Learn more about Search Results モード - Page 2

- You may be interested
- 「ベンジオが科学技術におけるゲルハルト...
- 「GeoPandasを使ったPythonにおける地理空...
- Gmailを効率的なメールソリューションに変...
- Q-学習入門 第1部への紹介
- 「組み込まれた責任あるAIプラクティスを...
- 大型言語モデル、StructBERT ー 言語構造...
- 「Amazon SageMakerトレーニングワークロ...
- 「Pythonもしもでないの場合:コード内の...
- 「PythonでゼロからGANモデルを構築および...
- 「リリに会ってください:マッキンゼーの...
- QLoRA:16GBのGPUで大規模な言語モデルの...
- 「EU AI法案:AIの未来における有望な一歩...
- 「Googleのおかげで、ロボットにとっての...
- モジュラーの共同創設者兼社長であるティ...
- AI(人工知能)の謎を解明:フォローすべ...

オンライン収益を新たな高みに引き上げましょう – リモートワークの成長する可能性を解き放ってください
オンラインの仕事は今まで以上に人気があります人々が在宅勤務の利点を発見するにつれ、世界中には1400万人以上のフリーランサーが登録アカウントを持っており、そのうち330万人が実際に収入を得ています数年前と比べると、在宅勤務を希望する人々の増加が著しいです...オンラインでの収入を新たな高みに引き上げましょう- リモートワークの成長ポテンシャルを引き出す 詳細を読む »

「pandasのCopy-on-Writeモードの深い探求-パートII」
最初の投稿では、Copy-on-Writeメカニズムの動作方法について説明しましたコピーがワークフローに導入されるいくつかの領域を強調していますこの投稿では、これを確実にする最適化に焦点を当てます...

