Learn more about Search Results LXT - Page 2

- You may be interested
- AI + No-Code 開発者のイノベーションを再...
- 「LLMエンジニアとしてChatGPTを使ってプ...
- 『Pythonでのマルチスレッディングとマル...
- スタンフォード大学の研究者が、大規模言...
- 「ATLAS研究者は、教師なし機械学習を通じ...
- 音楽の探索の未来:検索対生成
- スタンフォード大学の研究者が、シェーデ...
- 私たちの原則がAlphaFoldの公開を定義する...
- 「パブリックスピーキングのための5つの最...
- スタンフォードの研究者たちは、Parselと...
- デジタルアーティストのスティーブン・タ...
- 「Google Bard vs. ChatGPT ビジネスにお...
- 27/11から03/12までの週の主要なコンピュ...
- 欧州は、テック・ジャイアントの権力に挑...
- ベクトルデータベースについて知っておく...

「履歴書をよりスマートにする:仕事探しのためのAIパワードツール」
『就職活動を力強くサポートし、キャリアの成功を促進する:AI搭載の履歴書カリキュラム(CV)ビルダーツール、求職者向け | 就職活動とキャリアの成功を高める』
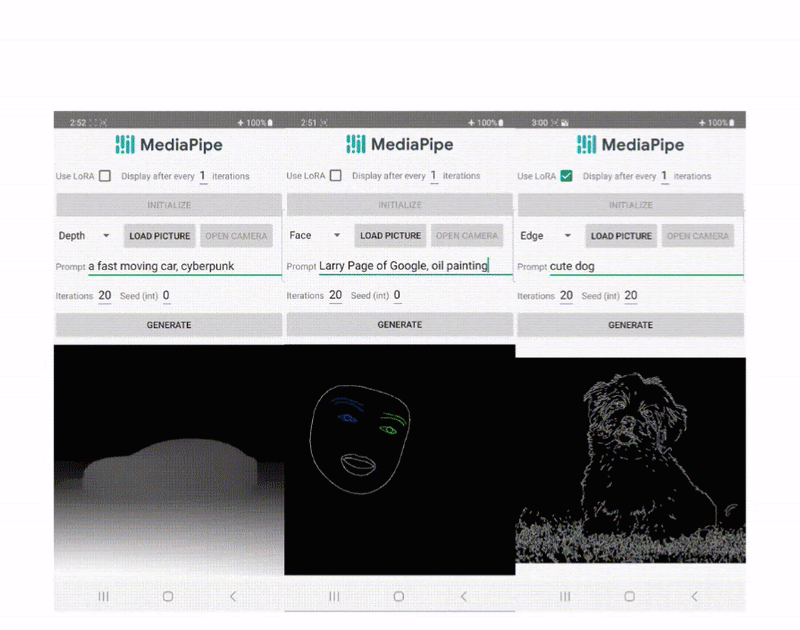
デバイス上での条件付きテキストから画像生成のための拡散プラグイン
Yang ZhaoとTingbo Houによる投稿、ソフトウェアエンジニア、Core ML 近年、拡散モデルはテキストから画像を生成する際に非常に成功を収め、高品質な画像、改善された推論パフォーマンス、そして創造的なインスピレーションの拡大を実現しています。しかし、特にテキストで説明しづらい条件での生成を効率的に制御することはまだ困難です。 本日、MediaPipe拡散プラグインを発表し、コントロール可能なテキストから画像をデバイス上で実行できるようにします。オンデバイスの大規模生成モデルにおけるGPU推論に関する以前の作業を拡張し、既存の拡散モデルとその低ランク適応(LoRA)バリアントにプラグインを追加し、コントロール可能なテキストから画像を生成するための低コストなソリューションを提供します。 デバイス上で動作するコントロールプラグインによるテキストからの画像生成。 背景 拡散モデルでは、画像生成はイテレーションのノイズ除去プロセスとしてモデル化されます。ノイズ画像から始め、各ステップで、拡散モデルは画像を徐々にノイズ除去して目標のコンセプトの画像を明らかにします。研究によると、テキストプロンプトを介した言語理解を活用することで、画像生成を大幅に改善できます。テキストから画像を生成する場合、テキストの埋め込みはモデルにクロスアテンションレイヤーを介して接続されます。