Learn more about Search Results D2L - Page 2

- You may be interested
- スターバックスのコーヒー代で、自分自身...
- 空気圧アクチュエータは、ロボットにチー...
- 「Matplotlibを使用してリップスティック...
- 「知っておくべき3つの一般的な時系列モデ...
- 04/12から10/12までの週のための重要なコ...
- 「シーケンシャルデータのディープラーニ...
- 「データサイエンスの精度向上のために、...
- 「AIアラインメントの二つの側面」
- AI時代の運転:AIへの恐怖が命を奪う代償...
- ChatGPTによるデータサイエンス面接チート...
- 「ユナイテッド航空がコスト効率の高い光...
- 「NLPモデルの正規化に関するクイックガイ...
- AccelDataがBewgleを買収:AIデータパイプ...
- 既存のLLMプロジェクトをLangChainを使用...
- GraphReduce グラフを使用した特徴エンジ...

「医療分野における生成型AI」
はじめに 生成型人工知能は、ここ数年で急速に注目を集めています。医療と生成型人工知能の間に強い関係性が生まれていることは驚くことではありません。人工知能(AI)はさまざまな産業を急速に変革しており、医療分野も例外ではありません。AIの特定のサブセットである生成型人工知能は、医療分野において画期的な存在となっています。 生成型AIシステムは、新しいデータ、画像、さらには完全な芸術作品を生成することができます。医療分野では、この技術は診断、新薬の発見、患者ケア、医学研究の向上において非常に有望です。本記事では、医療分野における生成型人工知能の潜在的な応用と利点、実装上の課題、倫理的な考慮事項について探究します。 学習目標 GenAIとその医療分野への応用 GenAIの医療分野における潜在的な利点 医療分野における生成型AIの実装上の課題と制約 医療分野における生成型AIの将来的な展望 本記事は、Data Science Blogathonの一環として公開されました。 医療分野における生成型人工知能の潜在的な応用 医療分野において、GenAIをどのように活用できるかについて、いくつかの研究が行われています。GenAIは、新薬のための分子構造や化合物の生成に影響を与え、有望な薬剤候補の同定と発見を促進しています。これにより、先端技術を活用しながら時間とコストを節約することが可能です。以下は、これらの潜在的な応用の一部です: 医療画像および診断の向上 医療画像は、診断と治療計画において重要な役割を果たしています。生成型AIアルゴリズム(生成対抗的ネットワーク(GAN)や変分オートエンコーダー(VAE)など)は、医療画像解析を大幅に改善しています。これらのアルゴリズムは、実際の患者データに似た合成医療画像を生成することができ、機械学習モデルのトレーニングと検証に役立ちます。また、限られたデータセットを補完するために追加のサンプルを生成することで、画像に基づく診断の正確性と信頼性を向上させることもできます。 薬剤の発見と開発の促進 新薬の発見と開発は、複雑で時間がかかり、費用がかかる作業です。生成型AIは、所望の特性を持つ仮想化合物や分子を生成することで、このプロセスを大幅に加速することができます。研究者は、生成モデルを用いて広大な化学空間を探索し、新たな薬剤候補を同定することができます。これらのモデルは既存のデータセット(既知の薬剤構造と関連する特性を含む)から学習し、望ましい特性を持つ新しい分子を生成します。 個別化医療と治療 生成型AIは、患者データを活用して個別化された治療計画を作成することで、個別化医療を革新する潜在能力を持っています。電子健康記録、遺伝子プロファイル、臨床結果などの大量の患者情報を分析することにより、生成型AIモデルは個別化された治療の推奨を生成することができます。これらのモデルはパターンを特定し、病気の進行を予測し、介入に対する患者の反応を推定することができるため、医療提供者は情報に基づいた意思決定を行うことができます。 医学研究と知識生成 生成型AIモデルは、特定の特性と制約を満たす合成データを生成することで、医学研究を支援することができます。合成データは、機密性の高い患者情報の共有に関連するプライバシーの問題を解決しながら、研究者が有益な洞察を抽出し、新たな仮説を開発することができます。 また、生成型AIは臨床試験のための合成患者コホートを生成することもできます。これにより、研究者はさまざまなシナリオをシミュレートし、実際の患者に対する高価で時間のかかる試験を実施する前に治療の効果を評価することができます。この技術は、医学研究を加速し、イノベーションを推進し、複雑な疾患に対する理解を広げる可能性があります。 事例研究: CPPE-5…
Pythonを使用した探索的データ分析(EDA)の実践ガイド
データを読み込むために、Pandasのread_csv関数を使用しますread_csv関数は、CSVファイルへのパスを第1引数として取ります私たちの直感によれば、人の結果は...
