Learn more about Search Results He et al., 2016 - Page 2

- You may be interested
- データプロジェクトが現実的な影響をもた...
- 「私と一緒に読む:因果律の読書クラブ」
- 「データサイエンティストには試してみる...
- エントロピーに基づく不確実性予測
- ラミニAIに会ってください:開発者が簡単...
- テキストデータの創造的で時折乱雑な世界&...
- グラフ機械学習の概要
- マイクロソフトがアメリカの労働組合と手...
- 未来は今です:MedTechにおけるAIの6つの応用
- 「AIサイバーセキュリティのスタートアッ...
- AIを学校に持ち込む:MITのアナント・アガ...
- トップ5AI開発企業:あなたのビジネスを変...
- 「OpenAIのGPT Builderが壊れたのは誰のお...
- 「タイムクリスタルからワームホールまで...
- NVIDIAのAI研究者は、オブジェクト周囲の...
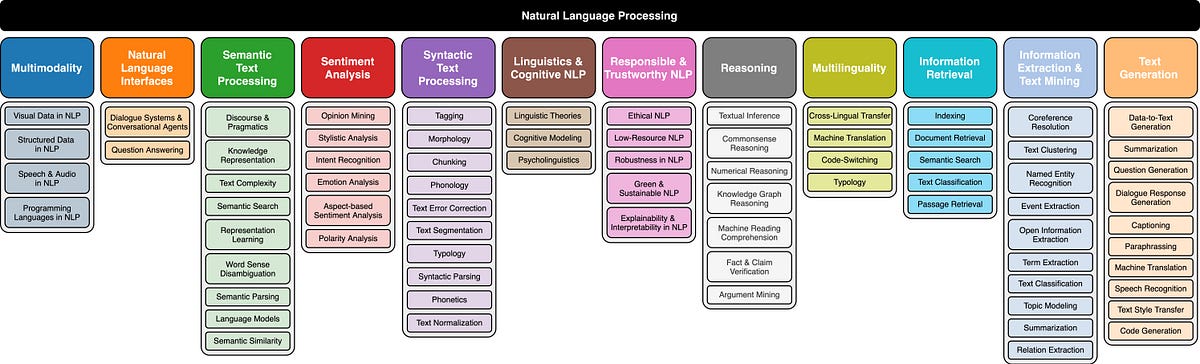
自然言語処理のタクソノミー
「異なる研究分野と最近の自然言語処理(NLP)の進展の概要」
「マルチタスクアーキテクチャ:包括的なガイド」
多くのタスクを実行するためにニューラルネットワークを訓練することは、マルチタスク学習として知られていますこの投稿では、複数の密な計算ビジョンタスクを実行するモデルを訓練します

「Transformerの簡略化:あなたが理解する言葉を使った最先端のNLP — part 3 — アテンション」
「トランスフォーマーは、AIの分野で、おそらく世界中で重大な影響を与えていますこのアーキテクチャはいくつかのコンポーネントで構成されていますが、元の論文は「Attention is All You...」という名前です」

