Learn more about Search Results CPU - Page 2

- You may be interested
- 3Dプリントされたセラミックはガスタービ...
- ネットワークの強化:異常検知におけるML...
- 「ChatGPTのコピーライターへの影響:AIと...
- 「PDF、txt、そしてウェブページとして、...
- 「Googleが最新のAIモデルGeminiを発表」
- OpenAIはGPT-3.5 Turboのファインチューニ...
- オープンAIのCEOであるサム・アルトマン氏...
- 2024年のトップ10のAI主導のデータ分析企業
- 3Dプリンターは郵便局の迅速かつ手頃な配...
- 「GPTQまたはbitsandbytes:LLMsのために...
- インデータベース分析:SQLの解析関数の活用
- 「LangChainのチェーンとGPTモデルを使用...
- 「過小評価されている宝石Pt.1:あなたを...
- 「Pythonでのプロトコル」
- 「Synthesysレビュー:最高のAIビデオジェ...
CPU上でBERT推論をスケーリングアップする(パート1)
.centered { display: block; margin: 0 auto; } figure { text-align: center; display: table; max-width: 85%; /* デモです; 必要に応じていくつかの量 (px や %) を設定してください */…

モダンなCPU上でのBERTライクモデルの推論のスケーリングアップ – パート2
イントロダクション:CPU上でのAI効率を最適化するためのIntelソフトウェアの使用 前のブログ記事で詳細に説明したように、Intel Xeon CPUは、AVX512やVNNI(Vector Neural Network Instructions)などのAIワークロードに特に設計された機能を提供しており、整数量子化されたニューラルネットワークを使用した効率的な推論をサポートするための追加のシステムツールも提供しています。このブログ記事では、ソフトウェアの最適化に焦点を当て、Intelの新しいIce Lake世代のXeon CPUのパフォーマンスについて紹介します。私たちの目標は、Intelのハードウェアを最大限に活用するためにソフトウェア側で利用可能なものをすべて紹介することです。前のブログ記事と同様に、ベンチマークの結果とグラフとともに、これらのツールと機能を簡単に使用できるようにします。 4月にIntelは最新のIntel Xeonプロセッサ、コードネームIce Lakeを発売しました。これはより効率的で高性能なAIワークロードをターゲットにしています。具体的には、Ice Lake Xeon CPUは、以前のCascade Lake Xeonプロセッサと比較して、さまざまなNLPタスクで最大75%高速な推論が可能です。これは、新しいSunny Coveアーキテクチャ上での新しい命令やPCIe 4.0のようなハードウェアおよびソフトウェアの改善の組み合わせによって実現されています。最後になりますが、Intelは、IntelのExtension for Scikit Learn、Intel TensorFlow、Intel PyTorch…

