Learn more about Search Results Tuna - Page 2

- You may be interested
- XGBoost ディープラーニングがグラディエ...
- 水中探査の革命:ブラウン大学のプリオボ...
- 「読むべき創造的エージェント研究論文」
- 「CMU研究者がニューラルネットワークの挙...
- エントロピー正則化強化学習の説明
- 「なぜSQLはデータサイエンスのために学ぶ...
- Plotlyの3Dサーフェスプロットを使用して...
- 新しい化学
- 「メタヒューリスティクスの説明:アント...
- Btech卒業後に何をすべきですか?
- スタビリティAIがアドバーサリアルディフ...
- 「データ時代における知識の解明」
- 「データ自体よりもデータ生成プロセスを...
- 「PaLM 2はどのように動作しますか?完全...
- エイントホーフェンとノースウェスタン大...

GPU を最大限に活用せずに LLM を微調整する
ただし、採用には障壁がありましたこれらのモデルは非常に大きいため、予算の少ない企業や研究者、または趣味を持つ人々が独自の目的に合わせてカスタマイズすることは困難でした...

ディープネットワークの活性化関数の構築
ディープニューラルネットワークの基本的な要素は、活性化関数(AF)です活性化関数は、ネットワーク内のノード(「ニューロン」)の最終出力を形成する非線形関数です一般的な活性化関数は...

