Learn more about Search Results CARTO - Page 2

- You may be interested
- 「ODSC East 2024 Pre-Bootcamp Primer コ...
- 「Juliaプログラミング言語の探求 ユニッ...
- 「Hugging FaceはLLMのための新しいGitHub...
- データストリームにおける行列近似
- 「ODSC West 2023 写真で振り返る」
- 「OpenAIがより大きく、より凶暴で、より...
- 「スマートな会話インターフェースのため...
- スタンフォードの研究者たちは、Parselと...
- 「グラフ理論における重要な概念、グラフ...
- AIAgentに会ってみましょう:APIキーを必...
- NLPの探求- NLPのキックスタート(ステッ...
- 「モダンデータウェアハウス」というテーマ
- 「データサイエンティストのための高収入...
- 「Amazon Bedrock と Amazon Location Ser...
- 分類の評価指標:正確度を超えて

「🧨 JAXを使用したCloud TPU v5eでの高速で安定したXL推論の拡散を加速する」
生成AIモデルであるStable Diffusion XL(SDXL)などは、幅広い応用において高品質でリアルなコンテンツの作成を可能にします。しかし、このようなモデルの力を利用するには、大きな課題や計算コストが伴います。SDXLは、そのUNetコンポーネントがモデルの以前のバージョンのものよりも約3倍大きい大きな画像生成モデルです。このようなモデルを実稼働環境に展開することは、増加したメモリ要件や推論時間の増加などの理由から難しいです。今日、私たちはHugging Face DiffusersがJAX on Cloud TPUsを使用してSDXLをサポートすることを発表できることを大いに喜んでいます。これにより、高性能でコスト効率の良い推論が可能になります。 Google Cloud TPUsは、大規模なAIモデルのトレーニングや推論を含む、最先端のLLMsや生成AIモデルなどのために最適化されたカスタムデザインのAIアクセラレータです。新しいCloud TPU v5eは、大規模AIトレーニングや推論に必要なコスト効率とパフォーマンスを提供するよう特別に設計されています。TPU v4の半分以下のコストで、より多くの組織がAIモデルのトレーニングと展開が可能になります。 🧨 Diffusers JAX連携は、XLAを介してTPU上でSDXLを実行する便利な方法を提供します。それに対応するデモも作成しました。このデモは、時間のかかる書式変換や通信時間、フロントエンド処理を含めて約4秒で4つの大きな1024×1024の画像を提供するために複数のTPU v5e-4インスタンス(各インスタンスに4つのTPUチップがあります)で実行されます。実際の生成時間は2.3秒です。以下で詳しく見ていきましょう! このブログ記事では、 なぜJAX + TPU + DiffusersはSDXLを実行するための強力なフレームワークなのかを説明します。…

AI(人工知能)開発の先頭を走る13の企業
AIの未来は今日作られています!ODSCウエストのAIエキスポでは、未来がどのように展開し、AIの軌道がこれからの数年間でどのようになるかがわかる絶好の機会ですなので、いくつかの会社が基礎を築いている様子を見てみましょう

