Learn more about Search Results HANA - Page 2

- You may be interested
- 「ターシャーに会ってください:GPT4のよ...
- オープンAIによるこの動きは、AGIへの道を...
- 実験から展開へ MLflow 101 | パート01
- ウェイト、バイアス、ロスのアンボクシン...
- 「IntelのOpenVINOツールキットを使用した...
- 「Q4 Inc.が、Q&Aチャットボットの構...
- 「ビッグデータパイプラインのデータ品質...
- 暗黙のフィードバックデータに対するレコ...
- 「大規模なモデルの時代のプログラマー」
- 物理情報を組み込んだDeepONetによるオペ...
- 「グラフ彩色の魅力的な世界を探索する」
- 「人間の偏見がAIによるソリューションを...
- ローカルで質問応答(QA)タスク用にLLMを...
- AIが生成したコンテンツは開発者のリスク...
- 「SDXL 1.0の登場」

「人工知能の炭素足跡」
AIの使用に起因する温室効果ガスの排出を削減する方法を探していますが、その使用は非常に増加する可能性があります

「2023年のトップデータウェアハウジングツール」
データウェアハウスは、データの報告、分析、および保存のためのデータ管理システムです。それはエンタープライズデータウェアハウスであり、ビジネスインテリジェンスの一部です。データウェアハウスには、1つ以上の異なるソースからのデータが保存されます。データウェアハウスは中央のリポジトリであり、複数の部門にわたる報告ユーザーが意思決定を支援するために設計された分析ツールです。データウェアハウスは、ビジネスや組織の歴史的なデータを収集し、それを評価して洞察を得ることができます。これにより、組織全体の統一された真実のシステムを構築するのに役立ちます。 クラウドコンピューティング技術のおかげで、ビジネスのためのデータウェアハウジングのコストと難しさは劇的に低下しました。以前は、企業はインフラに多額の投資をしなければなりませんでした。物理的なデータセンターは、クラウドベースのデータウェアハウスとそのツールに取って代わられています。多くの大企業はまだ古いデータウェアハウジングの方法を使用していますが、データウェアハウスが将来機能するのはクラウドであることは明らかです。使用料金ベースのクラウドベースのデータウェアハウジング技術は、迅速で効果的で非常にスケーラブルです。 データウェアハウスの重要性 現代のデータウェアハウジングソリューションは、データウェアハウスアーキテクチャの設計、開発、および導入の繰り返しのタスクを自動化することで、ビジネスの絶えず変化するニーズに対応しています。そのため、多くの企業がデータウェアハウスツールを使用して徹底的な洞察を獲得しています。 以上から、データウェアハウジングが大規模でボイジーサイズの企業にとって重要であることがわかります。データウェアハウスは、チームがデータにアクセスし、情報から結論を導き、さまざまなソースからデータを統合するのを支援します。その結果、企業はデータウェアハウスツールを以下の目標のために使用しています: 運用上および戦略上の問題について学ぶ。 意思決定とサポートのためのシステムを高速化する。 マーケティングイニシアチブの結果を分析し評価する。 従業員のパフォーマンスを分析する。 消費者のトレンドを把握し、次のビジネスサイクルを予測する。 市場で最も人気のあるデータウェアハウスツールは以下の通りです。 Amazon Redshift ビジネス向けのクラウドベースのデータウェアハウジングツールであるRedshiftです。完全に管理されたプラットフォームでペタバイト単位のデータを高速に処理できます。したがって、高速なデータ分析に適しています。さらに、自動の並列スケーリングがサポートされています。この自動化により、クエリ処理のリソースがワークロード要件に合わせて変更されます。オペレーションのオーバーヘッドがないため、同時に数百のクエリを実行できます。Redshiftはまた、クラスタをスケールアップしたりノードタイプを変更したりすることも可能です。その結果、データウェアハウスのパフォーマンスを向上させ、運用費用を節約することができます。 Microsoft Azure MicrosoftのAzure SQL Data Warehouseは、クラウドでホストされる関係データベースです。リアルタイムのレポート作成やペタバイト規模のデータの読み込みと処理に最適化されています。このプラットフォームは、大規模並列処理とノードベースのアーキテクチャ(MPP)を使用しています。このアーキテクチャは、並列処理のためのクエリの最適化に適しています。その結果、ビジネスインサイトの抽出と可視化が大幅に高速化されます。 データウェアハウスには数百のMS Azureリソースが互換性があります。たとえば、プラットフォームの機械学習技術を使用してスマートなアプリを作成することができます。さらに、IoTデバイスやオンプレミスのSQLデータベースなど、さまざまな種類の構造化および非構造化データをフォーラムに保存することができます。 Google BigQuery…

「Pythonによる(バイオ)イメージ解析:Matplotlibを使用して顕微鏡画像を読み込み、ロードする」
過去20年間、光学顕微鏡の分野は、共焦点レーザースキャニング顕微鏡(CLSM)などの画期的な技術の導入により、注目すべき進歩を遂げました...

