Learn more about Search Results Guanaco - Page 2

- You may be interested
- AI/MLを活用した観測性の向上
- 「AIと教育の公平性:ギャップを埋めるた...
- 「Pythonを使用してPDFファイルからテキス...
- 「NVIDIAは3DワールドのためのOpenUSD標準...
- 「2023年9月のベストデータ抽出ツール10選」
- ビデオゲームのGPUが人工知能の発展につな...
- パイソンによる機械学習エンジニアのため...
- 最高のウイルス対策ソフトウェア2023年
- 「暖かい抱擁の向こう側:ハグの奥深くに...
- AIツールが超新星を発見します
- 教えることは難しい:小さなモデルを訓練...
- 「グラフ機械学習 @ ICML 2023」
- Segmind APIsを使用した安定した拡散モデ...
- MLにおけるETLデータパイプラインの構築方法
- 2023年10月:オクタが新しいアイデ...
「GPT-4に対する無料の代替案トップ5」
GPT-4がすごいと思っている?これらの生成AIの新参者たちは既に注目を集めているよ!
「LLM Fine-Tuningの理解:大規模言語モデルを独自の要件に合わせる方法」
「Llama 2のような大規模言語モデル(LLM)の微調整技術の最新の進展を探索してくださいLow-Rank Adaptation(LoRA)やQuantized LoRA(QLoRA)などの技術が、新しい利用におけるモデルの適応を革新している方法を学びましょう最後に、人間のフィードバックからの強化学習による微調整が、LLMをより人間の価値観に近づける方法にどのように影響しているかを見てみましょう」

PyTorch FSDPを使用してLlama 2 70Bのファインチューニング
はじめに このブログ記事では、PyTorch FSDPと関連するベストプラクティスを使用して、Llama 2 70Bを微調整する方法について説明します。Hugging Face Transformers、Accelerate、およびTRLを活用します。また、AccelerateをSLURMと一緒に使用する方法も学びます。 Fully Sharded Data Parallelism(FSDP)は、オプティマイザの状態、勾配、およびパラメータをデバイス間でシャードするパラダイムです。フォワードパスでは、各FSDPユニットが完全な重みを取得するための全ギャザー操作を実行し、計算が行われた後に他のデバイスからのシャードを破棄します。フォワードパスの後、ロスが計算され、バックワードパスが行われます。バックワードパスでは、各FSDPユニットが完全な重みを取得するための全ギャザー操作を実行し、ローカルな勾配を取得するための計算が行われます。これらのローカルな勾配は平均化され、リダクション-スキャッタ操作を介してデバイス間でシャードされるため、各デバイスは自身のシャードのパラメータを更新することができます。PyTorch FSDPの詳細については、次のブログ記事を参照してください:PyTorch Fully Sharded Data Parallelを使用した大規模モデルトレーニングの加速。 (出典: リンク) 使用されたハードウェア ノード数:2。最小要件は1です。ノードあたりのGPU数:8。GPUタイプ:A100。GPUメモリ:80GB。ノード内接続:NVLink。ノードあたりのRAM:1TB。ノードあたりのCPUコア数:96。ノード間接続:Elastic Fabric Adapter。 LLaMa 70Bの微調整における課題…

「Llama 2内のストップ生成の課題」
メタによるLlama 2の発売は、コミュニティ内で興奮を引き起こし、以前は...を通じてのみアクセス可能だった優れた大規模言語モデルの時代の幕開けを告げています