事例研究:Hugging Face InfinityとモダンなCPUを使用したミリ秒レイテンシー
はじめに 転移学習は、自然言語処理(NLP)から音声およびコンピュータビジョンのタスクまで、機械学習を新たな精度レベルに変えてきました。Hugging Faceでは、これらの新しい複雑なモデルと大規模なチェックポイントをできるだけ簡単にアクセス可能かつ利用可能にするために、努力して取り組んでいます。しかし、研究者やデータサイエンティストがTransformersの新しい世界に移行している一方で、これらの大規模で複雑なモデルを実稼働環境で大規模に展開することができる企業はほとんどありません。 主なボトルネックは、予測のレイテンシーであり、大規模な展開を実行するために高コストになり、リアルタイムのユースケースが実用的になりません。これを解決するには、どの機械学習エンジニアリングチームにとっても難しいエンジニアリング上の課題であり、ハードウェアまでモデルを最適化するための高度な技術の使用を必要とします。 Hugging Face Infinityでは、最も人気のあるTransformerモデルに対して、低レイテンシー、高スループット、ハードウェアアクセラレーションされた推論パイプラインを簡単に展開できるコンテナ化されたソリューションを提供しています。企業は、Transformersの精度と大容量展開に必要な効率性を、使いやすいパッケージで手に入れることができます。このブログ投稿では、最新世代のIntel Xeon CPU上で実行されるInfinityの詳細なパフォーマンス結果を共有したいと思います。 Hugging Face Infinityとは Hugging Face Infinityは、お客様が最新のTransformerモデルを最適化したエンドツーエンドの推論パイプラインを任意のインフラストラクチャ上で展開できるコンテナ化されたソリューションです。 Hugging Face Infinityには、2つの主要なサービスがあります: Infinityコンテナは、Dockerコンテナとして提供されるハードウェア最適化された推論ソリューションです。 Infinity Multiverseは、Hugging Face Transformerモデルをターゲットハードウェアに最適化するモデル最適化サービスです。Infinity MultiverseはInfinityコンテナと互換性があります。…
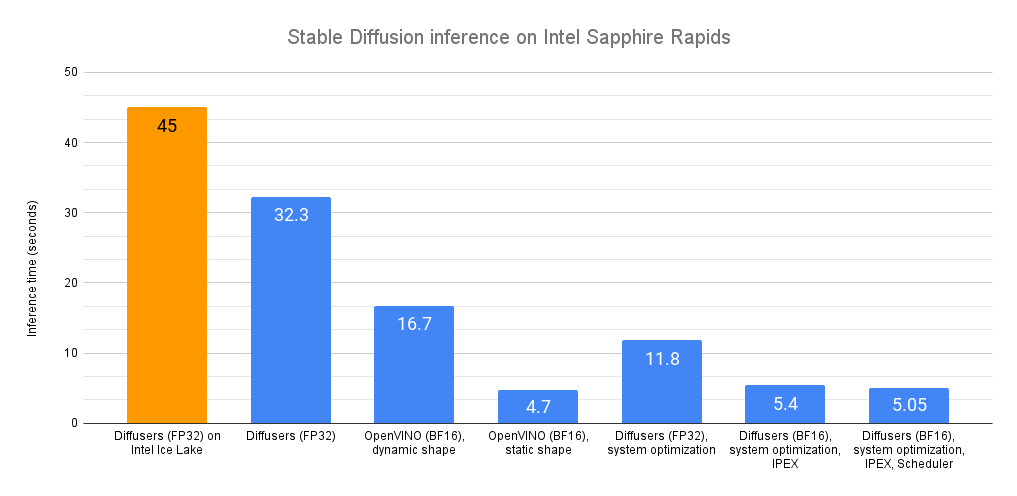
Intel CPU上での安定な拡散推論の高速化
最近、私たちは最新世代のIntel Xeon CPU(コードネームSapphire Rapids)を紹介しました。これには、ディープラーニングの高速化に対応した新しいハードウェア機能があります。また、これらを使用して自然言語処理のトランスフォーマーの分散微調整と推論を加速する方法も紹介しました。 この投稿では、Sapphire Rapids CPU上で安定拡散モデルを加速するための異なる技術を紹介します。次の投稿では、分散微調整について同様の内容を紹介します。 執筆時点では、Sapphire Rapidsサーバーにアクセスする最も簡単な方法は、Amazon EC2 R7izインスタンスファミリーを使用することです。まだプレビュー段階ですので、アクセスするためにはサインアップする必要があります。前の投稿と同様に、私はUbuntu 20.04 AMI(ami-07cd3e6c4915b2d18)を使用してr7iz.metal-16xlインスタンス(64 vCPU、512GB RAM)を使用しています。 さあ、始めましょう!コードサンプルはGitlabで利用できます。 Diffusersライブラリ Diffusersライブラリは、安定拡散モデルを使用して画像を生成するのが非常に簡単です。これらのモデルに詳しくない場合は、こちらの素晴らしいイラスト入りの紹介をご覧ください。 まず、必要なライブラリ(Transformers、Diffusers、Accelerate、PyTorch)を使用して仮想環境を作成しましょう。 virtualenv sd_inference source sd_inference/bin/activate pip…