「T2Iアダプタを使用した効率的で制御可能なSDXL生成」
T2I-Adapterは、オリジナルの大規模なテキストから画像へのモデルを凍結しながら、事前学習されたテキストから画像へのモデルに追加のガイダンスを提供する効率的なプラグアンドプレイモデルです。T2I-Adapterは、T2Iモデル内部の知識を外部の制御信号と整合させます。さまざまな条件に応じてさまざまなアダプタをトレーニングし、豊富な制御と編集効果を実現することができます。 ControlNetは同様の機能を持ち、広く使用されている現代の作業です。しかし、実行するには計算コストが高い場合があります。これは、逆拡散プロセスの各ノイズ除去ステップで、ControlNetとUNetの両方を実行する必要があるためです。さらに、ControlNetは制御モデルとしてUNetエンコーダのコピーを重要視しており、パラメータ数が大きくなるため、生成はControlNetのサイズによって制約されます(サイズが大きければそれだけプロセスが遅くなります)。 T2I-Adapterは、この点でControlNetに比べて競争力のある利点を提供します。T2I-Adapterはサイズが小さく、ControlNetとは異なり、T2I-Adapterはノイズ除去プロセス全体の間ずっと一度だけ実行されます。 過去数週間、DiffusersチームとT2I-Adapterの著者は、diffusersでStable Diffusion XL(SDXL)のT2I-Adapterのサポートを提供するために協力してきました。このブログ記事では、SDXLにおけるT2I-Adapterのトレーニング結果、魅力的な結果、そしてもちろん、さまざまな条件(スケッチ、キャニー、ラインアート、深度、およびオープンポーズ)でのT2I-Adapterのチェックポイントを共有します。 以前のバージョンのT2I-Adapter(SD-1.4/1.5)と比較して、T2I-Adapter-SDXLはまだオリジナルのレシピを使用しており、79Mのアダプタで2.6BのSDXLを駆動しています!T2I-Adapter-SDXLは、強力な制御機能を維持しながら、SDXLの高品質な生成を受け継いでいます。 diffusersを使用してT2I-Adapter-SDXLをトレーニングする 私たちは、diffusersが提供する公式のサンプルを元に、トレーニングスクリプトを作成しました。 このブログ記事で言及するT2I-Adapterモデルのほとんどは、LAION-Aesthetics V2からの3Mの高解像度の画像テキストペアで、以下の設定でトレーニングされました: トレーニングステップ:20000-35000 バッチサイズ:データ並列、単一GPUバッチサイズ16、合計バッチサイズ128。 学習率:定数学習率1e-5。 混合精度:fp16 コミュニティには、スピード、メモリ、品質の間で競争力のあるトレードオフを打つために、私たちのスクリプトを使用してカスタムでパワフルなT2I-Adapterをトレーニングすることをお勧めします。 diffusersでT2I-Adapter-SDXLを使用する ここでは、ラインアートの状態を例にとって、T2I-Adapter-SDXLの使用方法を示します。まず、必要な依存関係をインストールします: pip install -U git+https://github.com/huggingface/diffusers.git pip install…

「VoAGI創設者グレゴリー・ピアテツキーシャピロとの30周年記念インタビュー」
グレゴリー・ピアテツキー・シャピロは、30年前に知識発見に関する初期のワークショップを組織した後、VoAGIを設立しましたこの回顧的なインタビューでは、彼はVoAGIの成長、ディープラーニングなどの重要なイノベーション、AIの社会的影響への懸念について振り返っています