物理情報を持つDeepONetによる逆問題の解決:コード実装と実践ガイド
「前回のブログでは、物理情報を持つDeepONet(PI-DeepONet)の概念について探求し、なぜオペレータ学習、つまり入力からのマッピングを学習するのに特に適しているかについて調査しました...」

エンコーダー・デコーダーモデルのための事前学習済み言語モデルチェックポイントの活用
Transformerベースのエンコーダーデコーダーモデルは、Vaswani et al.(2017)で提案され、最近ではLewis et al.(2019)、Raffel et al.(2019)、Zhang et al.(2020)、Zaheer et al.(2020)、Yan et al.(2020)などにおいて大きな関心を集めています。 BERTやGPT2と同様に、大規模な事前学習済みエンコーダーデコーダーモデルは、Lewis et al.(2019)、Raffel et al.(2019)などのさまざまなシーケンス対シーケンスのタスクにおいて性能を大幅に向上させることが示されています。しかし、エンコーダーデコーダーモデルの事前学習には膨大な計算コストがかかるため、そのようなモデルの開発は主に大企業や研究所に限定されています。 Sascha Rothe、Shashi Narayan、Aliaksei Severynによる「シーケンス生成タスクのための事前学習済みチェックポイントの活用」(2020)では、事前学習済みのエンコーダーやデコーダーのみのチェックポイント(例:BERT、GPT2)でエンコーダーデコーダーモデルを初期化して、コストのかかる事前学習をスキップする方法が紹介されています。著者らは、このようなウォームスタートされたエンコーダーデコーダーモデルが、T5やPegasusなどの大規模な事前学習済みエンコーダーデコーダーモデルと比較して、複数のシーケンス対シーケンスのタスクで競争力のある結果をもたらすことを示しています。 このノートブックでは、エンコーダーデコーダーモデルをウォームスタートする方法の詳細を説明し、Rothe et…

Hugging Face Transformersでより高速なTensorFlowモデル
ここ数か月、Hugging FaceチームはTransformersのTensorFlowモデルの改良に取り組んできました。目標はより堅牢で高速なモデルを実現することです。最近の改良は主に次の2つの側面に焦点を当てています: 計算パフォーマンス:BERT、RoBERTa、ELECTRA、MPNetの計算時間を大幅に短縮するための改良が行われました。この計算パフォーマンスの向上は、グラフ/イージャーモード、TF Serving、CPU/GPU/TPUデバイスのすべての計算アスペクトで顕著に見られます。 TensorFlow Serving:これらのTensorFlowモデルは、TensorFlow Servingを使用して展開することができ、推論においてこの計算パフォーマンスの向上を享受することができます。 計算パフォーマンス 計算パフォーマンスの向上を実証するために、v4.2.0のTensorFlow ServingとGoogleの公式実装との間でBERTのパフォーマンスを比較するベンチマークを実施しました。このベンチマークは、GPU V100上でシーケンス長128を使用して実行されました(時間はミリ秒単位で表示されます): v4.2.0の現行のBertの実装は、Googleの実装よりも最大で約10%高速です。