Learn more about Search Results Flick - Page 2

- You may be interested
- 「AIを使わない人々の7つの愚かな理由」
- CDPとAIの交差点:人工知能が顧客データプ...
- ウェイブは、LINGO-1という新しいAIモデル...
- SetFit プロンプトなしで効率的なフューシ...
- 「2023年に注目すべきトップ7のデジタルマ...
- ホワイトキャッスルへようこそそれに人と...
- 「NVIDIA H100 Tensor Core GPUを使用した...
- 「AutoMixを使用した計算コストの最適化 ...
- 「H2O.aiとOptunaを使用した高度な予測モ...
- 「AWS AI サービスと Amazon Bedrock によ...
- データ駆動型のディスパッチ
- 「マーケティングにおける人工知能の短い...
- 「浙江大学の研究者がUrbanGIRAFFEを提案...
- 「科学者たちが侵略的なカルプを裏切り者...
- 『AI Time Journal(AI タイムジャーナル...

カリフォルニア州での山火事との戦いにAIが役立つ方法
カリフォルニア州は、州を壊滅させた山火事に対抗する新たな武器、AIを手に入れました。 NVIDIAのGPUで訓練されたAIによって駆動される最新のシステムは、火災が発生するたびにゴールデンステート全体の救助隊にタイムリーな警告を提供することを約束しています。 ALERTCaliforniaのイニシアチブは、カリフォルニアの山火事対策機関CAL FIREとカリフォルニア大学サンディエゴ校の協力によるもので、DigitalPathが開発した先進的なAIを利用しています。 NVIDIAのGPUの生のパワーを利用し、カリフォルニアの風景に点在する数千のカメラのネットワークに支えられて、DigitalPathはリアルタイムで火災の兆候を検知するために畳み込みニューラルネットワークを洗練させました。 家族に近い使命 DigitalPathのCEOであるジム・ヒギンズは、州で最も多くの命が奪われた2018年のパラダイス町での火災で85人が亡くなったカリフォルニア州における最も致命的で破壊的な火災を指し、「これが私たちのやっていることの主な理由の1つです」と述べました。 ALERTCaliforniaのイニシアチブは、UC San Diegoのジェイコブス工学部、クアルコム研究所、スクリップス海洋研究所に拠点を置いています。 このプログラムは、数千の監視カメラとセンサーアレイのネットワークを管理し、実際の時間に行動可能な情報を提供して公共の安全を支えるデータを収集しています。 AIプログラムは6月に始まり、最初にCal Fireの6つの指揮センターに展開されました。今月、CAL FIREの21の指揮センターに拡大しました。 DigitalPathによって駆動されるALERTCaliforniaは、カメラによって配置されたゴールデンステート全体の火災を検知できます。 DigitalPathは、911通報後のカリフォルニアの山火事を確認するために使用されるカメラのネットワークの管理プラットフォームの構築から始めました。 すぐに、システムに10秒から15秒ごとに画像を送信する数千のカメラから画像を検査する方法はないことに気付きました。 そこで、同社のシステムアーキテクトであるイーサン・ヒギンズはAIに取り組みました。 チームは、NVIDIA A100 Tensor Core GPUを搭載したクラウドベースのシステムで畳み込みニューラルネットワークを訓練し始め、後に8つのA100 GPUで動作するシステムに移行しました。…

「初心者におすすめの副業5選(無料のコースとAIツールで始める)」
「ここには、$0から始められる5つの実証済みの副業アイデアがありますこれらの無料コースとAIツールを活用して、成功を加速させましょう」

ContentStudio レビュー:ソーシャルメディアにおける最高のAIツール?(2023年9月)
「ContentStudioがあなたのビジネスに最適なソーシャルメディア管理プラットフォームかどうか疑問に思っていますか?詳細なContentStudioレビューを読んで、それを知ることができます!」
GLIP オブジェクト検出への言語-画像事前学習の導入
今日は、言語-画像の事前学習であるCLIPの素晴らしい成功を基に、物体検出のタスクに拡張した論文であるGLIPについて掘り下げます...

