Learn more about Search Results CLIP - Page 2

- You may be interested
- 拡散生成モデルによる医薬品発見の加速化
- dtreevizを使用して、信じられないほどの...
- 「韓国のAI研究がマギキャプチャを紹介:...
- ChatGPTの哲学コース:このAI研究は、対話...
- 「明日のニュースを、今日に!」ニュースG...
- マストゥゴにお会いしましょう:ディフュ...
- ユーザーのコンテキストに基づいてアイテ...
- 「AIネットワークは攻撃に対して脆弱性が...
- 「医療機械学習におけるバイアスのある臨...
- 「データの中で最も異常なセグメントを特...
- 「AIは医療セキュリティにおいて重要である」
- 「Tabnine」は、ベータ版のエンタープライ...
- Terraformのインポート:それは何か、そし...
- BERTを使用してカスタムFAQチャットボット...
- このAIニュースレターは、あなたが必要な...

「KAISTの研究者がFaceCLIPNeRFを紹介:変形可能なNeRFを使用した3D顔のテキスト駆動型操作パイプライン」
3Dデジタル人間コンテンツ改善の重要な要素は、簡単に3D顔表現を操作できる能力です。Neural Radiance Field(NeRF)は、3Dシーンの再構築において重要な進展を遂げていますが、その操作技術の多くは剛体ジオメトリや色の操作に焦点を当てており、表情の微細な制御を必要とする作業において改善が必要です。最近の研究では、領域制御された顔編集手法が提案されましたが、この手法では、選択したトレーニングフレームから顔の異なる部分のユーザーアノテーションマスクを収集する手間のかかる手順が必要であり、さらに人間の属性制御が必要です。 顔特異的な暗黙の表現技術は、可変性の高い顔モデルのパラメータを事前に使用して観測された顔の表情を高い忠実度でエンコードします。しかし、その手動操作には、顔の表情の範囲を網羅した大規模なトレーニングセットが必要であり、約6000フレームをカバーします。これにより、データ収集と操作のプロセスが困難になります。その代わりに、KAISTとScatter Labの研究者は、いくつかの異なるタイプの顔変形インスタンスから成る約300のトレーニングフレームの動的なポートレートビデオ上でトレーニングする方法を開発しました。これにより、図1に示すように、テキストによる変更が可能になります。 図1 彼らの手法は、HyperNeRFを使用して観測された変形をカノニカル空間から学習し分離し、顔の変形を制御します。特に、共通の潜在コード条件付きの暗黙のシーンネットワークとフレームごとの変形潜在コードは、トレーニングフレーム全体で教えられます。彼らの基本的な発見は、様々な空間変数の潜在コードを使用してシーンの変形を表現し、操作タスクに利用することです。この発見は、HyperNeRFの定式化を単純に適用することの欠点から生じます。すなわち、望ましい顔の歪みをエンコードする単一の潜在コードを探すことです。 たとえば、単一の潜在コードでは、多くの場合に見られるローカルな変形の混合を必要とする表情を伝えることはできません。彼らの研究では、この問題を「連結ローカル属性の問題」として特定し、空間的に変動する潜在コードを提供することで対処しています。これを行うために、彼らはまず、すべての観測された変形をアンカーコードのコレクションにまとめ、それらを組み合わせて数多くの位置条件付きの潜在コードを生成するためにMLPに教えます。そして、生成された潜在コードの画像をCLIP埋め込み空間の目標テキストに近づけることにより、潜在コードの反映性を実現します。結論として、彼らの研究は以下の貢献をしています。 • 空間的に変動する潜在コードを使用してシーンを表現する操作ネットワークの設計 • NeRFで再構築された顔のテキストによる操作パイプラインの提案 • 彼らの知る限り、NeRFで再構築された顔に関するテキストを操作する最初の人物。

メディアでのアルコール摂取の検出:CLIPのゼロショット学習とABIDLA2ディープラーニングの画像解析のパワーを評価する