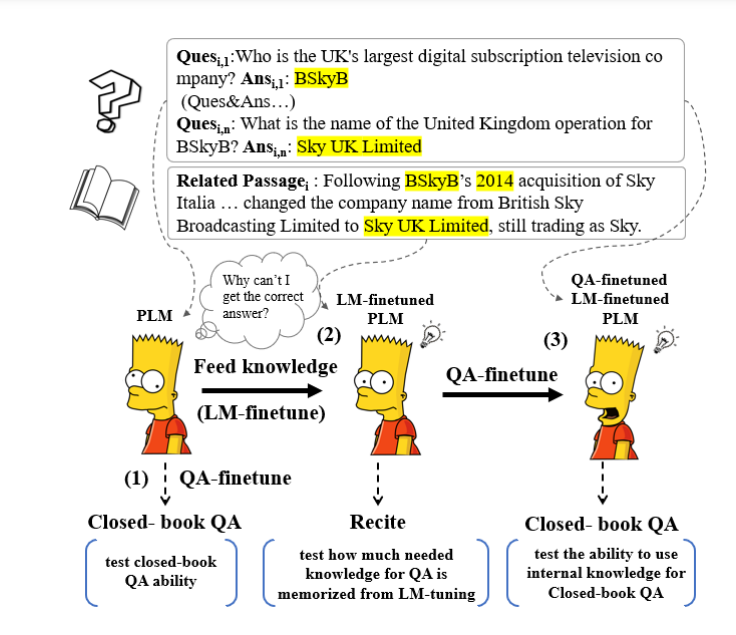
「大規模な言語モデルの探索-パート3」
「この記事は主に自己学習のために書かれていますしたがって、広く深く展開されています興味のあるセクションをスキップしたり、自分が興味を持っている分野を探求するために、自由に進めてください以下にはいくつかの...」

メタAIのハンプバック!LLMの自己整列と指示逆翻訳による大きな波を起こしています
大規模言語モデル(LLM)は、コンテキスト学習や思考の連鎖など、優れた一般化能力を示しています。LLMが自然言語の指示に従い、現実世界のタスクを完了するために、研究者はLLMの指示調整方法を探求しています。これは、人間の注釈付きプロンプトやフィードバック、または公開ベンチマークとデータセットを使用した監督微調整など、さまざまな関数でモデルを微調整することで実現されます。最近の研究では、人間の注釈データの品質の重要性が強調されています。しかし、そのような品質のデータセットに従って指示を注釈付けすることは、スケールするのが難しいことがわかっています。 この解決策は、LLMとの自己整列を扱います。つまり、モデルを利用して自身を改善し、モデルが書かれたフィードバック、批判、説明などの望ましい振る舞いに応じて応答を整列させることです。Meta AIの研究者は、自己整列による指示付きバックトランスレーションを紹介しました。基本的なアイデアは、大規模言語モデルを使用してWebテキストに対応する指示を自動的にラベル付けすることです。 セルフトレーニングのアプローチでは、ベースとなる言語モデル、ラベルのない例のコレクション(例えば、Webコーパス)、および少量のシードデータにアクセスできることが前提とされます。この方法の第一の前提は、この大量の人間によって書かれたテキストの一部は、いくつかのユーザー指示のための良い生成物として有用であるということです。第二の前提は、これらの応答に対して指示を予測できるということであり、これを使用して高品質の例のペアを使用して指示に従うモデルをトレーニングすることができます。 指示付きバックトランスレーション全体は、以下の手順に分割できます: セルフオーグメント:ラージ言語モデルMeta AI(LLaMA)を使用して、ラベルの付いていないデータ(Webコーパスなど)のための「良い指示」を生成し、指示の調整のためのトレーニングデータ(指示、出力のペア)を生成します。 セルフクリエイト:LLaMAを使用して生成されたデータを評価します。 そして、このデータを使用してLLaMAを微調整し、手順を繰り返して改良されたモデルを使用します。その結果、トレーニングされたLlamaベースの指示バックトランスレーションモデルは、「ハンプバック」と呼ばれました(クジラの大規模性にちなんでいます)。 「ハンプバック」は、アルパカリーダーボードのClaude、Guanaco、Falcon-Instruct、LIMAなどに関して、すべての既存の非蒸留モデルを上回りました。 現在の手順の欠点は、高度なデータがWebコーパスから派生しているため、微調整モデルはウェブデータのバイアスを強調する可能性があるということです。結論として、この方法はトレーニングデータがなくなることは絶対にありませんし、大規模言語モデルに指示に従うための堅牢なスケーラブルなアプローチを提供します。今後の課題は、より大きな未ラベルのコーパスを考慮することで、さらなる利益が得られる可能性があることです。
次回のLLM(法務修士)の申請に使用するためのトップ10のオープンソースLLM
大規模言語モデルをベースにしたアプリケーションは、OpenAIがChatGPTをリリースしてから過去10か月間で注目されてきましたそれ以降、多くの企業やスタートアップがアプリケーションを立ち上げ、...