Intel CPUのNNCFと🤗 Optimumを使用した安定したディフュージョンの最適化
潜在的な拡散モデルは、テキストから画像の生成問題を解決する際にゲームチェンジャーとなります。 安定した拡散は、コミュニティや産業界で広く採用されている最も有名な例の一つです。 安定した拡散モデルのアイデアはシンプルで魅力的です:ノイズベクトルから画像を複数の小さなステップで生成し、ノイズを潜在的な画像表現に洗練させます。 ただし、このようなアプローチは、全体的な推論時間を増加させ、クライアントマシンで展開された場合にユーザーエクスペリエンスの低下を引き起こします。 通常のように、強力なGPUがここで役立つことに注意することができますが、これに伴うコストも著しく増加します。 参考までに、H1’23では、8つのvCPUと64GBのRAMを備えた強力なCPU r6i.2xlargeインスタンスの価格は1時間あたり$0.504であり、同様のNVIDIA T4を搭載したg4dn.2xlargeインスタンスの価格は1時間あたり$0.75で、これは1.5倍以上です.. これにより、画像生成サービスは所有者とユーザーにとって非常に高価になります。 クライアントアプリケーションでは、GPUがまったくない場合もあります! これにより、安定した拡散パイプラインの展開は困難な問題となります。 過去5年間、OpenVINO Toolkitは高性能推論のための多くの機能をカプセル化しました。 最初はコンピュータビジョンモデルに設計されたものですが、現在でも最先端のモデルを含む多くのコンテンポラリーモデルにおいて、最高の推論パフォーマンスを示しています。 ただし、リソース制約のあるアプリケーションに安定した拡散モデルを最適化するには、ランタイム最適化にとどまらず、さらに進んだモデル最適化機能がOpenVINO Neural Network Compression Framework(NNCF)から必要とされます。 このブログ記事では、安定した拡散モデルの最適化の問題を概説し、CPUなどのリソース制約のあるHWで実行される場合に、そのようなモデルのレイテンシを大幅に削減するワークフローを提案します。 特に、PyTorchと比較して5.1倍の推論高速化と4倍のモデルフットプリントの削減を達成しました。 安定した拡散の最適化 安定した拡散パイプラインでは、UNetモデルが計算上最もコストがかかります。そのため、単一のモデルの最適化によって推論速度が大幅に向上します。 しかし、このモデルに対しては、従来のモデル最適化手法であるポストトレーニングの8ビット量子化は機能しないことがわかりました。その理由は2つあります。まず、セマンティックセグメンテーション、スーパーレゾリューションなどのピクセルレベル予測モデルは、タスクの複雑さにより、モデル最適化の観点では最も複雑なものの一つであり、モデルパラメータと構造の微調整が結果を多数の方法で崩してしまいます。…