ハイパーパラメータ最適化のためのトップツール/プラットフォーム2023年
ハイパーパラメータは、モデルの作成時にアルゴリズムの振る舞いを制御するために使用されるパラメータです。これらの要因は通常のトレーニングでは見つけることができません。モデルをトレーニングする前に、それらを割り当てる必要があります。 最適なハイパーパラメータの組み合わせを選ぶプロセスは、機械学習におけるハイパーパラメータの最適化またはチューニングとして知られています。 タスクに応じて利点と欠点を持つ、いくつかの自動最適化方法があります。 ディープラーニングモデルの複雑さとともに、ハイパーパラメータの最適化のためのツールの数も増えています。ハイパーパラメータの最適化(HPO)には、オープンソースのツールとクラウドコンピューティングリソースに依存したサービスの2つの種類のツールキットが一般的にあります。 以下に、MLモデルのハイパーパラメータ最適化に使用される主要なハイパーパラメータ最適化ライブラリとツールを示します。 ベイズ最適化 ベイジアン推論とガウス過程に基づいて構築されたPythonプログラムであるBayesianOptimisationは、ベイジアングローバル最適化を使用して、可能な限り少ない反復回数で未知の関数の最大値を見つけます。この方法は、探索と活用の適切なバランスを取ることが重要な高コスト関数の最適化に最適です。 GPyOpt GPyOptは、ベイジアン最適化のためのPythonオープンソースパッケージです。ガウス過程モデリングのためのPythonフレームワークであるGPyを使用して構築されています。このライブラリは、ウェットラボの実験、モデルと機械学習手法の自動セットアップなどを作成します。 Hyperopt Hyperoptは、条件付き、離散、および実数値の次元を含む検索空間上の直列および並列最適化に使用されるPythonモジュールです。ハイパーパラメータの最適化(モデル選択)を行いたいPythonユーザーに、並列化のための手法とインフラストラクチャを提供します。このライブラリでサポートされているベイジアン最適化の手法は、回帰木とガウス過程に基づいています。 Keras Tuner Keras Tunerモジュールを使用すると、機械学習モデルの理想的なハイパーパラメータを見つけることができます。コンピュータビジョン向けの2つのプリビルドカスタマイズ可能なプログラムであるHyperResNetとHyperXceptionがライブラリに含まれています。 Metric Optimisation Engine (MOE) Metric Optimisation Engine(MOE)は、最適な実験設計のためのオープンソースのブラックボックスベイジアングローバル最適化エンジンです。パラメータの評価に時間や費用がかかる場合、MOEはシステムのパラメータ最適化方法として有用です。A/Bテストを通じてシステムのクリックスルーや変換率を最大化したり、高コストのバッチジョブや機械学習予測手法のパラメータを調整したり、エンジニアリングシステムを設計したり、現実の実験の最適なパラメータを決定したりするなど、さまざまな問題に対応できます。 Optuna Optunaは、機械学習に優れた自動ハイパーパラメータ最適化のためのソフトウェアフレームワークです。ハイパーパラメータの検索空間を動的に構築するための命令的な定義によるユーザAPIを提供します。このフレームワークは、プラットフォームに依存しないアーキテクチャ、シンプルな並列化、Pythonicな検索空間のための多くのライブラリを提供します。…
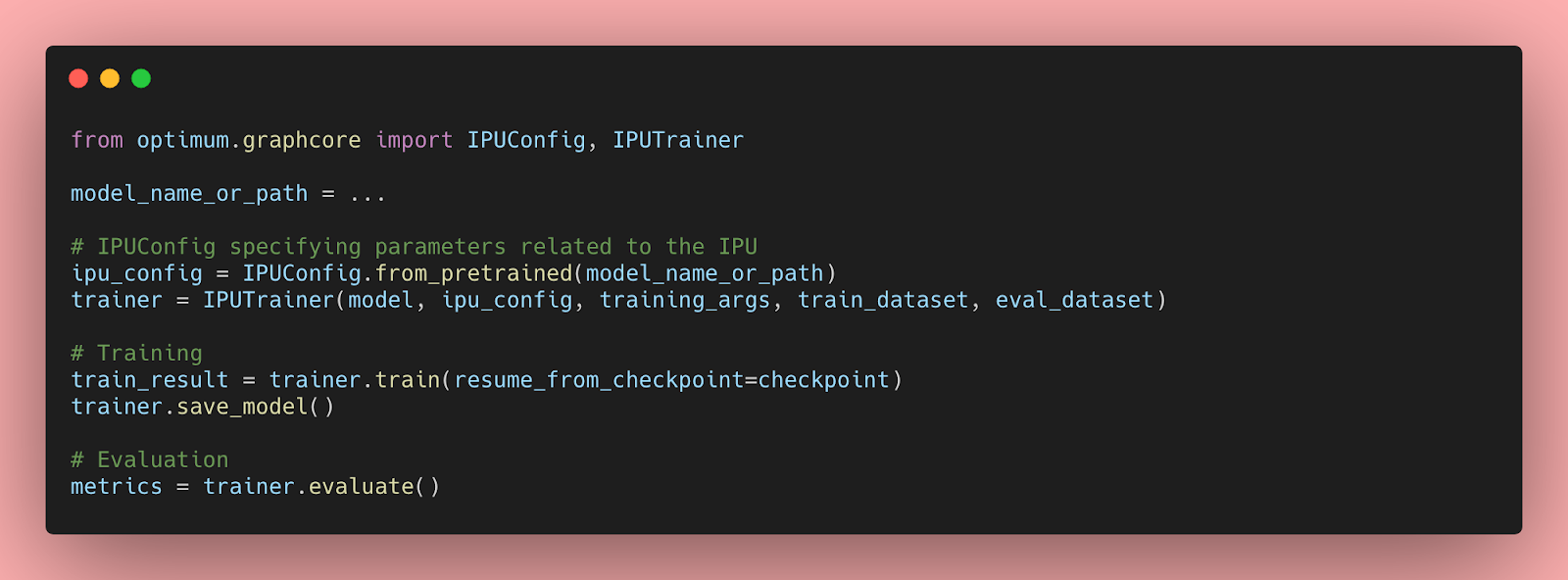
IPUを使用したHugging Face Transformersの始め方と最適化について
Transformerモデルは、自然言語処理、音声処理、コンピュータビジョンなど、さまざまな機械学習タスクで非常に効率的であることが証明されています。しかし、これらの大規模なモデルの予測速度は、会話型アプリケーションや検索などのレイテンシに敏感なユースケースでは実用的ではありません。さらに、実世界でのパフォーマンスを最適化するには、多くの企業や組織には到底手の届かない時間、労力、スキルが必要です。 幸いなことに、Hugging FaceはOptimumというオープンソースのライブラリを導入しました。このライブラリを使用すると、さまざまなハードウェアプラットフォーム上でTransformerモデルの予測レイテンシを大幅に削減することが容易になります。このブログ記事では、AIワークロードに最適化されたGraphcore Intelligence Processing Unit(IPU)向けにTransformerモデルを高速化する方法を学びます。 OptimumがGraphcore IPUと出会う GraphcoreとHugging Faceのパートナーシップにより、最初のIPUに最適化されたモデルとしてBERTが導入されました。今後数ヶ月にわたり、ビジョン、音声、翻訳、テキスト生成など、さまざまなアプリケーションに対応したIPUに最適化されたモデルをさらに導入していく予定です。 Graphcoreのエンジニアは、Hugging Faceのトランスフォーマーを使用してBERTをIPUシステムに実装し、最新のモデルを簡単にトレーニング、微調整、高速化できるように最適化しました。 IPUとOptimumの始め方 OptimumとIPUの使用を始めるために、BERTを例にして説明します。 このガイドでは、Graphcoreのクラウドベースの機械学習プラットフォームであるGraphcloudのIPU-POD16システムを使用し、Getting Started with Graphcloud のPyTorchのセットアップ手順に従います。 GraphcloudサーバーにはすでにPoplar SDKがインストールされています。別のセットアップを使用している場合は、PyTorch for the IPU:…