「2023年8月のアフィリエイトマーケティングにおける10の最高のAIツール」
アフィリエイトマーケティングのダイナミックな世界では、観客を魅了するために革新的で効率的なツールが求められます人工知能(AI)の急速な進歩により、コンテンツ作成や観客の関与戦略を再定義する革命が進行中です説得力のある文章の生成から魅力的な音声や映像の制作まで、AIツールはアフィリエイトにとって欠かせない存在になりつつあります

「NVIDIAのCEO、ジェンソン・ホアン氏がSIGGRAPHに戻る」
パンデミックと生成AI革命が終わり、NVIDIAの創設者兼CEOであるジェンソン・ファンが、世界最大のプロフェッショナルグラフィックスカンファレンスであるSIGGRAPHのステージに戻ってきます。 8月8日(火曜日)午前8時(PT)にロサンゼルスで予定されている講演では、NVIDIAの最新のブレークスルー、受賞歴のある研究、OpenUSDの開発、コンテンツ作成のための最新のAIソリューションなど、独占的な内容が紹介されます。 NVIDIAの創設者兼CEO、ジェンソン・ファン。 ファンの講演は、先週NVIDIAがPixar、Adobe、Apple、Autodeskと連携して、3Dグラフィックス、デザイン、シミュレーションの相互運用性の次の時代を開くためのAlliance for OpenUSDを設立したことに続いています。 このグループは、相互運用可能な3Dアプリケーションやビジュアルエフェクトから産業用デジタルツインまでのプロジェクトにおける基盤となるオープンソースのUniversal Scene DescriptionフレームワークであるOpenUSDを標準化および拡張します。 ファンはまた、AIにとっての騒々しい1年についての見解も提供し、世界中の開発者が取り組むことになる、ChatGPTやMidjourneyなどの非常に人気のある新しい生成AIアプリケーションの一部を紹介します。 カンファレンス全体を通じて、NVIDIAは没入型可視化、3D相互運用性、AIを介したビデオ会議などのセッションに参加し、20の研究論文を発表します。参加者はまた、ハンズオンラボに参加する機会も得ることができます。 SIGGRAPHに参加して、AIとビジュアルコンピューティングの進化を目撃してください。このページで講演をご覧ください。 画像の出典:Ron Diering、Flickr経由、一部の権利が保護されています。

「合成キャプションはマルチモーダルトレーニングに役立つのか?このAI論文は、合成キャプションがマルチモーダルトレーニングにおけるキャプションの品質向上に効果的であることを示しています」
マルチモーダルモデルは、人工知能の分野における最も重要な進歩の一つです。これらのモデルは、画像やビデオを含む視覚的な情報、自然言語を含むテキスト情報、音声や音などの音響的な情報など、複数のモダリティからのデータを処理し理解するために設計されています。これらのモデルは、これらの様々なモダリティからのデータを組み合わせ分析し、多様なデータの種類にわたる理解と推論を必要とする複雑なタスクを実行することができます。大規模なマルチモーダルモデルは、画像とテキストのペアで事前学習することで、さまざまなビジョン関連のタスクで高いパフォーマンスを発揮することが示されています。 