しかし、位置や姿勢など、一部の情報はテキストプロンプトで説明することが難しいです。この問題を解決するために、研究者は拡散に追加のモデルを追加して、条件画像から制御情報を注入します。 制御されたテキストから画像を生成するための一般的なアプローチには、Plug-and-Play、ControlNet、T2I Adapterなどがあります。Plug-and-Playは、広く使用されているノイズ除去拡散暗黙モデル(DDIM)の逆操作アプローチを適用し、入力画像から初期ノイズ入力を導出し、拡散モデルのコピー(安定拡散1.5用の860Mパラメータ)を使用して入力画像から条件をエンコードします。Plug-and-Playは、コピーされた拡散から自己注意で空間特徴を抽出し、それらをテキストから画像への拡散に注入します。ControlNetは、拡散モデルのエンコーダーの学習可能なコピーを作成し、ゼロで初期化されたパラメータを持つ畳み込み層を介してデコーダーレイヤーに接続し、条件情報をエンコードします。しかし、その結果、サイズが大きく、拡散モデルの半分(安定拡散1.5用の430Mパラメータ)になります。T2I Adapterはより小さなネットワーク(77Mパラメータ)であり、制御可能な生成に似た効果を実現します。T2I Adapterは条件画像のみを入力とし、その出力はすべての拡散イテレーションで共有されます。ただし、アダプターモデルはポータブルデバイス向けに設計されていません。 MediaPipe拡散プラグイン 条件付き生成を効率的かつカスタマイズ可能、スケーラブルにするために、MediaPipe拡散プラグインを別個のネットワークとして設計しました。これは以下のような特徴を持っています: プラグ可能:事前にトレーニングされたベースモデルに簡単に接続できます。 スクラッチからトレーニング:ベースモデルの事前トレーニング済みの重みを使用しません。 ポータブル:ベースモデル外でモバイルデバイス上で実行され、ベースモデルの推論と比較して無視できるコストです。 メソッド パラメーターサイズ プラグ可能 スクラッチからトレーニング ポータブル Plug-and-Play…
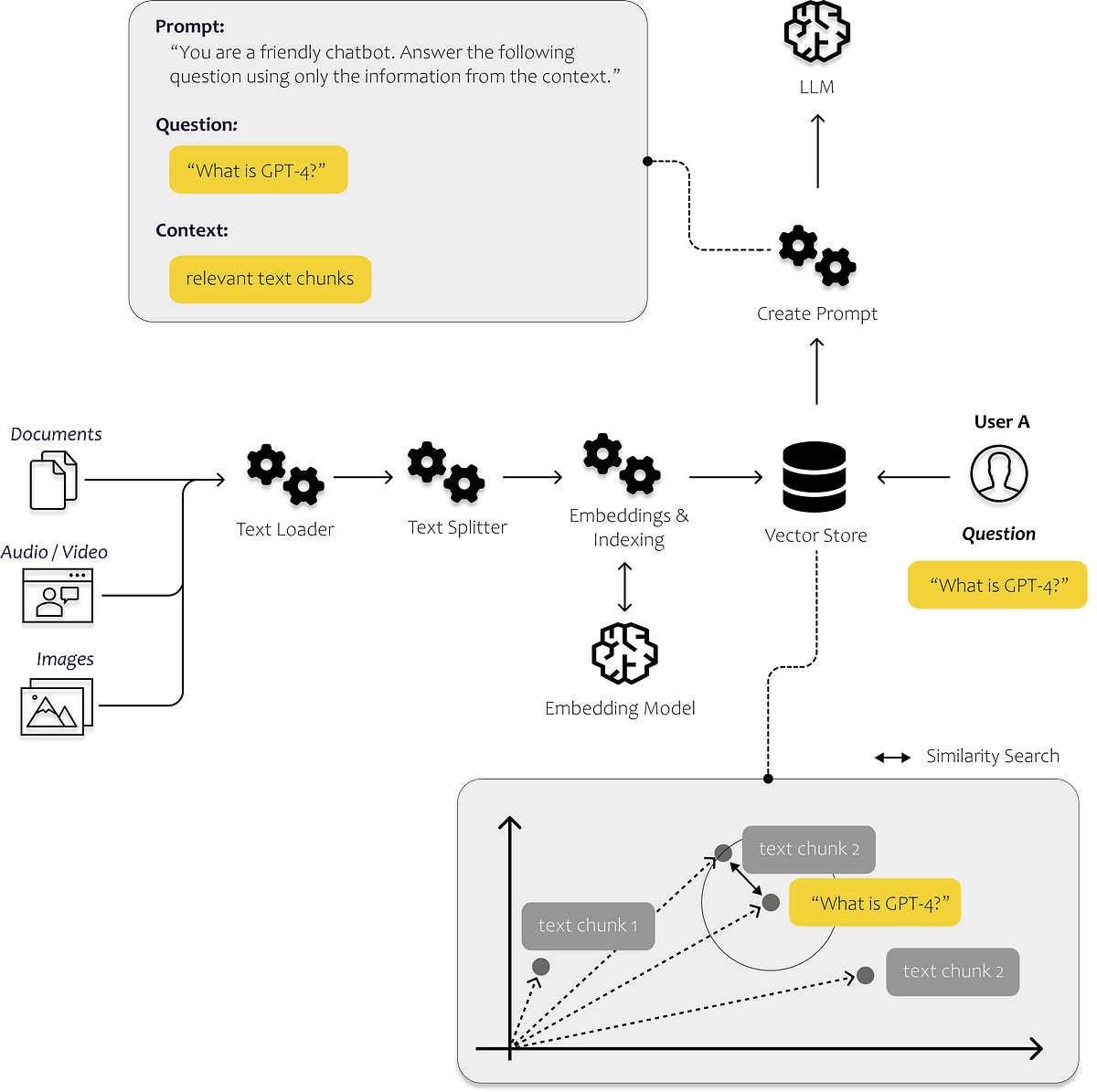
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...
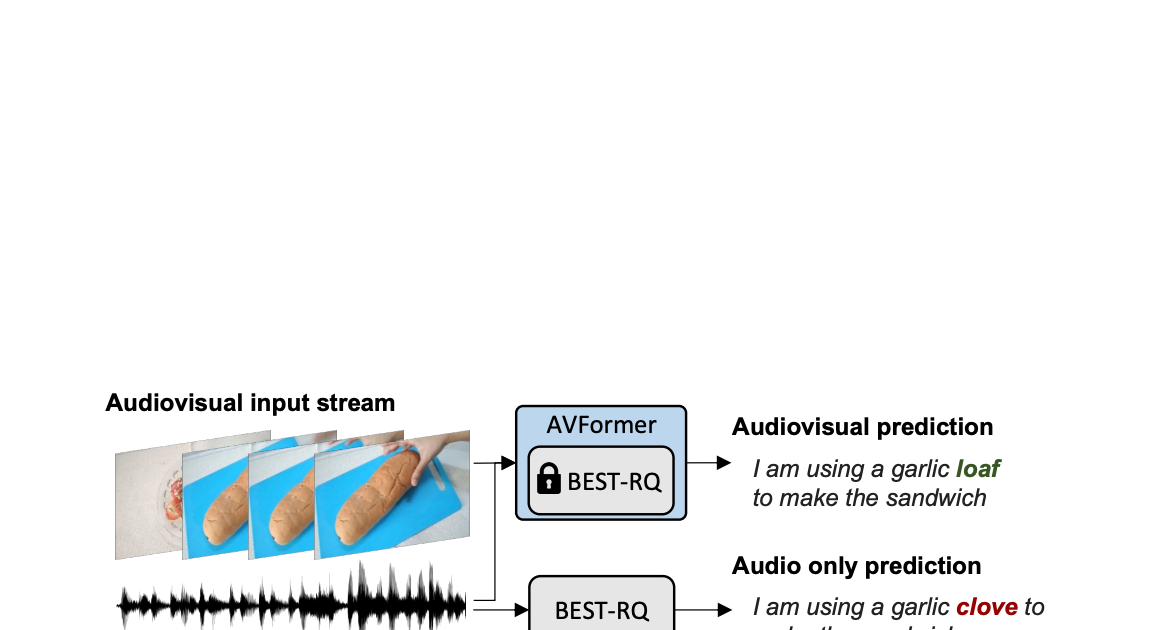
AVFormer:凍結した音声モデルにビジョンを注入して、ゼロショットAV-ASRを実現する