また、4.1.1リリースの実装よりも2倍高速です。 TensorFlow Serving 前のセクションでは、Transformersの最新バージョンでブランドニューのBertモデルが計算パフォーマンスが劇的に向上したことを示しました。このセクションでは、製品環境で計算パフォーマンスの向上を活用するために、TensorFlow Servingを使用してBertモデルを展開する手順をステップバイステップで説明します。 TensorFlow Servingとは何ですか? TensorFlow Servingは、モデルをサーバーに展開するタスクをこれまで以上に簡単にするTensorFlow Extended(TFX)が提供するツールの一部です。TensorFlow Servingには、HTTPリクエストを使用して呼び出すことができるAPIと、サーバー上で推論を実行するためにgRPCを使用するAPIの2つがあります。 SavedModelとは何ですか? SavedModelには、ウェイトとアーキテクチャを含むスタンドアロンのTensorFlowモデルが含まれています。SavedModelは、モデルの元のソースを実行する必要がないため、Java、Go、C++、JavaScriptなどのSavedModelを読み込むバックエンドをサポートするすべてのバックエンドと共有または展開するために役立ちます。SavedModelの内部構造は次のように表されます:…
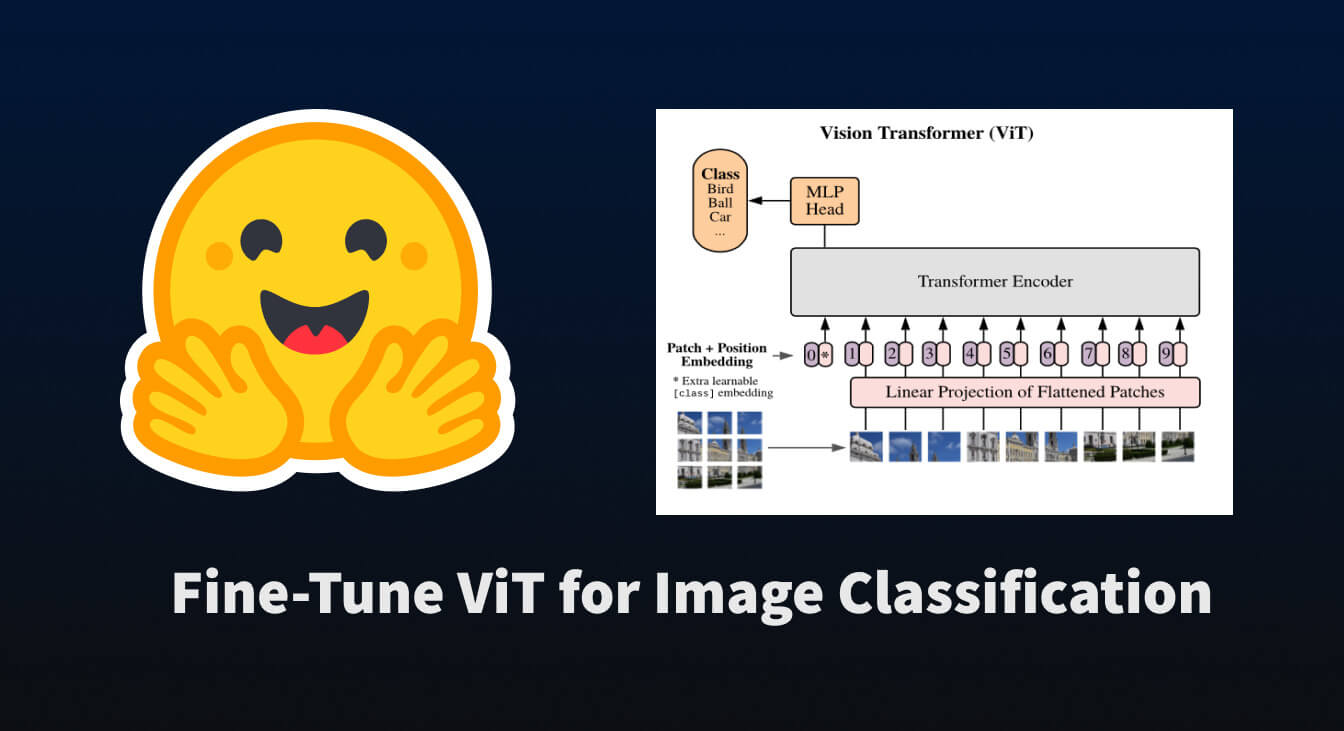
🤗 Transformersを使用して、画像分類のためにViTを微調整する
トランスフォーマーベースのモデルがNLPを革命化したように、我々は今、それらを他のさまざまな領域に適用する論文の爆発を目撃しています。その中でも最も革命的なものの一つが「Vision Transformer(ViT)」です。これは、Google Brainの研究チームによって2021年6月に紹介されました。 この論文では、文をトークン化するように画像をトークン化する方法を探求しており、それによってトランスフォーマーモデルにトレーニング用のデータとして渡すことができます。実際には非常にシンプルな概念です… 画像をサブ画像パッチのグリッドに分割する 各パッチを線形変換で埋め込む 各埋め込まれたパッチがトークンとなり、埋め込まれたパッチのシーケンスがモデルに渡される 上記の手順を実行すると、NLPのタスクと同様にトランスフォーマーを事前学習および微調整することができることがわかります。かなり便利です 😎。 このブログポストでは、🤗 datasets を使用して画像分類データセットをダウンロードおよび処理し、それを使用して事前学習済みの ViT を 🤗 transformers を使用して微調整する方法について説明します。 まずは、それらのパッケージをインストールしましょう。 pip install datasets transformers データセットの読み込み まずは、小規模な画像分類データセットを読み込んで、その構造を確認しましょう。…

Hugging Face TransformersとAWS Inferentiaを使用して、BERT推論を高速化する