「QLORAとは:効率的なファインチューニング手法で、メモリ使用量を削減し、単一の48GB GPUで65Bパラメーターモデルをファインチューニングできるだけでなく、完全な16ビットのファインチューニングタスクのパフォーマンスも保持します」
大規模言語モデル(LLM)は、追加または削除したい振る舞いを設定することも可能にするファインチューニングによって改善することができます。しかし、大きなモデルのファインチューニングは非常に高コストです。例えば、LLaMA 65Bパラメータモデルを標準の16ビットモードでファインチューニングすると、780GB以上のGPU RAMを消費します。最新の量子化手法はLLMのメモリフットプリントを軽減することができますが、これらの手法は推論時にのみ機能し、トレーニング時には失敗します。ワシントン大学の研究者たちは、QLORAを開発しました。QLORAは、高精度なアルゴリズムを使用して事前学習モデルを4ビットの解像度に量子化し、量子化結果に対する勾配を逆伝播させることで変更した一連の学習可能な低ランクアダプターの重みを追加します。彼らは、量子化された4ビットモデルがパフォーマンスに影響を与えずに調整できることを初めて示しています。 QLORAによって、65Bパラメータモデルのファインチューニングの平均メモリ要件を、ランタイムや予測パフォーマンスを犠牲にすることなく、16ビットの完全にファインチューニングされたベースラインから780GB以上のGPU RAMから48GBに削減することができます。これにより、これまでに公開されている最大のモデルでも単一のGPUでファインチューニングすることが可能となり、LLMのファインチューニングのアクセシビリティに大きな変化がもたらされます。彼らはQLORAを使用してGuanacoモデルファミリーを訓練し、最大のモデルは単一のプロフェッショナルGPUで24時間以上かけて99.3%の成績を達成し、VicunaベンチマークでのChatGPTに迫る成果を上げました。2番目に優れたモデルは、単一のコンシューマGPUで12時間未満の時間で、VicunaベンチマークでChatGPTのパフォーマンスレベルの97.8%に達します。 QLORAの以下の技術は、パフォーマンスを損なうことなくメモリ使用量を低減することを目的としています:(1) 4ビットNormalFloat、正規分布データのための量子化データ型であり、情報理論的に最適であり、4ビットの整数と4ビットの浮動小数点よりも優れた経験的な結果を生み出します。(2) ダブル量子化は、平均してパラメータごとに0.37ビット(または65Bモデルの約3GB)を節約し、量子化定数を量子化します。(3) ページドオプティマイザは、長いシーケンスを処理する際に勾配チェックポイントによるメモリスパイクを防ぐために、NVIDIA統一メモリを使用します。使用すると、最小のGuanacoモデル(7Bパラメータ)は、Vicunaテストで26GBのAlpacaモデルを20パーセント以上上回る性能を発揮しながら、5GB未満のメモリを使用します。 彼らはこれらの貢献をより洗練されたLoRA戦略に組み込み、以前の研究で特定された精度のトレードオフをほぼなくすようにしました。QLORAの効率性により、メモリコストのために従来のファインチューニングではできなかったモデルサイズに関する指示ファインチューニングとチャットボットのパフォーマンスをより詳細に分析することができます。その結果、彼らは80Mから65Bまでの様々な指示チューニングデータセット、モデルトポロジ、パラメータ値を使用して、1000以上のモデルをトレーニングしました。QLORAは16ビットのパフォーマンスを回復し、Guanacoという高度なチャットボットをトレーニングし、学習されたモデルのパターンを調査しました。 まず、両方が汎化後の指示を提供することを目的としているにもかかわらず、チャットボットのパフォーマンスでは、データの品質がデータセットのサイズよりもはるかに重要であることを発見しました。9kサンプルのデータセット(OASST1)は、チャットボットのパフォーマンスで450kサンプルのデータセット(FLAN v2、サブサンプリング)を上回ります。