「マーケティングからデータサイエンスへのキャリアチェンジ方法」
イントロダクション データの指数関数的な成長とデータに基づく意思決定の必要性により、マーケティングとデータサイエンスの交差点はますます重要になっています。多くの専門家がデータサイエンスへのキャリア転換を考えています。この記事では、マーケティングからデータサイエンスへの成功した転換をガイドします。 スキルギャップの評価 マーケティングからデータサイエンスへのキャリア転換を考える際には、これら2つの分野のスキルギャップを評価することが重要です。自分のスキルが一致する領域と追加の知識が必要な領域を理解することは、データサイエンティストへの成功への道筋を描くのに役立ちます。 データサイエンティストの役割に必要な主要なスキルと知識 データサイエンティストには、データ分析、プログラミング、統計、機械学習の専門知識など、多様なスキルセットが必要です。以下に、必要なすべてのスキルのリストを示します: 技術的なスキル PythonやRなどのプログラミング言語またはデータ言語 線形回帰やロジスティック回帰、ランダムフォレスト、決定木、SVM、KNNなどの機械学習アルゴリズム SAP HANA、MySQL、Microsoft SQL Server、Oracle Databaseなどのリレーショナルデータベース 自然言語処理(NLP)、光学文字認識(OCR)、ニューラルネットワーク、コンピュータビジョン、ディープラーニングなどの特殊スキル RShiny、ggplot、Plotly、Matplotlitなどのデータ可視化能力 Hadoop、MapReduce、Sparkなどの分散コンピューティング 分析スキル IBM Watson、OAuth、Microsoft AzureなどのAPIツール 実験とA/Bテスト 回帰、分類、時系列分析などの予測モデリングと統計概念 ドメイン知識…
.jpg)
「ACL 2023でのGoogle」
投稿者: Malaya Jules、プログラムマネージャー、Google 今週、自然言語処理に関する計算言語学の第61回年次総会(ACL)がオンラインで開催されます。ACLは、自然言語に対する計算的アプローチに関心のある広範な研究分野をカバーする主要な学会です。 自然言語処理と理解のリーダーであり、ACL 2023のダイヤモンドレベルのスポンサーであるGoogleは、50以上の研究発表とさまざまなワークショップやチュートリアルへの積極的な参加とともに、この分野の最新の研究を紹介します。 ACL 2023に登録されている場合、Googleブースにぜひお立ち寄りいただき、何十億もの人々のために興味深い問題を解決するためのGoogleのプロジェクトについて詳しく学んでいただければと思います。以下でGoogleの参加についてもっと詳しく知ることもできます(Googleの関連情報は太字で表示されます)。 ボードと組織委員会 エリアチェアには、Dan Garrette、ワークショップチェアには、Annie Louis、発表チェアには、Lei Shu、プログラム委員には、Vinodkumar Prabhakaran、Najoung Kim、Markus Freitagが含まれています。 注目論文 NusaCrowd: インドネシアNLPリソースのオープンソースイニシアチブ Samuel Cahyawijaya, Holy Lovenia, Alham…

