Learn more about Search Results TensorFlow - Page 2

- You may be interested
- 「サプライチェーンにおける生成型AIの役割」
- リシ・スナック、新しいグローバルAI安全...
- 「メタヒューリスティクスの説明:アント...
- ミネソタ湖のデータのクリーニング+準備
- ChatGPTでリードマグネットのアイデアをブ...
- 古い地図を使って、失われた地域の3Dデジ...
- 『ランチェーンでチェーンを使用するため...
- MongoDBで結合操作を実行するためのシンプ...
- ディフューザを使用してControlNetをトレ...
- Segmind APIsを使用した安定した拡散モデ...
- 退屈なプレゼンテーションを素晴らしいも...
- TaatikNet(ターティクネット):ヘブライ...
- マイクロソフトの研究者がPromptTTS 2を発...
- ラマとChatGPTを使用してマルチチャットバ...
- Android 14:より多様なカスタマイズ、制...

Hugging Face Transformersでより高速なTensorFlowモデル
ここ数か月、Hugging FaceチームはTransformersのTensorFlowモデルの改良に取り組んできました。目標はより堅牢で高速なモデルを実現することです。最近の改良は主に次の2つの側面に焦点を当てています: 計算パフォーマンス:BERT、RoBERTa、ELECTRA、MPNetの計算時間を大幅に短縮するための改良が行われました。この計算パフォーマンスの向上は、グラフ/イージャーモード、TF Serving、CPU/GPU/TPUデバイスのすべての計算アスペクトで顕著に見られます。 TensorFlow Serving:これらのTensorFlowモデルは、TensorFlow Servingを使用して展開することができ、推論においてこの計算パフォーマンスの向上を享受することができます。 計算パフォーマンス 計算パフォーマンスの向上を実証するために、v4.2.0のTensorFlow ServingとGoogleの公式実装との間でBERTのパフォーマンスを比較するベンチマークを実施しました。このベンチマークは、GPU V100上でシーケンス長128を使用して実行されました(時間はミリ秒単位で表示されます): v4.2.0の現行のBertの実装は、Googleの実装よりも最大で約10%高速です。また、4.1.1リリースの実装よりも2倍高速です。 TensorFlow Serving 前のセクションでは、Transformersの最新バージョンでブランドニューのBertモデルが計算パフォーマンスが劇的に向上したことを示しました。このセクションでは、製品環境で計算パフォーマンスの向上を活用するために、TensorFlow Servingを使用してBertモデルを展開する手順をステップバイステップで説明します。 TensorFlow Servingとは何ですか? TensorFlow Servingは、モデルをサーバーに展開するタスクをこれまで以上に簡単にするTensorFlow Extended(TFX)が提供するツールの一部です。TensorFlow Servingには、HTTPリクエストを使用して呼び出すことができるAPIと、サーバー上で推論を実行するためにgRPCを使用するAPIの2つがあります。 SavedModelとは何ですか? SavedModelには、ウェイトとアーキテクチャを含むスタンドアロンのTensorFlowモデルが含まれています。SavedModelは、モデルの元のソースを実行する必要がないため、Java、Go、C++、JavaScriptなどのSavedModelを読み込むバックエンドをサポートするすべてのバックエンドと共有または展開するために役立ちます。SavedModelの内部構造は次のように表されます:…

TF Servingを使用してHugging FaceでTensorFlow Visionモデルを展開する
過去数ヶ月間、Hugging Faceチームと外部の貢献者は、TransformersにさまざまなビジョンモデルをTensorFlowで追加しました。このリストは包括的に拡大しており、ビジョントランスフォーマー、マスク付きオートエンコーダー、RegNet、ConvNeXtなど、最先端の事前学習モデルがすでに含まれています! TensorFlowモデルを展開する際には、さまざまな選択肢があります。使用ケースに応じて、モデルをエンドポイントとして公開するか、アプリケーション自体にパッケージ化するかを選択できます。TensorFlowには、これらの異なるシナリオに対応するツールが用意されています。 この投稿では、TensorFlow Serving(TF Serving)を使用してローカルでビジョントランスフォーマーモデル(画像分類用)を展開する方法を紹介します。これにより、開発者はモデルをRESTエンドポイントまたはgRPCエンドポイントとして公開できます。さらに、TF Servingはモデルのウォームアップ、サーバーサイドバッチ処理など、多くの展開固有の機能を提供しています。 この投稿全体で示される完全な動作するコードを取得するには、冒頭に示されているColabノートブックを参照してください。 🤗 TransformersのすべてのTensorFlowモデルには、save_pretrained()というメソッドがあります。このメソッドを使用すると、モデルの重みをh5形式およびスタンドアロンのSavedModel形式でシリアライズできます。TF Servingでは、モデルをSavedModel形式で提供する必要があります。そこで、まずビジョントランスフォーマーモデルをロードして保存します。 from transformers import TFViTForImageClassification temp_model_dir = "vit" ckpt = "google/vit-base-patch16-224" model = TFViTForImageClassification.from_pretrained(ckpt)…