ノートブック:sagemaker/18_inferentia_inference BERTとTransformersの採用はますます広がっています。Transformerベースのモデルは、自然言語処理だけでなく、コンピュータビジョン、音声、時系列でも最先端のパフォーマンスを達成しています。💬 🖼 🎤 ⏳ 企業は、大規模なワークロードのためにトランスフォーマーモデルを使用するため、実験および研究フェーズから本番フェーズにゆっくりと移行しています。ただし、デフォルトでは、BERTとその仲間は、従来の機械学習アルゴリズムと比較して、比較的遅く、大きく、複雑なモデルです。TransformersとBERTの高速化は、将来的に解決すべき興味深い課題となるでしょう。 AWSはこの課題を解決するために、最適化された推論ワークロード向けに設計されたカスタムマシンラーニングチップであるAWS Inferentiaを開発しました。AWSは、AWS Inferentiaが「現行世代のGPUベースのAmazon EC2インスタンスと比較して、推論ごとのコストを最大80%低減し、スループットを最大2.3倍高める」と述べています。 AWS Inferentiaインスタンスの真の価値は、各デバイスに搭載された複数のNeuronコアを通じて実現されます。Neuronコアは、AWS Inferentia内部のカスタムアクセラレータです。各Inferentiaチップには4つのNeuronコアが搭載されています。これにより、高スループットのために各コアに1つのモデルをロードするか、低レイテンシのためにすべてのコアに1つのモデルをロードすることができます。 チュートリアル このエンドツーエンドのチュートリアルでは、Hugging Face Transformers、Amazon SageMaker、およびAWS Inferentiaを使用して、テキスト分類のBERT推論を高速化する方法を学びます。 ノートブックはこちらでご覧いただけます:sagemaker/18_inferentia_inference 以下の内容を学びます: 1. Hugging Face TransformerをAWS Neuronに変換する 2.…

カスタムデータセットでセマンティックセグメンテーションモデルを微調整する
このガイドでは、最先端のセマンティックセグメンテーションモデルであるSegformerのファインチューニング方法を紹介します。私たちの目標は、ピザ配達ロボットのためのモデルを構築することで、それによってロボットがどこに進むべきかを見ることができ、障害物を認識できるようにすることです 🍕🤖。最初に、Segments.aiで一連の歩道の画像にラベルを付けます。次に、🤗 transformersというオープンソースのライブラリを使用して、事前学習済みのSegFormerモデルをファインチューニングします。このライブラリは、最先端のモデルの簡単な実装を提供しています。このプロセスで、最大のオープンソースのモデルとデータセットのカタログであるHugging Face Hubの使用方法も学びます。 セマンティックセグメンテーションは、画像内の各ピクセルを分類するタスクです。これはより正確な画像の分類方法と見なすことができます。医療画像や自動運転など、さまざまな分野で幅広い用途があります。例えば、ピザ配達ロボットの場合、画像内の歩道がどこにあるか正確に知ることが重要です。 セマンティックセグメンテーションは分類の一種であるため、画像分類とセマンティックセグメンテーションに使用されるネットワークアーキテクチャは非常に似ています。2014年、Longらによる画像セグメンテーションのための異彩を放つ論文では、畳み込みニューラルネットワークが使用されています。最近では、画像分類にTransformers(例:ViT)が使用されており、最新のセマンティックセグメンテーションにも使用されており、最先端の技術をさらに押し上げています。 