Hugging FaceとAMDは、CPUおよびGPUプラットフォーム向けの最先端モデルの高速化に関するパートナーシップを結んでいます
言語モデル、大規模な言語モデル、または基盤モデル、トランスフォーマーは、事前学習、微調整、および推論において大量の計算を必要とします。Hugging Faceは、開発者や組織が最大のパフォーマンスを得るために、ハードウェア企業と協力して、各チップのアクセラレーション機能を活用してきました。 本日、私たちはAMDが正式に私たちのハードウェアパートナープログラムに参加したことをお知らせいたします。私たちのCEOであるClement Delangueが、サンフランシスコで行われたAMDのデータセンターおよびAIテクノロジープレミアで基調講演を行い、このエキサイティングな新しい協力関係を発表しました。 AMDとHugging Faceは、AMDのCPUおよびGPU上で最先端のトランスフォーマーパフォーマンスを提供するために協力しています。このパートナーシップは、Hugging Faceコミュニティ全体にとって非常に良いニュースであり、近々、最新のAMDプラットフォームをトレーニングおよび推論に活用することができるようになります。 長年にわたり、ディープラーニングハードウェアの選択肢は限られており、価格と供給は懸念事項となっています。この新しいパートナーシップは、競争に対抗するだけでなく、市場の動向を緩和するのに役立ちます。さらに、新しいコストパフォーマンスの基準を設定することも期待されます。 サポートされるハードウェアプラットフォーム GPU側では、AMDとHugging Faceはまず、エンタープライズグレードのInstinct MI2xxおよびMI3xxファミリー、次に、カスタマーグレードのRadeon Navi3xファミリーで協力します。AMDの最近のテストでは、MI250が直接競合他社よりもBERT-Largeを1.2倍、GPT2-Largeを1.4倍高速にトレーニングすることを報告しています。 CPU側では、両社はクライアントRyzenおよびサーバーEPYC CPUの推論の最適化に取り組みます。いくつかの以前の投稿で議論したように、CPUはトランスフォーマーの推論において優れたオプションになり得ます。特に、量子化などのモデル圧縮技術と組み合わせた場合です。 最後に、この協力関係には、低い電力要件で驚異的なパフォーマンスを発揮するAlveo V70 AIアクセラレータも含まれます。 サポートされるモデルアーキテクチャとフレームワーク 私たちは、自然言語処理、コンピュータビジョン、音声などの最先端のトランスフォーマーアーキテクチャ(BERT、DistilBERT、ROBERTA、Vision Transformer、CLIP、Wav2Vec2など)をサポートする予定です。もちろん、生成型AIモデル(GPT2、GPT-NeoX、T5、OPT、LLaMAなど)、私たち自身のBLOOMおよびStarCoderモデルも利用可能です。最後に、ResNetやResNextのようなより伝統的なコンピュータビジョンモデル、そして深層学習の推薦モデルにも初めて対応します。 これらのモデルをPyTorch、TensorFlow、およびONNX Runtime向けに上記のプラットフォームでテストおよび検証するために最善を尽くします。すべてのモデルが、すべてのフレームワークまたはすべてのハードウェアプラットフォームでトレーニングおよび推論に利用可能であるわけではないことを覚えておいてください。 今後の展望…

「5つ星アプリを構築する:AIと自動化を利用したモバイルテストの向上」
ソフトウェア開発チームは、高品質なモバイルアプリ体験を提供するために、強力で低コストのツールが必要ですAIと自動化は解決策を提供します

「Langchainの使い方:ステップバイステップガイド」
LangChain(ラングチェーン)は、プログラマーが大きな言語モデルを使用してアプリケーションを開発するための人工知能フレームワークです。LangChainの使用方法について詳しく見ていきましょう。 ステップ1: セットアップ LangChainを始める前に、適切に構成された開発環境があることを確認してください。PythonまたはJavaScriptなどの必要な依存関係をインストールしてください。LangChainは両方の言語に対応しており、開発者に柔軟性を提供します。 pip install langchain conda install langchain -c conda-forge ステップ2: LLM(Language Models) LangChainを効果的に使用するためには、モデルプロバイダーやデータストア、APIなどのさまざまなコンポーネントと統合することがしばしば必要です。ここでは、LangChainをOpenAIのモデルAPIと統合します。また、Hugging Faceを使用しても同様に行うことができます。 !pip install openaiimport osos.environ["OPENAI_API_KEY"] ="YOUR_OPENAI_TOKEN" from langchain.llms…

「RustコードのSIMD高速化のための9つのルール(パート2)」
SIMDを使用してRustコードを高速化するための9つの基本ルールを探求してくださいcoresimdについて学び、最適化技術を学びながらパフォーマンスを7倍に向上させましょう

クライテリオンを使用したRustコンパイラの設定のベンチマーキング
この記事では、まず、人気のある基準箱を使用してベンチマークする方法について説明します次に、コンパイラの設定を横断してベンチマークする方法について追加情報を提供します各組み合わせについて…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.