TensorFlowとXLAを使用した高速なテキスト生成
TL;DR : TensorFlowを使用した🤗transformersを使ったテキスト生成は、XLAでコンパイルできるようになりました。これにより、以前よりも最大100倍高速化され、PyTorchよりもさらに高速になりました – 以下のコラボをチェックしてください! テキスト生成 大規模言語モデルの品質が向上するにつれて、そのモデルができることに対する私たちの期待も高まりました。特にOpenAIのGPT-2のリリース以来、テキスト生成機能を持つモデルが注目されています。そして、その理由は妥当です – これらのモデルは要約、翻訳、さらにはいくつかの言語タスクでのゼロショット学習能力のデモンストレーションを行うことができます。このブログ記事では、TensorFlowを使用してこのテクノロジーを最大限に活用する方法を紹介します。 🤗transformersライブラリはNLPモデルから始まりましたので、テキスト生成は私たちにとって非常に重要な要素です。アクセス可能で、簡単に制御可能で効率的であることをHugging Faceの民主化の取り組みの一環として保証することが目的です。テキスト生成のさまざまなタイプについては以前のブログ記事があります。ただし、以下にコア機能のクイックな概要があります – 私たちのgenerate関数に慣れている場合や、TensorFlowの特異性に直接ジャンプしたい場合は、スキップしても構いません。 まずは基本から始めましょう。テキスト生成は、do_sampleフラグによって確定的または確率的になります。デフォルトでは、Falseに設定されており、出力は確定的であるため、Greedy Decodingとも呼ばれます。それをTrueに設定すると、サンプリングとも呼ばれるため、出力は確率的になりますが、seed引数(stateless TensorFlowのランダム数生成と同じ形式)を介して再現可能な結果を得ることもできます。一般的なガイドラインとして、モデルから事実情報を得る場合は確定的な生成を、よりクリエイティブな出力を目指す場合は確率的な生成を望むでしょう。 # transformers >= 4.21.0が必要です # サンプリングの出力は、使用するハードウェアによって異なる場合があります。 from transformers…

Hugging FaceのTensorFlowの哲学
はじめに PyTorchやJAXからの競争が増えても、TensorFlowは最も使用されるディープラーニングフレームワークのままです。また、それらの他の2つのライブラリとはいくつか非常に重要な点で異なります。特に、高レベルのAPIであるKerasと、データの読み込みライブラリであるtf.dataとの統合が非常に密接です。 PyTorchのエンジニアの中には(ここでオープンプランオフィスを暗く見つめながら私を想像してください)、これを克服すべき問題だと見なす傾向があります。彼らの目標は、TensorFlowが彼らのやり方に従って低レベルのトレーニングとデータの読み込みコードを使用できるようにする方法を見つけることです。これはTensorFlowに取り組む間違った方法です! Kerasは素晴らしい高レベルのAPIです。プロジェクトが数モジュールよりも大きい場合、それを押しのけると、必要になると気付いたときに、その機能のほとんどを自分で再現することになります。 洗練された、尊敬され、非常に魅力的なTensorFlowエンジニアとして、私たちは最先端のモデルの驚異的なパワーと柔軟性を使用したいと思っていますが、私たちが使い慣れたツールとAPIでそれらを扱いたいのです。このブログポストでは、Hugging Faceでそれを実現するために行う選択と、TensorFlowプログラマーとしてフレームワークから期待できることについて説明します。 インタールード:30秒で🤗 経験豊富なユーザーは、このセクションをざっと読んだりスキップしたりして構いませんが、Hugging Faceとtransformersに初めて出会う方には、ライブラリのコアアイデアについて概要を説明する必要があります。モデルを事前学習済みモデルとして名前でリクエストするだけで、1行のコードで取得できます。最も簡単な方法は、TFAutoModelクラスを使用するだけです。 from transformers import TFAutoModel model = TFAutoModel.from_pretrained("bert-base-cased") この1行でモデルのアーキテクチャがインスタンス化され、重みが読み込まれます。これにより、元の有名なBERTモデルの正確なレプリカが得られます。ただし、このモデル自体ではあまり役に立ちません – 出力ヘッドや損失関数がありません。実際には、これは最後の隠れ層の直後で終了するニューラルネットワークの「ステム」です。では、どのようにして出力ヘッドを追加するのでしょうか?簡単です、異なるAutoModelクラスを使用するだけです。ここでは、Vision Transformer(ViT)モデルを読み込み、画像分類ヘッドを追加しています。 from transformers import TFAutoModelForImageClassification…

