Learn more about Search Results Zhu et al - Page 2

- You may be interested
- 「NASAが宇宙探査用に3Dプリントでロケッ...
- Google AIが簡単なエンドツーエンドの拡散...
- ソウルでのオーケストラ指揮者として、ロ...
- 「大数の法則の解明」
- テックとマインドのバランス:メンタルヘ...
- MLモデルの最適化とデバッグにSHAP値を使...
- 「この新しいAI研究は、事前学習されたタ...
- 「MITとハーバードの研究者は、脳内の生物...
- 究極のGFNサーズデー:41の新しいゲームに...
- 「LangChainとChatGPTを使用してPythonコ...
- SlackメッセージのLLM微調整
- 🤗 ViTをVertex AIに展開する
- データ、アーキテクチャ、または損失:マ...
- クライテリオンを使用したRustコンパイラ...
- TDSベストオブ2023:ChatGPTとLLMについて

私たちはどのように大規模な言語モデルをストリーミングアプリケーションで効率的に展開できるのでしょうか?このAI論文では、無限のシーケンス長のためのStreamingLLMフレームワークを紹介しています
大きな言語モデル(LLM)は、コード補完、質問応答、文書要約、対話システムなど自然言語処理アプリケーションのパワーとして、ますます使用されています。事前にトレーニングされたLLMは、正確かつ迅速に拡張シーケンス作成を行う必要があり、その全ての潜在能力を発揮するためには可能な限り大量のシーケンスを処理できる必要があります。例えば、最近の日中のチャットのコンテンツを信頼性を持って編集する理想的なチャットボットヘルパーです。4KのLlama-2など、事前学習されたものよりも大きなシーケンス長に一般化することは、LLMにとって非常に困難です。事前トレーニング中のアテンションウィンドウのため、LLMは制約されます。 長い入力に対してこのウィンドウの大きさを拡張し、トレーニングと推論の効果を高めるための取り組みが行われていますが、許容されるシーケンス長はまだ見直す必要があり、永続的な展開を妨げています。MIT、Meta AI、カーネギーメロン大学の研究者らは、この研究で最初にLLMストリーミングアプリケーションのアイデアを検討し、次の質問を提起しています:LLMを無限の入力ストリームに使用する際には、2つの主要な問題が浮かび上がります: 1. TransformerベースのLLMは、デコーディングステージ中にすべての前のトークンのKeyとValueの状態(KV)をキャッシュします(図1(a)参照)。これは、過剰なメモリ使用量とデコードの遅延の増加を引き起こす可能性があります。 2. シーケンスの期間が事前学習中のアテンションウィンドウサイズを超えると、既存のモデルのパフォーマンスが低下します。 図1は、StreamingLLMと以前の技術を比較しています。トークンT(T>>L)は、長さLのテキストで事前トレーニングされた言語モデルによって予測されます。(a)密なアテンションはキャッシュ容量が上昇し、時間の複雑さがO(T^2)になります。テキストの長さが事前トレーニングのテキスト長を超えるとパフォーマンスが低下します。(b)ウィンドウアテンションは、キャッシュ中で最新のLトークンのKVを保存します。推論ではパフォーマンスが良いですが、最初のトークンのキーと値が削除されると急速に悪化します。新しいトークンごとに、(c)スライディングウィンドウとリコンピューテーションは、最新のLトークンを使用してKV状態を再構築します。