SegFormerは、2021年にXieらによって提案されたセマンティックセグメンテーションのモデルです。ポジションエンコーディングを使用しない階層的なトランスフォーマーエンコーダと、単純な多層パーセプトロンデコーダを持っています。SegFormerは、複数の一般的なデータセットで最先端の性能を実現しています。さあ、ピザ配達ロボットが歩道の画像でどのようにパフォーマンスを発揮するか見てみましょう。 必要な依存関係をインストールして始めましょう。データセットとモデルをHugging Face Hubにプッシュするために、Git LFSをインストールし、Hugging Faceにログインする必要があります。 git-lfsのインストール方法は、お使いのシステムによって異なる場合があります。Google ColabにはGit LFSが事前にインストールされていることに注意してください。 pip install -q transformers datasets evaluate segments-ai apt-get…

TF Servingを使用してHugging FaceでTensorFlow Visionモデルを展開する
過去数ヶ月間、Hugging Faceチームと外部の貢献者は、TransformersにさまざまなビジョンモデルをTensorFlowで追加しました。このリストは包括的に拡大しており、ビジョントランスフォーマー、マスク付きオートエンコーダー、RegNet、ConvNeXtなど、最先端の事前学習モデルがすでに含まれています! TensorFlowモデルを展開する際には、さまざまな選択肢があります。使用ケースに応じて、モデルをエンドポイントとして公開するか、アプリケーション自体にパッケージ化するかを選択できます。TensorFlowには、これらの異なるシナリオに対応するツールが用意されています。 この投稿では、TensorFlow Serving(TF Serving)を使用してローカルでビジョントランスフォーマーモデル(画像分類用)を展開する方法を紹介します。これにより、開発者はモデルをRESTエンドポイントまたはgRPCエンドポイントとして公開できます。さらに、TF Servingはモデルのウォームアップ、サーバーサイドバッチ処理など、多くの展開固有の機能を提供しています。 この投稿全体で示される完全な動作するコードを取得するには、冒頭に示されているColabノートブックを参照してください。 🤗 TransformersのすべてのTensorFlowモデルには、save_pretrained()というメソッドがあります。このメソッドを使用すると、モデルの重みをh5形式およびスタンドアロンのSavedModel形式でシリアライズできます。TF Servingでは、モデルをSavedModel形式で提供する必要があります。そこで、まずビジョントランスフォーマーモデルをロードして保存します。 from transformers import TFViTForImageClassification temp_model_dir = "vit" ckpt = "google/vit-base-patch16-224" model = TFViTForImageClassification.from_pretrained(ckpt)…
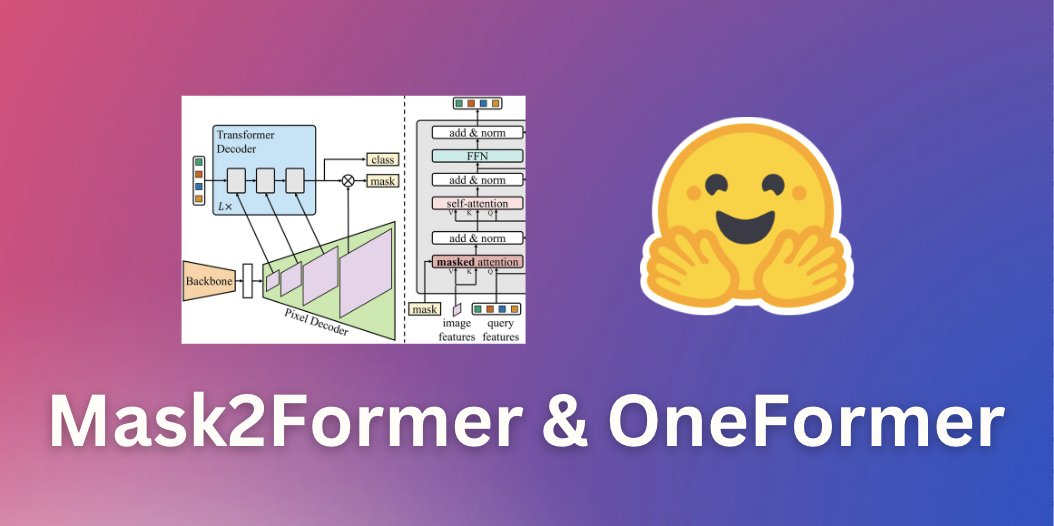