アルコールは、広範な健康上の懸念事項であり、5.1%のグローバルな疾病負荷を占め、個人や経済に重大な負の影響を与えています。ソーシャルメディアから映画、広告、人気のある音楽まで、アルコール暴露はいたるところにあります。研究者は、アルコール関連のソーシャルメディア投稿への暴露と特に若者の間でのアルコール使用との関連性を示唆しています。研究者たちは、アルコール暴露を測定し分析するための革新的な手法を探求しています。アルコール飲料の画像からの識別に関して、Alcoholic Beverage Identification Deep Learning Algorithm (ABIDLA) のような教師あり深層学習モデルは有望でありますが、トレーニングには大量の手動注釈付きデータが必要です。 これに対するもう一つのアプローチは、Zero-Shot Learning (ZSL) を利用したContrastive Language-Image Pretraining (CLIP)モデルです。研究者たちは、ZSLモデルのパフォーマンスを、画像中のアルコール飲料を特定するために特別にトレーニングされた深層学習アルゴリズム(ABIDLA2)と比較しました。評価のために研究者によって使用されたテストデータセットは、ABIDLA2の論文で使用されているABD22で、8つの飲料カテゴリを含んでいます。評価のために各クラスごとに1762のテストセットがあり、均一な分布を維持しています。評価には、加重平均再現率(UAR)、F1スコア、クラスごとの再現率などのパフォーマンスメトリックが計算され、ABIDLA2とZSLの名前付きおよび記述的なフレーズの両方について比較されました。 研究者たちは、ZSLがいくつかのタスクでうまく機能する一方で、細かい分類には支援が必要であることがわかりました。ABIDLA2モデルは、特定の飲料カテゴリの識別においてZSLを上回りました。しかし、記述的なフレーズ(例:「これはビール瓶を持っている人の写真です」)を使用したZSLは、特定の飲料をより広範な飲料カテゴリ(ビール、ワイン、スピリッツ、その他、つまりタスク2)に分類する際には、ABIDLA2とほぼ同等のパフォーマンスを発揮し、アルコール含有量の有無を分類する際にはABIDLA2を上回りました。 彼らは、フレーズエンジニアリングがZSLのパフォーマンス向上に重要であること、特に「その他」クラスにおいては不可欠であることを特定しました。 この研究の主な強みの一つは、ZSLが追加のトレーニングデータと計算リソースを最小限に抑え、教師あり学習アルゴリズムと比較してコンピュータサイエンスの専門知識を少なく必要とすることです。特に2値分類が必要な場合、画像中のアルコール含有物を正確に特定するという研究の質問に対して、ZSLは正確に対応することができます。この研究の結果は、将来の研究が実際のデータセットにおいて、異なる人口や文化の画像を含む教師あり学習モデルの一般化能力をZSLと比較することを奨励しています。
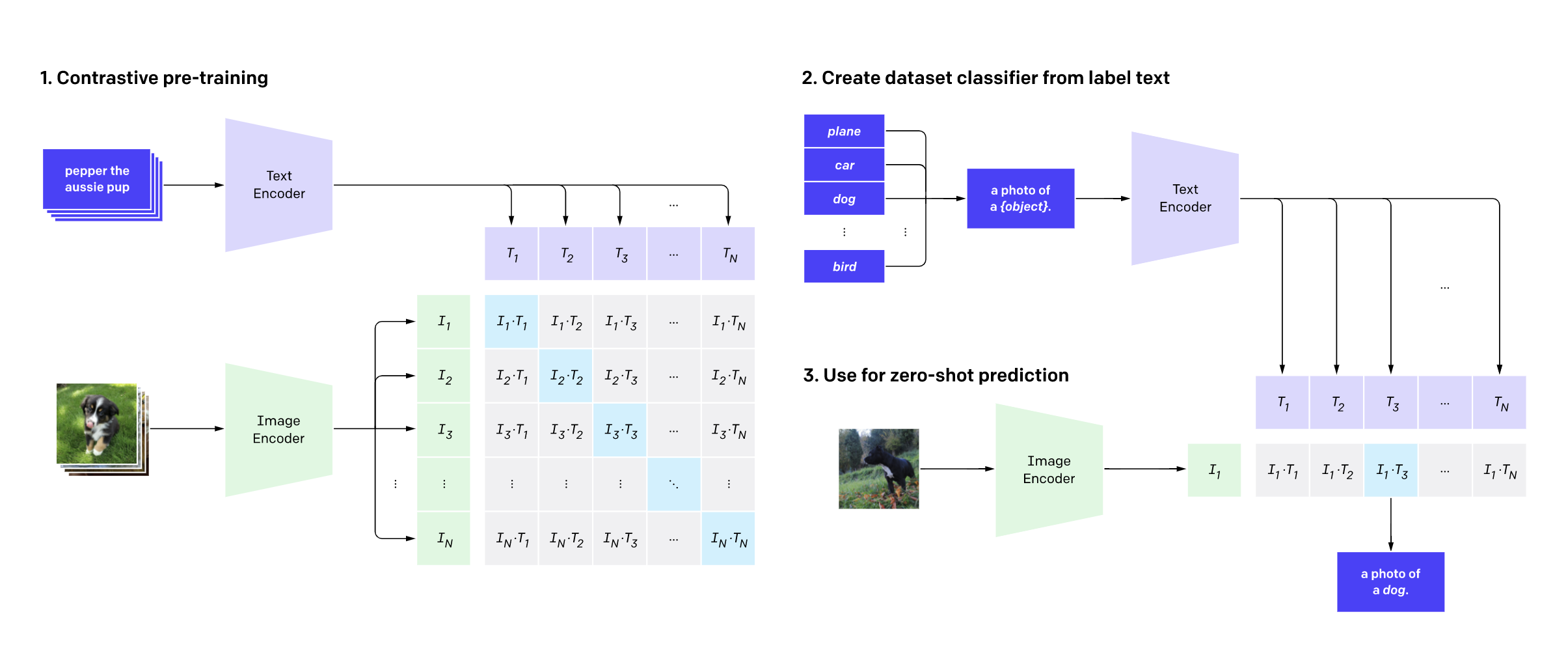
リモートセンシング(衛星)画像とキャプションを使用してCLIPの微調整
リモートセンシング(衛星)画像とキャプションを使用したCLIPの微調整 今年の7月、Hugging FaceはFlax/JAXコミュニティウィークを開催し、自然言語処理(NLP)とコンピュータビジョン(CV)の分野でHugging Faceトランスフォーマーモデルを訓練するプロジェクトの提出をコミュニティに呼びかけました。 参加者はFlaxとJAXを使用したTensor Processing Units(TPUs)を使用しました。JAXは線形代数ライブラリ(numpyのような)で、自動微分(Autograd)を行い、XLAにコンパイルできます。また、FlaxはJAX用のニューラルネットワークライブラリであり、エコシステムです。TPUの計算時間は、共同スポンサーであるGoogle Cloudが無料で提供しました。 その後の2週間で、チームはHugging FaceとGoogleの講義に参加し、JAX/Flaxを使用して1つ以上のモデルを訓練し、それらをコミュニティと共有し、モデルの機能を示すHugging Face Spacesデモを提供しました。