KiliとHuggingFace AutoTrainを使用した意見分類
イントロダクション ユーザーのニーズを理解することは、ユーザーに関連するビジネスにおいて重要です。しかし、それには多くの労力と分析が必要であり、非常に高価です。ならば、Machine Learningを活用しませんか?Auto MLを使用することでコーディングを大幅に削減できます。 この記事では、HuggingFace AutoTrainとKiliを活用して、テキスト分類のためのアクティブラーニングパイプラインを構築します。Kiliは、品質の高いトレーニングデータ作成を通じて、データ中心のアプローチを強力にサポートするプラットフォームです。協力的なデータ注釈ツールとAPIを提供し、信頼性のあるデータセット構築とモデルトレーニングの素早い反復を可能にします。アクティブラーニングとは、データセットにラベル付けされたデータを追加し、モデルを反復的に再トレーニングするプロセスです。そのため、終わりのない作業であり、人間がデータにラベルを付ける必要があります。 この記事の具体的なユースケースとして、Google PlayストアのVoAGIのユーザーレビューを使用してパイプラインを構築します。その後、構築したパイプラインでレビューをカテゴリ分類します。最後に、分類されたレビューに感情分析を適用します。その結果を分析することで、ユーザーのニーズと満足度を理解することが容易になります。 HuggingFaceを使用したAutoTrain 自動化されたMachine Learningは、Machine Learningパイプラインの自動化を指す用語です。データクリーニング、モデル選択、ハイパーパラメータの最適化も含まれます。🤗 transformersを使用して自動的にハイパーパラメータの検索を行うことができます。ハイパーパラメータの最適化は困難で時間のかかるプロセスです。 transformersや他の強力なAPIを使用してパイプラインを自分自身で構築することもできますが、AutoTrainを完全に自動化することも可能です。AutoTrainは、transformers、datasets、inference-apiなどの多くの強力なAPIを基に構築されています。 データのクリーニング、モデルの選択、ハイパーパラメータの最適化のステップは、すべてAutoTrainで完全に自動化されています。このフレームワークをフルに活用することで、特定のタスクに対してプロダクションレディのSOTAトランスフォーマーモデルを構築することができます。現在、AutoTrainはバイナリとマルチラベルのテキスト分類、トークン分類、抽出型質問応答、テキスト要約、テキストスコアリングをサポートしています。また、英語、ドイツ語、フランス語、スペイン語、フィンランド語、スウェーデン語、ヒンディー語、オランダ語など、多くの言語もサポートしています。AutoTrainでサポートされていない言語の場合、カスタムモデルとカスタムトークナイザを使用することも可能です。 Kili Kiliは、データ中心のビジネス向けのエンドツーエンドのAIトレーニングプラットフォームです。Kiliは、最適化されたラベリング機能と品質管理ツールを提供し、データを管理するための便利な手段を提供します。画像、ビデオ、テキスト、PDF、音声データを素早く注釈付けできます。GraphQLとPythonの強力なAPIも備えており、データ管理を容易にします。 オンラインまたはオンプレミスで利用可能であり、コンピュータビジョンやNLP、OCRにおいてモダンなMachine Learning技術を実現することができます。テキスト分類、固有表現認識(NER)、関係抽出などのNLP / OCRタスクをサポートしています。また、オブジェクト検出、画像転写、ビデオ分類、セマンティックセグメンテーションなどのコンピュータビジョンタスクもサポートしています。 Kiliは商用ツールですが、Kiliのツールを試すために無料のデベロッパーアカウントを作成することもできます。料金については、価格ページから詳細を確認できます。 プロジェクト モバイルアプリケーションについての洞察を得るために、レビューの分類と感情分析の例を取り上げます。…