マスク2フォーマーとワンフォーマーによるユニバーサル画像セグメンテーション
このガイドでは、画像セグメンテーションのための最先端のニューラルネットワークであるMask2FormerとOneFormerを紹介します。これらのモデルは、最先端モデルの簡単な実装を提供するオープンソースのライブラリである🤗 transformersで利用できます。途中で、さまざまな形式の画像セグメンテーションの違いについて学びます。 画像セグメンテーション 画像セグメンテーションは、人や車などの画像内の異なる「セグメント」を識別するタスクです。より具体的には、画像セグメンテーションは異なる意味を持つピクセルをグループ化するタスクです。詳細については、Hugging Faceのタスクページを参照してください。 画像セグメンテーションは、主に3つのサブタスクに分割できます。それぞれのサブタスクを実行するための多数の方法とモデルアーキテクチャがあります。 インスタンスセグメンテーションは、画像内の個々の人物などの異なる「インスタンス」を識別するタスクです。インスタンスセグメンテーションは、オブジェクト検出と非常に似ていますが、境界ボックスではなく、対応するクラスラベルとともに一連のバイナリセグメンテーションマスクを出力したいという点が異なります。インスタンスはしばしば「オブジェクト」や「事物」とも呼ばれます。ただし、個々のインスタンスは重なる場合があります。 意味セグメンテーションは、画像の各ピクセルの「人」や「空」などの異なる「意味カテゴリ」を識別するタスクです。インスタンスセグメンテーションとは異なり、与えられた意味カテゴリの個々のインスタンスの区別はありません。たとえば、「人」のカテゴリのマスクを作成するだけであり、個々の人物のマスクを作成するわけではありません。対象カテゴリに個別のインスタンスがない「空」や「草」などの意味カテゴリは、しばしば「物」と呼ばれます(素晴らしい名前ですね)。ピクセルごとのカテゴリには重なりがないことに注意してください。 パノプティックセグメンテーションは、Kirillov et al.によって2018年に導入され、モデルが対応するバイナリマスクとクラスラベルのセットを単に識別することで、インスタンスセグメンテーションと意味セグメンテーションを統一することを目指しています。セグメントは「物」または「物」のどちらでもなります。インスタンスセグメンテーションとは異なり、異なるセグメント間の重なりはありません。 以下の図は、3つのサブタスクの違いを示しています(このブログ投稿から取得)。 ここ数年、研究者たちは通常、インスタンスセグメンテーション、意味セグメンテーション、パノプティックセグメンテーションのいずれかに特化したいくつかのアーキテクチャを提案してきました。インスタンスセグメンテーションとパノプティックセグメンテーションは、通常、オブジェクトインスタンスごとにバイナリマスクと対応するラベルのセットを出力することによって解決されました(インスタンス検出と非常に似ていますが、インスタンスごとに境界ボックスの代わりにバイナリマスクを出力します)。これは通常「バイナリマスク分類」と呼ばれます。一方、意味セグメンテーションは、モデルがピクセルごとに1つの「セグメンテーションマップ」を出力することで解決されることが一般的でした。したがって、意味セグメンテーションは「ピクセルごとの分類」の問題として扱われました。このパラダイムを採用する人気のある意味セグメンテーションモデルには、SegFormer(詳細なブログ投稿を書いた)とUPerNetなどがあります。 