オムニバースへ:Reallusionは、2方向のライブ同期とOpenUSDサポートにより、キャラクターアニメーションのワークフローを向上させます
編集者の注:この投稿はInto the Omniverseシリーズの一部であり、アーティスト、開発者、企業がOpenUSDとNVIDIA Omniverseの最新の進歩を活用してワークフローを変革する方法に焦点を当てています。 単一の3Dキャラクターをアニメーション化したり、産業のデジタル化のためにそれらのグループを生成したりする場合、人気のあるReallusionソフトウェアを使用するクリエイターや開発者は、今月リリースされたiClone Omniverse Connectorの最新のアップデートでワークフローを向上させることができます。 このアップグレードにより、NVIDIA Omniverseを使用するクリエイターにとって、シームレスなコラボレーションが可能になり、創造的な可能性が拡大します。NVIDIA Omniverseは、OpenUSDベースのツールやアプリケーションを接続および構築するための開発プラットフォームです。 新機能には、プロジェクトのリアルタイム同期や、Universal Scene Descriptionフレームワーク(OpenUSDとも呼ばれる)の強化されたインポート機能が含まれており、これによりiCloneとOmniverseの間の作業がより迅速でスムーズかつ効率的になります。このアップデートには、バグ修正と改善も含まれています。 3Dキャラクターをより良くアニメーション化する 世界中のクリエイターは、リアルタイムの3DアニメーションソフトウェアであるReallusion iCloneを使用してキャラクターを生き生きとさせています。 ソロモン・ジャグウェは、3Dアーティスト、アニメーター、受賞歴を持つ映画監督であり、彼の作品はしばしば環境に焦点を当てています。 東アフリカで育ったジャグウェは、兄と一緒に田舎に冒険に出かけたときに見た生物を描くという幼い頃の思い出を思い出します。今でも、彼の3D作品の多くは、ペンと紙を使ったシンプルなスケッチから始まります。 このアーティストは、常に影響を与えるアートを作り出すことを目指していると語っています。 たとえば、ジャグウェは、ウガンダの文化についてあらゆる年齢の人々に教育するためのビデオシリーズ「Adventures of Nkoza and Nankya」を作成しました。彼はこのシリーズのためのセットをAutodesk…
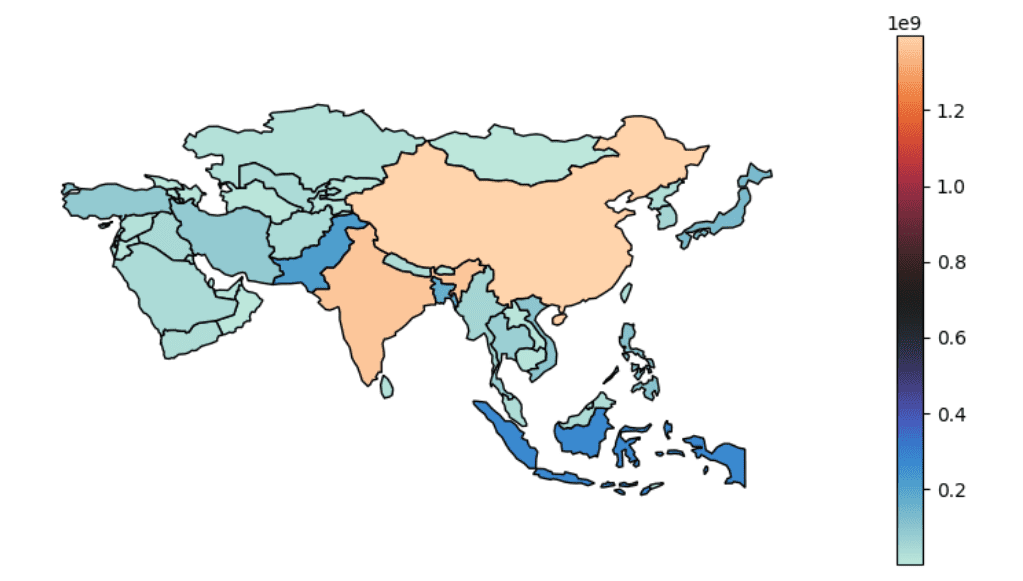
ジオスペーシャルデータ分析のための5つのPythonパッケージ
この記事では、地理空間解析の重要性について説明し、地理空間データから貴重な洞察を効果的に処理し可視化するための5つの必須のPythonパッケージを紹介しています
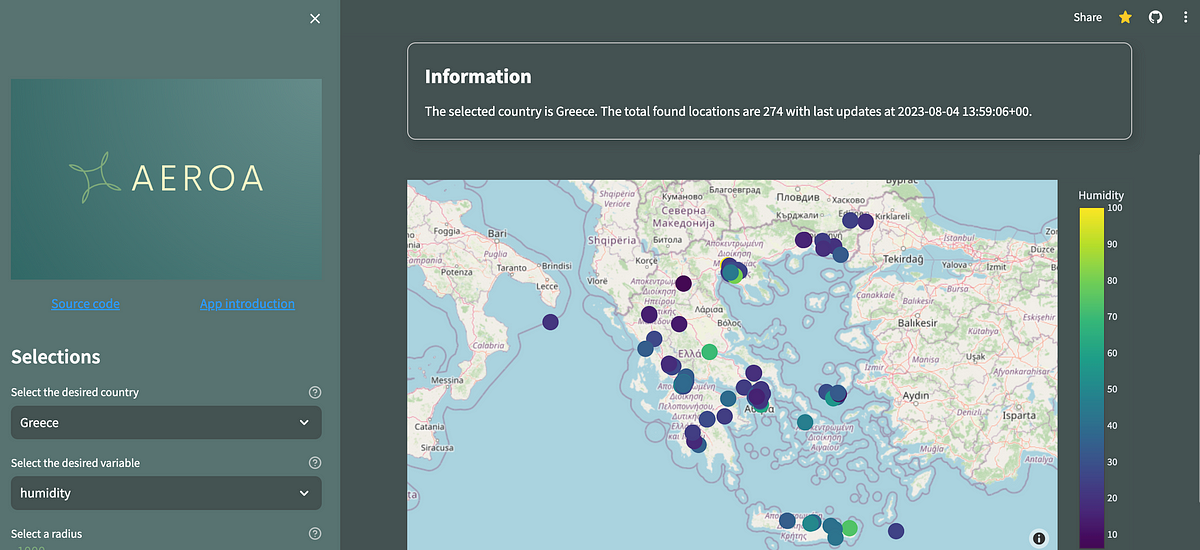
Streamlitの新しいConnections機能とインタラクティブなPlotlyマップでアプリを強化する
最近、Streamlitは、この記事が書かれている時点で、新機能であるst.experimental_connectionを発表しました私はそれを使ってみて、どのように動作するのかを理解することに非常に興味がありました...