「機械学習の未来:新興トレンドと機会」
「機械学習は、産業全体において転換力として浮上しており、問題解決や意思決定のアプローチを革新していますその影響は広範囲に及び、その可能性は年々拡大し続けています本記事では、機械学習の未来を形作る新興のトレンドや機会について掘り下げます機械学習の現状... 機械学習の未来:新興トレンドと機会の展望 詳細はこちら」
「グリオブラストーマ患者におけるMGMTメチル化状態を予測するための機械学習アプローチ」
今日は、雑誌Nature Scientific Reportsに掲載された、グリオブラストーマ患者に関する研究を探求します『グリオブラストーマのMGMTメチル化状態の予測を改善するために…』
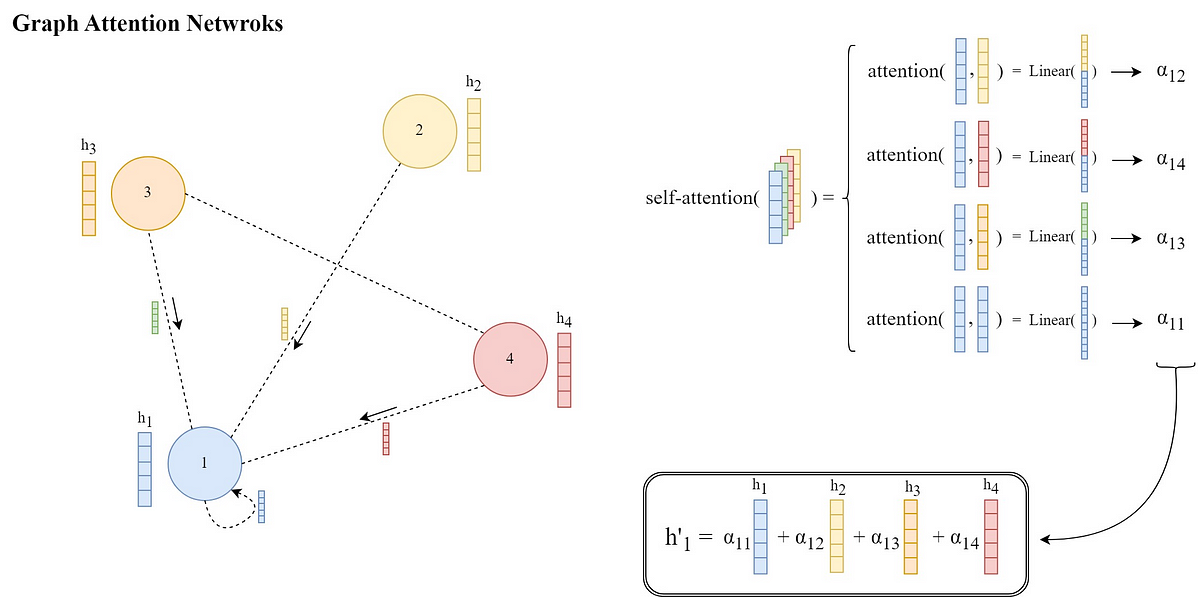
「グラフ注意ネットワーク論文のイラストとPyTorchによる実装の説明」
グラフニューラルネットワーク(GNN)は、グラフ構造のデータに作用する強力なニューラルネットワークの一種ですノードのローカルな情報を集約することによって、ノードの表現(埋め込み)を学習します...

「Amazon SageMaker Hyperband 自動モデルチューニングを使用して、分散トレーニングの収束問題を効果的に解決する」
最近の数年間は、ディープラーニングニューラルネットワーク(DNN)の驚異的な成長が見られていますこの成長は、より正確なモデルや生成型AIによる新たな可能性の開拓(自然言語を合成する大規模な言語モデル、テキストから画像を生成するものなど)に現れていますDNNのこれらの増加した機能は、巨大なモデルを持つことと引き換えに実現されています