第二に、優れたMassive Multitask Language Understanding(MMLU)ベンチマークのパフォーマンスが必ずしも優れたVicunaチャットボットベンチマークのパフォーマンスにつながるわけではないこと、そしてその逆もまた同様であることを示しています。言い換えれば、特定のタスクにおいては、データセットの適切さがスケールよりも重要です。彼らはまた、人間の評価者とGPT-4を使用してチャットボットのパフォーマンスを詳細に評価しています。 モデルは、与えられた刺激に対する最適な応答を決定するために、トーナメント形式のベンチマークマッチで互いに競い合います。GPT-4または人間の注釈者がゲームの勝者を決定します。トーナメントの中でのモデルのパフォーマンスのランク付けには、GPT-4と人間の判断がほぼ一致することがわかりましたが、明確な相違点もあります。そのため、彼らはモデルベースの評価が不確実性を持つ一方で、人間の注釈よりも費用が抑えられるという事実に注意を喚起しています。 彼らはチャットボットのベンチマーク調査結果にグアナコモデルの質的分析を追加します。彼らの研究では、定量的な基準では考慮されなかった成功と失敗のインスタンスを特定します。彼らはGPT-4および人間のコメントを含むすべてのモデル世代を公開し、将来の研究を支援します。彼らは自分たちの技術をHugging Face transformersスタックに組み込み、ソフトウェアおよびCUDAカーネルをオープンソース化し、広く利用可能にします。32の異なるオープンソース化された改良モデルについて、サイズ7/13/33/65Bのモデルに8つの異なる命令従属データセットでトレーニングを行ったアダプターのコレクションを提供します。コードリポジトリは公開され、Colabでホストできるデモも提供されます。

「Llama 2が登場しました – Hugging Faceで手に入れましょう」
はじめに Llama 2は、Metaが本日リリースした最新のオープンアクセスの大規模言語モデルのファミリーです。私たちはHugging Faceとの包括的な統合を完全にサポートすることで、このリリースを支援しています。Llama 2は非常に寛容なコミュニティライセンスでリリースされ、商業利用も可能です。コード、事前学習モデル、ファインチューニングモデルはすべて本日リリースされます🔥 私たちはMetaとの協力により、Hugging Faceエコシステムへのスムーズな統合を実現しています。Hubで12のオープンアクセスモデル(3つのベースモデルと3つのファインチューニングモデル、オリジナルのMetaチェックポイントを含む)を見つけることができます。リリースされる機能と統合の中には、以下のものがあります: モデルカードとライセンスを備えたHub上のモデル。 Transformersの統合 単一のGPUを使用してモデルの小さなバリアントをファインチューニングするための例 高速かつ効率的なプロダクションレディの推論のためのテキスト生成インファレンスとの統合 インファレンスエンドポイントとの統合 目次 Llama 2を選ぶ理由 デモ インファレンス Transformersを使用する場合 インファレンスエンドポイントを使用する場合 PEFTによるファインチューニング 追加リソース 結論 Llama 2を選ぶ理由…

RWKVとは、トランスフォーマーの利点を持つRNNの紹介です
ChatGPTとチャットボットを活用したアプリケーションは、自然言語処理(NLP)の領域で注目を集めています。コミュニティは、アプリケーションやユースケースに強力で信頼性の高いオープンソースモデルを常に求めています。これらの強力なモデルの台頭は、Vaswaniらによって2017年に最初に紹介されたトランスフォーマーベースのモデルの民主化と広範な採用によるものです。これらのモデルは、それ以降のSoTA NLPモデルである再帰型ニューラルネットワーク(RNN)ベースのモデルを大幅に上回りました。このブログ投稿では、RNNとトランスフォーマーの両方の利点を組み合わせた新しいアーキテクチャであるRWKVの統合を紹介します。このアーキテクチャは最近、Hugging Face transformersライブラリに統合されました。 RWKVプロジェクトの概要 RWKVプロジェクトは、Bo Peng氏が立ち上げ、リードしています。Bo Peng氏は積極的にプロジェクトに貢献し、メンテナンスを行っています。