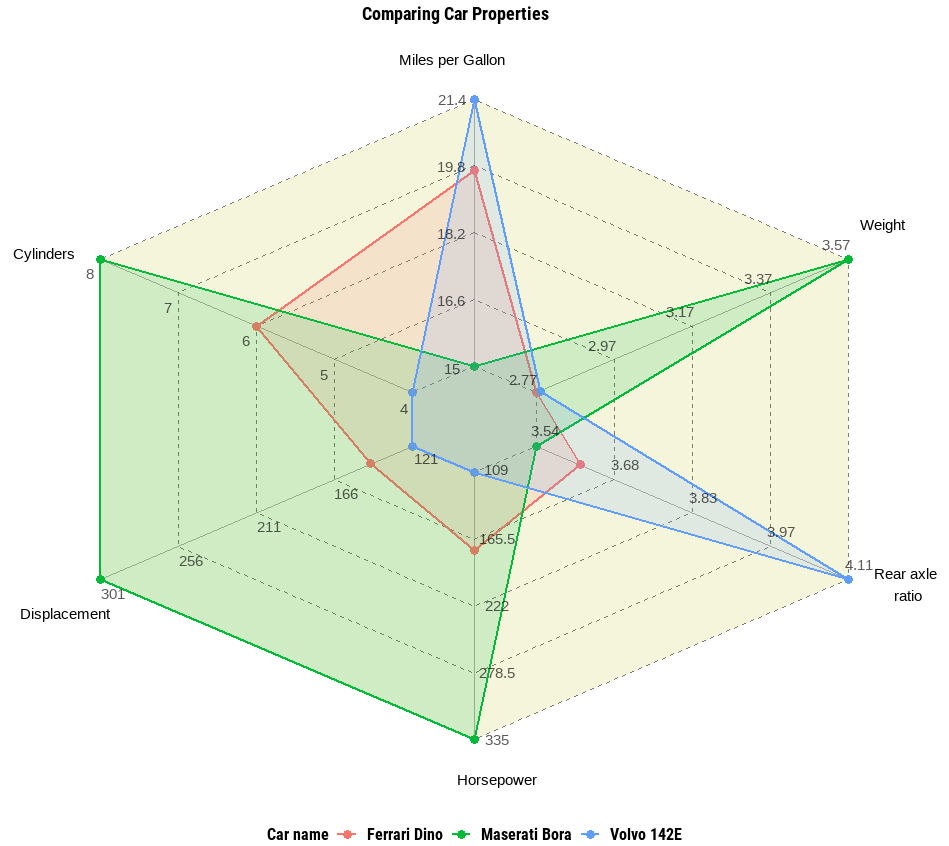
Rのggvancedパッケージを使用したスパイダーチャートと並列チャート
ggplot2パッケージの上に、スパイダーチャートや平行チャートなどの高度な多変数データ可視化を生成するためのパッケージ
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.