Google Researchの研究科学者、Arsha NagraniとPaul Hongsuck Seoによる投稿 自動音声認識(ASR)は、会議通話、ストリームビデオの転写、音声コマンドなど、さまざまなアプリケーションで広く採用されている確立された技術です。この技術の課題は、ノイズのあるオーディオ入力に集中していますが、マルチモーダルビデオ(テレビ、オンライン編集ビデオなど)の視覚ストリームはASRシステムの堅牢性を向上させる強力な手がかりを提供することができます。これをオーディオビジュアルASR(AV-ASR)と呼びます。 唇の動きは音声認識に強力な信号を提供し、AV-ASRの最も一般的な焦点であるが、野外のビデオで口が直接見えないことがよくあります(例えば、自己中心的な視点、顔のカバー、低解像度など)ため、新しい研究領域である拘束のないAV-ASR(AVATARなど)が誕生し、口の領域だけでなく、ビジュアルフレーム全体の貢献を調査しています。 ただし、AV-ASRモデルをトレーニングするためのオーディオビジュアルデータセットを構築することは困難です。How2やVisSpeechなどのデータセットはオンラインの教育ビデオから作成されていますが、サイズが小さいため、モデル自体は通常、ビジュアルエンコーダーとオーディオエンコーダーの両方から構成され、これらの小さなデータセットで過剰適合する傾向があります。それにもかかわらず、オーディオブックから取得した大量のオーディオデータを用いた大規模なトレーニングによって強く最適化された最近リリースされた大規模なオーディオモデルがいくつかあります。LibriLightやLibriSpeechなどがあります。これらのモデルには数十億のパラメータが含まれ、すぐに利用可能であり、ドメイン間で強い汎化性能を示します。 上記の課題を考慮して、私たちは「AVFormer:ゼロショットAV-ASRの凍結音声モデルにビジョンを注入する」と題した論文で、既存の大規模なオーディオモデルにビジュアル情報を付加するシンプルな方法を提案しています。同時に、軽量のドメイン適応を行います。AVFormerは、軽量のトレーニング可能なアダプタを使用して、視覚的な埋め込みを凍結されたASRモデルに注入します(Flamingoが大規模な言語モデルに視覚テキストタスクのためのビジュアル情報を注入する方法と似ています)。これにより、最小限の追加トレーニング時間とパラメータで弱くラベル付けられた少量のビデオデータでトレーニング可能です。トレーニング中のシンプルなカリキュラムスキームも紹介し、オーディオとビジュアルの情報を効果的に共同処理できるようにするために重要であることを示します。その結果、AVFormerモデルは、3つの異なるAV-ASRベンチマーク(How2、VisSpeech、Ego4D)で最新のゼロショットパフォーマンスを達成し、同時に伝統的なオーディオのみの音声認識ベンチマーク(LibriSpeechなど)のまともなパフォーマンスを保持しています。 拘束のないオーディオビジュアル音声認識。軽量モジュールを使用して、ビジョンを注入して、オーディオビジュアルASRのゼロショットを実現するために、Best-RQ(灰色)の凍結音声モデルにビジョンを注入します。AVFormer(青)というパラメーターとデータ効率の高いモデルが作成されます。