🤗 Transformersを使用してTensorFlowとTPUで言語モデルをトレーニングする
イントロダクション TPUトレーニングは有用なスキルです:TPUポッドは高性能で非常にスケーラブルであり、数千万から数百億のパラメータまで、どんなスケールでもモデルをトレーニングすることが容易です。GoogleのPaLMモデル(5000億パラメータ以上!)は完全にTPUポッドでトレーニングされました。 以前、TensorFlowを使用した小規模なTPUトレーニングと、TPUでモデルを動作させるために理解する必要がある基本的なコンセプトを紹介するチュートリアルとColabの例を作成しました。今回は、TensorFlowとTPUを使用してマスクされた言語モデルをゼロからトレーニングするためのすべての手順、トークナイザのトレーニングとデータセットの準備から最終的なモデルのトレーニングとアップロードまでを詳しく説明します。これはColabだけでなく、専用のTPUノード(またはVM)が必要なタスクであり、そこに焦点を当てます。 Colabの例と同様に、TensorFlowの非常にクリーンなTPUサポートであるXLAとTPUStrategyを活用しています。また、🤗 Transformers内のほとんどのTensorFlowモデルが完全にXLA互換であるという利点もあります。そのため、TPU上で実行するために必要な作業はほとんどありません。 ただし、この例はColabの例とは異なり、実際のトレーニングランに近いスケーラブルな例です。デフォルトではBERTサイズのモデルしか使用していませんが、いくつかの設定オプションを変更することで、コードをより大きなモデルとより強力なTPUポッドスライスに拡張することができます。 動機 なぜ今このガイドを書いているのでしょうか?実際、🤗 Transformersは何年もの間TensorFlowをサポートしてきましたが、これらのモデルをTPUでトレーニングすることはコミュニティにとって主要な問題でした。これは以下の理由によるものです: 多くのモデルがXLA互換ではなかった データコレクターがネイティブのTF操作を使用していなかった 私たちはXLAが将来の技術であると考えています。それはJAXのコアコンパイラであり、TensorFlowでの一流のサポートを受けており、PyTorchからも使用できます。そのため、私たちはコードベースをXLA互換にするために大きな取り組みを行い、XLAとTPUの互換性に立ちはだかるその他の障害を取り除きました。これにより、ユーザーは私たちのほとんどのTensorFlowモデルをTPUで煩わずにトレーニングできるはずです。 現在のLLM(言語モデル)と生成AIの最近の重要な進歩により、モデルのトレーニングに対する一般の関心が高まり、最新のGPUにアクセスすることが非常に困難になりました。TPUでのトレーニング方法を知っていると、超高性能な計算ハードウェアへのアクセスする別の方法を手に入れることができます。それは、eBayで最後のH100の入札戦に敗れてデスクで醜い泣きをするよりもずっと品位があります。あなたにはもっと良いものがふさわしいのです。そして経験から言えることですが、TPUでのトレーニングに慣れると、戻りたくなくなるかもしれません。 予想されること WikiTextデータセット(v1)を使用してRoBERTa(ベースモデル)をゼロからトレーニングします。モデルのトレーニングだけでなく、トークナイザをトレーニングし、データをトークン化してTFRecord形式でGoogle Cloud Storageにアップロードし、TPUトレーニングでアクセスできるようにします。コードはこのディレクトリにあります。ある種の人にとっては、このブログ投稿の残りをスキップして、コードに直接ジャンプすることもできます。ただし、しばらくお付き合いいただければ、コードベースのいくつかのキーポイントについて詳しく見ていきます。 ここで紹介するアイデアの多くは、私たちのColabの例でも触れられていましたが、それらをすべて組み合わせて実際に動作するフルエンドツーエンドの例をユーザーに示したかったのです。次の図は、🤗 Transformersを使用した言語モデルのトレーニングに関わる手順の概要を図解したものです。TensorFlowとTPUを使用しています。 データの取得とトークナイザのトレーニング 先述のように、WikiTextデータセット(v1)を使用しました。データセットの詳細については、Hugging Face Hubのデータセットページにアクセスして調べることができます。 データセットは既に互換性のある形式でHubに利用可能なので、🤗 datasetsを使用して簡単にロードして操作することができます。ただし、この例ではトークナイザをゼロから学習しているため、以下のような手順を踏んでいます:…

