Learn more about Search Results V100 - Page 2

- You may be interested
- ラミニAIに会ってください:開発者が簡単...
- 「人間によるガイド付きAIフレームワーク...
- オラクルクラウドインフラストラクチャは...
- 「Daskデータフレームのパーティションサ...
- 完全に自動化されたデータドリフト検出パ...
- Rにおけるトップ10のエラーとそれらを修正...
- 「Amazon SageMakerを使用してクラシカル...
- LLama Indexを使用してRAGパイプラインを...
- 「ソフトウェア開発におけるAIの活用:ソ...
- ウェブ3.0とブロックチェーンの進化による...
- 将来のイベントの予測:AIとMLの能力と限界
- AGIの現実世界の課題
- 「大規模な言語モデルとベクトルデータベ...
- 共同磁気マイクロロボットの進展
- このAIの論文は、テキスト変換グラフとし...

機械学習エンジニアのためのLLMOps入門ガイド
イントロダクション OpenAIのChatGPTのリリースは、大規模言語モデル(LLM)への関心を高め、人工知能について誰もが話題にしています。しかし、それは単なる友好的な会話だけではありません。機械学習(ML)コミュニティは、LLMオプスという新しい用語を導入しました。私たちは皆、MLOpsについて聞いたことがありますが、LLMOpsとは何でしょうか。それは、これらの強力な言語モデルをライフサイクル全体で扱い管理する方法に関するものです。 LLMは、AI駆動の製品の作成と維持方法を変えつつあり、この変化が新しいツールやベストプラクティスの必要性を引き起こしています。この記事では、LLMOpsとその背景について詳しく解説します。また、LLMを使用してAI製品を構築する方法が従来のMLモデルと異なる点も調査します。さらに、これらの相違によりMLOps(機械学習オペレーション)がLLMOpsと異なる点も見ていきます。最後に、LLMOpsの世界で今後期待されるエキサイティングな展開について討論します。 学習目標: LLMOpsとその開発についての理解を深める。 例を通じてLLMOpsを使用してモデルを構築する方法を学ぶ。 LLMOpsとMLOpsの違いを知る。 LLMOpsの将来の展望を一部垣間見る。 この記事はデータサイエンスブロガソンの一環として公開されました。 LLMOpsとは何ですか? LLMOpsは、Large Language Model Operationsの略であり、MLOpsと似ていますが、特に大規模言語モデル(LLM)向けに設計されたものです。開発から展開、継続的なメンテナンスまで、LLMを活用したアプリケーションに関連するすべての要素を処理するために、新しいツールとベストプラクティスを使用する必要があります。 これをよりよく理解するために、LLMとMLOpsの意味を解説します: LLMは、人間の言語を生成できる大規模言語モデルです。それらは数十億のパラメータを持ち、数十億のテキストデータで訓練されます。 MLOps(機械学習オペレーション)は、機械学習によって動力を得るアプリケーションのライフサイクルを管理するために使用されるツールやプラクティスのセットです。 これで基本的な説明ができたので、このトピックをもっと詳しく掘り下げましょう。 LLMOpsについての話題とは何ですか? まず、BERTやGPT-2などのLLMは2018年から存在しています。しかし、ChatGPTが2022年12月にリリースされたことで、LLMOpsのアイデアにおいて著しい盛り上がりを目の当たりにするのは、ほぼ5年後のことです。 それ以来、私たちはLLMのパワーを活用したさまざまなタイプのアプリケーションを見てきました。これには、ChatGPTなどのお馴染みのチャットボットから(ChatGPTなど)、編集や要約のための個人用のライティングアシスタント(Notion AIなど)やコピーライティングのためのスキルを持ったもの(Jasperやcopy.aiなど)まで含まれます。また、コードの書き込みやデバッグのためのプログラミングアシスタント(GitHub Copilotなど)、コードのテスト(Codium AIなど)、セキュリティのトラブルの特定(Socket…

