Learn more about Search Results DRF - Page 2

- You may be interested
- WAYVE社がGAIA-1を発表:ビデオ、テキスト...
- AIがUPSのパッケージ窃盗を監視しています
- 「OpenAI WhisperとHugging Chat APIを使...
- 『Gradioを使ったリテンションの理解』
- Earth.comとProvectusがAmazon SageMaker...
- マシンラーニング手法の鉄道欠陥検索への...
- (マルコフ連鎖を利用したモデリングゲーム)
- 「OpenAIは、パーソナライズされたAIイン...
- 「AIの画像をどのように保存すべきか?Goo...
- 「GPT-4が怠け者です:OpenAIが認める」
- 最後のチャンス!認定AIワークショップが2...
- 「プロンプトチューニングとは何ですか?」
- 「8月号:データサイエンティストのための...
- 「ONNX Runtimeを使用して130,000以上のHu...
- このAIサブカルチャーのモットーは、「行...

「LoRAアダプターにダイブ」
「大規模言語モデル(LLM)は世界中で大流行しています過去の1年間では、彼らができることにおいて莫大な進歩を目撃してきましたそれまではかなり限定的な用途にとどまっていましたが、今では…」

「プロセスマイニングとデジタルトランスフォーメーションによる産業4.0における業務の効率化の実現」
「業界に関係なく、デジタル技術は組織の間でますます人気を集めており、業績向上、収益成長、持続可能性の実現に向けて活用されています」

大規模画像モデルのための最新のCNNカーネル
「OpenAIのChatGPTの驚異的な成功が大型言語モデルのブームを引き起こしたため、多くの人々が大型画像モデルにおける次のブレークスルーを予測していますこの領域では、ビジョンモデルは...」

予測API:DjangoとGoogle Trendsの例
Djangoは高水準のPythonウェブフレームワークです速く、安全で、スケーラブルに設計されており、複雑さが増すことが予想される堅牢なウェブアプリケーションの開発に人気の選択肢です...
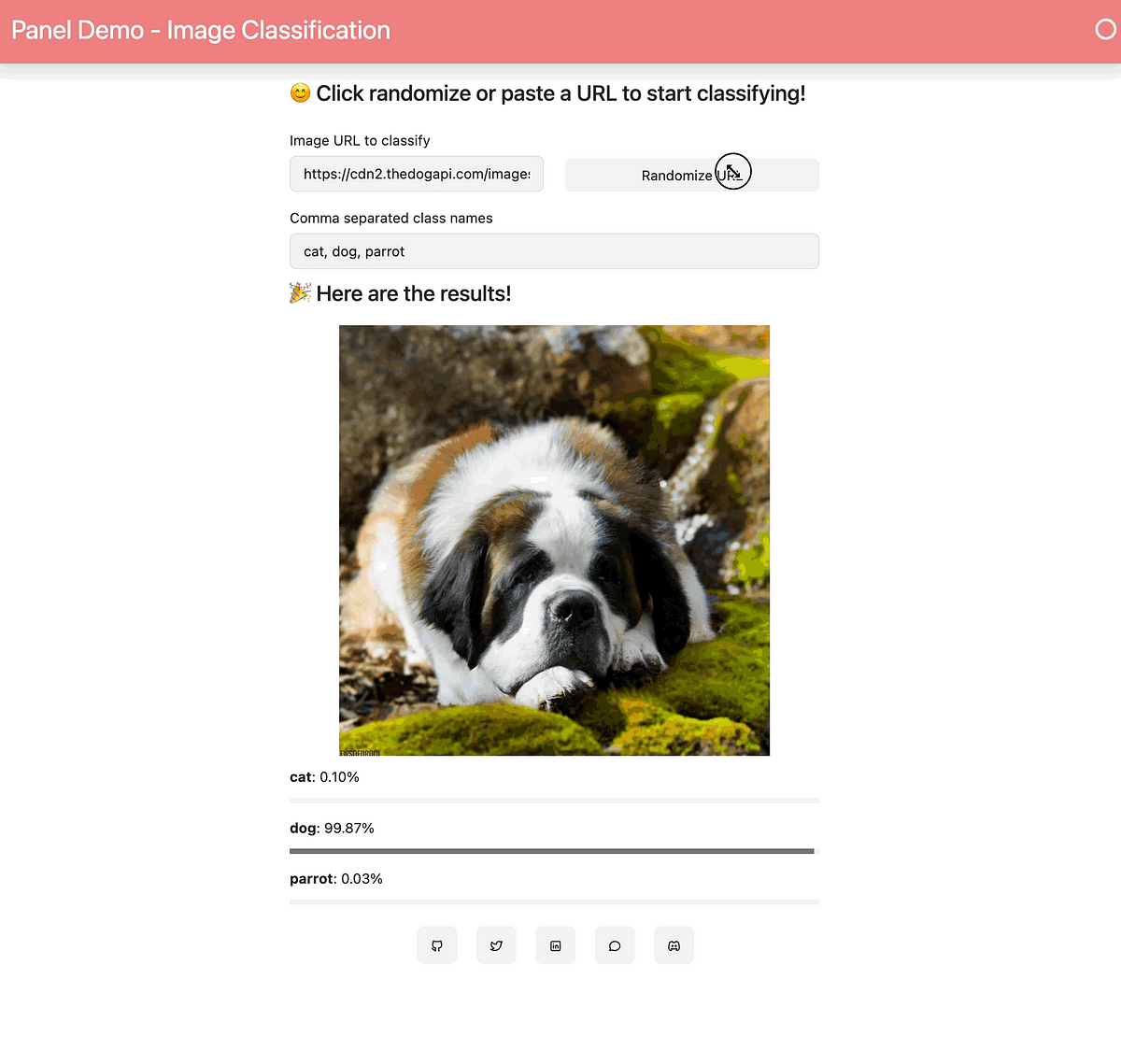
PanelでインタラクティブなMLダッシュボードを作成する
HoloViz Panelは、開発者やデータサイエンティストが簡単にインタラクティブな可視化を構築できる多目的なPythonライブラリです機械学習プロジェクトに取り組んでいるか、開発を行っているかに関わらず、HoloViz Panelはあなたをサポートします
クロスバリデーションの助けを借りて、あなたの機械学習モデルに自信を持ちましょう
「訓練された機械学習モデルを訓練データ自体で評価することは基本的に間違っていますもし評価が行われれば、モデルは訓練中に学習した値のみを返しますこの評価は...」