「人工知能が山火事との闘いに役立つ」
MSN.comの報告によると、オタワ大学とハワイ大学の研究者が協力して、人工知能(AI)を使った山火事の防災能力を開発していますこれは、現在カナダやシチリア、世界の他の地域で山火事が発生しているため、既に深刻な問題がさらに悪化している状況です

マルチモーダル言語モデル:人工知能(AI)の未来
大規模言語モデル(LLM)は、テキストの分析や生成などのタスクをこなすことができるコンピュータモデルです。これらは膨大なテキストデータで訓練され、テキスト生成やコーディングなどのパフォーマンスを向上させます。 現在のほとんどのLLMはテキストのみであり、テキストベースのアプリケーションに優れ、他の種類のデータを理解する能力に制限があります。 テキストのみのLLMの例には、GPT-3、BERT、RoBERTaなどがあります。 それに対して、マルチモーダルLLMは、テキストに加えて画像、動画、音声、その他の感覚入力など、他のデータタイプを組み合わせます。マルチモーダル性をLLMに統合することで、現在のテキストのみのモデルの制限を解消し、以前は不可能だった新しいアプリケーションの可能性を開くことができます。 最近リリースされたOpen AIのGPT-4はマルチモーダルLLMの一例です。画像とテキストの入力を受け付け、多くのベンチマークで人間レベルのパフォーマンスを示しています。 マルチモーダルAIの台頭 マルチモーダルAIの進展は、2つの重要な機械学習技術、表現学習と転移学習によってもたらされています。 表現学習により、モデルはすべてのモダリティに共有の表現を開発することができます。一方、転移学習により、モデルは特定のドメインでの微調整の前に基礎的な知識を学習することができます。 これらの技術は、マルチモーダルAIを実現し、CLIP(画像とテキストを整合させる)、DALL·E 2およびStable Diffusion(テキストプロンプトから高品質の画像を生成する)などの最近のブレークスルーによって効果的であります。 異なるデータモダリティ間の境界が不明瞭になるにつれて、複数のモダリティ間の関係を活用するAIアプリケーションがさらに増えることが予想され、フィールド全体でパラダイムシフトが起こります。アドホックなアプローチは徐々に時代遅れになり、さまざまなモダリティ間の関連を理解する重要性はますます高まるでしょう。 出典:https://jina.ai/news/paradigm-shift-towards-multimodal-ai/ マルチモーダルLLMの働き方 テキストのみの言語モデル(LLM)は、言語を理解し生成するためのトランスフォーマーモデルによって動作します。このモデルは入力テキストを「単語埋め込み」と呼ばれる数値表現に変換します。これらの埋め込みは、モデルがテキストの意味と文脈を理解するのに役立ちます。 トランスフォーマーモデルは、その後、「アテンションレイヤー」と呼ばれるものを使用して、入力テキストの異なる単語どうしの関係を処理し、出力の最も可能性の高い次の単語を予測します。 一方、マルチモーダルLLMは、テキストだけでなく、画像、音声、ビデオなどの他のデータ形式も扱います。これらのモデルは、テキストと他のデータタイプを共通のエンコーディング空間に変換するため、すべてのデータタイプを同じメカニズムで処理することができます。これにより、モデルは複数のモダリティからの情報を組み込んだ応答を生成し、より正確かつコンテキストに即した出力が可能となります。 マルチモーダル言語モデルの必要性 GPT-3やBERTのようなテキストのみのLLMは、記事の執筆、メールの作成、コーディングなど、幅広いアプリケーションに利用されています。ただし、このテキストのみのアプローチは、これらのモデルの制限も浮き彫りにしました。 言語は人間の知能の重要な部分ですが、それは私たちの知覚や能力の一側面を表すだけです。私たちの認知能力は、過去の経験や世界の動作の理解によって大きく形成された無意識の知覚と能力に大きく依存しています。 テキストだけで訓練されたLLMは、常識や世界の知識を組み込む能力に制限があります。トレーニングデータセットを拡大することはある程度役立つかもしれませんが、これらのモデルはまだ知識の予期せぬギャップに遭遇する可能性があります。マルチモーダルアプローチは、これらの課題のいくつかを解決することができます。 これをよりよく理解するために、ChatGPTとGPT-4の例を考えてみましょう。 ChatGPTは非常に有用な言語モデルであり、多くのコンテキストで非常に役立つことが証明されていますが、複雑な推論などの領域では制限があります。…

Pythonを使用して地理的な巡回セールスマン問題を解決する
有名な巡回セールスマン問題(TSP)は、ノード(都市)の集合間で最適な経路を見つけ、出発地に戻ることに関するものです簡単なように聞こえますが、解くことは不可能です...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.