長いテキストの処理には優れていますが、O(T L^2)の計算量と文脈の再計算における二次関数のアテンションのため、非常に遅いです。(d)「ステディなアテンションの計算のため、StreamingLLMは最新のトークンとともに少数の初期トークンをアテンションシンクとして保持します。長いテキストに対して効果的かつ一貫して機能します。Llama-2-13Bモデルは、PG-19テストセットの最初の本(65Kトークン)におけるPerplexityを計算するために使用されます。 ウィンドウアテンションは、最新のトークンのKV状態の固定サイズのスライディングウィンドウを保持する明確な戦略です(図1b)。最初のトークンのKVを排除するだけで、シーケンス長がキャッシュ容量を超えると、モデルは崩壊します。キャッシュが最初に一杯になった後も、一貫したメモリ使用量とデコード性能を保証します。さらなる戦略として、再計算を行うスライディングウィンドウ(図1c)があります。このテクニックは、ウィンドウ内の二次関数のアテンション計算により、非常に遅くなりますが、パフォーマンスは良好です。これは、実世界のストリーミングアプリケーションには適していません。 ウィンドウアテンションの失敗を説明するための自己回帰LLMの興味深い現象を彼らは発見しました。言語モデリングのタスクと関連性に関係なく、初期トークンに驚くほど高いアテンションスコアが割り当てられています。これらのトークンは「アテンションシンク」と呼ばれ、意味的な価値はほとんどありませんが、重要なアテンションスコアを受け取ります。関連するトークンすべてにおいてアテンションスコアが1になる必要があるソフトマックス処理が原因とされています。そのため、現在のクエリが多くの以前のトークンと良い一致がない場合でも、モデルはこれらの余分なアテンション値を一に加える必要があります。 初期トークンは、シンプルな理由で注意の溜め場として使用されます: 自己回帰型言語モデリングの性質により、実質的にすべての後続トークンに対して可視性があり、トレーニングが容易です。前述の発見に基づいて、ストリーミングLLMという直感的で効果的なアーキテクチャを提案しています。これにより、有限な注意ウィンドウで準備されたLLMが、細かな調整なしで無期限のテキストに対応できるようになります。注意の消耗が高いため、StreamingLLMはこの特性を活用して注目度の分布を適度に維持します。StreamingLLMは、スライディングウィンドウのキーバリューと初期トークンの注目計算とモデルの安定性を維持するために使用されます (初期トークンはわずか4つだけ必要です)。 Llama-2-B、MPT-B、Falcon-B、およびPythiaBのようなモデルは、StreamingLLMの助けを借りて4百万トークンを正確に表現できるでしょう、さらに多くの可能性もあります。StreamingLLMは、再計算を伴うスライディングウィンドウとの比較で最大22.2倍の高速化を実現し、LLMのストリーミング使用を実現します。最後に、言語モデルはストリーミング展開に必要な注目の溜め場トークンを単一にすることが事前学習で可能であることを示しています。トレーニングサンプルの開始時に、選択した注目の溜め場を追加の学習可能なトークンとして実装することを提案しています。この単一の溜め場トークンの導入により、1億6000万パラメータからゼロから言語モデルを事前学習することで、ストリーミングインスタンスにおけるモデルのパフォーマンスを維持できます。これは、同じパフォーマンスレベルを維持するために複数の初期トークンを溜め場として再導入する必要があるバニラモデルとは対照的です。