研究者たちは、ビジョンタスクで使用される大規模なマルチモーダルモデルのトレーニングにおいて、画像とテキストのペアなどのウェブデータの有用性を向上させようと試みていますが、不適切に整列した画像とテキストのペア、不良なデータソース、低品質なコンテンツなど、オンラインデータは頻繁にノイズが多く情報量が不足しています。現在の存在する手法はデータのノイズを減らすものの、しばしばデータの多様性の喪失をもたらします。そのため、研究チームは、ウェブスクレイピングされたデータにおけるキャプションの品質に焦点を当てたアプローチを提案しています。 主な目標は、曖昧または情報不足のテキストを持つ画像とテキストのペアの有用性を向上させるために、生成されたキャプションがどのように役立つかを探究することです。そのため、チームは複数のミキシング戦術をテストし、生のサイトキャプションとモードによって生成されたキャプションを組み合わせました。このアプローチは、DataCompのベンチマークで提案されたトップのフィルタリング戦略を大幅に上回りました。1億2800万の画像テキストペアの候補プールを使用して、ImageNetの改善は2%であり、38のジョブ全体で平均改善は4%です。彼らの最善の手法は、FlickrとMS-COCOの検索タスクで従来の手法を上回り、彼らの戦略が実世界の状況での実現可能性を示しています。 チームは、人工キャプションがテキスト監督の有用なツールである理由について調査しました。複数の画像キャプションモデルをテストすることにより、チームは、マルチモーダルトレーニングにおいてモデルが生成するキャプションの有用性が、NoCaps CIDErなどの確立された画像キャプションベンチマークでのパフォーマンスに常に依存しないことを示しました。これは、従来の画像キャプションベンチマークだけに頼らず、特にマルチモーダルな活動において生成されたキャプションを評価する必要性を強調しています。 この研究は、DataCompのデータセットである12.8億の画像テキストペアを使用して、生成されたキャプションの広範な適用を調査しました。この実験は、合成テキストの制約を明らかにし、トレーニングデータの拡大に伴い画像キュレーションの重要性が高まっていることを強調しています。チームによって共有されたinsightsは以下の通りです: キャプションモデルの選択:標準的なベンチマークに基づいて事前学習されたネットワークを画像キャプションのために微調整することは、マルチモーダルトレーニングにおけるキャプションの効果的な生成につながらない場合があります。CLIP-Sなどのリファレンスフリーメトリックは、生成されたキャプションのトレーニング品質をよりよく反映します。 複数のソースからのキャプションの組み合わせ:生のキャプションと合成キャプションのフィルタリングやミキシングには、DataCompベンチマークでの小規模およびVoAGIスケールでのパフォーマンス向上がもたらされました。 合成キャプションの効果:個々のレベルでは、合成キャプションはノイズが少なく、視覚情報が豊富です。ただし、集団レベルでは、生のキャプションと比較して多様性に欠けます。 合成キャプションの利点のスケーラビリティ:最適なフィルタリングアプローチは、異なるデータスケールによって異なります。異なる数量での実験は、合成キャプションの制約を明らかにし、大規模なデータ領域では画像品質の制御と多様性のギャップがより重要になることを示します。

「起業家のためのトップAIツール2023年」