JEN-1に会ってください:テキストまたは音楽表現に応じて条件付けられた高品質な音楽を生成するために、双方向および単方向のモードを組み合わせたユニバーサルAIフレームワーク
音楽は、ヘンリー・ワズワース・ロングフェローによって「人間の普遍的な言語」として讃えられ、調和、メロディ、リズムの本質を内包し、文化的な意義を織り交ぜて、世界中の人々と深く共鳴するものです。深層生成モデルの最近の進歩により、音楽生成の進歩が実現されています。ただし、テキストの説明に基づいて条件付けられた場合に、その複雑さやニュアンスを捉えた、高品質で現実的な音楽を生成するという課題は、依然として困難です。 既存の音楽生成方法は大きな進歩を遂げていますが、自由形式のテキストプロンプトと一致する複雑でリアルな音楽を開発するためには、さらなる改善が必要です。楽器やハーモニーの複雑な相互作用とメロディやハーモニーのアレンジにより、複雑で複雑な音楽構造が生まれます。音楽は不協和音に非常に敏感であるため、精度が重要です。 音楽は広い周波数スペクトルを持っており、細部を捉えるために44.1KHzステレオのような高いサンプリングレートが必要です。これは、低いサンプリングレートで動作する音声とは対照的です。 楽器の複雑な相互作用とメロディやハーモニーのアレンジは、複雑で複雑な音楽構造を生み出します。音楽は不協和音に非常に敏感であるため、精度が重要です。 キー、ジャンル、メロディのような属性を制御し続けることは、意図した芸術的なビジョンを実現するために重要です。 テキストから音楽を生成するという課題に対処するために、Futureverse研究チームはJEN-1を設計しました。JEN-1は、オートレグレッシブ(AR)と非オートレグレッシブ(NAR)のパラダイムを組み合わせたユニークな全方向拡散モデルを活用し、シーケンシャルな依存関係を捉えながら生成を加速することができます。音声データをメルスペクトログラムに変換する従来の方法とは異なり、JEN-1は生のオーディオ波形を直接モデル化し、より高い忠実度と品質を維持します。これは、ノイズに強いマスク付きオートエンコーダを使用して元のオーディオを潜在表現に圧縮することによって実現されます。研究者は、潜在埋め込みにおける異方性を減少させる正規化ステップを導入し、モデルのパフォーマンスをさらに向上させました。 JEN-1のコアアーキテクチャは、バイドとユニディレクショナルモードを組み合わせた全方向1D拡散モデルです。このモデルは、Efficient U-Netアーキテクチャに触発された時間的な1D効率的なU-Netを活用しています。このアーキテクチャは、波形を効果的にモデル化するために設計されており、シーケンシャルな依存関係と文脈情報の両方を捉えるために、畳み込み層とセルフアテンション層の両方を含んでいます。音楽生成において時系列性が重要であるため、ユニディレクショナルモードは因果パディングとマスク付きセルフアテンションを介して組み込まれており、生成された潜在埋め込みが右側の潜在埋め込みに依存するようにしています。 JEN-1のユニークな強みの一つは、統一された音楽マルチタスクトレーニングアプローチにあります。JEN-1は、主に次の3つの音楽生成タスクをサポートしています: 双方向テキストガイドの音楽生成 双方向音楽インペインティング(欠落セグメントの復元) ユニディレクションの音楽継続(外挿) マルチタスクトレーニングにより、JEN-1はタスク間でパラメータを共有し、より良い汎化性能を持ち、シーケンシャルな依存関係をより効果的に処理することができます。この柔軟性により、JEN-1はさまざまな音楽生成シナリオに適用できる多目的なツールとなります。 実験設定では、JEN-1を高品質の音楽データを5,000時間分トレーニングしました。モデルはマスク付き音楽オートエンコーダとFLAN-T5を使用しています。トレーニング中には、マルチタスク目的をバランスさせ、分類器フリーガイダンスを採用しています。JEN-1は、8つのA100 GPUでAdamWオプティマイザを使用して200kステップでトレーニングされました。 JEN-1の性能は、客観的および主観的な評価基準を用いていくつかの最新の手法と比較されます。JEN-1は、信憑性(FAD)、音声テキストの整合性(CLAP)、人間の評価に基づくテキストから音楽への品質(T2M-QLT)および整合性(T2M-ALI)の面で他の手法を上回っています。計算効率にもかかわらず、JEN-1はテキストから音楽への合成において競合モデルを上回っています。 除去実験により、JEN-1の異なる構成要素の効果が示されています。自己回帰モードの組み込みとマルチタスキング目標の採用により、音楽の品質と汎化性能が向上しています。提案手法は、トレーニングの複雑さを増加させることなく、一貫して高品質な音楽生成を実現しています。 総括すると、JEN-1はテキストから音楽を生成するための強力な解決策を提供し、この分野を大幅に前進させています。波形の直接モデリングと自己回帰および非自己回帰トレーニングの組み合わせにより、高品質な音楽を生成します。統合拡散モデルとマスクされたオートエンコーダーは、シーケンスモデリングを向上させます。JEN-1は、強力なベースラインと比較して主観的品質、多様性、および制御性において優れた性能を発揮し、音楽合成における効果を示しています。

パンダのコピー・オン・ライトモードの詳細な調査:パートI
「pandas 2.0 は4月初旬にリリースされ、新しいCopy-on-Write (CoW) モードに多くの改善がもたらされましたこの機能は、予定されている pandas 3.0 でデフォルトになることが期待されています」

Amazon SageMaker JumpStartを使用して、インターネット接続がないVPCモードで、生成AIの基礎モデルを利用します
最近の生成AIの進歩により、さまざまな業界で特定のビジネス問題を解決するために生成AIをどのように活用するかについての議論が盛んに行われています生成AIは、会話、物語、画像、動画、音楽などの新しいコンテンツやアイデアを作成することができるAIの一種ですこれらはすべて非常に大きなモデルに裏打ちされています
「Azureの「Prompt Flow」を使用して、GPTモードで文書コーパスをクエリする」
そして、「埋め込み」と「ベクトルストア」といった概念を習得し、プログラミングの要件と組み合わせることは、多くの人にとって複雑に思え、実際に力を引き出すことを妨げることは確かです...