約100チームが参加し、170のモデルと36のデモが生まれました。 私たちのチームは、おそらく他の多くのチームと同様に、12のタイムゾーンにまたがる分散型のチームです。私たちの共通点は、TWIML Slackチャンネルに所属していることであり、そこでは人工知能(AI)と機械学習(ML)のトピックに関心を持つメンバーが集まっています。 私たちは、OpenAIのCLIPネットワークをRSICDデータセットの衛星画像とキャプションで微調整しました。CLIPネットワークは、インターネット上で見つかる画像とキャプションのペアを使用して、自己教師ありの方法で視覚的な概念を学習します。推論中、モデルはテキストの説明に基づいて最も関連性の高い画像を予測するか、画像に基づいて最も関連性の高いテキストの説明を予測することができます。CLIPは、普段の画像に対してゼロショットで使用するには十分なパワフルです。しかし、衛星画像は普段の画像とは異なるため、CLIPを微調整することが有益であると考えました。私たちの直感は正しかったようで、評価結果(後述)が示すようになりました。この記事では、私たちのトレーニングと評価プロセスの詳細、およびこのプロジェクトへの今後の取り組みについて説明します。 私たちのプロジェクトの目標は、有用なサービスを提供し、CLIPを実用的なユースケースに使用する方法を示すことでした。私たちのモデルは、テキストクエリを使用して大規模な衛星画像のコレクションを検索するためにアプリケーションによって使用することができます。そのようなクエリは、画像全体を記述することができます(例:ビーチ、山、空港、野球場など)、またはこれらの画像内の特定の地理的または人工的な特徴を検索または言及することができます。CLIPは、他のドメインでも同様に微調整することができます。これは、医療画像のメディカルチームによって示されています。 テキストクエリを使用して大規模な画像コレクションを検索する能力は、非常に強力な機能であり、社会的な善だけでなく、悪意のある目的にも使用することができます。国家防衛や反テロ活動、気候変動の影響を管理可能な状態になる前に発見し対処する能力など、様々な応用が考えられます。ただし、この力は、権威主義的な国家による軍事や警察の監視などの目的で誤用される可能性もあるため、倫理的な問題も提起されます。 プロジェクトについては、プロジェクトページで詳細を読むことができます。また、独自のデータで推論に使用するために、トレーニング済みモデルをダウンロードすることもできます。デモでも実際の動作を確認することができます。 トレーニング データセット 私たちは、主にRSICDデータセットを使用してCLIPモデルを微調整しました。このデータセットは、Google Earth、Baidu Map、MapABC、Tiandituから収集された約10,000枚の画像から構成されています。このデータセットは、Exploring Models…

CLIPSegによるゼロショット画像セグメンテーション
このガイドでは、🤗 transformersを使用して、ゼロショットの画像セグメンテーションモデルであるCLIPSegを使用する方法を紹介します。CLIPSegは、ロボットの知覚、画像補完など、さまざまなタスクに使用できるラフなセグメンテーションマスクを作成します。より正確なセグメンテーションマスクが必要な場合は、Segments.aiでCLIPSegの結果を改善する方法も紹介します。 画像セグメンテーションは、コンピュータビジョンの分野でよく知られたタスクです。これにより、コンピュータは画像内の物体を知るだけでなく(分類)、画像内の物体の位置を知ることもできます(検出)、さらには物体の輪郭も知ることができます。物体の輪郭を知ることは、ロボット工学や自動運転などの分野では重要です。たとえば、ロボットは物体の形状を正しく把握するために、その形状を知る必要があります。セグメンテーションは、画像補完と組み合わせることもでき、ユーザーが画像のどの部分を置き換えたいかを説明することができます。 