GrammarlyはAIを活用した文章作成支援ツールで、あなたの文章がエラーフリーかつ磨かれたものになるようサポートします。 Salesforceはクラウドベースのソフトウェア会社であり、あらゆる規模の企業にCRM(顧客関係管理)のソリューションを提供しています。 Google Analyticsは、ユーザーがサイトとどのように対話しているかに関する洞察に役立つ無料のサービスです。 TensorFlowは、データフローグラフ上での数値計算のための無料かつオープンソースのライブラリです。 Tableau Softwareは、データをグラフィカルに表示することでユーザーがデータを理解するのを支援するツールです。 Zapierは、サービスとプログラムをリンクし、重要な作業に戻ることができる自動化ツールです。 Marketmuseは、高性能なコンテンツを作成するのを支援するコピーライティングツールです。 Google Cloud Platformは、Googleが消費者向け製品に使用しているサーバー上でホストされている一連のクラウドコンピューティングサービスへのアクセスをユーザーに提供します。 Slackは、チームがコミュニケーションや協力を行うためのクラウドベースのメッセージングプラットフォームです。 Zenefitsは、給与、福利厚生、人事管理などを支援するクラウドベースのHRソフトウェア会社です。 Tamrは、機械学習を使用してデータの統一とクリーニングを行うデータマスタリング企業です。 Optimoveは、顧客の関与、維持、および生涯価値を向上させるのを支援する顧客主導のマーケティングプラットフォームです。 Asanaは、チームが作業を整理、追跡、管理するのを支援する生産性プラットフォームです。 CrowdStrikeは、最も高度な攻撃からエンドポイント、クラウドワークロード、アイデンティティ、データを保護するクラウドネイティブのサイバーセキュリティ企業です。 Wordtuneは、より簡潔かつ明確で読者にとって興味深い代替表現の提案を行うライティングツールです。 DigitalGeniusは、カスタマーサービスを自動化し、従業員の生産性を向上させるための会話型AIプラットフォームを提供する企業です。 Intraspexionは、人工知能を使用して企業の法務部門が訴訟を回避するのを支援するソフトウェア企業です。 Howler AIは、ニッチなジャーナリストに正確にリーチするのを支援する自動化PRプラットフォームです。 Pictoryは、テキスト、ブログ投稿、その他の長文コンテンツから魅力的なビデオを作成するのを支援するAIパワードのビデオ作成プラットフォームです。…

新しいAI研究がGPT4RoIを紹介します:地域テキストペアに基づくInstruction Tuning大規模言語モデル(LLM)によるビジョン言語モデル
大型言語モデル(LLM)は最近、自然言語処理を必要とする会話タスクで驚異的なパフォーマンスを発揮し、大きな進歩を遂げています。商用製品のChatGPT、Claude、Bard、テキストのみのGPT-4、およびコミュニティオープンソースのLLama、Alpaca、Vicuna、ChatGLM、MOSSなどがその例です。彼らの前例のない能力のおかげで、彼らは汎用人工知能モデルへの潜在的なルートを提供しています。LLMの効果の結果として、マルチモーダルモデリングコミュニティは、ジョブの特徴空間を事前学習済み言語モデルの特徴空間に合わせるための普遍的なインターフェースとしてLLMを使用する新しい技術的な道を創造しています。 