オーディオ信号がノイズの場合、視覚的なパンの生成トランスクリプトでオンリーミステイク「クローブ」を「ローフ」に修正するのに役立つ視覚的なパンが役立つ場合があります。 軽量モジュールを使用してビジョンを注入する 私たちの目標は、既存のオーディオのみのASRモデルにビジュアル理解能力を追加しながら、その汎化性能を各ドメイン(AVおよびオーディオのみのドメイン)に維持することです。 このために、既存の最新のASRモデル(Best-RQ)に次の2つのコンポーネントを追加します:(i)線形ビジュアルプロジェクター、および(ii)軽量アダプター。前者は、オーディオトークン埋め込みスペースにおける視覚的な特徴を投影します。このプロセスにより、別々に事前トレーニングされたビジュアル機能とオーディオ入力トークン表現を適切に接続することができます。後者は、その後最小限の変更で、ビデオのマルチモーダル入力を理解するためにモデルを変更します。その後、これらの追加モジュールを、HowTo100Mデータセットからのラベル付けされていないWebビデオとASRモデルの出力を擬似グラウンドトゥルースとして使用してトレーニングし、Best-RQモデルの残りを凍結します。このような軽量モジュールにより、データ効率と強力なパフォーマンスの汎化が可能になります。 我々は、AV-ASRベンチマークにおいて、モデルが人手で注釈付けされたAV-ASRデータセットで一度もトレーニングされていないゼロショット設定で、拡張モデルを評価しました。 ビジョン注入のためのカリキュラム学習 初期評価後、私たちは経験的に、単純な一回の共同トレーニングでは、モデルがアダプタとビジュアルプロジェクタの両方を一度に学習するのが困難であることがわかりました。この問題を緩和するために、私たちは、これら2つの要因を分離し、ネットワークを順序良くトレーニングする2段階のカリキュラム学習戦略を導入しました。最初の段階では、アダプタパラメータが全くフィードされずに最適化されます。アダプタがトレーニングされたら、ビジュアルトークンを追加し、トレーニング済みのアダプタを凍結したまま第2段階でビジュアルプロジェクションレイヤーのみをトレーニングします。 最初の段階は、音声ドメイン適応に焦点を当てています。第2段階では、アダプタが完全に凍結され、ビジュアルプロジェクタは、ビジュアルトークンをオーディオ空間に投影するためのビジュアルプロンプトを生成することを学習する必要があります。このように、私たちのカリキュラム学習戦略は、モデルがAV-ASRベンチマークでビジュアル入力を統合し、新しい音声ドメインに適応することを可能にします。私たちは、交互に適用する反復的な適用では性能が低下するため、各段階を1回だけ適用します。 AVFormerの全体的なアーキテクチャとトレーニング手順。