Learn more about Search Results G-Eval - Page 2

- You may be interested
- タイム100 AI:最も影響力のあるもの?
- 「私はChatGPTのコードインタプリタに乱雑...
- 音楽作曲における創造的なジェネレーティ...
- 「CVPR 2023のメモ」
- 「音のシンフォニーを解読する:音楽工学...
- 「個人データへのアクセス」
- アルファベットは、遠隔地域でのインター...
- 「砂の下を泳ぐ赤ちゃんカメに触発された...
- 「人工知能の暗黒面」
- 活性化関数と非線形性:ニューラルネット...
- BERTopic(バートピック):v0.16の特別さ...
- Field Programmable Gate Array(FPGA)と...
- 「E.U.法がディスインフォメーション...
- 「ODSC Westでの対面トレーニングがチーム...
- フルスケールのゲームプレイ:「ドラゴン...

「機械学習の謎を解く」
この記事は、機械学習の本質、基本的な概念、高レベルの機械学習プロセスについての理解を深めることを目的としています

「ノイズのある量子プロセッサをクラシカルコンピュータと比較する方法」
Google Quantum AIチームの主任研究員であるセルヒオ・ボイショとヴァディム・スメリャンスキーによる投稿 完全なスケールのエラー訂正量子コンピュータは、古典コンピュータでは不可能な問題を解決することができますが、そのようなデバイスを構築することは非常に困難です。私たちは完全にエラー訂正された量子コンピュータに向けて達成したマイルストーンに誇りを持っていますが、大規模なコンピュータはまだ数年先です。一方、私たちは現在のノイズのある量子プロセッサを柔軟なプラットフォームとして量子実験に活用しています。 エラー訂正された量子コンピュータとは異なり、ノイズのある量子プロセッサでの実験は、ノイズが量子状態を劣化させる前に数千回の量子操作またはゲートに制限されています。2019年に、私たちはランダム回路サンプリングという特定の計算タスクを量子プロセッサで実装し、それが最先端の古典超並列計算を上回ることを初めて示しました。 彼らはまだ古典的な能力を超えていませんが、私たちはまた、時間結晶やマヨラナエッジモードなどの新しい物理現象を観察するためにプロセッサを使用し、相互作用する光子の堅牢な束縛状態やフロケ進化のマヨラナエッジモードのノイズ耐性などの新しい実験的な発見をしました。 私たちは、この中間のノイズ領域でも、量子プロセッサを使って有用な量子実験を古典的な超並列計算よりもはるかに高速に実行できるアプリケーションを見つけると予想しています。これを「計算アプリケーション」と呼んでいます。まだ誰もこのような超古典的な計算アプリケーションを実証していません。したがって、このマイルストーンを達成するための問題は、量子プロセッサで実行された量子実験を古典的なアプリケーションの計算コストと比較する最良の方法は何かということです。 エラー訂正された量子アルゴリズムと古典的なアルゴリズムを比較する方法はすでにわかっています。その場合、計算複雑性の分野から、それらの相互の計算コスト(つまり、タスクを達成するために必要な操作の回数)を比較できることがわかります。しかし、現在の実験的な量子プロセッサでは、状況はそれほど明確ではありません。 「ノイズのある量子処理実験の計算コストの効果的な量子ボリューム、信頼性、および計算コスト」では、量子実験の計算コストを測定するためのフレームワークを提供し、実験の「効果的な量子ボリューム」を導入します。これは、測定結果に寄与する量子操作またはゲートの数です。私たちはこのフレームワークを適用して、最近の3つの実験の計算コストを評価します:ランダム回路サンプリング実験、アウトオブタイムオーダーコレレータ(OTOC)と呼ばれる量を測定する実験、およびイジングモデルに関連するフロケ進化の最新の実験。私たちは特にOTOCに興奮しています。なぜなら、OTOCは回路(量子ゲートまたは操作のシーケンス)の効果的な量子ボリュームを実験的に測定する直接的な方法を提供し、これは古典的なコンピュータにとって正確に推定するのが難しい計算的なタスクです。OTOCはまた、核磁気共鳴や電子スピン共鳴分光学においても重要です。したがって、私たちはOTOC実験が量子プロセッサの初の計算アプリケーションの有望な候補であると考えています。 計算コストといくつかの最近の量子実験の影響のプロット。一部(例:QC-QMC 2022)は高い影響力を持ち、他の一部(例:RCS 2023)は高い計算コストを持っていますが、まだ有用で十分に困難なものはありません。私たちの将来のOTOC実験がこの閾値を初めて超える可能性があると推測しています。プロットされた他の実験は、テキストで参照されています。 ランダム回路サンプリング:ノイズのある回路の計算コストの評価 ノイズのある量子プロセッサで量子回路を実行する場合、2つの競合する考慮事項があります。一方では、古典的に達成するのが困難なことを行いたいと考えています。計算コスト(古典的なコンピュータでタスクを達成するために必要な操作の数)は、量子回路の効果的な量子ボリュームに依存します。