MiniGPT-4、LLaVA、LLaMA-Adapter、InstructBLIPなどのビジョンと言語のモデルは、代表的なタスクの1つとして画像とテキストのペアリングでの指示調整により、ビジョンエンコーダをLLMに合わせるようにアラインメントされます。アラインメントの品質は、指示調整の設計コンセプトに基づいてビジョンと言語のモデルのパフォーマンスに大きな影響を与えます。これらの作品は優れたマルチモーダルスキルを持っていますが、領域レベルのアラインメントにより、領域のキャプションや推論などのより複雑な理解タスクを超えることができません。彼らのアラインメントは画像とテキストのペアリングに限定されています。一部の研究では、MM-REACT、InternGPT、DetGPTなどの外部のビジョンモデルを使用して、ビジョン言語モデルで領域レベルの理解を提供しています。 ただし、彼らの非エンドツーエンドの設計は、汎用マルチモーダルモデルにとってより良い可能性があります。この作品は、関心領域の細かい理解を提供するために、最初から終わりまでビジョン言語モデルを開発することを目指しています。画像全体を画像埋め込みとして圧縮し、特定の部分を参照するための操作を行わないこれらのモデルのモデルアーキテクチャでは、空間指示にオブジェクトボックスを形式として確立します。回答を得るために、LLMは空間教育と言語的指示によって抽出されたビジュアル要素を提供されます。たとえば、問い合わせが「これは何をしているのか?」という交互のシーケンスの場合、モデルは空間指示によって参照される領域の特徴で置き換えます。 RoIAlignまたは変形可能なアテンションは、空間指示のための柔軟な実装方法です。これらは、画像とテキストのデータセットから領域とテキストのデータセットにトレーニングデータを更新し、領域とテキストのペアリング間の細かいアライメントを構築するために、各アイテムの境界ボックスとテキストの説明が提供されます。COCOオブジェクト識別、RefCOCO、RefCOCO+、RefCOCOg、Flickr30Kエンティティ、Visual Genome(VG)、Visual Commonsense Reasoning(VCR)などの公開データセットが組み合わされます。これらのデータセットは、指示調整のための形式に変更されます。さらに、商業的に利用可能な物体検出器を使用して、画像からオブジェクトボックスを抽出し、空間指示として利用することができます。LLaVA150Kなどの画像とテキストのトレーニングデータを活用するために、棚からひとつオブジェクト検出器を使用することもできます。彼らのモデルは、LLMに影響を与えることなく、領域特徴抽出器を事前トレーニングするために使用されます。 彼らのモデルは、これらの画像テキストデータセットから学習し、視覚的指示の調整に注意深く選択されたビジュアルインストラクションを持つため、対話品質が向上し、より人間らしい返答を生成します。収集されたデータセットは、テキストの長さに基づいて2種類に分けられます。まず、短いテキストデータにはアイテムのカテゴリや基本的な特徴に関する情報が含まれます。これらはLLMに影響を与えることなく、領域特徴抽出器を事前トレーニングするために使用されます。次に、より長いテキストには、複雑なアイデアや論理的思考が必要な場合があります。これらのデータには複雑な空間指示が提供され、エンドツーエンドの領域特徴抽出器とLLMの微調整が可能になります。