Learn more about Search Results StandardScaler - Page 2

- You may be interested
- LLMOps:ハミルトンとのプロダクションプ...
- 「データストーリーテリングとアナリティ...
- 「#30DayMapChallange」の四週目
- AIモデルの知覚を測定する
- テキストのポテンシャルを引き出す:プリ...
- ボット、詐欺ファームがウェブトラフィッ...
- 組合せ最適化によるニューラルネットワー...
- 「AIプログラムがイスラエルの男性の命を...
- 「データ分析のためのトップ10のSQLプロジ...
- ニューラル輝度場の不確実性をどのように...
- 磁気センサーがGPUクリプトジャッキング攻...
- プラグインを使ったチャットボットのため...
- BrainPadがAmazon Kendraを使用して内部の...
- Huggingface TransformersとRayを使用した...
- GPT-エンジニア:あなたの新しいAIコーデ...

Amazon SageMakerを使用して、ML推論アプリケーションをゼロから構築し、展開する
機械学習(ML)が主流化し、広く採用されるにつれて、MLを活用した推論アプリケーションは複雑なビジネス問題を解決するためにますます一般的になっていますこれらの複雑なビジネス問題の解決には、複数のMLモデルとステップを使用することがしばしば必要ですこの記事では、カスタムコンテナを使用してMLアプリケーションを構築・ホストする方法をご紹介します

「教師付き学習の実践:線形回帰」
「もしScikit-learnを使用した線形回帰の実装について、詳細で初心者にもやさしいチュートリアルを通じて実践的な経験を求めているなら、魅力的な旅になるでしょう」

「Amazon SageMakerを使用して、Rayベースの機械学習ワークフローをオーケストレーションする」
機械学習(ML)は、お客様がより困難な問題を解決しようとするにつれて、ますます複雑になっていますこの複雑さはしばしば、複数のマシンを使用して単一のモデルをトレーニングする必要性を引き起こしますこれにより、複数のノード間でタスクを並列化することが可能になり、トレーニング時間の短縮、スケーラビリティの向上、[…] などがもたらされます

5つのステップでScikit-learnを始める
このチュートリアルでは、Scikit-learnを使用した機械学習の包括的なハンズオンの手順を提供します読者は、データの前処理、モデルのトレーニングと評価、ハイパーパラメータのチューニング、およびパフォーマンスを向上させるためのアンサンブルモデルのコンパイルなど、キーコンセプトと技術を学びます

機械学習:中央化とスケーリングの目的を理解する
この記事では、センタリングとスケーリングの概念について紹介します 実世界の使用例を通じて、データのセンタリングとスケーリングの利点を説明します技術的には、MinMaxScalerを比較します...

「Pandasによるデータクリーニング」
このステップバイステップのチュートリアルは、初心者向けであり、強力なPandasライブラリを使用してデータのクリーニングと前処理のプロセスをガイドします
『過学習から卓越へ:正則化の力を活用する』
機械学習に関して言えば、私たちの目的は、訓練されていないデータに対して最も正確な予測を行うMLモデルを見つけることですそのために、訓練データでMLモデルを訓練し、どのように機能するかを確認します
データ駆動型のディスパッチ
「現代のスピーディーな世界において、データに基づく意思決定がディスパッチ応答システムにおいて不可欠となっていますディスパッチャーは、通話を聞いて優先順位を付けるという一種のトリアージを行います...」
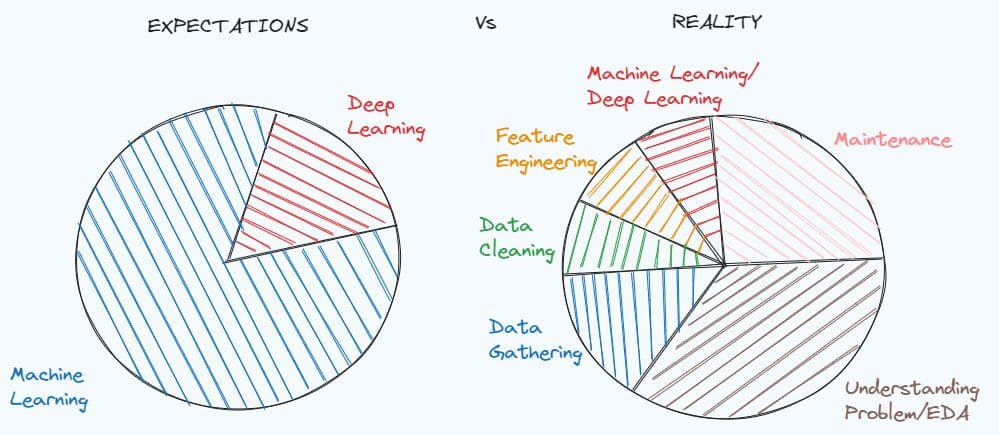
「データクリーニングと前処理の技術をマスターするための7つのステップ」
「初めてのデータサイエンスプロジェクトを解決しようとしていますか?このチュートリアルは、機械学習モデルを適用する前にデータセットを準備するためのステップバイステップのガイドを提供します」

「マスタリングモンテカルロ:より良い機械学習モデルをシミュレーションする方法」
モンテカルロ:統計的シミュレーションが機械学習を支える方法、πの推定からハイパーパラメータの最適化までPythonでこの多目的なテクニックを使用するためのガイド
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.