「自動推論とツールの利用(ART)を紹介します:凍結された大規模言語モデル(LLM)を使用して、推論プログラムの中間段階を迅速に生成するフレームワーク」
大規模言語モデルは、いくつかのデモとリアルな言語の指示を与えることで、新しいタスクに迅速に適応し、コンテキスト内での学習を利用することができます。これにより、LLMのホスティングや大規模なデータセットの注釈付けを回避することができますが、マルチステップの推論、数学、最新の情報の取得など、パフォーマンスに関する重要な課題があります。最近の研究では、LLMに高度な推論段階をサポートするためのツールへのアクセスを与えるか、マルチステップの推論のための推論チェーンのエミュレーションを課題とすることで、これらの制約を緩和することが提案されています。ただし、新しい活動やツールに対してチェーン化された理由付けの確立されたアプローチを適応することは困難であり、特定の活動やツールに特化したファインチューニングやプロンプトエンジニアリングが必要です。 図1:タスクライブラリから類似のタスク分解(A)を選択し、LLM生成と組み合わせてツールライブラリからツールを選択して適用することで、ARTは新しいタスクの自動マルチステップ分解(B)を開発します。人間は分解を変更してパフォーマンスを向上させることができます(コードの修正や変更など)(C)。 本研究では、ワシントン大学、マイクロソフト、メタ、カリフォルニア大学、アレン人工知能研究所の研究者が、新しいタスクの例に対して自動的に分解(マルチステップ推論)を作成するフレームワークであるAutomated Reasoning and Tool usage(ART)を開発しました。ARTはタスクライブラリから類似のタスクの例を引っ張ってきて、少数のデモとツールの使用を可能にすることで、さらなる作業に活用します。これらの例では、柔軟で構造化されたクエリ言語が使用されており、中間段階を読みやすくし、外部ツールの使用を一時停止して、そのツールの出力が含まれるまで再開することが簡単になっています(図1)。また、フレームワークは各段階で最適なツール(検索エンジンやコード実行など)を選択して使用します。 ARTはARTから各種関連活動のインスタンスを分解する方法や、これらの例で描かれたツールライブラリからツールを選択して使用する方法について、LLMにデモを提供します。これにより、モデルは例から新しいタスクを分解し、適切なツールを利用してジョブを行うことができます。また、ユーザーはタスクとツールのライブラリを更新し、論理の連鎖に誤りがある場合や新しいツール(例:対象のタスクに対して)を追加するために必要な最新の例を追加することができます。 彼らは15のBigBenchタスク用のタスクライブラリを作成し、19のBigBenchテストタスク(以前に見たことのないもの)、6つのMMLUタスク、および関連するツールの使用研究(SQUAD、TriviaQA、SVAMP、MAWPS)から数多くのタスクでARTをテストしました。34のBigBench問題のうち32問とすべてのMMLUタスクでは、ARTは平均でコンピュータによって作成されたCoT推論チェーンを22ポイント以上上回るか、または一致させます。ツールの使用が許可されると、テストタスクのパフォーマンスは平均で約12.3ポイント向上します。 平均して、ARTはBigBenchとMMLUの両方のタスクで直接のフューショットプロンプティングよりも10.8ポイント優れています。ARTは、数学的およびアルゴリズム的な推論を要求する未知のタスクにおいて、直接のフューショットプロンプティングよりも12.5ポイント優れ、分解とツールの使用のための監視を含むGPT3の最もよく知られた結果よりも6.1ポイント優れています。タスクとツールのライブラリを新しい例で更新することで、人間との相互作用と推論プロセスの向上が可能になり、最小限の人間の入力で任意のジョブのパフォーマンスを劇的に向上させることができます。追加の人間のフィードバックが与えられた場合、ARTは12のテストタスクで最もよく知られたGPT3の結果を平均で20%以上上回ります。
AWSとPower BIを使用して、米国のフライトを調査する
∘ 問題の説明 ∘ データ ∘ AWSアーキテクチャ ∘ AWS S3を使ったデータストレージ ∘ スキーマの設計 ∘ AWS Glueを使ったETL ∘ AWS Redshiftを使ったデータウェアハウジング ∘ インサイトの抽出...