RWKVとは、トランスフォーマーの利点を持つRNNの紹介です
ChatGPTとチャットボットを活用したアプリケーションは、自然言語処理(NLP)の領域で注目を集めています。コミュニティは、アプリケーションやユースケースに強力で信頼性の高いオープンソースモデルを常に求めています。これらの強力なモデルの台頭は、Vaswaniらによって2017年に最初に紹介されたトランスフォーマーベースのモデルの民主化と広範な採用によるものです。これらのモデルは、それ以降のSoTA NLPモデルである再帰型ニューラルネットワーク(RNN)ベースのモデルを大幅に上回りました。このブログ投稿では、RNNとトランスフォーマーの両方の利点を組み合わせた新しいアーキテクチャであるRWKVの統合を紹介します。このアーキテクチャは最近、Hugging Face transformersライブラリに統合されました。 RWKVプロジェクトの概要 RWKVプロジェクトは、Bo Peng氏が立ち上げ、リードしています。Bo Peng氏は積極的にプロジェクトに貢献し、メンテナンスを行っています。コミュニティは、公式のdiscordチャンネルで組織されており、パフォーマンス(RWKV.cpp、量子化など)、スケーラビリティ(データセットの処理とスクレイピング)、および研究(チャットの微調整、マルチモーダルの微調整など)など、さまざまなトピックでプロジェクトの成果物を常に拡張しています。RWKVモデルのトレーニングに使用されるGPUは、Stability AIによって寄付されています。 公式のdiscordチャンネルに参加し、RWKVの基本的なアイデアについて詳しく学ぶことで、参加することができます。以下の2つのブログ投稿で詳細を確認できます:https://johanwind.github.io/2023/03/23/rwkv_overview.html / https://johanwind.github.io/2023/03/23/rwkv_details.html トランスフォーマーアーキテクチャとRNN RNNアーキテクチャは、データのシーケンスを処理するための最初の広く使用されているニューラルネットワークアーキテクチャの1つであり、固定サイズの入力を取る従来のアーキテクチャとは異なります。RNNは、現在の「トークン」(つまり、データストリームの現在のデータポイント)、前の「状態」を入力として受け取り、次のトークンと次の状態を予測します。新しい状態は、次のトークンの予測を計算するために使用され、以降も同様に続きます。RNNは異なる「モード」でも使用できるため、Andrej Karpathy氏のブログ投稿で示されているように、1対1(画像分類)、1対多(画像キャプション)、多対1(シーケンス分類)、多対多(シーケンス生成)など、さまざまなシナリオでRNNを適用することが可能です。 RNNは、各ステップで予測を計算するために同じ重みを使用するため、勾配消失の問題により長距離のシーケンスに対する情報の記憶に苦労します。この制限に対処するために、LSTMやGRUなどの新しいアーキテクチャが導入されましたが、トランスフォーマーアーキテクチャはこの問題を解決するためにこれまでで最も効果的なものとなりました。 トランスフォーマーアーキテクチャでは、入力トークンは自己注意モジュールで同時に処理されます。トークンは、クエリ、キー、値の重みを使用して異なる空間に線形にプロジェクションされます。結果の行列は、アテンションスコアを計算するために直接使用され、その後値の隠れ状態と乗算されて最終的な隠れ状態が得られます。この設計により、アーキテクチャは長距離のシーケンスの問題を効果的に緩和し、RNNモデルと比較して推論とトレーニングの速度も高速化します。 トランスフォーマーアーキテクチャは、トレーニング中に従来のRNNおよびCNNに比べていくつかの利点があります。最も重要な利点の1つは、文脈的な表現を学習できる能力です。RNNやCNNとは異なり、トランスフォーマーアーキテクチャは単語ごとではなく、入力シーケンス全体を処理します。これにより、シーケンス内の単語間の長距離の依存関係を捉えることができます。これは、言語翻訳や質問応答などのタスクに特に有用です。 推論中、RNNは速度とメモリ効率の面でいくつかの利点があります。これらの利点には、単純さ(行列-ベクトル演算のみが必要)とメモリ効率(推論中にメモリ要件が増えない)が含まれます。さらに、現在のトークンと状態にのみ作用するため、コンテキストウィンドウの長さに関係なく計算速度が同じままです。 RWKVアーキテクチャ RWKVは、AppleのAttention Free Transformerに触発されています。アーキテクチャは注意深く簡素化され、最適化されており、RNNに変換することができます。さらに、TokenShiftやSmallInitEmbなどのトリックが追加されています(公式のGitHubリポジトリのREADMEにトリックのリストが記載されています)。これにより、モデルのパフォーマンスがGPTに匹敵するように向上しています。現在、トレーニングを14Bパラメータまでスケーリングするためのインフラストラクチャがあり、RWKV-4(本日の最新バージョン)では数値の不安定性など、いくつかの問題が反復的に修正されました。 RNNとトランスフォーマーの組み合わせとしてのRWKV…
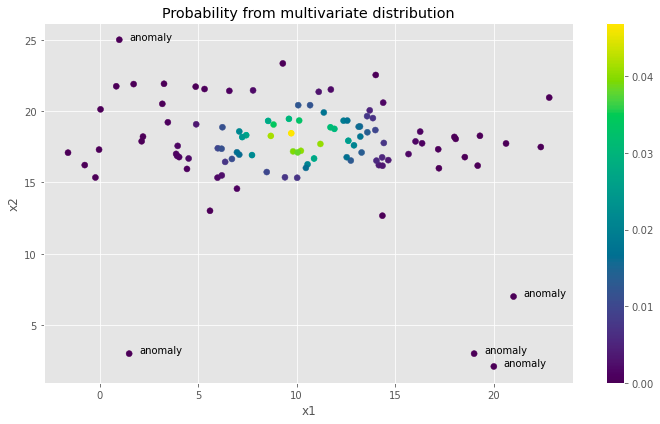
多変量ガウス分布による異常検知の基本
私たちの生まれつきのパターン認識能力によって、私たちはこのスキルを使って抜け落ちた部分を埋めたり、次に何が起こるかを予測したりすることができますしかし時折、私たちの予測に合わないことが起こります...