「2023年にリモートジョブを見つけるための最適なプラットフォーム」
進化する労働環境に伴い、リモートの仕事の機会を提供する信頼性のあるプラットフォームへの需要が急増していますこちらで詳細をご確認ください!
2023年にリモートジョブを見つけるための最高のプラットフォーム
進化する労働環境に伴い、リモートの仕事の機会を提供する信頼性のあるプラットフォームへの需要が急増しています詳しくはこちらをご確認ください!
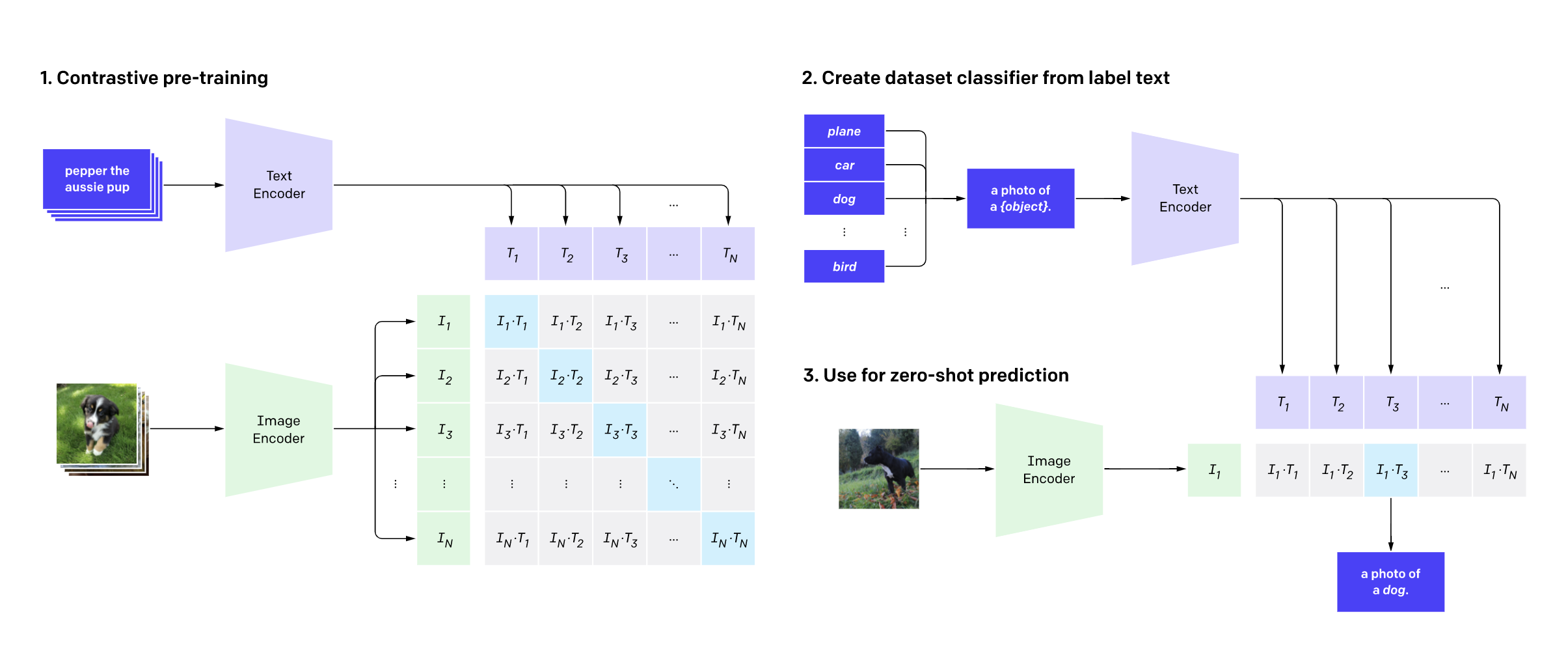
リモートセンシング(衛星)画像とキャプションを使用してCLIPの微調整
リモートセンシング(衛星)画像とキャプションを使用したCLIPの微調整 今年の7月、Hugging FaceはFlax/JAXコミュニティウィークを開催し、自然言語処理(NLP)とコンピュータビジョン(CV)の分野でHugging Faceトランスフォーマーモデルを訓練するプロジェクトの提出をコミュニティに呼びかけました。 参加者はFlaxとJAXを使用したTensor Processing Units(TPUs)を使用しました。JAXは線形代数ライブラリ(numpyのような)で、自動微分(Autograd)を行い、XLAにコンパイルできます。また、FlaxはJAX用のニューラルネットワークライブラリであり、エコシステムです。TPUの計算時間は、共同スポンサーであるGoogle Cloudが無料で提供しました。 その後の2週間で、チームはHugging FaceとGoogleの講義に参加し、JAX/Flaxを使用して1つ以上のモデルを訓練し、それらをコミュニティと共有し、モデルの機能を示すHugging Face Spacesデモを提供しました。約100チームが参加し、170のモデルと36のデモが生まれました。 私たちのチームは、おそらく他の多くのチームと同様に、12のタイムゾーンにまたがる分散型のチームです。私たちの共通点は、TWIML Slackチャンネルに所属していることであり、そこでは人工知能(AI)と機械学習(ML)のトピックに関心を持つメンバーが集まっています。 私たちは、OpenAIのCLIPネットワークをRSICDデータセットの衛星画像とキャプションで微調整しました。CLIPネットワークは、インターネット上で見つかる画像とキャプションのペアを使用して、自己教師ありの方法で視覚的な概念を学習します。推論中、モデルはテキストの説明に基づいて最も関連性の高い画像を予測するか、画像に基づいて最も関連性の高いテキストの説明を予測することができます。