「プロダクションでのあなたのLLMの最適化」
注意: このブログ投稿は、Transformersのドキュメンテーションページとしても利用可能です。 GPT3/4、Falcon、LLamaなどの大規模言語モデル(LLM)は、人間中心のタスクに取り組む能力を急速に向上させており、現代の知識ベース産業で不可欠なツールとして確立しています。しかし、これらのモデルを実世界のタスクに展開することは依然として課題が残っています: ほぼ人間のテキスト理解と生成能力を持つために、LLMは現在数十億のパラメータから構成される必要があります(Kaplanら、Weiら参照)。これにより、推論時のメモリ要件が増大します。 多くの実世界のタスクでは、LLMには豊富な文脈情報が必要です。これにより、推論中に非常に長い入力シーケンスを処理する能力が求められます。 これらの課題の核心は、特に広範な入力シーケンスを扱う場合に、LLMの計算およびメモリ能力を拡張することにあります。 このブログ投稿では、効率的なLLMの展開のために、現時点で最も効果的な技術について説明します: 低精度: 研究により、8ビットおよび4ビットの数値精度で動作することが、モデルのパフォーマンスに大幅な低下を伴わずに計算上の利点をもたらすことが示されています。 Flash Attention: Flash Attentionは、よりメモリ効率の高いアテンションアルゴリズムのバリエーションであり、最適化されたGPUメモリの利用により、高い効率を実現します。 アーキテクチャのイノベーション: LLMは常に同じ方法で展開されるため、つまり長い入力コンテキストを持つ自己回帰的なテキスト生成として、より効率的な推論を可能にする専用のモデルアーキテクチャが提案されています。モデルアーキテクチャの中で最も重要な進歩は、Alibi、Rotary embeddings、Multi-Query Attention(MQA)、Grouped-Query-Attention(GQA)です。 このノートブックでは、テンソルの視点から自己回帰的な生成の分析を提供し、低精度の採用の利点と欠点について包括的な探索を行い、最新のアテンションアルゴリズムの詳細な調査を行い、改良されたLLMアーキテクチャについて議論します。これを行う過程で、各機能の改善を示す実用的な例を実行します。 1. 低精度の活用 LLMのメモリ要件は、LLMを重み行列とベクトルのセット、およびテキスト入力をベクトルのシーケンスとして見ることで最も理解できます。以下では、重みの定義はすべてのモデルの重み行列とベクトルを意味するために使用されます。 この投稿の執筆時点では、LLMは少なくとも数十億のパラメータから構成されています。各パラメータは通常、float32、bfloat16、またはfloat16形式で保存される10進数の数値で構成されています。これにより、LLMをメモリにロードするためのメモリ要件を簡単に計算できます: X十億のパラメータを持つモデルの重みをロードするには、おおよそ4 *…

2023年にディープラーニングのためのマルチGPUシステムを構築する方法
「これは、予算内でディープラーニングのためのマルチGPUシステムを構築する方法についてのガイドです特に、コンピュータビジョンとLLMモデルに焦点を当てています」
大規模言語モデル:SBERT
「トランスフォーマーが自然言語処理(NLP)において進化的な進歩を遂げたことは秘密ではありませんトランスフォーマーを基に、他の多くの機械学習モデルも進化していますその中の一つがBERTであり、主にいくつかの要素から構成されています...」

「カタストロフィックな忘却を防ぎつつ、タスクに微調整されたモデルのファインチューニングにqLoRAを活用する:LLaMA2(-chat)との事例研究」
大規模言語モデル(LLM)のAnthropicのClaudeやMetaのLLaMA2などは、さまざまな自然言語タスクで印象的な能力を示していますしかし、その知識とタスク固有の...

AIイメージフュージョンとDGX GH200
「コンピュータビジョン(CV)の領域では、部分的な画像を繋ぎ合わせて寸法を測定する能力は単なる高度なトリックではなく、重要なスキルですパノラマビューを作成している場合でも...」

韓国の研究者がVITS2を提案:自然さと効率性の向上のためのシングルステージのテキスト読み上げモデルにおける飛躍的な進歩
この論文では、以前のモデルのさまざまな側面を改善することにより、より自然な音声を合成する単一ステージのテキストから音声へのモデルであるVITS2が紹介されています。このモデルは、不自然さの断続的な問題、計算効率、音素変換への依存性といった問題に取り組んでいます。提案手法は、自然さの向上、マルチスピーカーモデルにおける音声特性の類似性、トレーニングおよび推論効率を向上させます。 以前の研究では音素変換への強い依存度が大幅に低下し、完全なエンドツーエンドの単一ステージアプローチが可能になりました。 以前の手法: 2段階のパイプラインシステム:これらのシステムは、入力テキストから波形を生成するプロセスを2つの段階に分割しました。最初の段階は、入力テキストからメルスペクトログラムや言語特徴などの中間音声表現を生成しました。2番目の段階では、これらの中間表現に基づいて生の波形を生成しました。これらのシステムには、最初の段階から2番目の段階へのエラー伝播、メルスペクトログラムなどの人間によって定義された特徴への依存、中間特徴の生成に必要な計算などの制限がありました。 単一ステージのモデル:最近の研究では、入力テキストから直接波形を生成する単一ステージのモデルが積極的に探求されています。これらのモデルは、2段階のシステムを上回るだけでなく、人間の音声とほとんど区別できない高品質の音声を生成する能力も示しています。 J. Kim、J. Kong、J. Sonによるエンドツーエンドのテキストから音声への条件付き変分オートエンコーダによる敵対的学習は、単一ステージのテキストから音声への合成の分野での重要な先行研究でした。この以前の単一ステージアプローチは大きな成功を収めましたが、断続的な不自然さ、デュレーション予測の効率の低さ、複雑な入力形式、マルチスピーカーモデルにおける不十分な話者の類似性、トレーニングの遅さ、音素変換への強い依存性などの問題がありました。 本論文の主な貢献は、以前の単一ステージモデルで見つかった問題、特に上記の成功したモデルで言及された問題に取り組み、テキストから音声合成の品質と効率を向上させる改良を導入することです。 ディープニューラルネットワークベースのテキストから音声への変換は、大きな進歩を遂げています。連続的な波形への不連続なテキストの変換と、高品質の音声オーディオの確保が課題です。以前の解決策は、テキストから中間音声表現を生成し、それらの表現に基づいて生の波形を生成する2つの段階にプロセスを分割しました。単一ステージのモデルは積極的に研究され、2段階のシステムを上回っています。この論文では、以前の単一ステージモデルで見つかった問題に取り組むことを目指しています。 本論文では、デュレーション予測、正規化フローを持つ拡張変分オートエンコーダ、アライメントサーチ、話者条件付きテキストエンコーダの4つの領域で改善点が説明されています。敵対的学習を通じてトレーニングされた確率的なデュレーション予測器が提案されています。モノトニックアライメントサーチ(MAS)は、品質向上のための修正を加えたアライメントに使用されます。モデルは、長期依存関係を捉えるために正規化フローにTransformerブロックを導入します。話者条件付きテキストエンコーダは、各話者のさまざまな音声特性をより良く模倣するために設計されています。 LJ SpeechデータセットとVCTKデータセットで実験が行われました。モデルの入力として音素シーケンスと正規化されたテキストの両方が使用されました。ネットワークはAdamWオプティマイザを使用してトレーニングされ、トレーニングはNVIDIA V100 GPUで実施されました。合成音声の自然さを評価するためにクラウドソーシングされた平均意見スコア(MOS)テストが実施されました。提案手法は、以前のモデルと比較して合成音声の品質において大きな改善が示されました。提案手法の妥当性を検証するために削除研究が行われました。最後に、著者は実験、品質評価、計算速度の測定を通じて提案手法の妥当性を示しましたが、音声合成の分野にはまだ解決すべきさまざまな問題が存在し、彼らの研究が将来の研究の基盤となることを期待しています。