ほとんどの画像セグメンテーションモデルの制限の1つは、固定されたカテゴリのリストでのみ機能するということです。たとえば、オレンジでトレーニングされたセグメンテーションモデルを使用して、リンゴをセグメント化することはできません。セグメンテーションモデルに追加のカテゴリを教えるには、新しいカテゴリのデータをラベル付けし、新しいモデルをトレーニングする必要があります。これは費用と時間がかかる場合があります。しかし、さらなるトレーニングなしにほとんどどのような種類のオブジェクトでもセグメント化できるモデルがあったらどうでしょうか?それがCLIPSeg、ゼロショットのセグメンテーションモデルが達成するものです。 現時点では、CLIPSegにはまだ制限があります。たとえば、モデルは352 x 352ピクセルの画像を使用するため、出力はかなり低解像度です。したがって、モダンなカメラの画像を使用すると、ピクセルパーフェクトな結果を期待することはできません。より正確なセグメンテーションを必要とする場合、前のブログ記事で示したように、最新のセグメンテーションモデルを微調整することができます。その場合、CLIPSegを使用してラフなラベルを生成し、Segments.aiなどのラベリングツールでそれらを調整することができます。それについて説明する前に、まずCLIPSegの動作を見てみましょう。 CLIP: CLIPSegの背後にある魔法のモデル CLIP(Contrastive Language–Image Pre-training)は、OpenAIが2021年に開発したモデルです。CLIPに画像またはテキストの一部を与えると、CLIPは入力の抽象的な表現を出力します。この抽象的な表現、または埋め込みとも呼ばれるものは、実際にはベクトル(数値のリスト)です。このベクトルは、高次元空間のポイントと考えることができます。CLIPは、似たような画像とテキストの表現も似たようにするようにトレーニングされています。つまり、画像とそれに合致するテキストの説明を入力すると、画像とテキストの表現が似ている(つまり、高次元のポイントが近くにある)ことになります。 最初はあまり役に立たないように思えるかもしれませんが、実際には非常に強力です。例えば、CLIPを使用して訓練されたことがないタスクで画像を分類する方法を簡単に見てみましょう。画像を分類するには、画像と選択肢となる異なるカテゴリをCLIPに入力します(例えば、画像と「りんご」、「オレンジ」などの単語を入力します)。CLIPは、画像と各カテゴリの埋め込みを返します。今、画像の埋め込みに最も近いカテゴリの埋め込みを確認するだけです。これで完了です!まるで魔法のようですね。 CLIPを使用した画像分類の例(出典)。 さらに、CLIPは分類だけでなく、画像検索(これが分類と似ていることがわかりますか?)、テキストから画像への変換モデル(DALL-E 2はCLIPで動作します)、物体検出(OWL-ViT)などにも使用できます。そして、私たちにとって最も重要なのは、画像セグメンテーションです。これでCLIPが機械学習において本当に画期的なものである理由がお分かりいただけるでしょう。 CLIPが非常にうまく機能する理由は、モデルがテキストのキャプション付きの膨大なデータセットでトレーニングされたからです。そのデータセットには、インターネットから取得した4億枚の画像テキストペアが含まれています。これらの画像にはさまざまなオブジェクトや概念が含まれており、CLIPはそれぞれのオブジェクトに対して表現を生成するのに優れています。 CLIPSeg: CLIPによる画像セグメンテーション CLIPSegは、CLIPの表現を使用して画像セグメンテーションマスクを作成するモデルです。Timo LüddeckeさんとAlexander Eckerさんによって公開されました。彼らは、CLIPモデルを凍結したまま、TransformerベースのデコーダをCLIPモデルの上にトレーニングすることで、ゼロショット画像セグメンテーションを達成しました。デコーダは、画像のCLIP表現とセグメンテーションしたい対象のCLIP表現を入力として受け取り、これらの2つの入力を使用して、CLIPSegデコーダは2値のセグメンテーションマスクを作成します。