MLモデルのトレーニングパイプラインの構築方法
手を挙げてください、もしもあなたがごちゃ混ぜのスクリプトをほどくのに時間を無駄にしたことがあるか、またはそう難解なバグを修正しようとしている間に幽霊を追いかけているような気持ちになったことがあるかそしてその間にモデルの訓練が永遠にかかっているという状況も経験したことがあるかもしれません私たちは皆、そんな経験をしたことがあるはずですよね?でも今、別のシナリオを思い浮かべてくださいきれいなコード効率的なワークフロー効率的なモデルの訓練信じられないほど素晴らしい光景ですよね…

2023年のMLOpsの景色:トップのツールとプラットフォーム
2023年のMLOpsの領域に深く入り込むと、多くのツールやプラットフォームが存在し、モデルの開発、展開、監視の方法を形作っています総合的な概要を提供するため、この記事ではMLOpsおよびFMOps(またはLLMOps)エコシステムの主要なプレーヤーについて探求します...

Glassdoorの解読:情報に基づく意思決定のためのNLP駆動Insights
はじめに 現代の厳しい就職市場において、個人は情報を収集して適切なキャリアの決定をする必要があります。Glassdoor は、従業員が匿名で自分たちの経験を共有する人気のプラットフォームです。しかし、口コミの豊富さは求職者を圧倒することがあります。この問題に対処するため、Glassdoor のレビューを洞察に富んだ要約に自動的に縮小する NLP 駆動のシステムを構築しようと試みます。このプロジェクトでは、レビュー収集のために Selenium を使用してから要約化のために NLTK を活用するまで、ステップバイステップのプロセスを探求します。これらの簡潔な要約は、企業文化や成長機会に関する貴重な洞察を提供し、キャリアの目標を適切な組織に調整するのに役立ちます。また、解釈の違いやデータ収集のエラーなどの限界についても議論し、要約化プロセスを包括的に理解できるようにしています。 学習目標 このプロジェクトの学習目標は、多量の Glassdoor レビューを簡潔かつ情報豊富な要約に効果的に縮小する堅牢なテキスト要約システムを開発することです。このプロジェクトに取り組むことで、次のことができます。 公開プラットフォーム(この場合は Glassdoor)からレビューを要約する方法と、求職者が求職を受け入れる前に組織を評価するのにどのように役立つかを理解し、自動要約技術が必要であるという課題に気づく。 Python の Selenium ライブラリを活用して Glassdoor からデータを抽出するためのウェブスクレイピングの基礎を学び、ウェブページのナビゲーション、要素の操作、テキストデータの取得などを探求する。 Glassdoor のレビューから抽出されたテキストデータをクリーニングして準備するスキルを開発する。ノイズの処理、関係のない情報の削除、入力データの品質を確保して効果的な要約を実現する方法を実装する。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.