TensorFlowの学習率の変更方法
TensorFlowで学習率を変更するには、使用している最適化アルゴリズムに応じてさまざまなテクニックを利用することができます
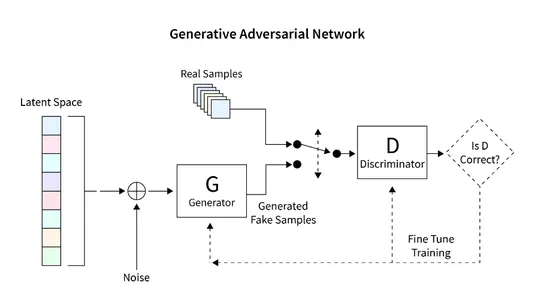
TensorFlowを使用したGANの利用による画像生成
イントロダクション この記事では、GAN(Generative Adversarial Networks)を使用して手書き数字のユニークなレンダリングを生成するためのTensorFlowの応用について探求します。GANフレームワークには、ジェネレータとディスクリミネータという2つの主要なコンポーネントがあります。ジェネレータはランダムな方法で新しい画像を生成し、ディスクリミネータは本物と偽物の画像を区別するために設計されています。GANのトレーニングを通じて、手書き数字に似たコレクションの画像を得ることができます。この記事の主な目的は、MNISTデータセットを使用してGANを構築し評価する手順を概説することです。 学習目標 この記事は、生成的対抗ネットワーク(GAN)の包括的な紹介を提供し、画像生成におけるその応用を探求します。 このチュートリアルの主な目的は、TensorFlowライブラリを使用してGANを構築する手順をステップバイステップで読者に案内することです。MNISTデータセットでGANをトレーニングして手書き数字の新しい画像を生成する方法をカバーしています。 この記事では、ジェネレータとディスクリミネータを含むGANのアーキテクチャとコンポーネントについて説明し、基本的な動作原理を読者の理解を深めるために探求します。 学習を支援するために、記事にはMNISTデータセットの読み込みと前処理、GANアーキテクチャの構築、損失関数の計算、ネットワークのトレーニング、結果の評価などさまざまなタスクをデモンストレーションするコード例が含まれています。 さらに、この記事ではGANの予想される成果物である手書き数字に酷似した画像のコレクションを探求します。 この記事は、データサイエンスブログマラソンの一環として公開されました。 何を構築するのか? 既存の画像データベースを使用して新しい画像を生成することは、生成的対抗ネットワーク(GAN)と呼ばれる特殊なモデルの主要な特徴です。GANは多様な画像データセットを活用して教師なしまたは半教師ありの画像を生成することに優れています。 この記事では、GANの画像生成の潜在能力を活用して手書き数字を作成します。手法としては、手書き数字のデータベースでネットワークをトレーニングすることが含まれます。この教示的な記事では、Tensorflowライブラリを利用して基本的なGANを構築し、MNISTデータセットでトレーニングを行い、手書き数字の新しい画像を生成します。 どのように設定しますか? この記事の主な焦点は、GANの画像生成の潜在能力を活用することです。手順は、画像データベースの読み込みと前処理から始まり、GANのトレーニングプロセスを容易にするためです。データが正常に読み込まれたら、GANモデルを構築し、トレーニングとテストのための必要なコードを開発します。次のセクションでは、この機能を実装し、MNISTデータベースを使用して新しい画像を生成するための詳細な手順が提供されます。 モデルの構築 構築するGANモデルは、2つの重要なコンポーネントで構成されています: ジェネレータ:このコンポーネントは新しい画像を生成する責任があります。 ディスクリミネータ:このコンポーネントは生成された画像の品質を評価します。 GANを使用して画像を生成するために開発する一般的なアーキテクチャは、以下の図に示されています。次のセクションでは、データベースの読み取り、必要なアーキテクチャの作成、損失関数の計算、ネットワークのトレーニングなどの詳細な手順について簡単に説明します。また、ネットワークの検査と新しい画像の生成に使用するコードも提供されます。 データセットの読み込み MNISTデータセットは、コンピュータビジョンの分野で非常に重要で、28×28ピクセルの大きさの手書き数字の広範なコレクションで構成されています。このデータセットは、グレースケールの単一チャンネルの画像形式であるため、GANの実装に理想的です。 次のコードスニペットは、Tensorflowの組み込み関数を使用してMNISTデータセットを読み込む例を示しています。読み込みが成功したら、画像を正規化し、3次元形式に変形します。この変換により、GANアーキテクチャ内で2D画像データを効率的に処理することができます。また、トレーニングデータと検証データの両方にメモリが割り当てられます。…