新しい人工知能(AI)の研究アプローチは、統計的な視点からアルゴリズム学習の問題として、プロンプトベースのコンテキスト学習を提示します
インコンテキスト学習は、最近のパラダイムであり、大規模言語モデル(LLM)がテストインスタンスと数少ないトレーニング例を入力として観察し、パラメータの更新なしに直接出力をデコードする方法です。この暗黙のトレーニングは、通常のトレーニングとは異なり、例に基づいて重みが変更されることと対照的です。 出典: https://arxiv.org/pdf/2301.07067.pdf なぜインコンテキスト学習が有益であるのかという問題が生じます。2つの回帰タスクをモデル化したいと仮定できますが、制限は1つのモデルしか使用できないということです。ここでインコンテキスト学習は便利であり、タスクごとに回帰アルゴリズムを学習することができます。つまり、モデルは異なる入力のセットに対して別々に適合した回帰を使用します。 論文 「Transformers as Algorithms: Generalization and Implicit Model Selection in In-context Learning」では、インコンテキスト学習の問題をアルゴリズム学習の問題として形式化しています。彼らは学習アルゴリズムとしてトランスフォーマーを使用し、推論時に別のターゲットアルゴリズムを実装するためにトレーニングして特化できると述べています。この論文では、トランスフォーマーを介したインコンテキスト学習の統計的側面を探求し、理論的予測を検証するために数値評価を行いました。 この研究では、2つのシナリオを調査しました。最初のシナリオでは、プロンプトはi.i.d(入力、ラベル)のペアのシーケンスで構成されています。もう一つのシナリオでは、シーケンスは動的システムの軌跡です(次の状態は前の状態に依存します:xm+1 = f(xm) + ノイズ)。 では、このようなモデルをどのようにトレーニングするのでしょうか? ICLのトレーニングフェーズでは、T個のタスクがデータ分布 {Dt}t=1Tに関連付けられます。各タスクに対して、対応する分布からトレーニングシーケンスStを独立してサンプリングします。その後、Stの部分シーケンスとシーケンスStから値xを渡して、xに対して予測を行います。ここではメタラーニングのフレームワークのようです。予測後、損失を最小化します。ICLトレーニングの背後にある直感は、対象のタスクに最適なアルゴリズムを探し出すことです。…
究極の可視化アシスタント
太陽が薄れ始め、街の灯りが輝き出すと、オフィスでの遅い夜が避けられなくなりました私は時間との競争に巻き込まれました重要な営業プレゼンテーションが迫っていました...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.