より詳しく言うと、デコーダはセグメンテーションしたい画像の最終的なCLIP表現だけでなく、CLIPのいくつかのレイヤーの出力も使用します。 ソース デコーダは、PhraseCutデータセットでトレーニングされています。このデータセットには、340,000以上のフレーズと対応する画像セグメンテーションマスクが含まれています。著者たちはまた、データセットのサイズを拡大するためにさまざまな拡張方法も試みました。ここでの目標は、データセットに存在するカテゴリだけでなく、未知のカテゴリもセグメンテーションできるようにすることです。実験の結果、デコーダは未知のカテゴリにも対応できることが示されています。…

CapPaに会ってください:DeepMindの画像キャプション戦略は、ビジョンプレトレーニングを革新し、スケーラビリティと学習性能でCLIPに匹敵しています
「Image Captioners Are Scalable Vision Learners Too」という最近の論文は、CapPaと呼ばれる興味深い手法を提示しています。CapPaは、画像キャプションを競争力のある事前学習戦略として確立することを目的としており、DeepMindの研究チームによって執筆されたこの論文は、Contrastive Language Image Pretraining(CLIP)の驚異的な性能に匹敵する可能性を持つと同時に、簡単さ、拡張性、効率性を提供することを強調しています。 研究者たちは、Capと広く普及しているCLIPアプローチを比較し、事前学習コンピュータ、モデル容量、トレーニングデータを慎重に一致させ、公平な評価を確保しました。研究者たちは、Capのビジョンバックボーンが、少数派分類、キャプション、光学式文字認識(OCR)、視覚的問い合わせ(VQA)を含むいくつかのタスクでCLIPモデルを上回ったことがわかりました。さらに、大量のラベル付きトレーニングデータを使用した分類タスクに移行する際、CapのビジョンバックボーンはCLIPと同等の性能を発揮し、マルチモーダルなダウンストリームタスクにおける潜在的な優位性を示しています。 さらに、研究者たちは、Capの性能をさらに向上させるために、CapPa事前学習手順を導入しました。この手順は、自己回帰予測(Cap)と並列予測(Pa)を組み合わせたものであり、画像理解に強いVision Transformer(ViT)をビジョンエンコーダーとして利用しました。画像キャプションを予測するために、研究者たちは、標準的なTransformerデコーダーアーキテクチャを使用し、ViTエンコードされたシーケンスをデコードプロセスに効果的に使用するために、クロスアテンションを組み込みました。 研究者たちは、訓練段階でモデルを自己回帰的にのみ訓練するのではなく、モデルがすべてのキャプショントークンを独立して同時に予測する並列予測アプローチを採用しました。これにより、デコーダーは、並列でトークン全体にアクセスできるため、予測精度を向上させるために、画像情報に強く依存できます。この戦略により、デコーダーは、画像が提供する豊富な視覚的文脈を活用することができます。 研究者たちは、画像分類、キャプション、OCR、VQAを含むさまざまなダウンストリームタスクにおけるCapPaの性能を、従来のCapおよび最先端のCLIPアプローチと比較するための研究を行いました。その結果、CapPaはほぼすべてのタスクでCapを上回り、CLIP*と同じバッチサイズで訓練された場合、CapPaは同等または優れた性能を発揮しました。さらに、CapPaは強力なゼロショット機能を備え、見知らぬタスクにも効果的な汎化が可能であり、スケーリングの可能性があります。 全体的に、この論文で提示された作業は、画像キャプションを競争力のあるビジョンバックボーンの事前学習戦略として確立することを示しています。CapPaの高品質な結果をダウンストリームタスクにおいて実現することにより、研究チームは、ビジョンエンコーダーの事前トレーニングタスクとしてのキャプションの探索を促進することを望んでいます。その簡単さ、拡張性、効率性により、CapPaは、ビジョンベースのモデルを進化させ、マルチモーダル学習の境界を押し広げるための興味深い可能性を開拓しています。