TensorFlowを使用して責任あるAIを構築する方法は?
イントロダクション 人工知能(AI)は、今週リリースされる新しいAIアプリ、機能、プラットフォームが数百あるほど、前例のない勢いで急速に発展しています。AIが発展する速度につれて、技術の安全性を確保することがますます重要になってきています。これが責任あるAIが登場する理由です。責任あるAIとは、倫理、透明性、責任を遵守し、AIシステムの持続可能な開発と利用を指します。AI企業はそれぞれ独自のルールやチェックリストを持っていますが、TensorFlowやMicrosoftのようなプラットフォームは、誰でもAIを責任あるものにするために使用できるツールのセットを提供しています。この記事では、各機械学習モデル展開フェーズで使用される、最も重要なTensorFlowツールを紹介しています。 学習目標: TensorFlowが、広範なツールとリソースを提供することで、責任あるAIアプリケーションの構築にどのように貢献するか理解する。 機械学習モデル展開の異なるフェーズについて学ぶ。 機械学習モデル展開プロセスの各フェーズでTensorFlowが提供するさまざまなツールを探索する。 責任あるAIとは? 責任あるAIとは、プライバシー、公正性、安全性、持続可能性などの社会的価値に合致するように、倫理的、透明的、責任を持って人工知能(AI)システムを開発および使用することを指します。責任あるAIは、AIシステムが社会全体の利益になるように設計および使用され、有害な影響を与えたり、バイアスを増幅することを防ぐことができます。 責任あるAIの主要な原則には、透明性、責任、公正性、プライバシー、安全性、持続可能性が含まれます。開発者は、AIシステムの設計、開発、展開、および継続的な監視のすべての段階でこれらの原則を適用することができます。 今日は、TensorFlowを使って責任あるAIアプリケーションを構築する方法について探求します。 TensorFlowと責任あるAIへの貢献 TensorFlowは、機械学習モデルの構築および展開のためのオープンソースプラットフォームです。Googleによって開発されたTensorFlowは、画像認識、音声認識、自然言語処理、予測分析など、さまざまなドメインでAIアプリケーションを作成するためのさまざまなツールとリソースを提供しています。 オープンソースであるため、TensorFlowは透明性と解釈可能性の2つの重要な要素を持っています。さらに、このプラットフォームは、責任あるAIアプリケーションを構築するためのツールとガイドラインをリリースしています。ここでは、機械学習モデル展開のさまざまなフェーズで使用されるいくつかの有用なツールを探索してみましょう。 フェーズ1:問題の定義 TensorFlowには、問題定義フェーズのためのツールセットがあります。PAIR(People + AI Research)ガイドブックやPAIR Explorablesは、AIアプリケーションを計画する際に役立ちます。TensorFlowのガイドラインには、データセットの選択、モデルの選択、およびモデルのパフォーマンス評価の戦略が含まれています。これらのガイドラインに従うことで、AIアプリケーションを正確で信頼性があり、効果的にすることができます。 PAIRガイドブックは、ユーザーのニーズと価値に合わせて設計されたAI製品の包括的なガイダンスを提供しています。PAIR Explorablesは、機械学習アルゴリズムや公正性に関連する複雑なトピックなど、責任あるAIに関連する複雑なトピックを探求するためのインタラクティブなブログです。 フェーズ2:データ収集と準備 機械学習の第二フェーズは、データの収集と準備です。TensorFlowには、このフェーズを容易にするためのいくつかのツールがあります。 TensorFlowデータバリデーション(TFDV)…

「コンピュータビジョン101」
コンピュータビジョンの進歩により、未来には莫大な可能性がありますその変革的な影響は、さまざまな産業にまたがっています

「無料ハーバード講座:PythonでのAI入門」
「Pythonを使った人工知能の学びに最適なコースを探していますか?ハーバード大学の無料コースをチェックしてみてください!」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.