ユニバーサル画像セグメンテーション 幸いなことに、2020年ごろから、インスタンスセグメンテーション、意味セグメンテーション、およびパノプティックセグメンテーションのすべてのタスクを統一されたアーキテクチャで解決できるモデルが登場し始めました。これは最初にDETRが行ったものであり、”物”クラスと”物”クラスを統一的な方法で扱うことによってパノプティックセグメンテーションを解決した最初のモデルでした。キーイノベーションは、トランスフォーマーデコーダが並列的に一連のバイナリマスクとクラスを生成することでした。これはMaskFormerの論文で改善され、”バイナリマスク分類”のパラダイムが意味セグメンテーションにも非常にうまく適用されることが示されました。 Mask2Formerは、ニューラルネットワークアーキテクチャをさらに改善することで、インスタンスセグメンテーションにも拡張します。したがって、個別のアーキテクチャから、研究者たちが現在「ユニバーサル画像セグメンテーション」と呼んでいる、すべての画像セグメンテーションタスクを解決できるアーキテクチャに進化しました。興味深いことに、これらのユニバーサルモデルはすべて「マスク分類」のパラダイムを採用しており、完全に「ピクセルごとの分類」のパラダイムを廃止しています。Mask2Formerのアーキテクチャを示す図は、以下に示されています(オリジナルの論文から取得)。 要するに、画像はまずバックボーン(この論文ではResNetまたはSwin Transformerのどちらか)に送信されて、低解像度の特徴マップのリストを取得します。次に、これらの特徴マップは、ピクセルデコーダモジュールを使用して高解像度の特徴に改善されます。最後に、トランスフォーマーデコーダは一連のクエリを受け取り、ピクセルデコーダの特徴に基づいて一連のバイナリマスクとクラスの予測を行います。 Mask2Formerは、最先端の結果を得るために、各タスクごとにトレーニングする必要があることに注意してください。これは、OneFormerモデルによって改善されました。OneFormerモデルは、データセットのパノプティックバージョンのみをトレーニングすることで、すべての3つのタスクで最先端のパフォーマンスを実現します。さらに、テキストエンコーダを追加してモデルを「インスタンス」、「セマンティック」、または「パノプティック」の入力に条件付けることで、これをさらに改善しました。このモデルは、今日でも🤗 transformersで利用できます。Mask2Formerよりも精度が高くなっていますが、追加のテキストエンコーダにより遅延が大きくなります。OneFormerの概要については、以下の図を参照してください。Swin Transformerまたは新しいDiNATモデルをバックボーンとして使用しています。 TransformersでのMask2FormerとOneFormerの推論 Mask2FormerとOneFormerの使用法は非常に簡単であり、前身であるMaskFormerと非常に似ています。COCOパノプティックデータセットでトレーニングされたハブからMask2Formerモデルをインスタンス化し、それに対応するプロセッサもインスタンス化します。作者たちはさまざまなデータセットでトレーニングされた30個以上のチェックポイントをリリースしていることに注意してください。 from…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.