2024年にフォローするべきデータサイエンスのトップ12リーダー
データサイエンスの広がりを見据えると、2024年の到来は、革新を牽引し、分析の未来を形作る一握りの著名人にスポットライトを当てる重要な瞬間として迎えられます。『Top 12 Data Science Leaders List』は、これらの個人の卓越した専門知識、先見のリーダーシップ、および分野への重要な貢献を称えるビーコンとして機能します。私たちは、これらの画期的なマインドの物語、プロジェクト、そして先見の見通しをナビゲートしながら、データサイエンスの進路を形作ると約束された航跡を探求します。これらの模範的なリーダーたちは単なるパイオニアにとどまることはありません。彼らは無類のイノベーションと発見の時代へと私たちを導く先駆者そのものです。 2024年に注目すべきトップ12データサイエンスリーダーリスト 2024年への接近とともに、データサイエンスにおいて傑出した専門知識、リーダーシップ、注目すべき貢献を示す特異なグループの人々に焦点を当てています。『Top 12 Data Science Leaders List』は、これらの個人を認識し、注目することで、彼らを思想リーダー、イノベーター、およびインフルエンサーとして認め、来年重要なマイルストーンを達成することが予想されます。 さらに詳細に突入すると、これらの個人の視点、事業、イニシアチブが、さまざまなセクターを横断する複雑な課題に対するメソッドとデータの活用方法を変革することが明らかになります。予測分析の進展、倫理的なAIの実践の促進、または先進的なアルゴリズムの開発など、このリストでハイライトされた個人たちが2024年にデータサイエンスの領域に影響を与えることが期待されています。 1. Anndrew Ng 「AIのゲームにおいて、適切なビジネスコンテキストを見つけることが非常に重要です。私はテクノロジーが大好きです。それは多くの機会を提供します。しかし結局のところ、テクノロジーはコンテクスト化され、ビジネスユースケースに収まる必要があります。」 Dr. アンドリュー・エングは、機械学習(ML)と人工知能(AI)の専門知識を持つ英米のコンピュータ科学者です。AIの開発への貢献について語っている彼は、DeepLearning.AIの創設者であり、Landing AIの創設者兼CEO、AI Fundのゼネラルパートナー、およびスタンフォード大学コンピュータサイエンス学科の客員教授でもあります。さらに、彼はGoogle AIの傘下にある深層学習人工知能研究チームの創設リードでありました。また、彼はBaiduのチーフサイエンティストとして、1300人のAIグループの指導や会社のAIグローバル戦略の開発にも携わりました。 アンドリュー・エング氏は、スタンフォード大学でMOOC(大規模オープンオンラインコース)の開発をリードしました。また、Courseraを創設し、10万人以上の学生に機械学習のコースを提供しました。MLとオンライン教育の先駆者である彼は、カーネギーメロン大学、MIT、カリフォルニア大学バークレー校の学位を保持しています。さらに、彼はML、ロボット工学、関連する分野で200以上の研究論文の共著者であり、Tiime誌の世界で最も影響力のある100人のリストに選ばれています。…

「Javaアプリケーションのレイテンシー削減」
この記事では、大規模なプロダクションアプリケーションのメモリ解析に関連する課題と、それを乗り越える方法について取り上げます

高度なRAGテクニック:イラスト入り概要
この投稿の目標は、利用可能なRAGアルゴリズムとテクニックの概要と説明をすることなので、コードの実装の詳細には立ち入らず、参照のみ行い、それについては放置します

「FinTech API管理におけるAIの力を解き放つ:製品マネージャーのための包括的なガイド」
この包括的なガイドでは、AIが金融技術のAPI管理に果たす変革的な役割を探求し、各セクションごとに実世界の例を提供していますAIによる洞察力や異常検知からAIによる設計、テスト、セキュリティ、そして個人化されたユーザーエクスペリエンスまで、金融技術のプロダクトマネージャーはAIの力を活用してオペレーションを最適化し、セキュリティを強化し、提供を行わなければなりません