ボリュームが大きいほど、計算コストが高くなり、量子プロセッサが古典的なものを上回ることができます。 しかし、一方で、ノイズの多いプロセッサでは、各量子ゲートが計算に誤りを導入することがあります。操作が多いほど誤りが増え、興味のある量を測定する量子回路の信頼性が低下します。この考慮に基づいて、効果的な体積が小さく、クラシックコンピュータで簡単にシミュレートできるような単純な回路を選ぶことがあります。最大化したいこれら競合する要素のバランスを、「計算リソース」と呼びます。以下に示します。 量子回路の量子体積とノイズのトレードオフを示したグラフであり、これは「計算リソース」と呼ばれる量で捉えられます。ノイズの多い量子回路では、計算コストとともにこれは初めは増加しますが、やがてノイズが回路を制御し、減少させます。 これら競合する要素がどのように影響するかは、量子プロセッサの単純な「ハローワールド」プログラムであるランダム回路サンプリング(RCS)によって明らかになります。このプログラムは、量子プロセッサがクラシックコンピュータを上回る最初のデモンストレーションでした。ゲートのいかなるエラーもこの実験を失敗させる可能性があります。必然的に、これは高い信頼性で達成することの難しい実験であり、システムの信頼性の基準ともなります。しかし、これはまた、量子プロセッサによって達成可能な既知の最も高い計算コストに対応しています。私たちは最近、これまでで最も強力なRCS実験を報告しました。その実験では、低い測定実験的信頼性が1.7×10-3であり、高い理論的計算コストが約1023です。これらの量子回路には700の2量子ビットゲートがあります。この実験を世界最大のスーパーコンピュータでシミュレートするには約47年かかると推定されています。これは、計算アプリケーションに必要な2つの要件のうちの1つを満たしていますが、それ自体は特に有用なアプリケーションではありません。 OTOCとフロケエボリューション:局所観測量の効果的な量子体積 量子多体物理学にはクラシカルに解けない問題が多く存在し、これらの実験のいくつかを量子プロセッサ上で実行することには大きな潜在能力があります。通常、RCS実験とは異なる視点でこれらの実験を考えます。実験の終わりにすべてのキュビットの量子状態を測定するのではなく、通常は特定の局所物理観測量に関心があります。回路内のすべての操作が観測量に影響を与えるわけではないため、局所観測量の効果的な量子体積は、実験を実行するために必要なフル回路の体積よりも小さくなる場合があります。 これは、相対性理論からの光錐の概念を適用することで理解することができます。光錐は、時空内のどのイベントが因果関係を持つ可能性があるかを決定するものであり、情報がそれらの間を伝播するのに時間がかかるため、一部のイベントはお互いに影響を与えることはできません。このような2つのイベントはそれぞれの光錐の外にあります。量子実験では、光錐を「バタフライコーン」というものに置き換えます。その成長はバタフライ速度によって決まります。バタフライ速度はシステム全体に情報が広がる速度を表します(これは後述のOTOCによって特徴付けられます)。局所観測量の効果的な量子体積は、本質的にはバタフライコーンの体積であり、観測量に因果関係を持つ量子操作のみを含みます。したがって、情報がシステム内で広がる速度が速いほど、効果的な体積は大きくなり、クラシック的にシミュレートするのはより困難になります。 局所観測量Bに寄与するゲートの効果的な体積Veffの描写です。関連する量である効果的な面積Aeffは、平面とコーンの断面で表されています。底辺の周囲はバタフライ速度vBで移動する情報の前面に対応しています。 このフレームワークを最近の実験に適用し、いわゆるFloquet Isingモデル、時間結晶およびMajorana実験に関連する物理モデルを実装しました。この実験のデータから、最大回路に対して有効な信頼性を0.37と直接推定することができます。測定されたゲートエラーレートは約1%であり、これにより推定される有効なボリュームは約100となります。これは、127量子ビットに2,000のゲートが含まれるライトコーンよりもはるかに小さくなります。したがって、この実験のバタフライ速度は非常に小さいです。実験よりも大きな精度を得る数値シミュレーションを使用して、この小さな有効なボリュームが127ではなく約28の量子ビットのみをカバーしていることも確認されました。この小さな有効ボリュームはOTOC技術によっても裏付けられています。これは深い回路であったにもかかわらず、推定される計算コストは5×10^11であり、最近のRCS実験のおよそ1兆分の1です。それに対応して、この実験は単一のA100 GPU上のデータポイントごとに1秒未満でシミュレートすることができます。したがって、これは確かに有用なアプリケーションであるものの、計算アプリケーションの2番目の要件を満たしていません:古典的なシミュレーションを大幅に上回ること。…

ランキングアルゴリズム入門
ランキング学習(LTR)は、クエリに対する関連性に基づいてアイテムのリストを並べ替えることを目的とした、教師あり機械学習アルゴリズムの一種です古典的な機械学習では、問題の中で...