コミュニティは、公式のdiscordチャンネルで組織されており、パフォーマンス(RWKV.cpp、量子化など)、スケーラビリティ(データセットの処理とスクレイピング)、および研究(チャットの微調整、マルチモーダルの微調整など)など、さまざまなトピックでプロジェクトの成果物を常に拡張しています。RWKVモデルのトレーニングに使用されるGPUは、Stability AIによって寄付されています。 公式のdiscordチャンネルに参加し、RWKVの基本的なアイデアについて詳しく学ぶことで、参加することができます。以下の2つのブログ投稿で詳細を確認できます:https://johanwind.github.io/2023/03/23/rwkv_overview.html / https://johanwind.github.io/2023/03/23/rwkv_details.html トランスフォーマーアーキテクチャとRNN RNNアーキテクチャは、データのシーケンスを処理するための最初の広く使用されているニューラルネットワークアーキテクチャの1つであり、固定サイズの入力を取る従来のアーキテクチャとは異なります。RNNは、現在の「トークン」(つまり、データストリームの現在のデータポイント)、前の「状態」を入力として受け取り、次のトークンと次の状態を予測します。新しい状態は、次のトークンの予測を計算するために使用され、以降も同様に続きます。RNNは異なる「モード」でも使用できるため、Andrej Karpathy氏のブログ投稿で示されているように、1対1(画像分類)、1対多(画像キャプション)、多対1(シーケンス分類)、多対多(シーケンス生成)など、さまざまなシナリオでRNNを適用することが可能です。 RNNは、各ステップで予測を計算するために同じ重みを使用するため、勾配消失の問題により長距離のシーケンスに対する情報の記憶に苦労します。この制限に対処するために、LSTMやGRUなどの新しいアーキテクチャが導入されましたが、トランスフォーマーアーキテクチャはこの問題を解決するためにこれまでで最も効果的なものとなりました。 トランスフォーマーアーキテクチャでは、入力トークンは自己注意モジュールで同時に処理されます。トークンは、クエリ、キー、値の重みを使用して異なる空間に線形にプロジェクションされます。結果の行列は、アテンションスコアを計算するために直接使用され、その後値の隠れ状態と乗算されて最終的な隠れ状態が得られます。この設計により、アーキテクチャは長距離のシーケンスの問題を効果的に緩和し、RNNモデルと比較して推論とトレーニングの速度も高速化します。 トランスフォーマーアーキテクチャは、トレーニング中に従来のRNNおよびCNNに比べていくつかの利点があります。最も重要な利点の1つは、文脈的な表現を学習できる能力です。RNNやCNNとは異なり、トランスフォーマーアーキテクチャは単語ごとではなく、入力シーケンス全体を処理します。これにより、シーケンス内の単語間の長距離の依存関係を捉えることができます。これは、言語翻訳や質問応答などのタスクに特に有用です。 推論中、RNNは速度とメモリ効率の面でいくつかの利点があります。これらの利点には、単純さ(行列-ベクトル演算のみが必要)とメモリ効率(推論中にメモリ要件が増えない)が含まれます。さらに、現在のトークンと状態にのみ作用するため、コンテキストウィンドウの長さに関係なく計算速度が同じままです。 RWKVアーキテクチャ RWKVは、AppleのAttention Free Transformerに触発されています。アーキテクチャは注意深く簡素化され、最適化されており、RNNに変換することができます。さらに、TokenShiftやSmallInitEmbなどのトリックが追加されています(公式のGitHubリポジトリのREADMEにトリックのリストが記載されています)。これにより、モデルのパフォーマンスがGPTに匹敵するように向上しています。現在、トレーニングを14Bパラメータまでスケーリングするためのインフラストラクチャがあり、RWKV-4(本日の最新バージョン)では数値の不安定性など、いくつかの問題が反復的に修正されました。 RNNとトランスフォーマーの組み合わせとしてのRWKV…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.