データアナリストからデータサイエンティストへのキャリアチェンジの方法は?
人々は常にデータを扱っており、データアナリストは専門知識を身につけた後、よりチャレンジングな役割を求めています。データサイエンティストは、最も収益性の高いキャリアオプションの1つとされています。スキルセットの拡大が必要ですが、いくつかの教育プラットフォームが変化に有益な洞察を提供しています。多くのデータアナリストが成功して転身していますし、あなたも次の転身者になることができます! 以下のステップは、データサイエンティストとしてのキャリアをスタートさせる際に、企業の成長に貢献し、専門知識を増やすのに役立ちます: スキルギャップの評価 データサイエンティストの役割に必要な基本的なスキルと知識 データサイエンティストはデータを実験する必要があるため、新しいアイデアや研究を開発するマインドセットが重要です。過去の実験のミスを分析する能力も同様に重要です。これに加えて、以下のような技術スキルと知識が求められます: 技術スキル: PythonやRなどのプログラミング言語やデータ言語 線形回帰やロジスティック回帰、ランダムフォレスト、決定木、SVM、KNNなどの機械学習アルゴリズム SAP HANA、MySQL、Microsoft SQL Server、Oracle Databaseなどのリレーショナルデータベース Natural Language Processing(NLP)、Optical Character Recognition(OCR)、Neural networks、computer vision、deep learningなどの特殊なスキル RShiny、ggplot、Plotly、Matplotlitなどのデータ可視化能力 Hadoop、MapReduce、Sparkなどの分散コンピューティング 分析スキル:…

CVPR 2023におけるGoogle
Googleのプログラムマネージャー、Shaina Mehtaが投稿しました 今週は、バンクーバーで開催される最も重要なコンピュータビジョンとパターン認識の年次会議であるCVPR 2023の始まりを迎えます(追加のバーチャルコンテンツもあります)。Google Researchはコンピュータビジョンの研究のリーダーであり、プラチナスポンサーであり、メインカンファレンスで約90の論文が発表され、40以上のカンファレンスワークショップやチュートリアルに積極的に参加しています。 今年のCVPRに参加する場合は、是非、ブースに立ち寄って、最新のマシンパーセプションの様々な分野に応用するための技術を積極的に探求している研究者とお話ししてください。弊社の研究者は、MediaPipeを使用したオンデバイスのMLアプリケーション、差分プライバシーの戦略、ニューラル輝度場技術など、いくつかの最近の取り組みについても話し、デモを行います。 以下のリストでCVPR 2023で発表される弊社の研究についても詳しくご覧いただけます(Googleの所属は太字で表示されています)。 理事会と組織委員会 シニアエリアチェアには、Cordelia Schmid、Ming-Hsuan Yangが含まれます。 エリアチェアには、Andre Araujo、Anurag Arnab、Rodrigo Benenson、Ayan Chakrabarti、Huiwen Chang、Alireza Fathi、Vittorio Ferrari、Golnaz Ghiasi、Boqing Gong、Yedid Hoshen、Varun Jampani、Lu…

Glassdoorの解読:情報に基づく意思決定のためのNLP駆動Insights
はじめに 現代の厳しい就職市場において、個人は情報を収集して適切なキャリアの決定をする必要があります。Glassdoor は、従業員が匿名で自分たちの経験を共有する人気のプラットフォームです。しかし、口コミの豊富さは求職者を圧倒することがあります。この問題に対処するため、Glassdoor のレビューを洞察に富んだ要約に自動的に縮小する NLP 駆動のシステムを構築しようと試みます。このプロジェクトでは、レビュー収集のために Selenium を使用してから要約化のために NLTK を活用するまで、ステップバイステップのプロセスを探求します。これらの簡潔な要約は、企業文化や成長機会に関する貴重な洞察を提供し、キャリアの目標を適切な組織に調整するのに役立ちます。また、解釈の違いやデータ収集のエラーなどの限界についても議論し、要約化プロセスを包括的に理解できるようにしています。 学習目標 このプロジェクトの学習目標は、多量の Glassdoor レビューを簡潔かつ情報豊富な要約に効果的に縮小する堅牢なテキスト要約システムを開発することです。このプロジェクトに取り組むことで、次のことができます。 公開プラットフォーム(この場合は Glassdoor)からレビューを要約する方法と、求職者が求職を受け入れる前に組織を評価するのにどのように役立つかを理解し、自動要約技術が必要であるという課題に気づく。 Python の Selenium ライブラリを活用して Glassdoor からデータを抽出するためのウェブスクレイピングの基礎を学び、ウェブページのナビゲーション、要素の操作、テキストデータの取得などを探求する。 Glassdoor のレビューから抽出されたテキストデータをクリーニングして準備するスキルを開発する。ノイズの処理、関係のない情報の削除、入力データの品質を確保して効果的な要約を実現する方法を実装する。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.