機械学習におけるクラスタリングの評価
「クラスタリングは常に私の関心を引きました特に、機械学習全体に初めて入り込んだ時には、教師なしクラスタリングは常に...」
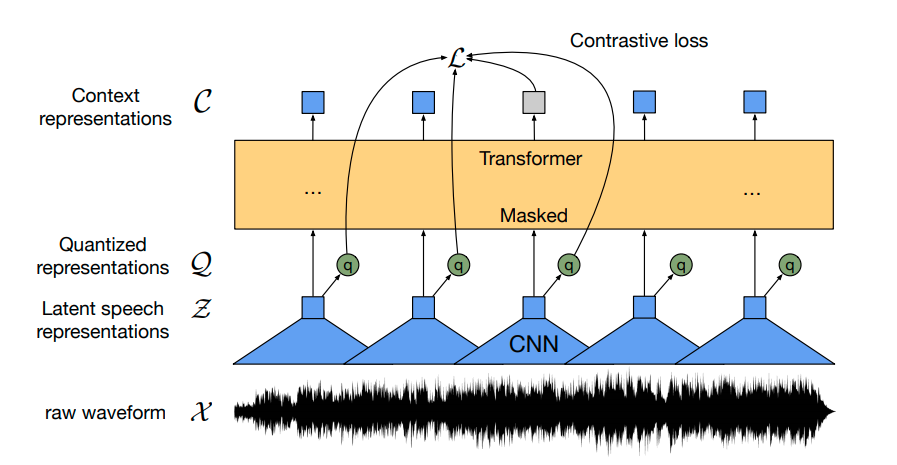
Hugging Faceを使用してWav2Vec2を英語音声認識のために微調整する
Wav2Vec2は、自動音声認識(ASR)のための事前学習済みモデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。 Wav2Vec2は、革新的な対比的事前学習目標を使用して、50,000時間以上の未ラベル音声から強力な音声表現を学習します。BERTのマスクされた言語モデリングと同様に、モデルはトランスフォーマーネットワークに渡す前に特徴ベクトルをランダムにマスクすることで、文脈化された音声表現を学習します。 初めて、事前学習に続いてわずかなラベル付き音声データで微調整することで、最先端のASRシステムと競合する結果が得られることが示されました。Wav2Vec2は、わずか10分のラベル付きデータを使用しても、LibriSpeechのクリーンテストセットで5%未満の単語エラーレート(WER)を実現します – 論文の表9を参照してください。 このノートブックでは、Wav2Vec2の事前学習チェックポイントをどの英語のASRデータセットでも微調整する方法について詳しく説明します。このノートブックでは、言語モデルを使用せずにWav2Vec2を微調整します。言語モデルを使用しないWav2Vec2は、エンドツーエンドのASRシステムとして非常にシンプルであり、スタンドアロンのWav2Vec2音響モデルでも印象的な結果が得られることが示されています。デモンストレーションの目的で、わずか5時間のトレーニングデータしか含まれていないTimitデータセットで「base」サイズの事前学習チェックポイントを微調整します。 Wav2Vec2は、コネクショニスト時系列分類(CTC)を使用して微調整されます。CTCは、シーケンス対シーケンスの問題に対してニューラルネットワークを訓練するために使用されるアルゴリズムであり、主に自動音声認識および筆記認識に使用されます。 Awni Hannunによる非常にわかりやすいブログ記事Sequence Modeling with CTC(2017)を読むことを強くお勧めします。 始める前に、datasetsとtransformersを最新バージョンからインストールすることを強くお勧めします。また、オーディオファイルを読み込むためにsoundfileパッケージと、単語エラーレート(WER)メトリックを使用して微調整モデルを評価するためにjiwerが必要です1 {}^1 1 。 !pip install datasets>=1.18.3 !pip install…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.