これにより、実際の使用時に柔軟なユーザー指示をシミュレートすることができます。彼らの手法は、空間指示の調整から得られる利点により、ビジョン言語モデルのユーザーに、言語形式と空間指示形式の両方でモデルに問い合わせることができるユニークなインタラクティブな体験を提供します。 図1は、これにより、複雑な領域推論や領域キャプションなど、画像レベルの理解を超える新たな能力が実現することを示しています。結論として、彼らの作品は以下の点に貢献しています: • LLMに地域テキストデータセットのトレーニングを与えることで、地域レベルのビジョン言語モデルを進化させます。彼らのモデルは、以前の画像レベルのモデルと比較して、領域キャプションや推論などの追加機能を備えています。 • 応答を得るために、関心領域を参照するための空間指示を導入し、ビジュアルエンコーダから回復した領域特性を言語指示と共にLLMに提供します。 • コーディング、データセットの指示調整形式、オンラインデモはすべてGitHubで利用可能です。 図1: GPT4RoIと呼ばれるビジョン言語モデルは、領域とテキストのペアリングで大規模な言語モデル(LLM)を調整する指示調整に基づいて構築されています。単一の領域に口頭と位置情報を組み合わせたユーザーの指示を分析することができます。領域のキャプション付けや推論など、細かいマルチモーダル理解のタスクを達成します。
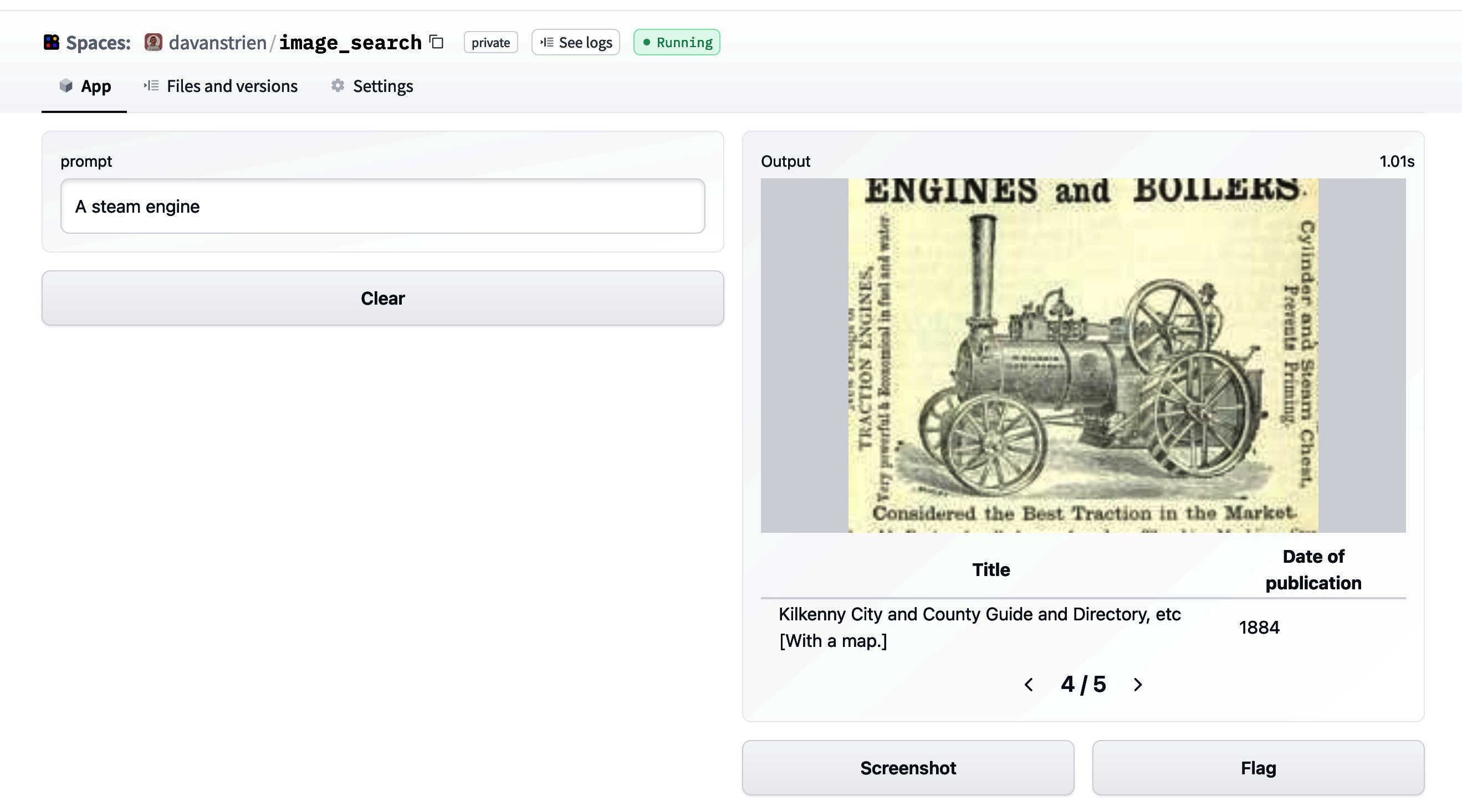
🤗データセットを使った画像検索
🤗 datasetsは、データセットに簡単にアクセスして共有することができるライブラリです。また、メモリに収まらないデータを効率的に処理することも容易にします。 datasetsが最初にリリースされた当初は、主にテキストデータと関連していました。しかし、最近では、datasetsは音声や画像に対するサポートを増やしています。特に、画像のためのdatasetsの機能タイプが追加されました。以前のブログ投稿では、datasetsと🤗 transformersを組み合わせて画像分類モデルのトレーニング方法を紹介しました。このブログ投稿では、datasetsと他のいくつかのライブラリを組み合わせて画像検索アプリケーションを作成する方法を見ていきます。 まず、datasetsをインストールします。画像を扱うために、pillowもインストールします。さらに、sentence_transformersとfaissも必要です。これらについては後ほど詳しく説明します。また、richもインストールします。ここでは簡単に使用するだけですが、非常に便利なパッケージなので、ぜひ詳しく探索してみてください! !pip install datasets pillow rich faiss-gpu sentence_transformers まずは、画像の特徴を見てみましょう。素晴らしいライブラリであるrichを使用して、Pythonオブジェクト(関数、クラスなど)を調べることができます。 from rich import inspect import datasets inspect(datasets.Image, help=True) ╭───────────────────────── <class 'datasets.features.image.Image'>…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.