「人物再識別入門」
「人物再識別」は、異なる非重複カメラビューに現れる個人を識別するプロセスですこのプロセスは、顔認識に頼らずに、服装を考慮します...

「なんでもセグメント:任意のオブジェクトのセグメンテーションを促す」
今日の論文解説はビジュアルになります!私たちはMetaのAI研究チームによる論文「Segment Anything」を分析しますこの論文は研究コミュニティだけでなく、あらゆる分野でも話題となりました...
「機械学習のテクニック、ChatGPTとの学習、そして他の最近の必読記事」
8月も終わりに近づき、多くの読者の皆さんは学校へ戻る準備をしていることでしょう(大学であれ、ブートキャンプであれ、オンラインであれ)一方で他の方々は、夏のゆっくりしたスケジュールから抜け出している最中かもしれません…

「量子計算の優位性を確実に示すための新しいプロトコル」
このプロトコルは中間回路の測定と暗号技術に依存しています

「LoRAアダプターにダイブ」
「大規模言語モデル(LLM)は世界中で大流行しています過去の1年間では、彼らができることにおいて莫大な進歩を目撃してきましたそれまではかなり限定的な用途にとどまっていましたが、今では…」

「ダークウェブを照らす」
「ダークウェブがどのように運営され続けているのか、そしてなぜ法執行機関がそれをすぐに閉鎖しないのか」

関数呼び出し:GPTチャットボットを何にでも統合する
OpenAIのGPTの新しい関数呼び出し機能を探索し、チャットボットが外部ツールやAPIと対話できるようにしますAIパワーを活用したアプリケーションの可能性を解き放つ

Pythonコード生成のためのLlama-2 7Bモデルのファインチューニング
約2週間前、生成AIの世界はMeta社が新しいLlama-2 AIモデルをリリースしたことによって驚かされましたその前身であるLlama-1は、LLM産業において画期的な存在であり、…
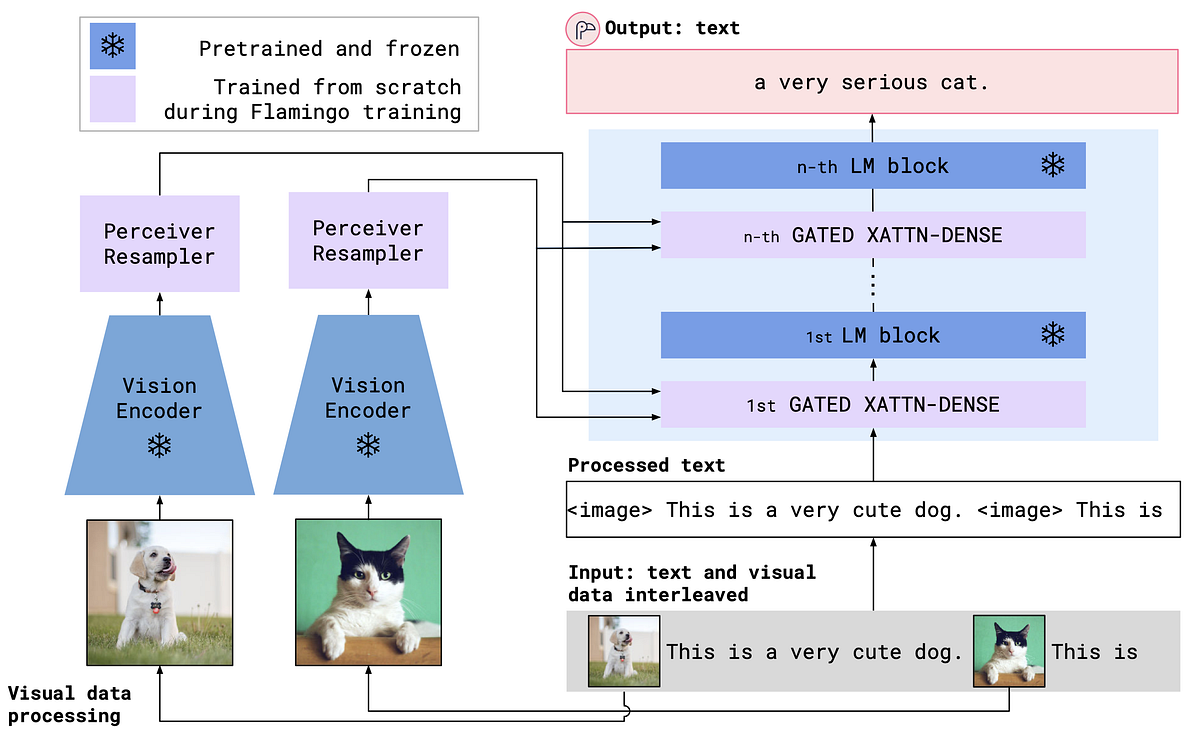
マルチモーダル言語モデルの解説:ビジュアル指示の調整
「LLMは、多くの自然言語タスクでゼロショット学習とフューショット学習の両方で有望な結果を示していますしかし、LLMは視覚的な推論を必要とするタスクにおいては不利です...」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.