「2023年のAI タイムライン」
はじめに 人工知能(AI)は、技術的な進歩が人間のつながりの本質と共鳴する形で私たちの日常生活と交差する魅力的な領域です。今年は、単なるアルゴリズムを超えてAIを身近に感じる革新の物語が展開されました。2023年のAIの素晴らしいハイライトを探索しながら、この旅に参加しましょう。 AI 2023年のハイライト 2023年のAIの世界で行われた最大の発見、進歩、および世界的な変革の一部を紹介します。これらの進歩がどのように、技術が私たちの人間の体験にシームレスに統合される未来を形作っているのか、探求してみましょう。 2023年1月のAIハイライト この年は、AIが医療と健康の分野で重要な進展を示しました。MITの研究者はマサチューセッツ総合病院と連携し、CTスキャンに基づいて患者の肺がんのリスクを評価できるディープラーニングモデルを開発しました。また、革命的な進歩として、研究者たちはAIを使ってゼロから人工的な酵素やタンパク質を作り出すことが可能なAIを開発しました。 他にも多くのイノベーションの中で、人工知能は視覚障害のある人々が食料品を見つけるのを手助けするために手杖に統合されました。一方、ビジネスのフロントでは、OpenAIがMicrosoftとの数年間にわたる数十億ドルの取引を通じてAIの開発に大きく投資しました。 2023年2月のAIハイライト 2023年2月には、OpenAIのChatGPTに関する話題が最も盛り上がりました。このAI搭載のチャットボットは、アメリカ合衆国医師資格試験(USMLE)に合格し、その人気は1億人以上のユーザーにまで急上昇しました。 ChatGPTの現象に応えて、GoogleはAI会話の領域に新しい要素となるBard A.I.を導入しました。また、MicrosoftもChatGPTと統合された新しいBing検索エンジンの導入に重要な一歩を踏み出しました。 Metaは、Metaエコシステム内でAIの能力を向上させるというLLaMAを発表しました。一方、Amazon Web Services(AWS)は、一流のAIプラットフォームであるHugging Faceと提携し、AI開発者を支援しました。 画期的な成果として、オックスフォードの研究者たちはRealFusionを示し、単一の画像から完全な360°写真モデルを再構築することができる最新のモデルを実証しました。 2023年2月には、AIの世界は音楽生成の領域にも足を踏み入れました。Google ResearchはMusicLMを紹介し、さまざまなジャンル、楽器、概念で曲を作成できるトランスフォーマーベースのテキストからオーディオへのモデルを提供しました。一方、Baiduの研究者はERNIE-Musicを発表し、拡散モデルを使用して、波形領域での最初のテキストから音楽を生成するモデルを開発しました。これらのモデルは、AIと創造的表現の融合における重要な進歩を示しています。 2023年3月のAIハイライト 2023年3月には、創造的なAIはいくつかの興味深い進展を見せました。AdobeはFireflyというAIをバックアップする画像生成および編集ツールの範囲でGenAIの領域に参入しました。一方、Canvaはユーザー向けにAIパワードの仮想デザインアシスタントとブランドマネージャーを導入しました。 テックジャイアンツのAIプロジェクトは、第1四半期終盤に向けて全力で進展していました。OpenAIはChatGPTとWhisperというテキストから音声へのモデルのためのAPIを発売しました。OpenAIはまた、ChatGPTのためのいくつかのプラグインをリリースし、最も高度なAIモデルであるGPT-4を正式に発表しました。 HubSpotはユーザー向けにChatSpot.aiとContent Assistantという2つの新しいAIパワードツールを導入しました。ZoomはスマートコンパニオンのZoom…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.