バイオメディカルインサイトのための生成AI
OpenBIOMLとBIO GPTを利用したGenerative AIを探求し、Large Language Models (LLMs)を使用して疾患の理解と治療に新たなアプローチを取ることを目指しています
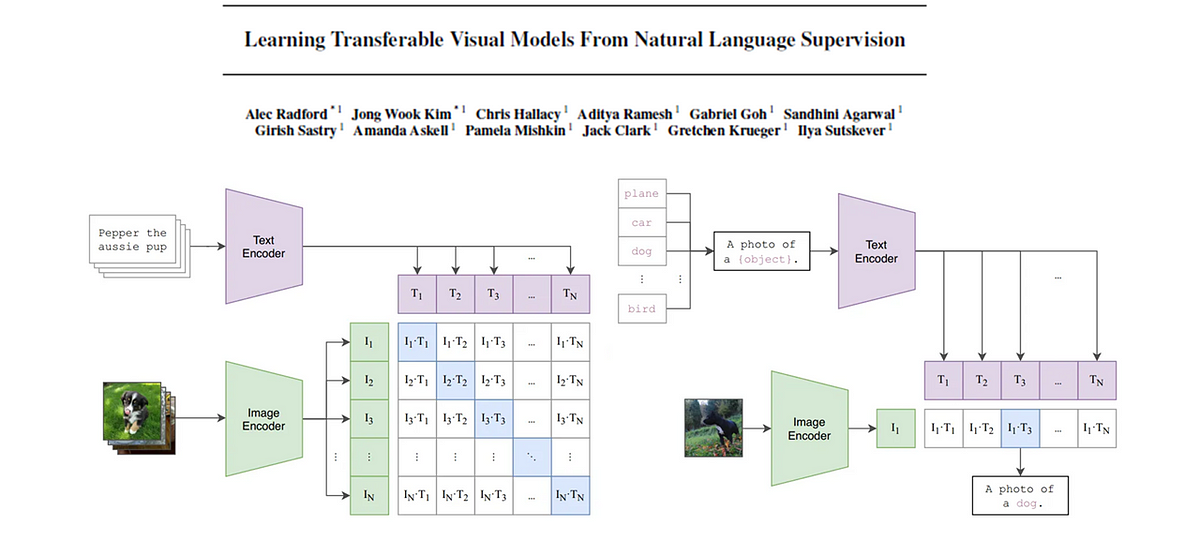
CLIP基礎モデル
この記事では、CLIP(対照的な言語画像事前学習)の背後にある論文を詳しく解説しますキーコンセプトを抽出し、わかりやすく解説しますさらに、画像...

Amazon SageMakerを使用して、オーバーヘッドイメージで自己教師ありビジョン変換モデルをトレーニングする
この記事では、Amazon SageMakerを使用して、オーバーヘッドのイメージに対して自己教師ありビジョン変換器をトレーニングする方法を示しますトラベラーズは、Amazon Machine Learning Solutions Lab(現在はGenerative AI Innovation Centerとして知られています)と協力して、このフレームワークを開発し、航空写真モデルのユースケースをサポートおよび強化しました
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.