アーキテクチャは、凍結されたConformerエンコーダー・デコーダーモデル、凍結されたCLIPエンコーダー(グレーのロックシンボルで示される凍結層を持つ)、および2つの軽量トレーニング可能なモジュールで構成されています。-(i)ビジュアルプロジェクションレイヤー(オレンジ)およびボトルネックアダプタ(青)を有効にし、多モーダルドメイン適応を可能にします。私たちは、2段階のカリキュラム学習戦略を提案しています。最初に、アダプタ(青)をビジュアルトークンなしでトレーニングします。その後、ビジュアルプロジェクションレイヤー(オレンジ)を調整し、他のすべての部分を凍結したままトレーニングします。 下のプロットは、カリキュラム学習なしでは、AV-ASRモデルがすべてのデータセットでオーディオのみのベースラインよりも劣っており、より多くのビジュアルトークンが追加されるにつれてその差が拡大することを示しています。一方、提案された2段階のカリキュラムが適用されると、AV-ASRモデルは、オーディオのみのベースラインよりも遥かに優れたパフォーマンスを発揮します。 カリキュラム学習の効果。赤と青の線はオーディオビジュアルモデルであり、ゼロショット設定で3つのデータセットに表示されます(WER%が低い方が良いです)。カリキュラムを使用すると、すべての3つのデータセットで改善します(How2(a)およびEgo4D(c)では、オーディオのみのパフォーマンスを上回るために重要です)。4つのビジュアルトークンまで性能が向上し、それ以降は飽和します。 ゼロショットAV-ASRでの結果 私たちは、How2、VisSpeech、Ego4Dの3つのAV-ASRベンチマークで、zero-shotパフォーマンスのために、BEST-RQ、私たちのモデルの音声バージョン、およびAVATARを比較しました。AVFormerは、すべてのベンチマークでAVATARとBEST-RQを上回り、BEST-RQでは600Mパラメータをトレーニングする必要がありますが、AVFormerはわずか4Mパラメータしかトレーニングせず、トレーニングデータセットのわずか5%しか必要としません。さらに、音声のみのLibriSpeechでのパフォーマンスも評価し、AVFormerは両方のベースラインを上回ります。 AV-ASRデータセット全体におけるゼロショット性能に対する最新手法との比較。音声のみのLibriSpeechのパフォーマンスも示します。結果はWER%(低い方が良い)として報告されています。 AVATARとBEST-RQはHowTo100Mでエンドツーエンド(すべてのパラメータ)で微調整されていますが、AVFormerは微調整されたパラメータの少ないセットのおかげで、データセットの5%でも効果的に機能します。…

機械学習モデルのための高度な特徴選択技術
特徴選択のマスタリング:教師あり・教師なし機械学習モデルの高度な技術の探求
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.