CLIPは、普段の画像に対してゼロショットで使用するには十分なパワフルです。しかし、衛星画像は普段の画像とは異なるため、CLIPを微調整することが有益であると考えました。私たちの直感は正しかったようで、評価結果(後述)が示すようになりました。この記事では、私たちのトレーニングと評価プロセスの詳細、およびこのプロジェクトへの今後の取り組みについて説明します。 私たちのプロジェクトの目標は、有用なサービスを提供し、CLIPを実用的なユースケースに使用する方法を示すことでした。私たちのモデルは、テキストクエリを使用して大規模な衛星画像のコレクションを検索するためにアプリケーションによって使用することができます。そのようなクエリは、画像全体を記述することができます(例:ビーチ、山、空港、野球場など)、またはこれらの画像内の特定の地理的または人工的な特徴を検索または言及することができます。CLIPは、他のドメインでも同様に微調整することができます。これは、医療画像のメディカルチームによって示されています。 テキストクエリを使用して大規模な画像コレクションを検索する能力は、非常に強力な機能であり、社会的な善だけでなく、悪意のある目的にも使用することができます。国家防衛や反テロ活動、気候変動の影響を管理可能な状態になる前に発見し対処する能力など、様々な応用が考えられます。ただし、この力は、権威主義的な国家による軍事や警察の監視などの目的で誤用される可能性もあるため、倫理的な問題も提起されます。 プロジェクトについては、プロジェクトページで詳細を読むことができます。また、独自のデータで推論に使用するために、トレーニング済みモデルをダウンロードすることもできます。デモでも実際の動作を確認することができます。 トレーニング データセット 私たちは、主にRSICDデータセットを使用してCLIPモデルを微調整しました。このデータセットは、Google Earth、Baidu Map、MapABC、Tiandituから収集された約10,000枚の画像から構成されています。このデータセットは、Exploring Models…

ウェアラブルフィットネストラッカー:早期疾患の検出の可能性を開く
消費者向けと医療用のウェアラブルが融合のばしょにあるかもしれませんか?ウェアラブルが融合して、より価値のあるものになるかもしれません
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.