「トランスフォーマーベースのエンコーダーデコーダーモデル」
!pip install transformers==4.2.1 !pip install sentencepiece==0.1.95 トランスフォーマーベースのエンコーダーデコーダーモデルは、Vaswani et al.によって有名なAttention is all you need論文で紹介され、現在では自然言語処理(NLP)におけるデファクトスタンダードのエンコーダーデコーダーアーキテクチャです。 最近、T5、Bart、Pegasus、ProphetNet、Margeなど、トランスフォーマーベースのエンコーダーデコーダーモデルの異なる事前学習目的に関する多くの研究が行われていますが、モデルのアーキテクチャはほとんど変わっていません。 このブログ記事の目的は、トランスフォーマーベースのエンコーダーデコーダーアーキテクチャがシーケンス対シーケンスの問題をどのようにモデル化しているかを詳細に説明することです。アーキテクチャによって定義された数学モデルとそのモデルを推論に使用する方法に焦点を当てます。途中で、NLPのシーケンス対シーケンスモデルについての背景をいくつか説明し、トランスフォーマーベースのエンコーダーとデコーダーのパーツに分解します。多くのイラストを提供し、トランスフォーマーベースのエンコーダーデコーダーモデルの理論と🤗Transformersにおける実際の使用方法のリンクを確立します。なお、このブログ記事ではそのようなモデルをトレーニングする方法については説明していません。これについては将来のブログ記事のテーマです。 トランスフォーマーベースのエンコーダーデコーダーモデルは、表現学習とモデルアーキテクチャに関する数年にわたる研究の成果です。このノートブックでは、ニューラルエンコーダーデコーダーモデルの歴史の簡単な概要を提供します。詳細については、Sebastion Ruder氏の素晴らしいブログ記事を読むことをお勧めします。また、セルフアテンションアーキテクチャの基本的な理解も推奨されます。以下のJay Alammar氏のブログ記事は、元のトランスフォーマーモデルの復習として役立ちます。 このノートブックの執筆時点では、🤗Transformersには、T5、Bart、MarianMT、Pegasusのエンコーダーデコーダーモデルが含まれており、これらはモデルの要約についてはドキュメントで要約されています。 このノートブックは4つのパートに分かれています: 背景 – ニューラルエンコーダーデコーダーモデルの短い歴史がRNNベースのモデルに焦点を当てて与えられます。 エンコーダーデコーダー…
テキストの生成方法:トランスフォーマーを使用した言語生成のための異なるデコーディング方法の使用方法
はじめに 近年、大規模なトランスフォーマーベースの言語モデル(例えば、OpenAIの有名なGPT2モデル)が数百万のウェブページを学習することで、オープンエンドの言語生成に対する関心が高まっています。条件付きのオープンエンドの言語生成の結果は印象的です。例えば、ユニコーンに関するGPT2、XLNet、CTRLでの制御言語生成などです。改良されたトランスフォーマーアーキテクチャや大量の非教示学習データに加えて、より良いデコーディング手法も重要な役割を果たしています。 このブログ記事では、異なるデコーディング戦略の概要と、さらに重要なことに、人気のあるtransformersライブラリを使ってそれらを簡単に実装する方法を紹介します! 以下のすべての機能は、自己回帰言語生成に使用することができます(ここでは復習です)。要するに、自己回帰言語生成は、単語のシーケンスの確率分布を条件付き次の単語の分布の積として分解できるという仮定に基づいています: P(w1:T∣W0)=∏t=1TP(wt∣w1:t−1,W0) ,with w1:0=∅, P(w_{1:T} | W_0 ) = \prod_{t=1}^T P(w_{t} | w_{1: t-1}, W_0) \text{ ,with } w_{1: 0} = \emptyset, P(w1:T∣W0)=t=1∏TP(wt∣w1:t−1,W0) ,with w1:0=∅,…

エンコーダー・デコーダーモデルのための事前学習済み言語モデルチェックポイントの活用
Transformerベースのエンコーダーデコーダーモデルは、Vaswani et al.(2017)で提案され、最近ではLewis et al.(2019)、Raffel et al.(2019)、Zhang et al.(2020)、Zaheer et al.(2020)、Yan et al.(2020)などにおいて大きな関心を集めています。 BERTやGPT2と同様に、大規模な事前学習済みエンコーダーデコーダーモデルは、Lewis et al.(2019)、Raffel et al.(2019)などのさまざまなシーケンス対シーケンスのタスクにおいて性能を大幅に向上させることが示されています。しかし、エンコーダーデコーダーモデルの事前学習には膨大な計算コストがかかるため、そのようなモデルの開発は主に大企業や研究所に限定されています。 Sascha Rothe、Shashi Narayan、Aliaksei Severynによる「シーケンス生成タスクのための事前学習済みチェックポイントの活用」(2020)では、事前学習済みのエンコーダーやデコーダーのみのチェックポイント(例:BERT、GPT2)でエンコーダーデコーダーモデルを初期化して、コストのかかる事前学習をスキップする方法が紹介されています。著者らは、このようなウォームスタートされたエンコーダーデコーダーモデルが、T5やPegasusなどの大規模な事前学習済みエンコーダーデコーダーモデルと比較して、複数のシーケンス対シーケンスのタスクで競争力のある結果をもたらすことを示しています。 このノートブックでは、エンコーダーデコーダーモデルをウォームスタートする方法の詳細を説明し、Rothe et…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.